本文介绍基于Python语言,按照一定命名规则批量修改多个文件的文件名的方法。
已知现有一个文件夹,其中包括班级所有同学上交的作业文件,每人一份;所有作业文件命名格式统一,都是地信1701_姓名_学习心得格式。
现需要对每一位同学的作业文件加以改名,有很多种需求。
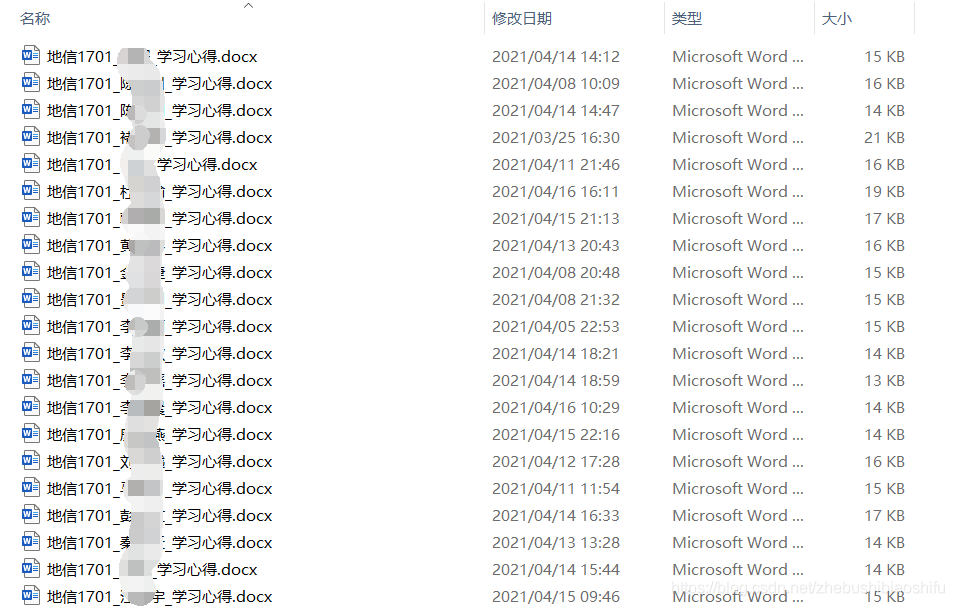
第一种需求,将每一位同学作业文件名中原本是姓名的部分,都修改为学号。即原本的地信1701_姓名_学习心得修改为地信1701_学号_学习心得(每一位同学有且仅有一个学号,且相互不重复,且姓名与学号的对应关系我们是已知的),如下图所示。
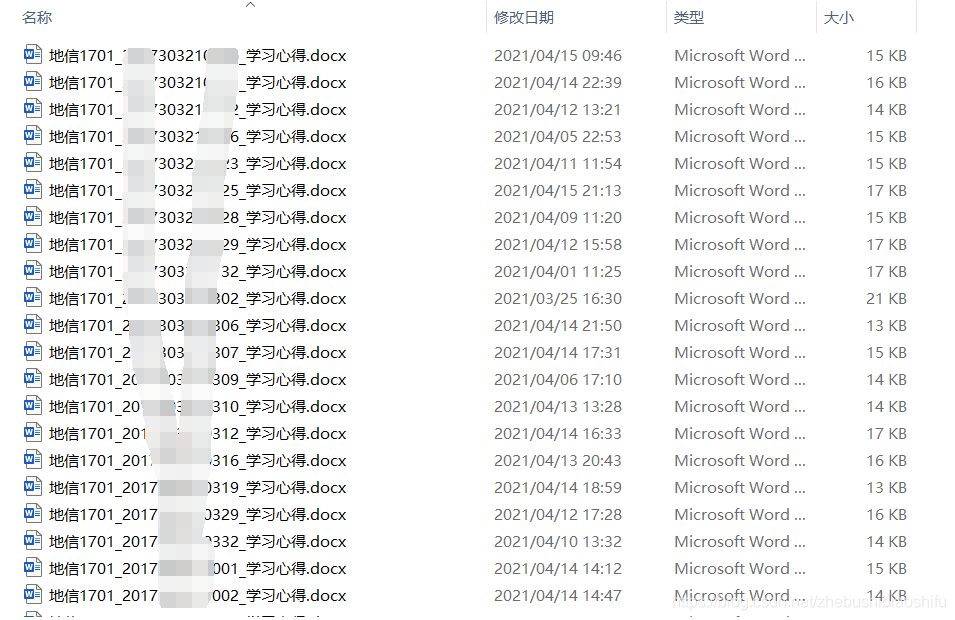
第二种需求,将每一位同学作业文件名中原本姓名的部分的后面,都添加上学号。即原本的地信1701_姓名_学习心得修改为地信1701_姓名_学号_学习心得,如下图所示。
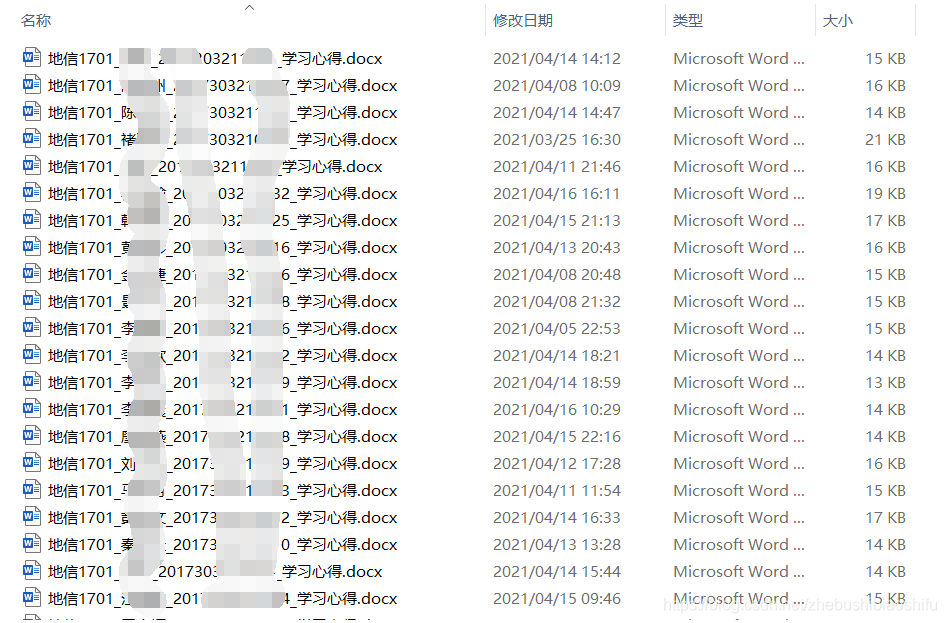
第三种需求,将每一位同学满足第二种需求后的作业文件名中的下划线_部分,都修改为连接符-。即原本的地信1701_姓名_学号_学习心得修改为地信1701-姓名-学号-学习心得,如下图所示。
好了,知道了需求我们就可以开始进行代码的编写了。
首先,导入必要的库。
import os
from openpyxl import load_workbook
接下来,我们首先需要让程序知道每一位同学的姓名与学号之间的对应关系。因为我们已知姓名与学号之间的关系,因此首先需要类似于下图的表格,其中为姓名与学号的一一对应关系。
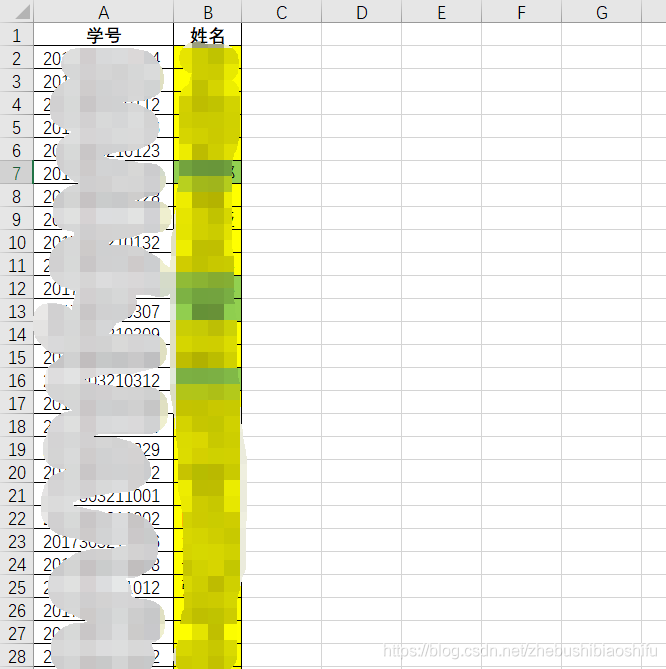
接下来,我们需要将上述表格中的内容在Python中以字典的格式存储。具体代码如下,关于这一部分代码的解释大家查看Python导入Excel表格数据并以字典dict格式保存即可,此处就不再赘述。
original_path='F:/学习/2020-2021-2/形势与政策(二)/论文与学习心得/01_学习心得/地信1701-学习心得/'
look_up_table_path='F:/学习/2020-2021-2/形势与政策(二)/论文与学习心得/01_学习心得/Name_Number.xlsx'
look_up_table_row_start=2
look_up_table_row_number=32
name_number_dict={}
look_up_table_excel=load_workbook(look_up_table_path)
look_up_table_all_sheet=look_up_table_excel.get_sheet_names()
look_up_table_sheet=look_up_table_excel.get_sheet_by_name(look_up_table_all_sheet[0])
for i in range(look_up_table_row_start,look_up_table_row_start+look_up_table_row_number):
number=look_up_table_sheet.cell(i,1).value
name=look_up_table_sheet.cell(i,2).value
name_number_dict[number]=name
接下来,进行第一种需求的代码实现。
# Replacement Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
old_name_name_end=old_name.rfind('_')
old_name_name=old_name[7:old_name_name_end]
new_name_number=[k for k, v in name_number_dict.items() if v==old_name_name]
new_name=old_name.replace(old_name_name,''.join(str(w) for w in new_name_number))
os.rename(original_path+old_name,original_path+new_name)
其中,由于大家的姓名有两个字、三个字或者更多字,因此我们使用了old_name_name_end获取原有文件名称中姓名最后一个字所在的下标;而姓名开始的位置是确定的,即从而确定了每一位同学姓名在原有文件名中的起始与终止下标位置。同时利用replace,依据同学的姓名,在字典中搜索该同学的学号,最后将同学的名字替换为其对应的学号。
其次,是第二种需求。
# Additional Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
old_name_name_end=old_name.rfind('_')
old_name_name=old_name[7:old_name_name_end]
new_name_number=[k for k, v in name_number_dict.items() if v==old_name_name]
old_name_list=list(old_name)
insert_number=''.join(str(w) for w in new_name_number)+'_'
old_name_list.insert(old_name_name_end+1,insert_number)
new_name=''.join(old_name_list)
os.rename(original_path+old_name,original_path+new_name)
在这里,同样使用old_name_name_end获取原有文件名称中姓名最后一个字所在的下标,从而确定了每一位同学姓名在原有文件名中的起始与终止下标位置。此外,利用insert,将学号这一项插入到原有的文件名称中。
最后,是第三种需求。
# Modified Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
new_name=old_name.replace('_',"-",3)
os.rename(original_path+old_name,original_path+new_name)
这个就简单很多了,直接利用replace,用连接符-替换掉原有的下划线_即可。
至此,大功告成。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题