最小化的Hadoop已经可以满足学习过程中大部分需求,但是为了研究Hadoop集群运行机制,部署一个类生产的环境还是有必要的。因为集群机器比较少,笔者没有配置ssh,所以就需要在每一台机器上手动启动服务。启动上相对繁琐一些,优点是可以高度自定义集群中的任务节点数量,从而更好的理解集群中各个进程的作用。
笔者认为一个Hadoop集群管理着两种资源,计算资源(CPU和内存)与存储资源(数据存储)。所以就对应了两类服务,yarn和HDFS:
yarn resourcemanager:资源管理器,负责管理nodemanager、调度集群资源
yarn nodemanager:节点管理器,管理物理机器上的CPU和内存,一个集群可以有多个节点
HDFS namenode:HDFS namenode节点,管理文件系统元数据
HDFS datanode:HDFS datanode节点,存储文件数据块
historyserver:历史作业查询服务,用于查询已经结束的任务运行期间数据
yarn之后会进行介绍,这里只需要知道它和HDFS一样,有两种服务:resourcemanager和nodemanager,resourcemanager类似HDFS的namenode节点,nodemanager类似HDFS的datanode节点。
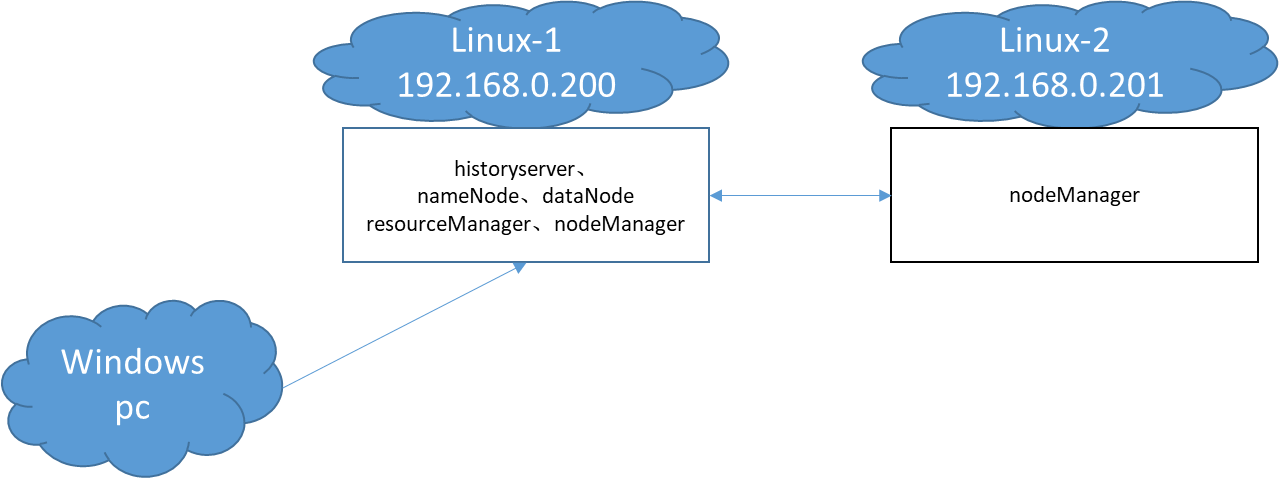
我的集群使用了2个虚拟机,debian系统,8G内存,并且安装了JDK1.8。这样我就有3台机器,分别是客户机Windows,Linux-1和Linux-2。Linux-1运行了集群全套的服务,Linux-2负责运行一个nodemanager节点,模拟被resourcemanager调度。
Linux-1和Linux-2的完整情况如下:
| Linux-1 | Linux-2 | |
|---|---|---|
| IP地址 | 192.168.0.200 | 192.168.0.201 |
| resourcemanager | 运行 | |
| nodemanager | 运行 | 运行 |
| namenode | 运行 | |
| datanode | 运行 | |
| historyserver | 运行 |
整个集群的网络需要能够互相访问,其他无特殊要求,系统拓扑如下:
一个配置文件结构如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.host}:8082/</value>
</property>
</configuration>
一个配置文件的根节点是configuration,一般包含多个property节点,而一个property节点就是一个配置参数。property节点有name和value两个属性,分别是配置名称和值。
如果存在多个同名的property节点,后一个property节点会覆盖前一个。property节点的value支持${}占位符,运行的时候占位符会被解析为实际的值。
Hadoop有上百个配置,分为默认配置和自定义配置两类。如果某个参数在自定义配置没有,则会加载默认配置,所以我们只需要在自定义配置中加入少量的参数就可以运行集群。
可以在以下网址查询到Hadoop的默认配置:
自定义配置位于Hadoop安装目录下的etc/hadoop下,对应的4个自定义配置文件,名称分别为core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
从https://hadoop.apache.org/releases.html下载Hadoop程序。这里我下载的是2.10.2。分别解压到Linux-1和Linux-2上,解压后程序目录如下:
drwxr-xr-x 2 debian debian 4096 5月 25 2022 bin
drwxr-xr-x 3 debian debian 4096 5月 25 2022 etc
drwxr-xr-x 2 debian debian 4096 5月 25 2022 include
drwxr-xr-x 3 debian debian 4096 5月 25 2022 lib
drwxr-xr-x 2 debian debian 4096 5月 25 2022 libexec
-rw-r--r-- 1 debian debian 106210 5月 25 2022 LICENSE.txt
drwxr-xr-x 3 debian debian 4096 2月 4 17:05 logs
-rw-r--r-- 1 debian debian 15830 5月 25 2022 NOTICE.txt
-rw-r--r-- 1 debian debian 1366 5月 25 2022 README.txt
drwxr-xr-x 3 debian debian 4096 5月 25 2022 sbin
drwxr-xr-x 4 debian debian 4096 5月 25 2022 share
etc/hadoop为程序配置文件存放配置,我们需要在每一个节点创建4个文件core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml。
笔者的配置完整内容如下:
my.host需要配置成当前主机实际的地址。my.namenode.host、my.resourcemanager.host、my.jobhistory.host分别配置为:HDFS namenode运行地址、yarn资源管理器运行地址、历史作业查询服务jobhistory运行地址。这里提一下fs.defaultFS,它的含义是HDFS的namenode地址,HDFS的datanode通过这个地址来发现namenode,同时这个地址也是默认文件系统地址,用于解析相对的文件路径。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 当前主机地址,修改成Linux-1或Linux-2实际的IP地址 -->
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<!-- dfs namenode所在地址 -->
<property>
<name>my.namenode.host</name>
<value>192.168.0.200</value>
</property>
<!-- yarn 资源管理器所在地址 -->
<property>
<name>my.resourcemanager.host</name>
<value>192.168.0.200</value>
</property>
<!-- 作业历史所在地址 -->
<property>
<name>my.jobhistory.host</name>
<value>192.168.0.200</value>
</property>
<!-- 文件系统地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.namenode.host}:8082/</value>
</property>
</configuration>
yarn中机器ip的配置大多数继承于core-site.xml,所以可以直接分发这个文件到各个机器上,唯一需要注意的是yarn.nodemanager.local-dirs参数,这个目录用于存放任务运行过程中的临时文件,通常需要大一点。
<?xml version="1.0"?>
<configuration>
<!-- 资源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>${my.resourcemanager.host}</value>
</property>
<!-- 资源管理器绑定地址 -->
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 节点管理器地址 -->
<property>
<name>yarn.nodemanager.hostname</name>
<value>${my.host}</value>
</property>
<!-- 节点管理器绑定地址 -->
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 节点管理器临时文件存放路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data1/debian/hadoop-data/nodemanager-local-data</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 节点管理器运行容器最大内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4000</value>
</property>
<!-- 节点管理器单个容器分配最大内存 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3000</value>
</property>
</configuration>
mapred-site.xml配置只需要配置历史作业查询服务jobhistory运行地址,笔者的这个配置文件参数也来源于core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 历史任务IPC地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>${my.jobhistory.host}:10020</value>
</property>
<!-- 历史任务web服务地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>${my.jobhistory.host}:19888</value>
</property>
</configuration>
这个配置文件用于控制HDFS的namenode和datanode节点数据存放路径,dfs.namenode.checkpoint.dir控制namenode数据持久化目录,之前提到的HDFS文件系统中的文件元数据就保存在这里。dfs.datanode.data.dir为数据块存放路径,HDFS中的数据块就存放在这里。
这里并没有配置namenode所在地址,datanode是通过core-site.xml的fs.defaultFS中配置的地址寻找namenode的
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 配置namenode数据存储目录 多个逗号分割-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data1/debian/hadoop-data/namenode-data</value>
</property>
<!-- 配置辅助namenode数据存储目录 多个逗号分割-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data1/debian/hadoop-data/namenode-checkpoint-data</value>
</property>
<!-- namenode rpc绑定主机地址 -->
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 配置datanode数据存储目录 多个逗号分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1/debian/hadoop-data/datanode-data</value>
</property>
<!-- 数据副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
一个新的HDFS的namenode类似新硬盘,使用前需要先格式化(初始化数据文件),datanode节点不需要这个操作。一个HDFS的容量大小取决于datanode节点数量,所以也不需要设置HDFS的容量。
在namenode运行的节点,使用如下命令初始化HDFS的数据目录:
bin/hdfs namenode -format
运行完成后在dfs.namenode.name.dir配置的目录会生成namenode所需要的数据文件,里面有一个文件夹current,由于笔者HDFS节点已经运行过一段时间了,所以current中的内容如下:
debian@debian:/data1/debian/hadoop-data/namenode-data$ pwd
/data1/debian/hadoop-data/namenode-data
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll
总用量 8
drwxr-xr-x 2 debian debian 4096 2月 4 15:27 current
-rw-r--r-- 1 debian debian 10 2月 4 15:27 in_use.lock
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll current/
总用量 15396
-rw-r--r-- 1 debian debian 1048576 1月 22 14:20 edits_0000000000000000001-0000000000000000001
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000002-0000000000000000002
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000003-0000000000000000003
-rw-r--r-- 1 debian debian 1048576 1月 22 14:29 edits_0000000000000000004-0000000000000000004
-rw-r--r-- 1 debian debian 1048576 1月 24 17:47 edits_0000000000000000005-0000000000000000048
-rw-r--r-- 1 debian debian 1048576 1月 24 18:03 edits_0000000000000000049-0000000000000000061
-rw-r--r-- 1 debian debian 1048576 1月 28 10:01 edits_0000000000000000062-0000000000000000170
-rw-r--r-- 1 debian debian 1048576 2月 2 17:01 edits_0000000000000000171-0000000000000000171
-rw-r--r-- 1 debian debian 1048576 2月 2 21:18 edits_0000000000000000172-0000000000000000482
-rw-r--r-- 1 debian debian 1048576 2月 2 22:32 edits_0000000000000000483-0000000000000000866
-rw-r--r-- 1 debian debian 1048576 2月 2 22:45 edits_0000000000000000867-0000000000000000867
-rw-r--r-- 1 debian debian 1048576 2月 2 23:09 edits_0000000000000000868-0000000000000001143
-rw-r--r-- 1 debian debian 1048576 2月 3 10:50 edits_0000000000000001144-0000000000000001382
-rw-r--r-- 1 debian debian 1048576 2月 4 00:39 edits_0000000000000001383-0000000000000001620
-rw-r--r-- 1 debian debian 1048576 2月 4 17:07 edits_inprogress_0000000000000001621
-rw-r--r-- 1 debian debian 8109 2月 4 00:01 fsimage_0000000000000001382
-rw-r--r-- 1 debian debian 62 2月 4 00:01 fsimage_0000000000000001382.md5
-rw-r--r-- 1 debian debian 10696 2月 4 15:27 fsimage_0000000000000001620
-rw-r--r-- 1 debian debian 62 2月 4 15:27 fsimage_0000000000000001620.md5
-rw-r--r-- 1 debian debian 5 2月 4 15:27 seen_txid
-rw-r--r-- 1 debian debian 214 2月 4 15:27 VERSION
进入Hadoop安装目录下的sbin文件夹,主要有3个脚本文件,用于启停集群中各种守护进程,它们分别是
hadoop-daemon.sh
启停HDFS的namenode和datanode,它还有多主机的启停版本hadoop-daemons.sh
yarn-daemon.sh
启停yarn的资源管理器和节点管理器,它还有多主机的启停版本yarn-daemons.sh
mr-jobhistory-daemon.sh
启停历史任务管理服务historyserver
在Linux-1机器上运行如下命令
-- 启动namenode
sbin/hadoop-daemon.sh start namenode
-- 启动datanode
sbin/hadoop-daemon.sh start datanode
使用jps命令可以看到两个进程
debian@debian:~/program/hadoop-2.10.2$ jps
676 NameNode
7846 Jps
733 DataNode
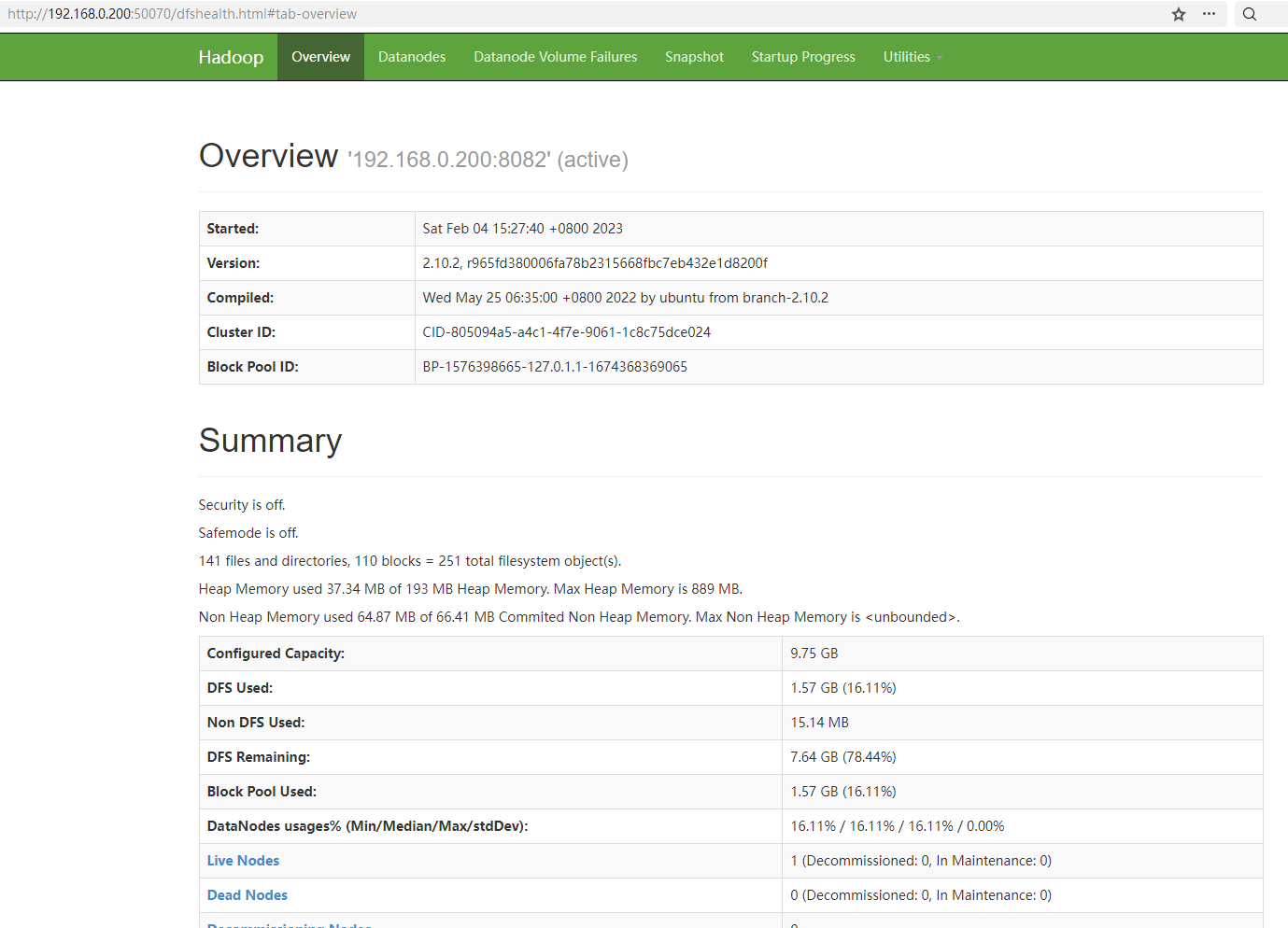
在windows物理机的浏览器输入http://192.168.0.200:50070/可访问HDFS的web管理页面,笔者的显示如下:
在Linux-1上输入如下命令启动yarn resourcemanager
-- 启动yarn resourcemanager
sbin/yarn-daemon.sh start resourcemanager
然后在Linux-1和Linux-2启动yarn nodemanager
-- 启动yarn nodemanager
sbin/yarn-daemon.sh start nodemanager
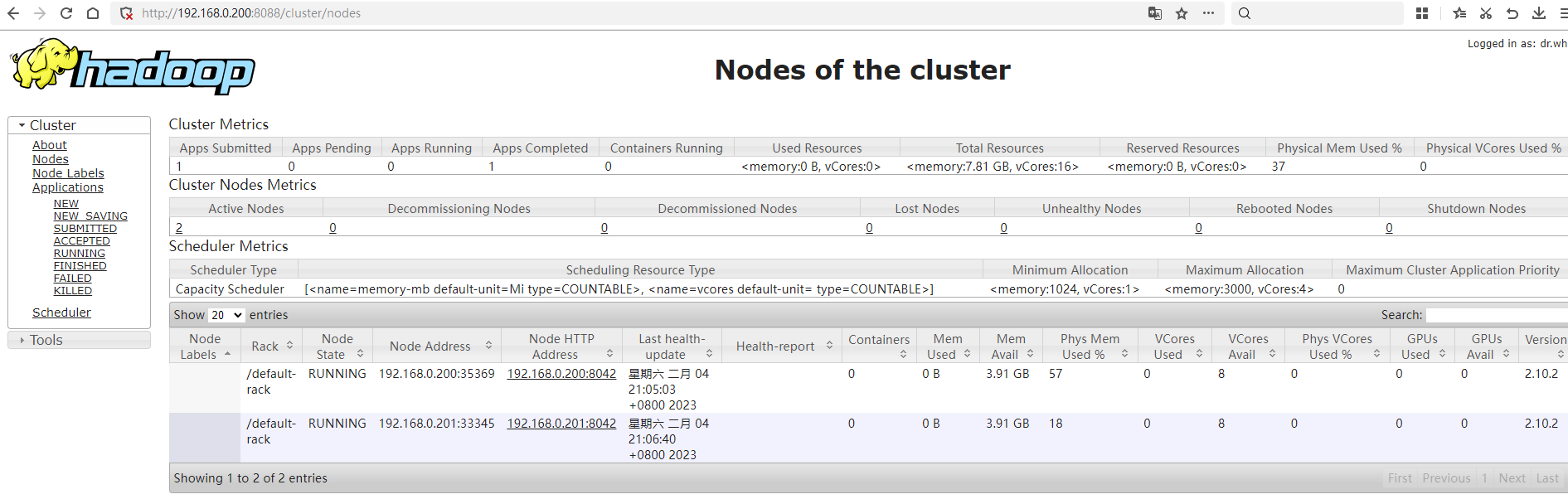
访问yarn的web管理地址http://192.168.0.200:8088/,可以看到当前集群下有两个资源管理器
在Linux-1运行如下命令启动:
sbin/mr-jobhistory-daemon.sh start historyserver
访问可以看到http://192.168.0.200:19888,如下界面:

本文所有的代码放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop 。本节需要用到的模块是maxSaleMapReduce。任务用到的数据文件可以用common模块中的SaleDataGenerator可以生成。
为了让任务运行在Hadoop集群上,我们需要编写一个配置文件cluster-config.xml。需要注意的是yarn.resourcemanager.hostname配置,很多书籍或其他资料配置的是yarn.resourcemanager.address,因为笔者提交作业是在windows上提交的,作业使用的配置是Hadoop默认配置,如果不配置yarn.resourcemanager.hostname,那么yarn.resourcemanager.resource-tracker.address的值就是0.0.0.0:8031(默认${yarn.resourcemanager.hostname}:8031),导致ApplicationMasters进程无法连上yarn resourcemanager。
如果需要跨平台,也就是提交作业的系统和集群运行的系统不一样,需要把mapreduce.app-submission.cross-platform配置成true
其他的配置就没什么特别的了,fs.defaultFS配置成HDFS的namenode的地址。mapreduce执行框架配置成yarn
完整内容如下:
<configuration>
<!-- 跨平台提交 -->
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<!-- 文件系统地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.200:8082/</value>
</property>
<!-- 资源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.200</value>
</property>
<!-- 执行框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- map任务数量 -->
<property>
<name>mapreduce.job.maps</name>
<value>5</value>
</property>
</configuration>
任务用到的数据文件可以用common包中的SaleDataGenerator生成,把生成数据文件传到HDFS上的/input目录上,可以用Hadoop的fs命令上传。
hadoop fs -copyFromLocal file-0 hdfs://192.168.0.200:8082/input/file-0
hadoop fs -copyFromLocal file-1 hdfs://192.168.0.200:8082/input/file-1
hadoop fs -copyFromLocal file-2 hdfs://192.168.0.200:8082/input/file-2
hadoop fs -copyFromLocal file-3 hdfs://192.168.0.200:8082/input/file-3
hadoop fs -copyFromLocal file-4 hdfs://192.168.0.200:8082/input/file-4
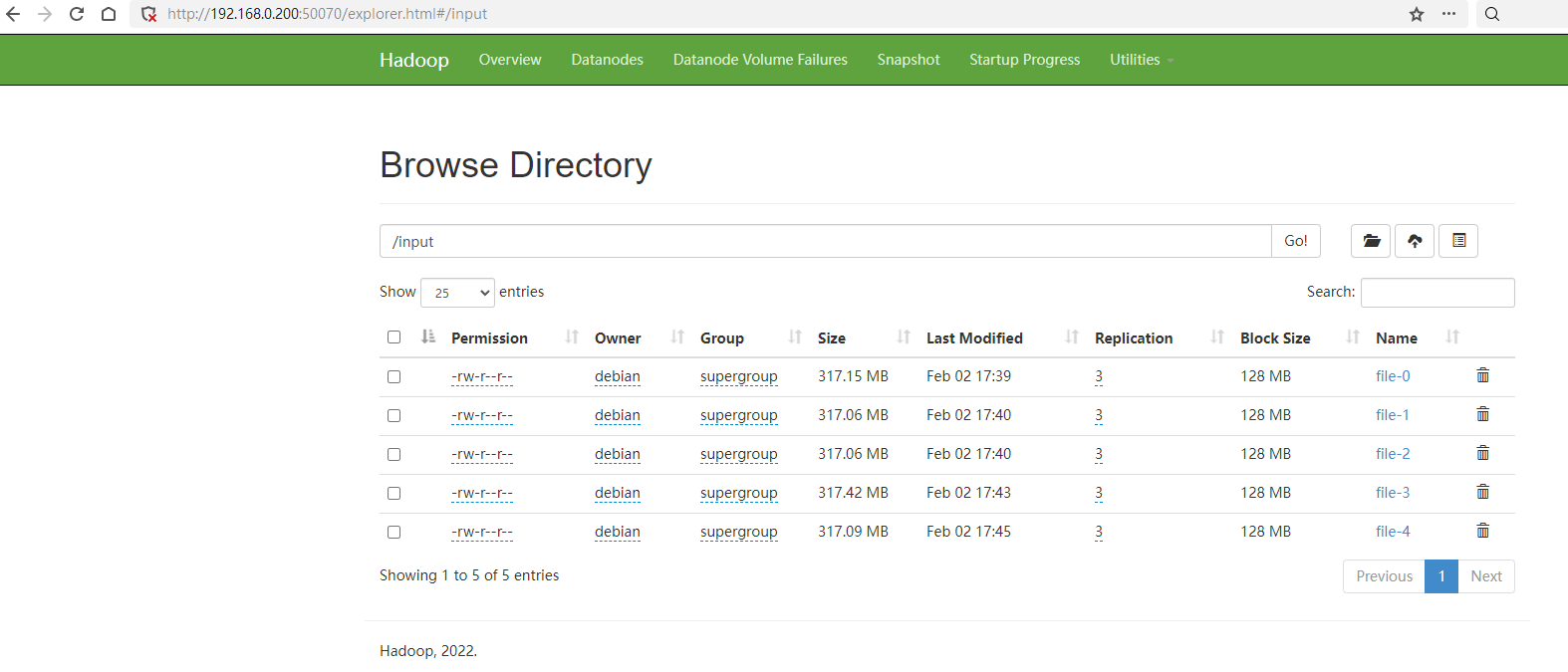
上传完成后可以在HDFS的管理页面中看到文件:
输入命令启动作业:
hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar -conf cluster-config.xml -libjars ./lib/common-1.0-SNAPSHOT.jar /input /output
命令最后的input和output参数分别是数据输入目录和输出目录,由于是相对路径,会自动使用fs.defaultFS配置进行填充,所以相当于hdfs://192.168.0.200:8082/input和hdfs://192.168.0.200:8082/output。
命令执行如下:
C:\Users\l3789\Desktop\新建文件夹>hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar -conf cluster-config.xml -libjars ./lib/common-1.0-SNAPSHOT.jar /input /output
23/02/04 21:27:31 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032
23/02/04 21:27:41 INFO input.FileInputFormat: Total input files to process : 5
23/02/04 21:27:41 INFO mapreduce.JobSubmitter: number of splits:15
23/02/04 21:27:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1675501509686_0002
23/02/04 21:27:42 INFO conf.Configuration: resource-types.xml not found
23/02/04 21:27:42 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/02/04 21:27:42 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
23/02/04 21:27:42 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
23/02/04 21:27:42 INFO impl.YarnClientImpl: Submitted application application_1675501509686_0002
23/02/04 21:27:42 INFO mapreduce.Job: The url to track the job: http://192.168.0.200:8088/proxy/application_1675501509686_0002/
23/02/04 21:27:42 INFO mapreduce.Job: Running job: job_1675501509686_0002
23/02/04 21:27:46 INFO mapreduce.Job: Job job_1675501509686_0002 running in uber mode : false
23/02/04 21:27:46 INFO mapreduce.Job: map 0% reduce 0%
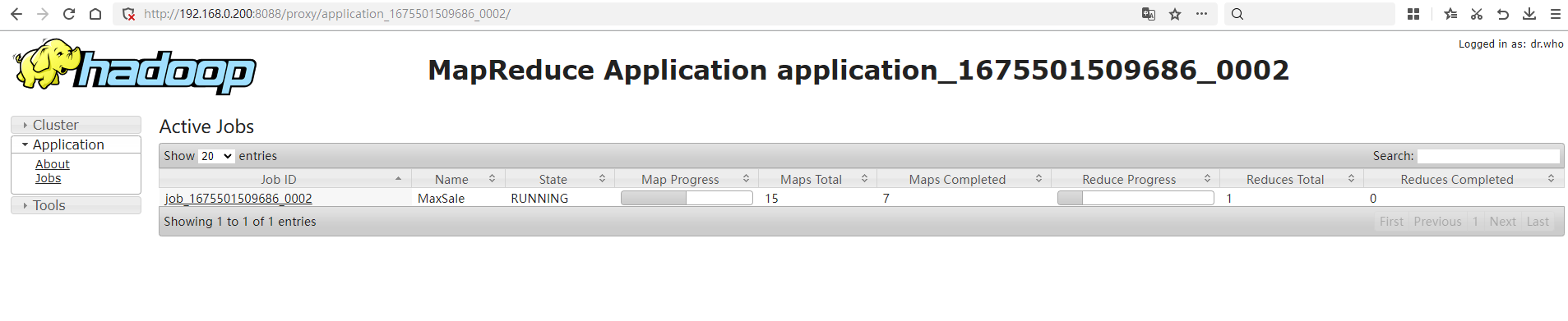
可以访问http://192.168.0.200:8088/proxy/application_1675501509686_0002/查看任务运行情况:
上传文件到HDFS提示copyFromLocal: Permission denied
这个是因为hadoop命令获取到用户与HDFS上的权限不符,修改环境变量更改运行用户,然后重新执行命令:
-- windows
set HADOOP_USER_NAME=debian
-- linux
export HADOOP_USER_NAME=debian
运行MapReduce作业提示无读写权限
23/02/04 21:34:34 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=test, access=EXECUTE, inode="/tmp":debian:supergroup:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:350)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:311)
/tmp存放任务运行的历史结果,供historyserver使用。运行任务的用户无写入权限,把这个目录设置成所有人可写,或者修改运行用户为/tmp目录的用户
修改环境变量更改运行用户,然后重新执行命令:
-- windows
set HADOOP_USER_NAME=debian
-- linux
export HADOOP_USER_NAME=debian
运行任务状态一直卡在,任务日志报org.apache.hadoop.ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8031
这个问题卡了我好久,MapReduce任务的ApplicationMasters进程无法连上yarn resourcemanager。根本原因是提交任务的机器使用的yarn.resourcemanager.resource-tracker.address配置是默认的,需要在任务的配置文件中加入yarn.resourcemanager.address配置
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象