EAX是edge assembly crossover 算子的缩写。本算法有Y nagata教授公布,目前在VLSI最大的几个案例上获得了best的成绩。另外目前MonoLisa 100K问题的最优解也是由其公布,若能得到更优解,可以获得1000美元奖励。
算法步骤如下:
参考代码https://github.com/nagata-yuichi/GA-EAX(原版)
以及https://github.com/wlsgusjjn/EAX-TSP.git (简化版)
原版文件清单如下:
main.cpp
- The main function
env.cpp, env.h
- Main procedure of the GA
kopt.cpp kopt.h
- Local search with the 2-opt neighborhood
cross.cpp cross.h
- Edge assembly crossover,核心程序
evaluator.cpp evaluator.h
- Pre-processing procedures to the TSP instance
indi.cpp, indi.h
- An individual (tour)
rand.cpp, rand.h
- Procedures for generating a random number and permutation etc
sort.cpp, sort.h
- Procedures for sorting
***.tsp
- Several TSP instances (TSPLIB format)
编译:g++ -o jikken -O3 main.cpp env.cpp cross.cpp evaluator.cpp indi.cpp rand.cpp kopt.cpp sort.cpp -lm
运行:./jikken <integer1> <string1> <integer2> <integer3> <string2>
比如:./jikken 10 DATA 100 30 rat575.tsp
参数说明:
如果string1位DATA,则会生成两个结果文件:
DATA_Result和DATA_BestSol
DATA_Result:存储迭代信息,格式如下:
0 6773 173 0 3
1 6773 174 0 3
2 6773 166 0 3
3 6773 173 0 3
4 6773 173 0 3
5 6773 171 0 3
6 6773 182 0 3
7 6773 168 0 3
8 6773 173 0 3
9 6773 173 0 3
*DATA_BestSol:存储每一轮的最优结果
575 6773
1 24 25 26 27 28 29 52 50 51 74 73 72 49 48 47 70 71 93 94 116 …
如果想记录每一轮的所有路径,将main.cpp中的gEnv->WritePop()开启,结果会写入DATA_POP_*
随后可以将这个文件作为初始路径传给程序继续执行优化:./jikken 10 DATA2 100 30 rat575.tsp DATA_POP_0
还可以做一些自定义算法配置,主要在env。cpp里面的TEnvironment::Init() 可以修改搜索参数:
Example1: Default setting
fStage = 1; /* Stage I */
fFlagC[ 0 ] = 4; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 1; /* Eset Type: 1:Single-AB, 2:Block2 */
Example2: Only Stage II is performed using EAX with the Block2 strategy
fStage = 2; /* Stage I */
fFlagC[ 0 ] = 4; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 2; /* Eset Type: 1:Single-AB, 2:Block2 */
Example3: The greedy selection is used instead of the entropy-preserving selection.
fStage = 1; /* Stage I */
fFlagC[ 0 ] = 1; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 1; /* Eset Type: 1:Single-AB, 2:Block2 */
TerminationCondition() 里可以修改停止条件
参考文章:https://sci-hub.se/10.1287/ijoc.1120.0506,主要想法就是第一步将EAX的操作局部化,随后再执行正常的EAX算子。
每一阶段的GA算法架构如下,其中Npop个初始解使用的是greedy local search +2-opt neighborhood。注意下面有两个参数Npop和Nch。

每个阶段的终止条件:如果最近的1500/Nch次迭代都没有改进,则令G=当前迭代总次数。继续迭代,直至连续G/10次迭代都没有改进
3.2节中构造E-set时,局部EXA规则目前有两种:
1.随机策略:每个AB-cycles有0.5的概率选上
2.单个策略:随机在剩余的AB-cycles中选一个
subtour消除规则为:
1.每次都从最小的subtour开始,遍历所有待删除的边e
2.另一条待删除的边,需满足其中至少有一个点在e的最近10个点中
全局EXA规则有三种
1.K-multiple策略:随机选取K个AB-cycles,代码中K=5
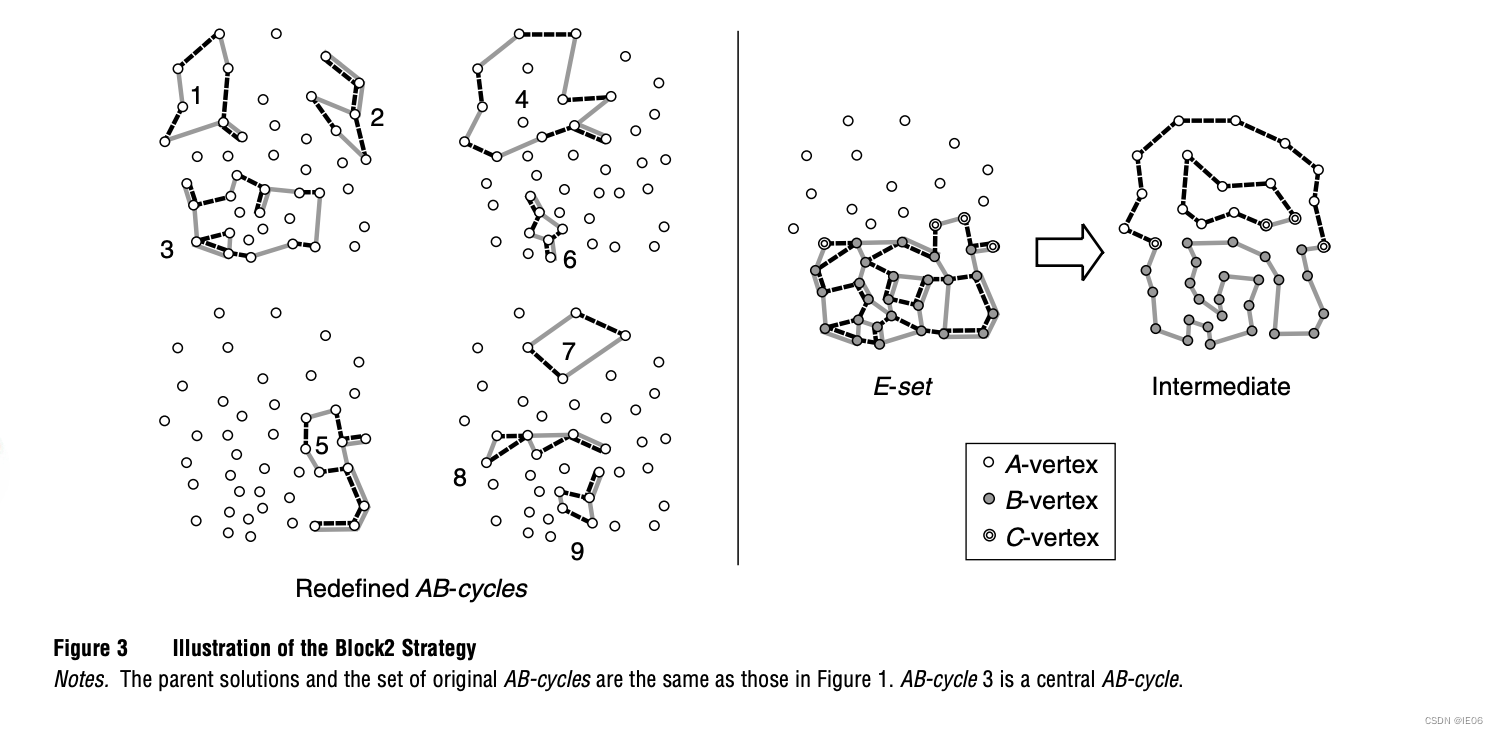
2.block策略:主要思想是选取位置相近的AB-cycles
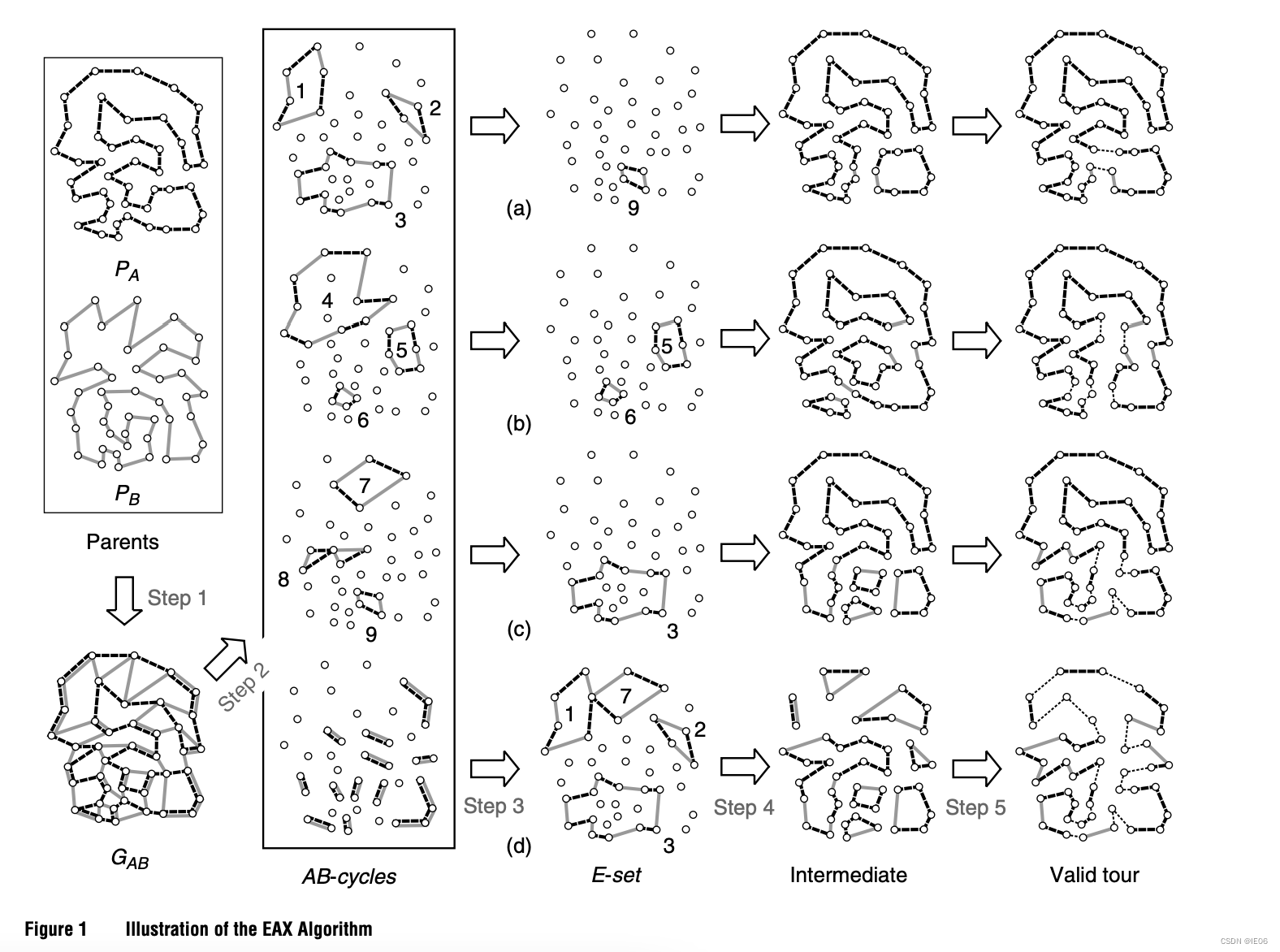
3.block2策略:首先定义A-vertex为连接A中两条边的点;B-vertex为连接B中两条边的点;C-vertex为连接A和B中各一条边的点,如下图。其中a和b的差别在于,b中对c-vertex做了精简。
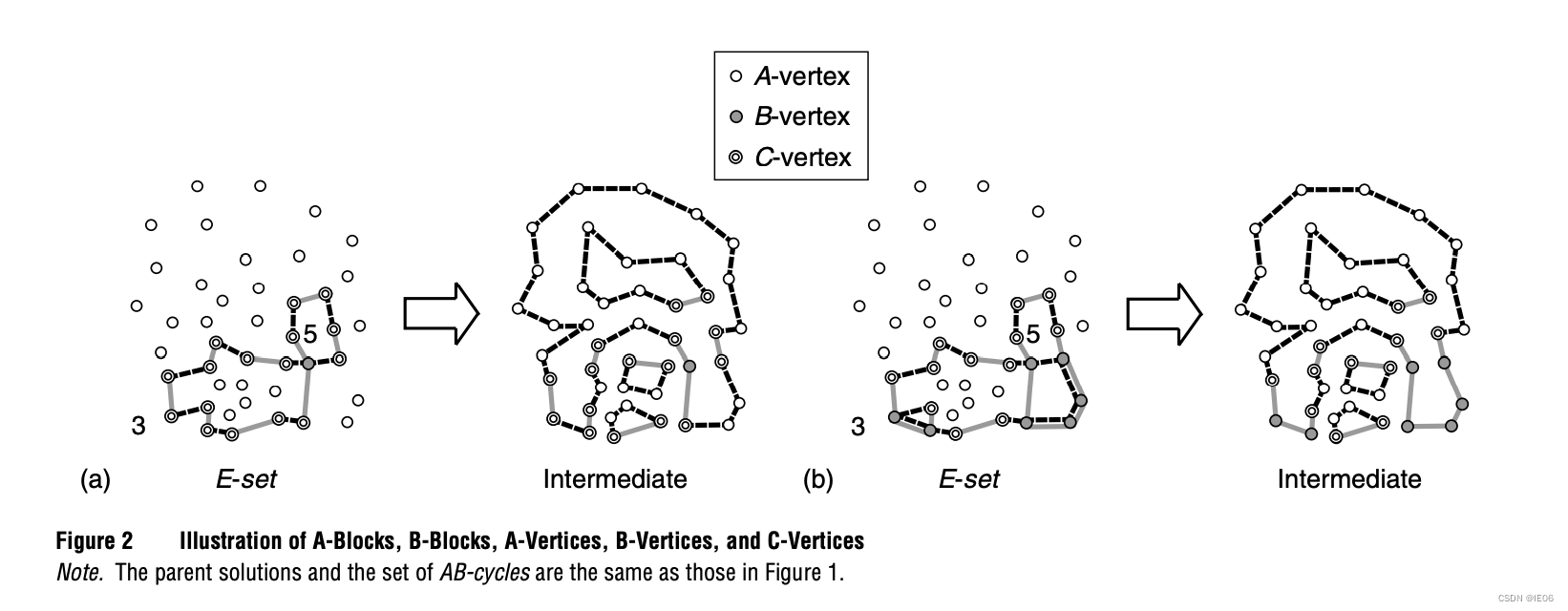
在intermediate solution中,A-blocks和B-blocks被c-vertex隔开,且c-vertex的数量肯定是偶数。c-vertex的计算比subtour的计算要快。使用tabu-search选取E-set,规则为:
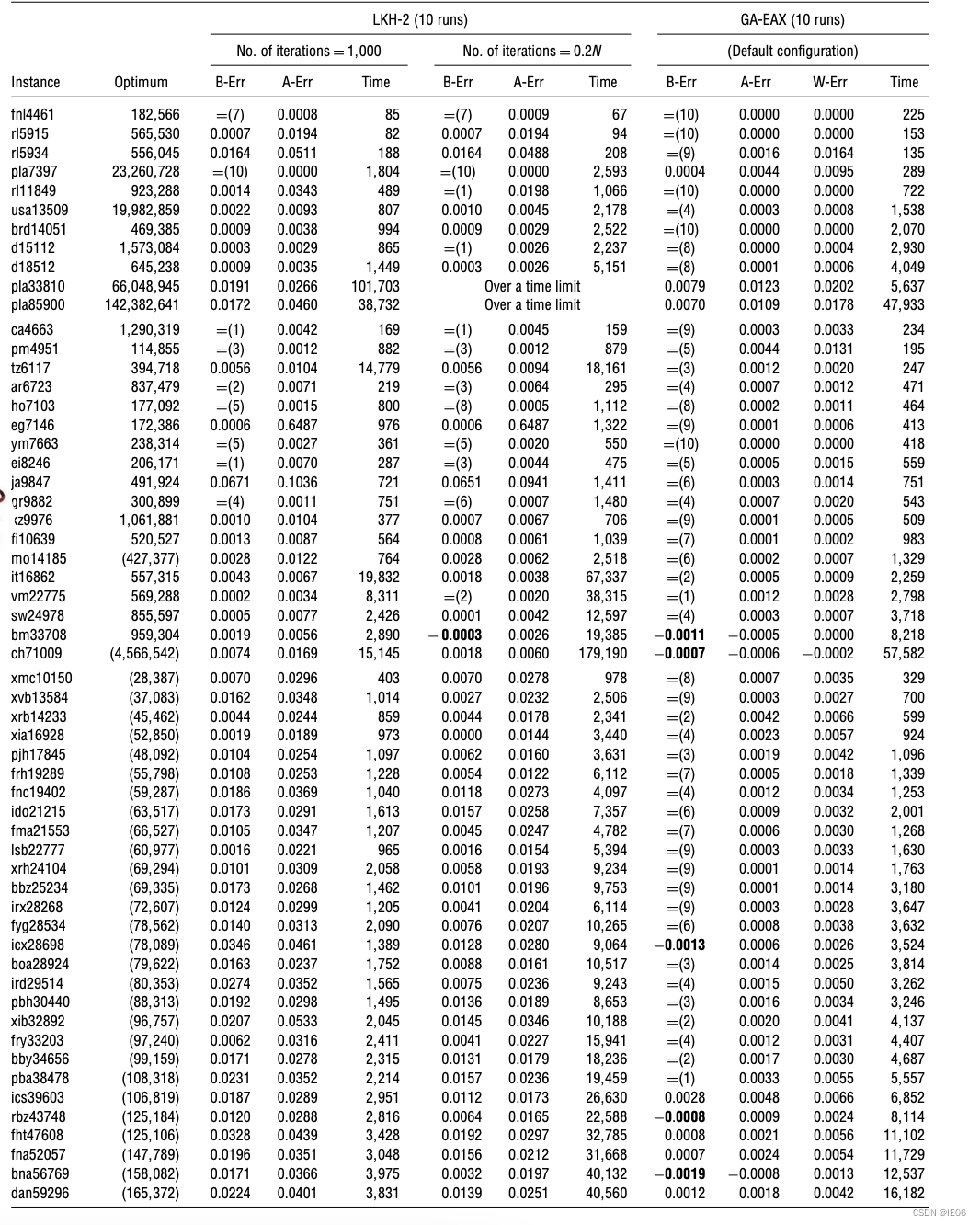
如下,其中B-err是best solution error,如果是=的话,后面括号中表示获得最优值的次数。A-err是average,W-error则是worst。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen