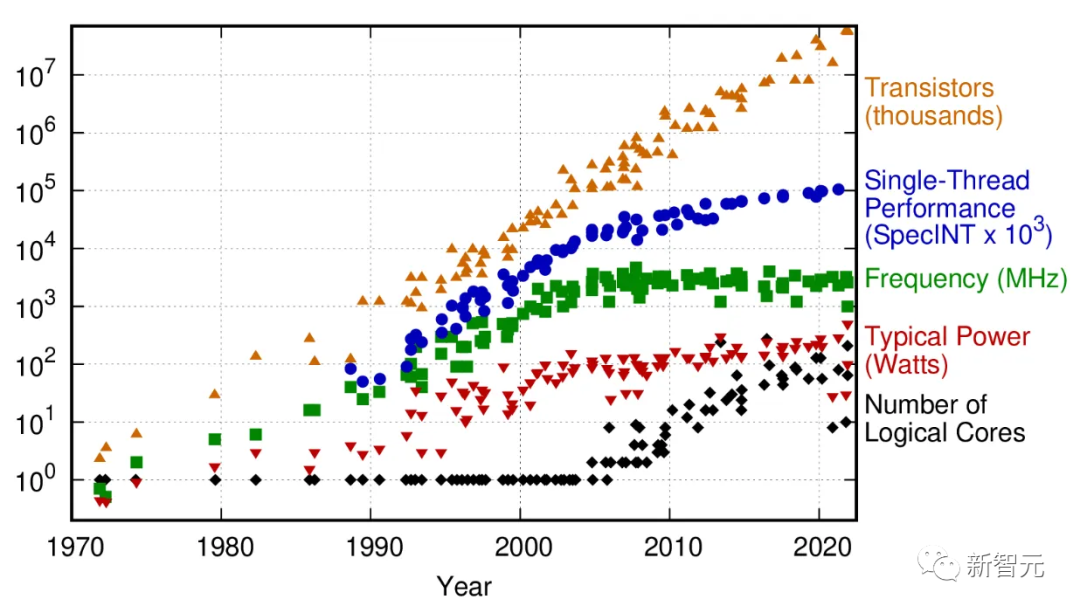
 50年的微处理器趋势数据2005 年,由于电流泄漏导致芯片升温,这种缩放比例开始失效,随之而来的是具有单个处理核心的芯片的性能停滞不前。为了保持计算增长轨迹,芯片行业转向了多核架构:多个微处理器“粘合”在一起。虽然这可能在晶体管密度方面延长了摩尔定律,但它增加了整个计算堆栈的复杂性。对于某些类型的计算任务,如机器学习或计算机图形,这带来了性能提升。但是对于很多并行化不好的通用计算任务,多核架构无能为力。总之,很多任务的计算能力不再呈指数级增长。即使在多核超级计算机的性能上,从TOP500 (全球最快超级计算机排名)来看,2010年左右也出现了明显的拐点。
50年的微处理器趋势数据2005 年,由于电流泄漏导致芯片升温,这种缩放比例开始失效,随之而来的是具有单个处理核心的芯片的性能停滞不前。为了保持计算增长轨迹,芯片行业转向了多核架构:多个微处理器“粘合”在一起。虽然这可能在晶体管密度方面延长了摩尔定律,但它增加了整个计算堆栈的复杂性。对于某些类型的计算任务,如机器学习或计算机图形,这带来了性能提升。但是对于很多并行化不好的通用计算任务,多核架构无能为力。总之,很多任务的计算能力不再呈指数级增长。即使在多核超级计算机的性能上,从TOP500 (全球最快超级计算机排名)来看,2010年左右也出现了明显的拐点。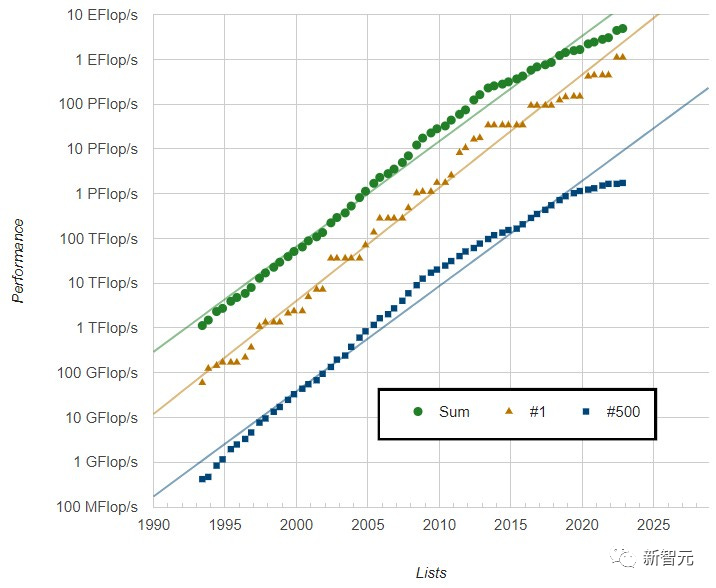 这种放缓的影响是什么?计算在不同行业中发挥的越来越重要的作用表明,影响是立竿见影的,而且只有在摩尔定律进一步动摇的情况下才会变得更加重要。举两个极端的例子:计算能力的提高和成本的降低使得能源行业石油勘探的生产率增长了49%,生物技术行业的蛋白质折叠预测增长了94%。这意味着计算速度的影响不仅限于科技行业,过去50年的大部分经济增长都是摩尔定律驱动的二阶效应,没有它,世界经济可能会停止增长。还有一个需要更多算力的突出原因,就是人工智能的兴起。在今天,训练大语言模型 (LLM) 可能花费数百万美元,并需要数周时间。如果不继续增加数字运算和数据扩展,机器学习所承诺的未来就无法实现。随着机器学习模型在消费技术中的日益普及,预示着其他行业对计算的巨大需求,而且可能是双曲线的需求,廉价的处理正成为生产力的基石。摩尔定律的死亡可能会带来计算的大停滞。与达到AGI可能需要的多模态神经网络相比,今天的LLM仍然相对较小,且容易训练。未来的GPT和它们的竞争对手将需要特别强大的高性能计算机来改进,甚至进行优化。或许很多人会感到怀疑。毕竟,摩尔定律的终结已经被预言过很多次了。为什么应该是现在?从历史上看,这些预测中有许多都源于工程上的挑战。此前,人类的聪明才智曾一次又一次地克服了这些障碍。现在的不同之处在于,我们面临的不再是工程和智能方面的挑战,而是物理学施加的限制。
这种放缓的影响是什么?计算在不同行业中发挥的越来越重要的作用表明,影响是立竿见影的,而且只有在摩尔定律进一步动摇的情况下才会变得更加重要。举两个极端的例子:计算能力的提高和成本的降低使得能源行业石油勘探的生产率增长了49%,生物技术行业的蛋白质折叠预测增长了94%。这意味着计算速度的影响不仅限于科技行业,过去50年的大部分经济增长都是摩尔定律驱动的二阶效应,没有它,世界经济可能会停止增长。还有一个需要更多算力的突出原因,就是人工智能的兴起。在今天,训练大语言模型 (LLM) 可能花费数百万美元,并需要数周时间。如果不继续增加数字运算和数据扩展,机器学习所承诺的未来就无法实现。随着机器学习模型在消费技术中的日益普及,预示着其他行业对计算的巨大需求,而且可能是双曲线的需求,廉价的处理正成为生产力的基石。摩尔定律的死亡可能会带来计算的大停滞。与达到AGI可能需要的多模态神经网络相比,今天的LLM仍然相对较小,且容易训练。未来的GPT和它们的竞争对手将需要特别强大的高性能计算机来改进,甚至进行优化。或许很多人会感到怀疑。毕竟,摩尔定律的终结已经被预言过很多次了。为什么应该是现在?从历史上看,这些预测中有许多都源于工程上的挑战。此前,人类的聪明才智曾一次又一次地克服了这些障碍。现在的不同之处在于,我们面临的不再是工程和智能方面的挑战,而是物理学施加的限制。 MIT Technology Review2月24日发文称,我们没有为摩尔定律的终结做好准备
MIT Technology Review2月24日发文称,我们没有为摩尔定律的终结做好准备 它是每次计算操作过程中散发的微量热量:大约每比特10^-21焦耳。鉴于这种热量这么小,兰道尔极限长期以来一直被认为可以忽略。然而,现在的工程能力已经发展到了可以达到这种能量规模的程度,因为由于电流泄漏等其他开销,现实世界的极限估计比Landauer的边界大了10-100倍。芯片有数以千亿计的晶体管,以每秒数十亿次的速度运行。把这些数字加起来,或许在到达热障碍之前,摩尔定律或许还剩下一个数量级的增长。到那时,现有的晶体管架构将无法进一步提高能效,而且产生的热量会阻止将晶体管封装得更紧密。如果我们不弄清楚这一点,就无法看清行业价值观将会发生什么变化。微处理器将受到限制,行业将争夺边际能源效率的较低奖励。芯片尺寸会膨胀。看看英伟达4000系列的GPU 卡:尽管使用了更高密度的工艺,但它只有一只小狗那么大,功率高达650W。这促使NVIDIA首席执行官黄仁勋在2022年底宣布“摩尔定律已死”——尽管这一声明大部分正确,但其他半导体公司否认了这一声明。IEEE每年都会发布半导体路线图,最新的评估是2D的微缩将在2028年完成,3D微缩应该在2031年全面启动。3D 微缩(芯片在其中相互堆叠)已经很普遍,但它是在计算机内存中,而不是在微处理器中。这是因为内存的散热要低得多;然而,散热在3D架构中很复杂,因此主动内存冷却变得很重要。具有256层的内存即将出现,预计到2030年将达到1,000层大关。回到微处理器,正在成为商业标准的多门器件架构(如Fin场效应晶体管和Gates-all-round)将在未来几年继续遵循摩尔定律。然而,由于固有的热问题,在20世纪30年代以后都不可能有真正的垂直扩展(vertical scaling)。事实上,目前的芯片组会仔细监督处理器的哪些部分随时处于活跃状态,即使在单个平面上也能避免过热。
它是每次计算操作过程中散发的微量热量:大约每比特10^-21焦耳。鉴于这种热量这么小,兰道尔极限长期以来一直被认为可以忽略。然而,现在的工程能力已经发展到了可以达到这种能量规模的程度,因为由于电流泄漏等其他开销,现实世界的极限估计比Landauer的边界大了10-100倍。芯片有数以千亿计的晶体管,以每秒数十亿次的速度运行。把这些数字加起来,或许在到达热障碍之前,摩尔定律或许还剩下一个数量级的增长。到那时,现有的晶体管架构将无法进一步提高能效,而且产生的热量会阻止将晶体管封装得更紧密。如果我们不弄清楚这一点,就无法看清行业价值观将会发生什么变化。微处理器将受到限制,行业将争夺边际能源效率的较低奖励。芯片尺寸会膨胀。看看英伟达4000系列的GPU 卡:尽管使用了更高密度的工艺,但它只有一只小狗那么大,功率高达650W。这促使NVIDIA首席执行官黄仁勋在2022年底宣布“摩尔定律已死”——尽管这一声明大部分正确,但其他半导体公司否认了这一声明。IEEE每年都会发布半导体路线图,最新的评估是2D的微缩将在2028年完成,3D微缩应该在2031年全面启动。3D 微缩(芯片在其中相互堆叠)已经很普遍,但它是在计算机内存中,而不是在微处理器中。这是因为内存的散热要低得多;然而,散热在3D架构中很复杂,因此主动内存冷却变得很重要。具有256层的内存即将出现,预计到2030年将达到1,000层大关。回到微处理器,正在成为商业标准的多门器件架构(如Fin场效应晶体管和Gates-all-round)将在未来几年继续遵循摩尔定律。然而,由于固有的热问题,在20世纪30年代以后都不可能有真正的垂直扩展(vertical scaling)。事实上,目前的芯片组会仔细监督处理器的哪些部分随时处于活跃状态,即使在单个平面上也能避免过热。 (有趣的是,在3月19日博文发表后,作者又将这个预测删除了。他的解释是,这是基于Nature论文中最坏情况的推断,为了论证的清晰和精确,现在已将其删除)而现在的能源生产的规模化速度,在这之后会导致摩尔定律规模化的成本略微增加。而在设计(能源效率)和实施层面(将仍在使用的旧设计替换为最新技术)的一系列一次性优化措施,将允许印度等发展中经济体赶上全球的整体生产力。而摩尔定律终结后,人类在微处理器芯片的制造还没有达到极限之前,就会耗尽能源,计算成本下降的步伐将停滞不前。虽然量子计算被吹捧为超越摩尔定律的有效途径,但它存在太多未知数了,离商用还有数十年的发展,至少在未来 20到30年内,都派不上用场。显然,未来10年将出现严重的算力差距,现有的技术公司、投资者或政府机构都没办法解决。摩尔定律和兰道尔极限的碰撞已经有数十年了,可以说是2030年代最重大、最关键的事件之一。但现在,知道这件事的人,似乎并不多。
(有趣的是,在3月19日博文发表后,作者又将这个预测删除了。他的解释是,这是基于Nature论文中最坏情况的推断,为了论证的清晰和精确,现在已将其删除)而现在的能源生产的规模化速度,在这之后会导致摩尔定律规模化的成本略微增加。而在设计(能源效率)和实施层面(将仍在使用的旧设计替换为最新技术)的一系列一次性优化措施,将允许印度等发展中经济体赶上全球的整体生产力。而摩尔定律终结后,人类在微处理器芯片的制造还没有达到极限之前,就会耗尽能源,计算成本下降的步伐将停滞不前。虽然量子计算被吹捧为超越摩尔定律的有效途径,但它存在太多未知数了,离商用还有数十年的发展,至少在未来 20到30年内,都派不上用场。显然,未来10年将出现严重的算力差距,现有的技术公司、投资者或政府机构都没办法解决。摩尔定律和兰道尔极限的碰撞已经有数十年了,可以说是2030年代最重大、最关键的事件之一。但现在,知道这件事的人,似乎并不多。 这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int
给定一个包含各种语言字符的UTF-8文件,我如何计算它包含的唯一字符的数量,同时排除选定数量的符号(例如:“!”、“@”、"#",".")从这个算起? 最佳答案 这是一个bash解决方案。:)bash$perl-CSD-ne'BEGIN{$s{$_}++forsplit//,q(!@#.)}$s{$_}++||$c++forsplit//;END{print"$c\n"}'*.utf8 关于python-如何计算文件中唯一字符的数量?,我们在StackOverflow上找到一个类似的问题