前几天有个朋友问我“了不了解关于手机硬件加速方面的知识?”,嗯?其实我也想知道。。。

于是笔者就去网上搜罗了文章再结合自己对源码的理解,总结了这篇关于硬件加速的理解。
关于屏幕绘制前面文章《"一文读懂"系列:Android屏幕刷新机制》已经做了一个全局的介绍,本篇来讲解下屏幕绘制中的硬件加速。
手机开发中最重要的两个点:
早期的Android系统这两个事件都是在主线程上执行,导致用户点击的时候,界面绘制停滞或者界面绘制的时候,用户点击半天不响应,体验性很差。
于是在4.0以后,以 “run fast, smooth, and responsively” 为核心目标对 UI 进行了优化,应用开启了硬件加速对UI进行绘制。
在之前文章中我们分析过,Android 屏幕的绘制流程分为两部分:
1.生产者:app侧将View渲染到一个buffer中,供SurfaceFlinger消费2.消费者:SurfaceFlinger测将多个buffer合并后放入buffer中,供屏幕显示
其中 第二步一直都是在GPU中实现的,而我们所说的硬件加速就是第一步中的view渲染流程。
早期view的渲染是在主线程中进行的,而硬件加速则使用一个新的线程RenderThread以及硬件GPU进行渲染,
CPU和GPU结构对比:
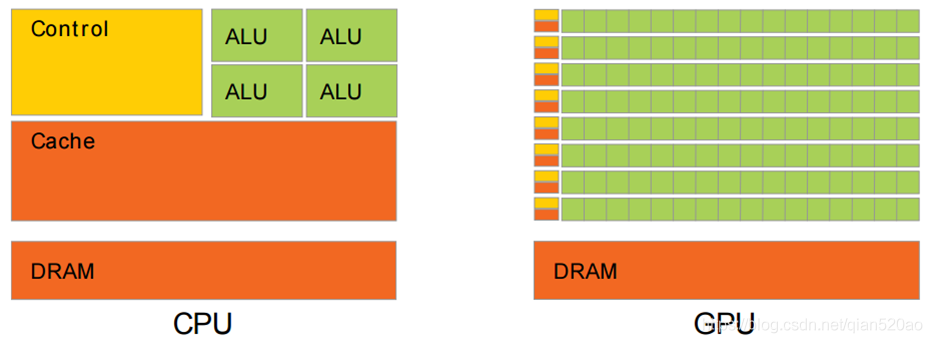
1.结构上看:CPU的ALU较少,而了解过OpenGl的同学应该知道View的渲染过程中是有大量的浮点数计算的,而浮点数转换为整数计算,可能会消耗大量的ALU单元,这对于CPU是比较难接受的。
2.CPU是串行的,一个CPU同一时间只能做一件事情,(多线程其实也是将CPU时间片分割而已),而GPU内部使用的是几千个小的GPU内核,每个GPU内核处理单元都是并行的,
这就非常符合图形的渲染过程。
GPU是显卡的核心部分,在破解密码方面也非常出色,再知道为啥哪些挖矿的使用的是显卡而不是CPU了吧,一个道理。
硬件加速底层原理:
通过将计算机不擅长的图形计算指令使用特殊的api转换为GPU的专用指令,由GPU完成。这里可能是传统的OpenGL或其他开放语言。
Android端一般使用OpenGL ES来实现硬件加速。
这里简单介绍下OpenGL和OpenGL ES。
如果一个设备支持GPU硬件加速渲染(有可能不支持,看GPU厂商是不是适配了OpenGL 等接口),
那么当Android应用程序调用Open GL接口来绘制UI时,Android应用程序的 UI 就是通过GPU进行渲染的。
在介绍Android图像系统架构前,我们先来了解几个概念:如果把UI的绘制过程当成一幅画的制作过程:
那么:
1.画笔:
2.画纸:
Surface:所有的绘制和渲染都是在这张画纸上进行,每个窗口都是一个DecorView的容器,同时每个窗口都关联一个Surface
3.画板:
Graphic Buffer :Graphic Buffer是谷歌在4.1以后针对双缓冲的jank问题提出的第三个缓冲,CPU/GPU渲染的内容都将写到这个buffer上。
4.合成
SurfaceFlinger:将所有的Surface合并叠加后显示到一个buffer里面。
简单理解过程:我们使用画笔(Skia、Open GL ES)将内容画到画纸(Surface)中,这个过程可能使用OpenGl ES也可能使用Skia,
使用OpenGl ES表示使用了硬件加速绘制,使用Skia,表示使用的是纯软件绘制。
下面是Android 图形系统的整体架构:
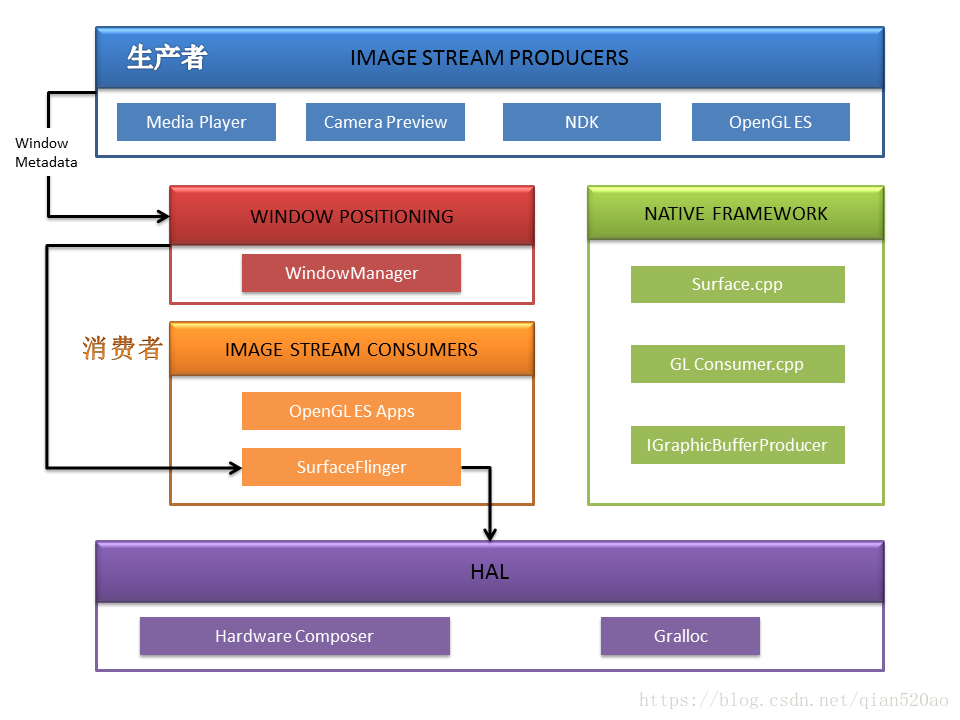
Image Stream Producers:图像数据流生产者,图像或视频数据最终绘制到Surface中。
WindowManager :前面一篇文章《WindowManager体系(上)》笔者说过,每个Surface都有一个Window和他一一对应,而WindowManager则用来管理窗口的各个方面:
动画,位置,旋转,层序,生命周期等。
SurfaceFlinger:用来对渲染后的Surface进行合并,并传递给硬件抽象层处理。
HWC : Hardware Composer,SurfaceFlinger 会委派一些合成的工作给 Hardware Composer 以此减轻 GPU 的负载。这样会比单纯通过 GPU 来合成消耗更少的电量。
Gralloc(Graphics memory allocator):前面讲解的Graphic Buffer分配的内存。
前面讲解了那么多理论知识,下面从源码角度来分析下硬件加速和软件绘制过程。
“read the fking source”
在前面文章《》中分析过。View最终是在ViewRootImpl的performDraw方法最新渲染的,
而performDraw内部调用的是draw方法。
定位到draw方法:
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {//1
...
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);//2
}else {
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {//3
return;
}
}
}
}
注释1:如果mThreadedRenderer不为null且isEnabled为true,则调用注释2处的mThreadedRenderer.draw,这个就是硬件绘制的入口
如果其他情况,则调用注释3处的drawSoftware,这里就是软件绘制的入口,再正式对软硬件绘制进行深入之前我们看下mAttachInfo.mThreadedRenderer是在哪里赋值的?
源码全局搜索下:我们发现ViewRootImpl的enableHardwareAcceleration方法中有创建mThreadedRenderer的操作。
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
// Try to enable hardware acceleration if requested
...
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
//这里如果attrs.flags设置了WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,则表示该Window支持硬件加速绘制
if (hardwareAccelerated) {
// Persistent processes (including the system) should not do
// accelerated rendering on low-end devices. In that case,
// sRendererDisabled will be set. In addition, the system process
// itself should never do accelerated rendering. In that case, both
// sRendererDisabled and sSystemRendererDisabled are set. When
// sSystemRendererDisabled is set, PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED
// can be used by code on the system process to escape that and enable
// HW accelerated drawing. (This is basically for the lock screen.)
//Persistent的应用进程以及系统进程不能使用硬件加速
final boolean fakeHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FAKE_HARDWARE_ACCELERATED) != 0;
final boolean forceHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED) != 0;
if (fakeHwAccelerated) {
mAttachInfo.mHardwareAccelerationRequested = true;
} else if (!ThreadedRenderer.sRendererDisabled
|| (ThreadedRenderer.sSystemRendererDisabled && forceHwAccelerated)) {
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mThreadedRenderer.destroy();
}
...
//这里创建了mAttachInfo.mThreadedRenderer
mAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent,
attrs.getTitle().toString());
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
}
}
}
这里源码告诉我们:
再看哪里调用enableHardwareAcceleration方法?
通过源码查找我们注意到ViewRootImpl的setView方法中:
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
//注释1
if (view instanceof RootViewSurfaceTaker) {
mSurfaceHolderCallback =
((RootViewSurfaceTaker)view).willYouTakeTheSurface();
if (mSurfaceHolderCallback != null) {
mSurfaceHolder = new TakenSurfaceHolder();
mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);
mSurfaceHolder.addCallback(mSurfaceHolderCallback);
}
}
...
// If the application owns the surface, don't enable hardware acceleration
if (mSurfaceHolder == null) {//注释2
enableHardwareAcceleration(attrs);
}
}
注释1处:表示当前view实现了RootViewSurfaceTaker接口,且view的willYouTakeTheSurface返回的mSurfaceHolderCallback不为null,
则表示应用想自己接管所有的渲染操作,这样创建出来的Activity窗口就类似于一个SurfaceView一样,完全由应用程序自己来控制它的渲染
基本上我们是不会将一个Activity窗口当作一个SurfaceView来使用的,
因此在ViewRootImpl类的成员变量mSurfaceHolder将保持为null值,
这样就会导致ViewRootImpl类的成员函数enableHardwareAcceleration被调用为判断是否需要为当前创建的Activity窗口启用硬件加速渲染。
好了我们回到ViewRootImpl的draw方法:
软件绘制调用的是drawSoftware方法。
进入
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
...
canvas = mSurface.lockCanvas(dirty);//1
mView.draw(canvas);//2
surface.unlockCanvasAndPost(canvas);//3
}
软件绘制基本就分三步走:
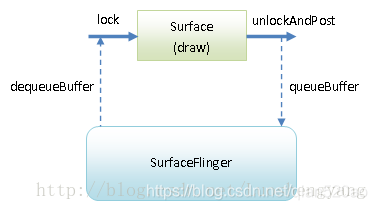
并且向SurfaceFlinger Dequeue了一块Graphic buffer,绘制的内容都会输出到这个buffer中,供SurfaceFlinger合成使用。
步骤2:draw:调用了View的draw方法,这个就会调用到我们自定义组件中View的onDraw方法,传入1中创建的Canvas对象,使用Skia api对图像进行绘制。
步骤3:unlockCanvasAndPost:绘制完成后,通知SurfaceFlinger绘制完成,可以进行buffer的交换,显示到屏幕上了,本质是给SurfaceFlinger queue 一个Graphic buffer、
关于什么是Queue和Dequeue看下图:
软件绘制条形简图:
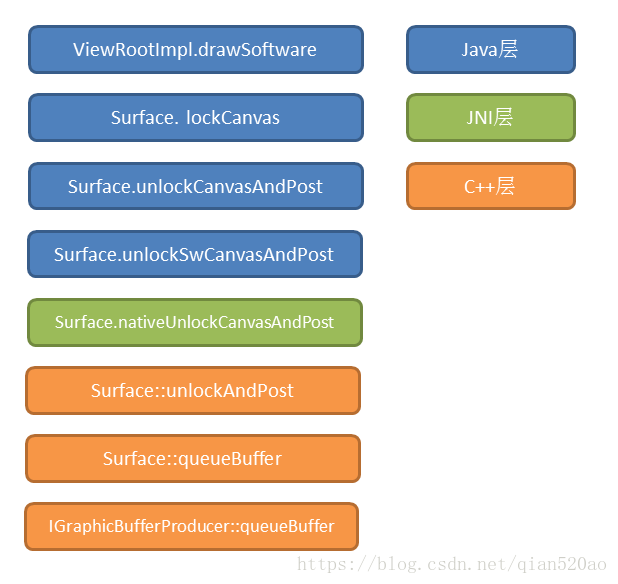
硬件加速分为两个步骤:
这个阶段用于遍历所有的视图,将需要绘制的Canvas API调用及其参数记录下来,保存在一个Display List,这个阶段发生在CPU主线程上。
Display List本质上是一个缓存区,它里面记录了即将要执行的绘制命令序列,这些命令最终会在绘制阶段被OpenGL转换为GPU渲染指令。
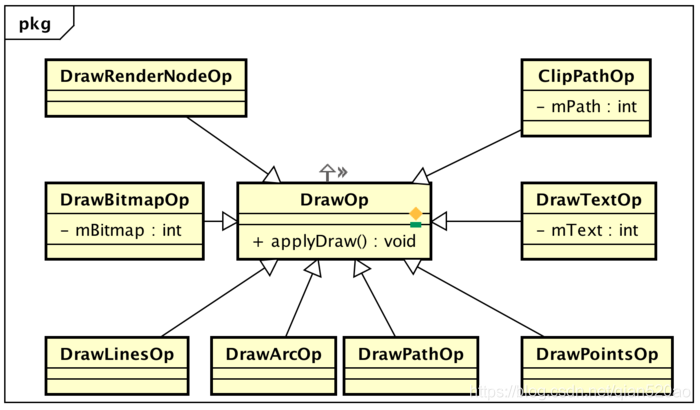
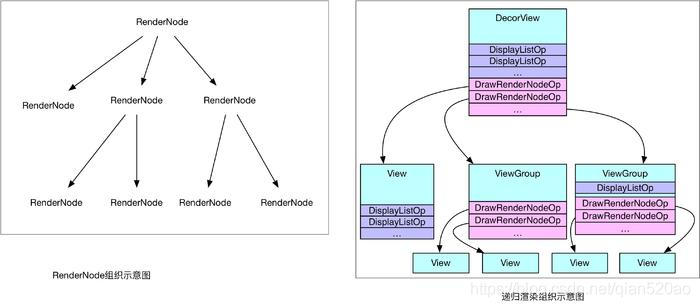
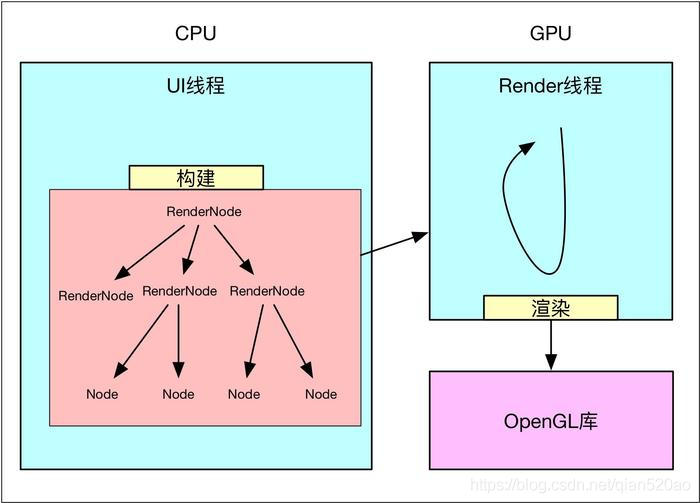
视图构建阶段会将每个View抽象为一个RenderNode,每个View的绘制操作抽象为一系列的DrawOp,
比如:
View的drawLine操作会被抽象为一个DrawLineOp,drawBitmap操作会被抽象成DrawBitmapOp,每个子View的绘制被抽象成DrawRenderNodeOp,每个DrawOp都有对应的OpenGL绘制指令,同时内部也握有需要绘制的数据元。
使用Display List的好处:
Display List模型图:
接下来我们从源码角度来看下:
前面我们分析了硬件加速入口是在ThreadedRenderer的draw方法:
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this)
进入这个方法看看:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2通知RenderThread线程绘制
}
ThreadedRenderer主要作用就是在主线程CPU中视图的构建,然后通知RenderThread使用OpenGL进行视图的渲染(注释2处)。
注释1处:updateRootDisplayList看名称应该就是用于视图构建,进去看看
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
//1.构建参数view(DecorView)视图的Display List
updateViewTreeDisplayList(view);
//2
//mRootNodeNeedsUpdate true表示需要更新视图
//mRootNode.isValid() 表示已经构建了Display List
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
//获取DisplayListCanvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);//3
try {
//ReorderBarrie表示会按照Z轴坐标值重新排列子View的渲染顺序
canvas.insertReorderBarrier();
//构建并缓存所有的DrawOp
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
canvas.restoreToCount(saveCount);
} finally {
//将所有的DrawOp填充到根RootNode中,作为新的Display List
mRootNode.end(canvas);
}
}
}
注释1:updateViewTreeDisplayList对View树Display List进行构建
private void updateViewTreeDisplayList(View view) {
view.mPrivateFlags |= View.PFLAG_DRAWN;
view.mRecreateDisplayList = (view.mPrivateFlags & View.PFLAG_INVALIDATED)
== View.PFLAG_INVALIDATED;
view.mPrivateFlags &= ~View.PFLAG_INVALIDATED;
view.updateDisplayListIfDirty();
view.mRecreateDisplayList = false;
}
看View的updateDisplayListIfDirty方法。
/**
* Gets the RenderNode for the view, and updates its DisplayList (if needed and supported)
* @hide
*/
@NonNull
public RenderNode updateDisplayListIfDirty() {
//获取当前mRenderNode
final RenderNode renderNode = mRenderNode;
//2.判断是否需要进行重新构建
if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0
|| !renderNode.isValid()
|| (mRecreateDisplayList)) {
if (renderNode.isValid()
&& !mRecreateDisplayList) {
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
//这里用于当前View是ViewGroup,且自身不需要重构,对其子View的DisplayList进行构建
dispatchGetDisplayList();
return renderNode; // no work needed
}
...
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
//软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
...
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
//View是ViewGroup,需要绘制子View
dispatchDraw(canvas);
...
} else {
draw(canvas);
}
}
} finally {
//将绘制好后的数据填充到renderNode中去
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
}
updateDisplayListIfDirty主要作用:
判断是否需要进行重新构建的条件如下:
mRenderNode在View的构造方法中初始化:
public View(Context context) {
...
mRenderNode = RenderNode.create(getClass().getName(), this);
}
构建过程如下:
通过上面几个步骤就将View树对应的DisplayList构建好了。而且这个构建过程会递归构建子View的Display List
我们从绘制流程火焰图中也可以看到大概流程:
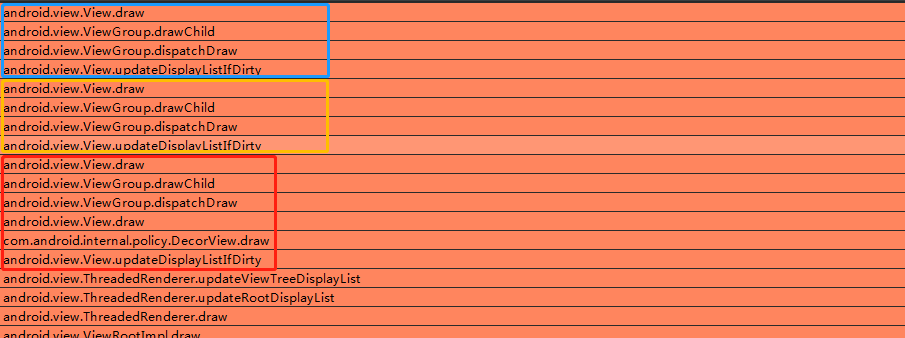
红色框中部分:是绘制的DecorView的时候,一直递归updateDisplayListIfDirty方法进行Display List的构建
其他颜色框部分是子View Display List的构建
这个阶段会调用OpenGL接口将构建好视图进行绘制渲染,将渲染好的内容保存到Graphic buffer中,并提交给SurfaceFlinger。
回到ThreadedRenderer的draw方法:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2
}
在注释1中创建好视图对应的Display List后,在注释2处调用nSyncAndDrawFrame方法通知RenderThread线程进行绘制
nSyncAndDrawFrame是一个native方法,在讲解nSyncAndDrawFrame方法前我们先来看ThreadedRenderer构造函数中做了哪些事。
ThreadedRenderer(Context context, boolean translucent, String name) {
//这个方法在native层创建RootRenderNode对象并返回对象的地址
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
//这个方法在native层创建一个RenderProxy
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
}
nCreateRootRenderNode和nCreateProxy方法在android_view_ThreadedRenderer.cpp中实现:
static jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) {
RootRenderNode* node = new RootRenderNode(env);
node->incStrong(0);
node->setName("RootRenderNode");
return reinterpret_cast<jlong>(node);
}
static jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz,
jboolean translucent, jlong rootRenderNodePtr) {
RootRenderNode* rootRenderNode = reinterpret_cast<RootRenderNode*>(rootRenderNodePtr);
ContextFactoryImpl factory(rootRenderNode);
return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);
}
RenderProxy构造方法:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())//1
, mContext(nullptr) {
...
}
注意到mRenderThread使用的是RenderThread::getInstance()单例线程,也就说整个绘制过程只有一个RenderThread线程。
接着看RenderThread::getInstance()创建线程的方法:
RenderThread::RenderThread() : Thread(true)
...
Properties::load();
mFrameCallbackTask = new DispatchFrameCallbacks(this);
mLooper = new Looper(false);
run("RenderThread");
}
居然也是使用的Looper,是不是和我们的主线程的消息机制一样呢?哈哈
调用run方法会执行RenderThread的threadLoop方法。
bool RenderThread::threadLoop() {
...
int timeoutMillis = -1;
for (;;) {
int result = mLooper->pollOnce(timeoutMillis);
...
nsecs_t nextWakeup;
{
...
while (RenderTask* task = nextTask(&nextWakeup)) {
workQueue.push_back(task);
}
for (auto task : workQueue) {
task->run();
// task may have deleted itself, do not reference it again
}
}
if (nextWakeup == LLONG_MAX) {
timeoutMillis = -1;
} else {
nsecs_t timeoutNanos = nextWakeup - systemTime(SYSTEM_TIME_MONOTONIC);
timeoutMillis = nanoseconds_to_milliseconds(timeoutNanos);
if (timeoutMillis < 0) {
timeoutMillis = 0;
}
}
if (mPendingRegistrationFrameCallbacks.size() && !mFrameCallbackTaskPending) {
...
requestVsync();
}
if (!mFrameCallbackTaskPending && !mVsyncRequested && mFrameCallbacks.size()) {
...
requestVsync();
}
}
return false;
}
石锤了就是应用程序主线程的消息机制模型,
这里做个小结:
ThreadedRenderer构造方法中
好了回头看nSyncAndDrawFrame的native方法
nSyncAndDrawFrame同样也在android_view_ThreadedRenderer.cpp中实现:
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) {
LOG_ALWAYS_FATAL_IF(frameInfoSize != UI_THREAD_FRAME_INFO_SIZE,
"Mismatched size expectations, given %d expected %d",
frameInfoSize, UI_THREAD_FRAME_INFO_SIZE);
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
return proxy->syncAndDrawFrame();
}
这个方法返回值是proxy->syncAndDrawFrame(),进入RenderProxy的syncAndDrawFrame方法:
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}
这里的 mDrawFrameTask.drawFrame其实就是向RenderThread的TaskQueue添加一个drawFrame渲染任务,通知RenderThread渲染UI视图。
如下图:
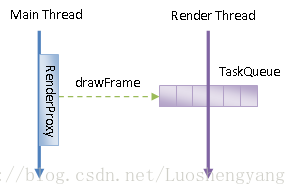
mDrawFrameTask是DrawFrameTask中的函数
int DrawFrameTask::drawFrame() {
...
postAndWait();
return mSyncResult;
}
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue(this);
mSignal.wait(mLock);//锁住等待锁释放
}
void RenderThread::queue(RenderTask* task) {
AutoMutex _lock(mLock);
mQueue.queue(task);
if (mNextWakeup && task->mRunAt < mNextWakeup) {
mNextWakeup = 0;
mLooper->wake();
}
}
看到这就知道了drawFrame其实就是往RenderThread线程的任务队列mQueue中按时间顺序加入一个绘制task,并调用mLooper->wake()唤醒RenderThread线程处理。
说到底还是主线程消息机制那套东西。
注意DrawFrameTask在postAndWait的mRenderThread->queue(this)中是将this传入任务队列,所以此任务就是this自己。后面执行绘制任务就使用到了OpenGL对构建好的DisplayList进行渲染。
经过上面的分析,整个硬件绘制流程就有个清晰模型了
点到为止,后面代码大家可以自行找到源码阅读。
绘制阶段这块可能比较复杂些,因为基本上都是native层的东西,有的消化下。
| 渲染场景 | 纯软件绘制 | 硬件加速 | 加速效果分析 |
|---|---|---|---|
| 页面初始化 | 绘制所有View | 创建所有DisplayList | GPU分担了复杂计算任务 |
| 在一个复杂页面调用背景透明TextView的setText(),且调用后其尺寸位置不变 | 重绘脏区所有View | TextView及每一级父View重建DisplayList | 重叠的兄弟节点不需CPU重绘,GPU会自行处理 |
| TextView逐帧播放Alpha / Translation / Scale动画 | 每帧都要重绘脏区所有View | 除第一帧同场景2,之后每帧只更新TextView对应RenderNode的属性 | 刷新一帧性能极大提高,动画流畅度提高 |
| 修改TextView透明度 | 重绘脏区所有View | 直接调用RenderNode.setAlpha()更新 | 只触发DecorView.updateDisplayListIfDirty,不再往下遍历,CPU执行时间可忽略不计 |
Android 4.1(API 级别 16)或更高版本的设备上,
这时,GPU 呈现模式工具已经开启了,接下来,我们可以打开我们要测试的APP来进行观察测试了。
GPU 渲染模式分析工具以图表(以颜色编码的直方图)的形式显示各个阶段及其相对时间。
Android 10 上显示的彩色部分:
注意点:
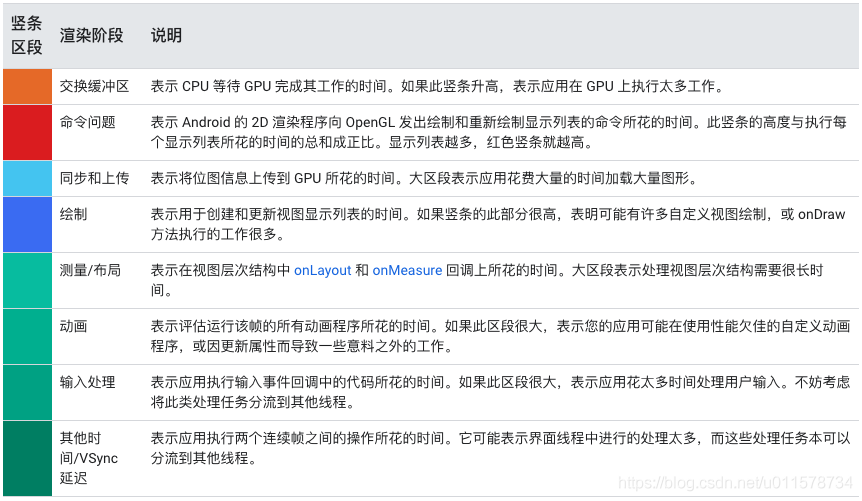
Android 6.0 及更高版本的设备时分析器输出中某个竖条的每个区段含义:
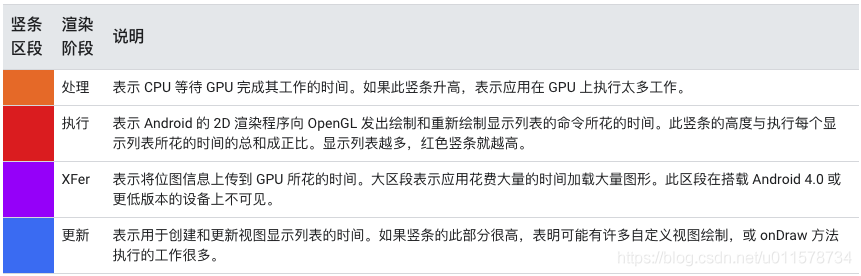
4.0(API 级别 14)和 5.0(API 级别 21)之间的 Android 版本具有蓝色、紫色、红色和橙色区段。低于 4.0 的 Android 版本只有蓝色、红色和橙色区段。下表显示的是 Android 4.0 和 5.0 中的竖条区段。
GPU 呈现模式工具,很直观的为我们展示了 APP 运行时每一帧的耗时详情。我们只需要关注代表每一帧的柱状图的颜色详情,就可以分析出卡顿的原因了。
默认情况下Skia的绘制没有采用GPU渲染的方式(虽然Skia也能用GPU渲染),也就说默认drawSoftware工作完全由CPU来完成,不会牵扯到GPU的操作,但是8.0之后,Google逐渐加重了Skia,开始让Skia接手OpenGL,间接统一调用,将来还可能是Skia同Vulkan的结合。这也是手机端硬件性能越来越好的结果吧。
如果本篇文章对你有帮助,请帮忙点个赞,关注下,谢谢,笔者会定期推送一些关于Android移动开发中的高质量文章。
笔者公众号:小余的自习室

参考
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只