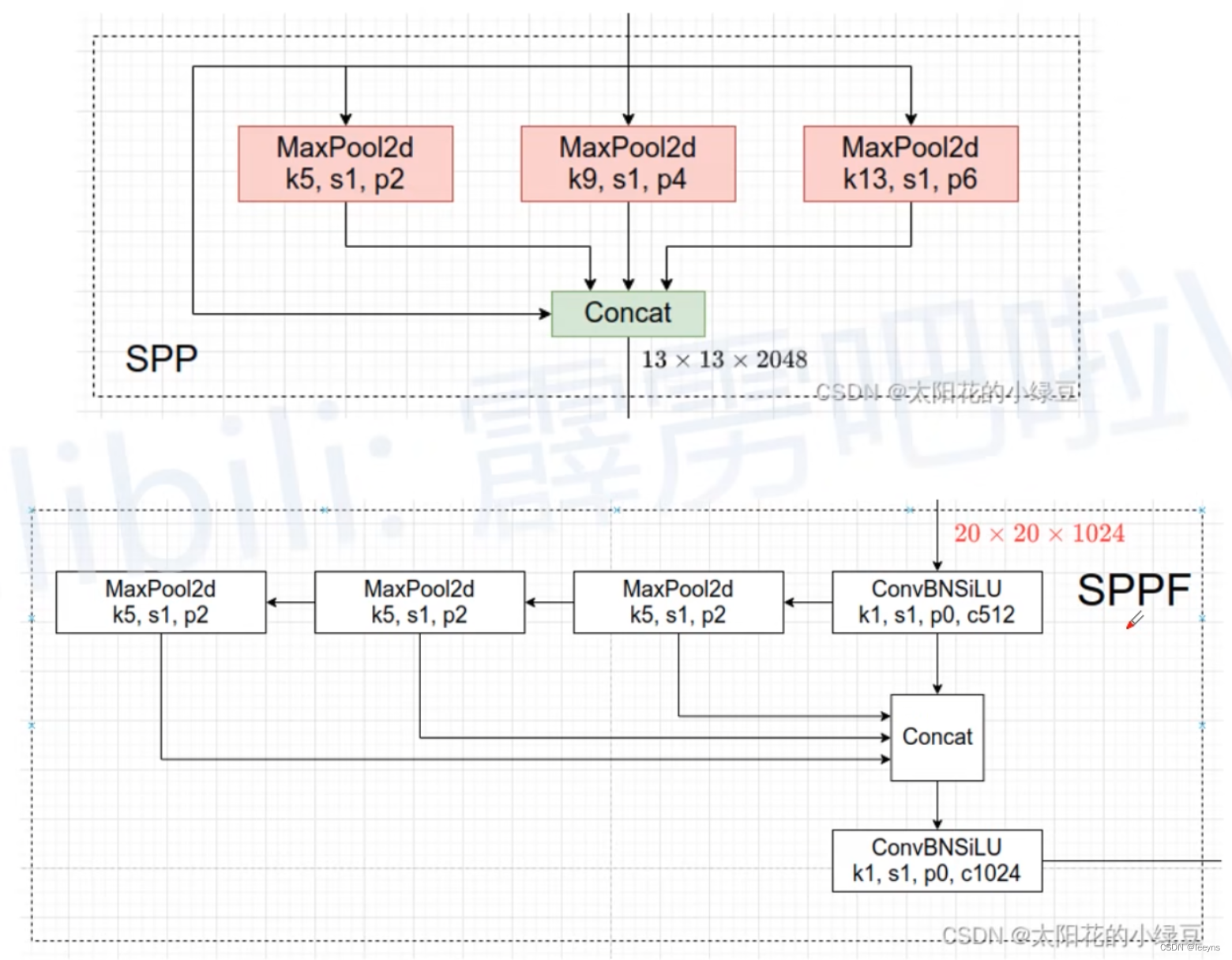
SPP 是使用了3个kernel size不一样大的pooling 并行运算。SPPF是将kernel size为5的 pooling 串行运算,这样的运算的效果和SPP相同,但是运算速度加快。因为SPPF减少了重复的运算,每一次的pooling 运算都是在上一次运算的基础上进行的。
在YOLO V4中,作者仅仅使用了PAN模块,在PAN中的卷积操作为一般卷积操作。而在YOLO V5中,PAN中的卷积操作换为了CSP。如图,上图为YOLO V4中的PAN模块,下图为YOLO V5的CSP-PAN模块。
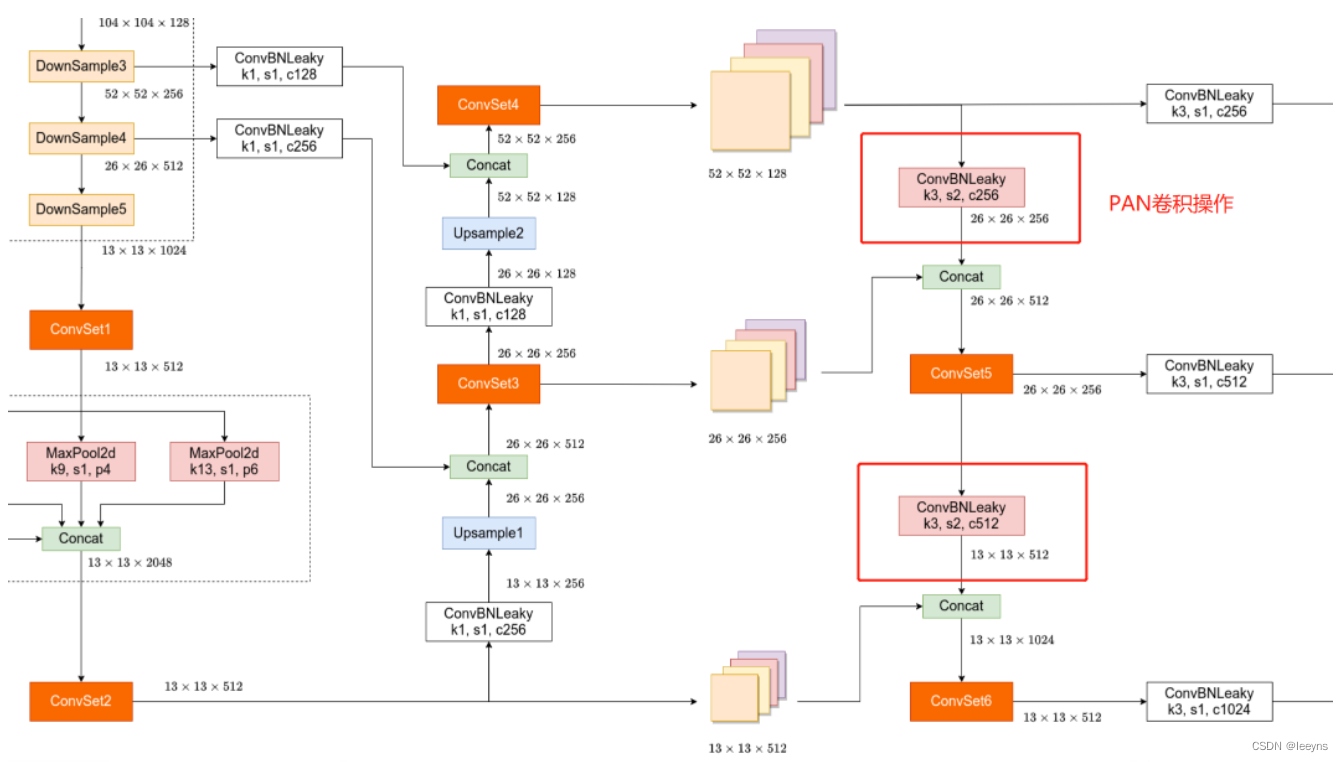
YOLO V5 CSP-PAN模块
Loss function 的组成和YOLO V3一样,同样是由 Classes loss, Objectness loss, Location loss.
改进:
Location Loss 采用的是 CIOU Loss.Objectness Loss 在YOLO V3中 将IOU最大的设为正样本,将IOU小于阈值的设为负样本,其他的都不考虑。而在YOLO V5 中是计算所有样本的obj损失,采用CIOU作为标准。Objectness Loss 同时也平衡了不同尺度的损失,针对三个预测特征层上的obj损失赋予不同的权重。在YOLO V4对于x, y进行了优化使其对极限值0和1更加敏感一些。然而,对于横纵比同样存在问题,原始的公式中仅使用 e x e^x ex 来进行偏移,这样会导致偏移量没有限制,变得十分敏感。
b w = p w e t w b h = p h e t h \begin{aligned} b_w = p_we^{t_w}\\ b_h = p_he^{t_h} \end{aligned} bw=pwetwbh=pheth
而在 YOLO V5中对横纵比的偏移进行了优化,将其变成如下:
b x = 2 σ ( t x ) − 0.5 + c x b y = 2 σ ( t y ) − 0.5 + c y b w = p w ( 2 σ ( t w ) ) 2 b h = p h ( 2 σ ( t h ) ) 2 \begin{array}{c} b_{x}=2 \sigma\left(t_{x}\right)-0.5+c_{x} \\ b_{y}=2 \sigma\left(t_{y}\right)-0.5+c_{y} \\ b_{w}=p_{w}\left(2 \sigma\left(t_{w}\right)\right)^{2} \\ b_{h}=p_{h}\left(2 \sigma\left(t_{h}\right)\right)^{2} \end{array} bx=2σ(tx)−0.5+cxby=2σ(ty)−0.5+cybw=pw(2σ(tw))2bh=ph(2σ(th))2
这在一定程度上限制了横纵比的偏移,YOLO V5作者所做的实验曲线如下。
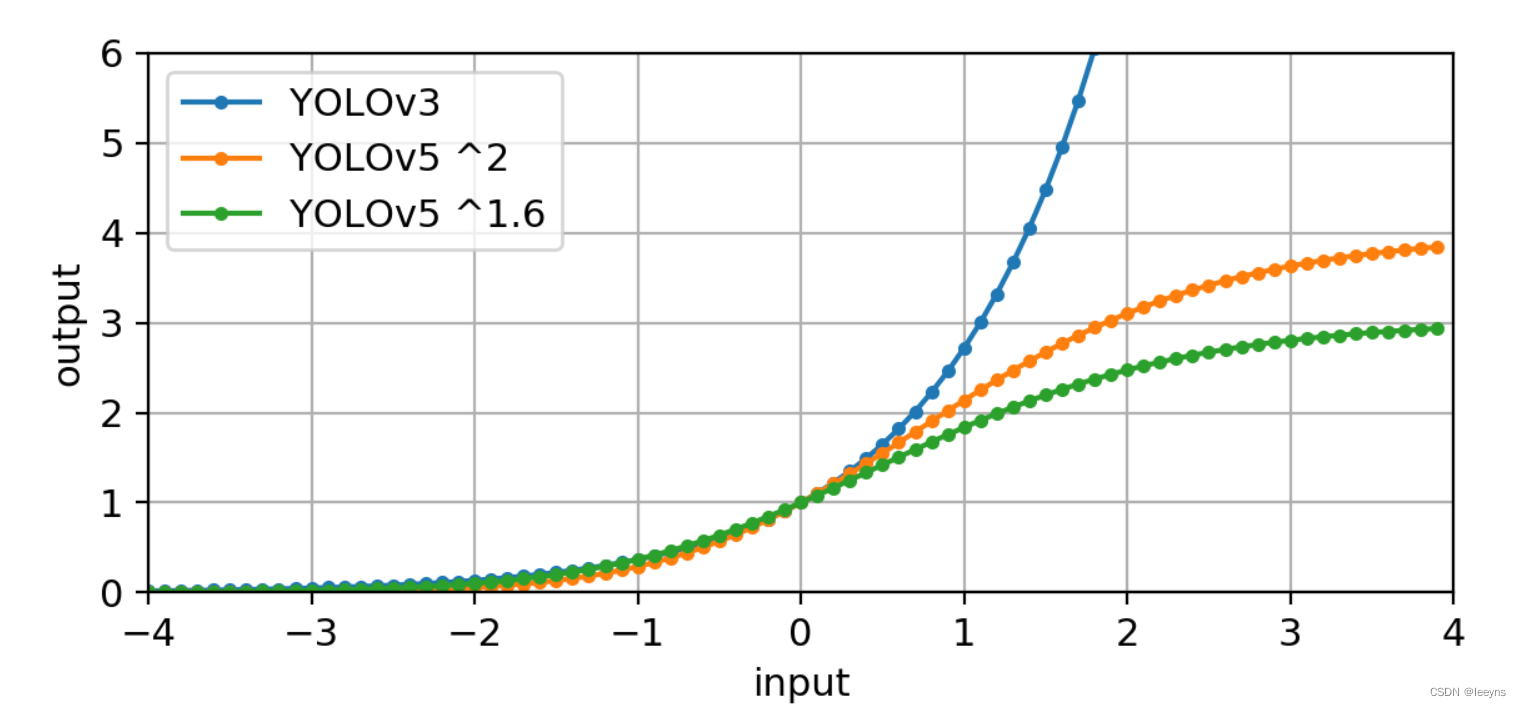
在YOLO V4的拓展基础上,YOLO V5 对正样本的选取同时加入了横纵比的限制。
r w = w g t / w a t r h = h g t / h a t r w max = max ( r w , 1 / r w ) r h max = max ( r h , 1 / r h ) r max = max ( r w max , r h max ) \begin{array}{l} r_{w}=w_{g t} / w_{a t} \\ r_{h}=h_{g t} / h_{a t} \\ r_{w}^{\max }=\max \left(r_{w}, 1 / r_{w}\right) \\ r_{h}^{\max }=\max \left(r_{h}, 1 / r_{h}\right) \\ r^{\max }=\max \left(r_{w}^{\max }, r_{h}^{\max }\right) \end{array} rw=wgt/watrh=hgt/hatrwmax=max(rw,1/rw)rhmax=max(rh,1/rh)rmax=max(rwmax,rhmax)
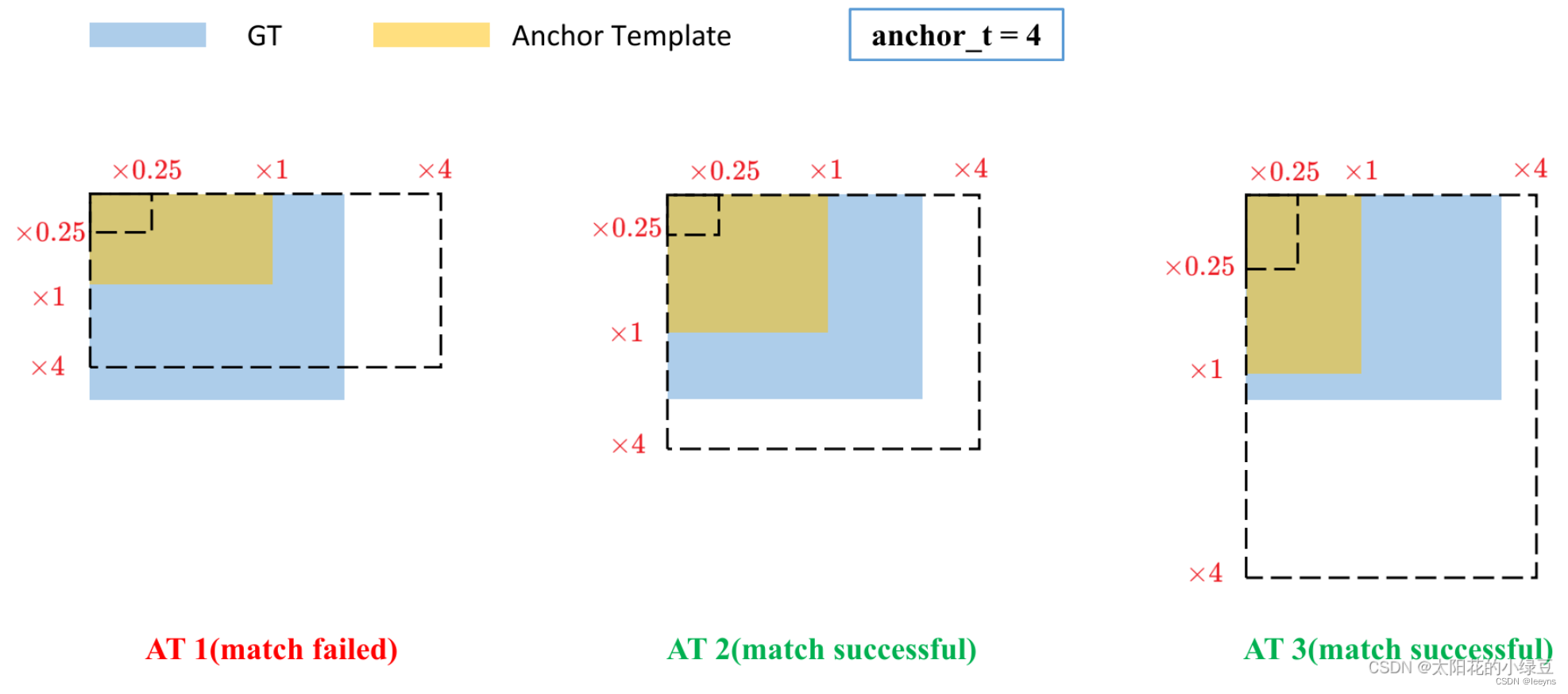
首先算出anchor和GT的横纵比的最大差距,对于最大差距在4倍以上的例子都不作为正样本采用。
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
我正在用Ruby编写DSL来控制我正在处理的Arduino项目;巴尔迪诺。这是一只酒吧猴子,将由软件控制来提供饮料。Arduino通过串行端口接收命令,告诉Arduino要打开什么泵以及打开多长时间。它目前正在读取一个食谱(见下文)并将其打印出来。串行通信的代码以及我在下面提到的其他一些想法仍然需要改进。这是我的第一个DSL,我正在处理之前的示例,所以它的边缘非常粗糙。任何批评、代码改进(是否有任何关于RubyDSL最佳实践或习语的良好引用?)或任何一般性评论。我目前有DSL的粗略草稿,因此饮料配方如下所示(Githublink):desc"Simpleglassofwater"rec
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif