这节课是巡安似海PyHacker编写指南的《XSS检测脚本编写》
喜欢用Python写脚本的小伙伴可以跟着一起写一写。
编写环境:Python2.x
00x1:
需要用到的模块如下:
import requests
00x2:
大致思路:
每次插入一个xss,判断网页内容是否存在,如果存在则输出
def req(url,xss):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url=url+xss,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Xss url:%s payload:%s"%(url,xss)
为了方便测试,我们先定义一个payload列表
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
00x3:
修改一下源代码,过滤script

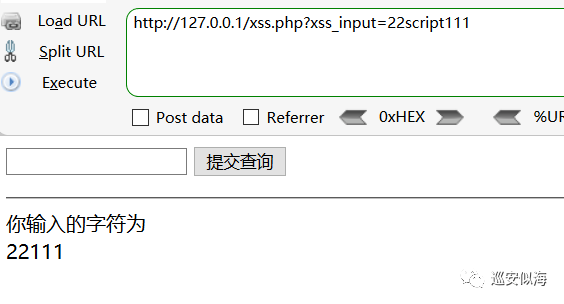
ok,一切正常
00x4:
我们来运行一下,遍历xss payload
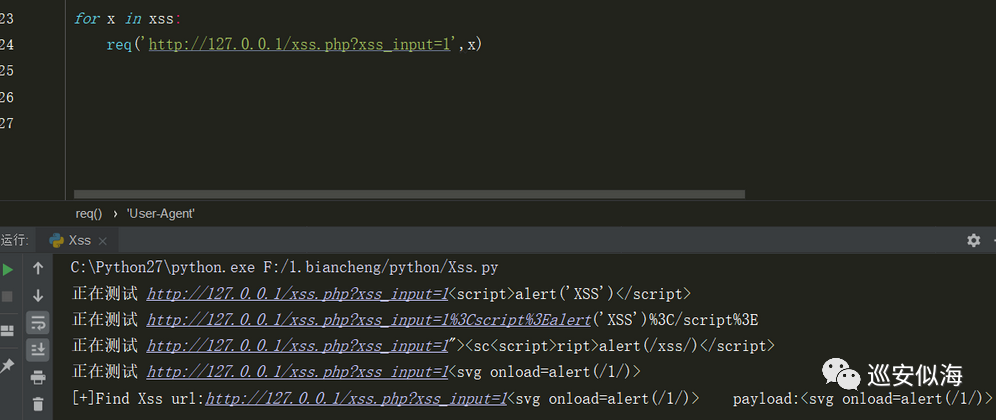
你也可以定义一个xss.txt,进行读取,然后遍历xss fuzz
(post请求也是如此,只需要一个post请求即可)
你也可以加上 如果存在xss则退出
00x5:
代码如下:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import urllib3
urllib3.disable_warnings()
def req(url,xss):
url = url + xss
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
print u"正在测试",url
if xss in req.content:
print "[+]Find Xss url:%s payload:%s"%(url,xss)
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
for x in xss:
req('http://127.0.0.1/xss.php?xss_input=1',x)
00x6:
当然这只是一个最简单的模型,下面我们来进行维护加强一下
思路:
我们可以匹配网页的form标签(表单提交),然后获取请求方式,以及请求参数,模拟请求,进行fuzz

def html(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
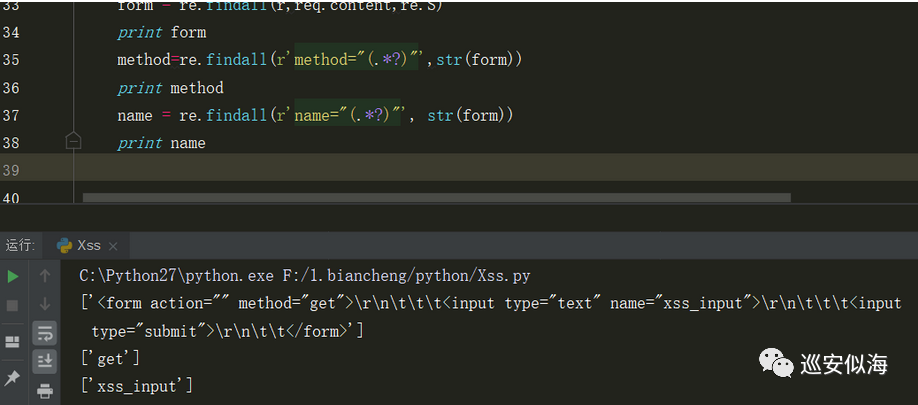
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
print form

接着我们去获取他的请求方式,以及请求参数
method=re.findall(r'method="(.*?)"',str(form)) print method name = re.findall(r'name="(.*?)"', str(form)) print name
Ok,我们设置全局变量,方便调用
global method,name
00x7:
添加判断,自动fuzz
if method[0] == 'get' or 'GET':
req = requests.get(url=url+"?"+name[0]+"="+xss,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
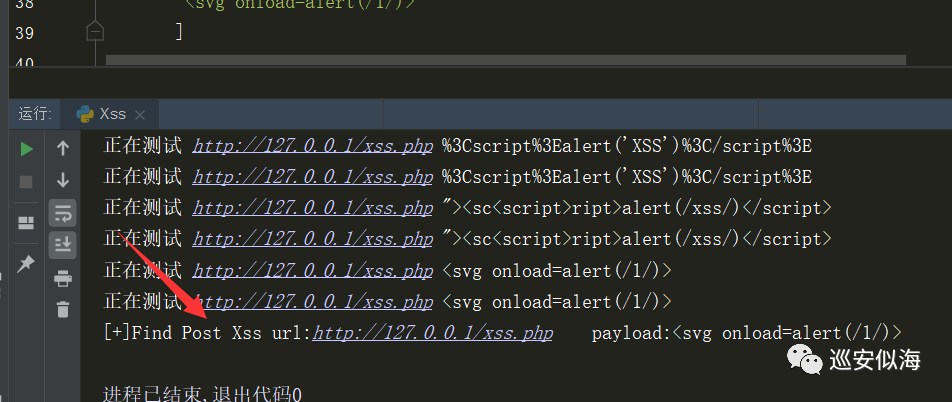
print "[+]Find Get Xss url:%s payload:%s"%(url,xss)
if method[0] == 'post' or 'POST':
data={name[0]:xss}
req = requests.post(url=url,data=data,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Post Xss url:%s payload:%s"%(url,xss)
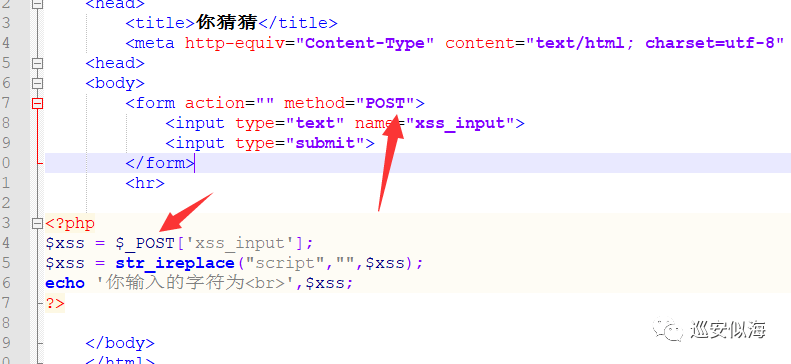
00x8:
为了更人性化,我们再修改一下,导入sys模块
sys.exit() 表示退出程序
def html(url):
global method,name
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
method=re.findall(r'method="(.*?)"',str(form))
name = re.findall(r'name="(.*?)"', str(form))
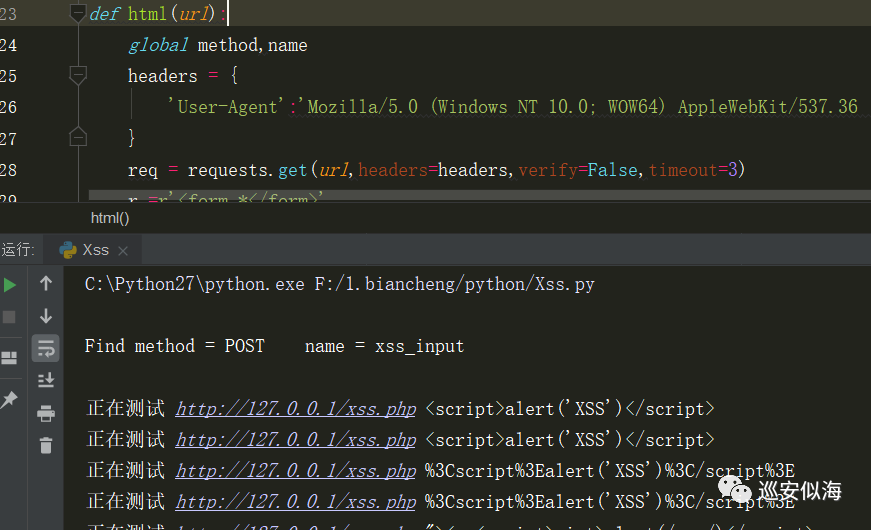
try:
if method==None or name==None:
sys.exit(0)
else:
print u"\nFind method = %s name = %s\n"%(method[0],name[0])
except:
print u"\n自动分析失败!"
sys.exit(0)
00x9:
完整代码:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests,re,sys
import urllib3
urllib3.disable_warnings()
def req(url,xss):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
if method[0] == 'get' or 'GET':
req = requests.get(url=url+"?"+name[0]+"="+xss,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Get Xss url:%s payload:%s"%(url,xss)
sys.exit(1)
if method[0] == 'post' or 'POST':
data={name[0]:xss}
req = requests.post(url=url,data=data,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Post Xss url:%s payload:%s"%(url,xss)
sys.exit(1)
def html(url):
global method,name
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
method=re.findall(r'method="(.*?)"',str(form))
name = re.findall(r'name="(.*?)"', str(form))
try:
if method==None or name==None:
sys.exit(0)
else:
print u"\nFind method = %s name = %s\n"%(method[0],name[0])
except:
print u"\n自动分析失败!"
sys.exit(0)
if __name__ == '__main__':
url = raw_input('\nurl:')
if 'http' not in url:
url = 'http://'+url
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
html(url)
for x in xss:
req(url,x)
文章写到这里就结束了,但还是存在一些缺陷,比如表单有多个name,所以你需要去加载多个name,进行请求,这里就不修改了,仅抛砖引玉,希望你可以开发出自己的大项目!
留个关注再走叭~

我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
有没有一种简单的方法可以判断ruby脚本是否已经在运行,然后适本地处理它?例如:我有一个名为really_long_script.rb的脚本。我让它每5分钟运行一次。当它运行时,我想看看之前运行的是否还在运行,然后停止第二个脚本的执行。有什么想法吗? 最佳答案 ps是一种非常糟糕的方法,并且可能会出现竞争条件。传统的Unix/Linux方法是将PID写入文件(通常在/var/run中)并在启动时检查该文件是否存在。例如pid文件位于/var/run/myscript.pid然后你会在运行程序之前检查它是否存在。有一些技巧可以避免
我正在开发一个Ruby脚本,需要在没有Ruby解释器的情况下部署到系统上。它将需要在使用ELF格式的FreeBSD系统上运行。我知道有一个ruby2exe项目可以编译在Windows上运行的ruby脚本,但是在其他操作系统上这样做容易吗?甚至可能吗? 最佳答案 您是否检查过Rubinius或JRuby是否允许您预编译您的代码? 关于ruby-ruby脚本可以预编译成二进制文件吗?,我们在StackOverflow上找到一个类似的问题: https://
我使用rails3.1+rspec和factorygirl。我对必填字段(validates_presence_of)的验证工作正常。我如何让测试将该事实用作“成功”而不是“失败”规范是:describe"Addanindustrywithnoname"docontext"Unabletocreatearecordwhenthenameisblank"dosubjectdoind=Factory.create(:industry_name_blank)endit{shouldbe_invalid}endend但是我失败了:Failures:1)Addanindustrywithnona
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题