Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
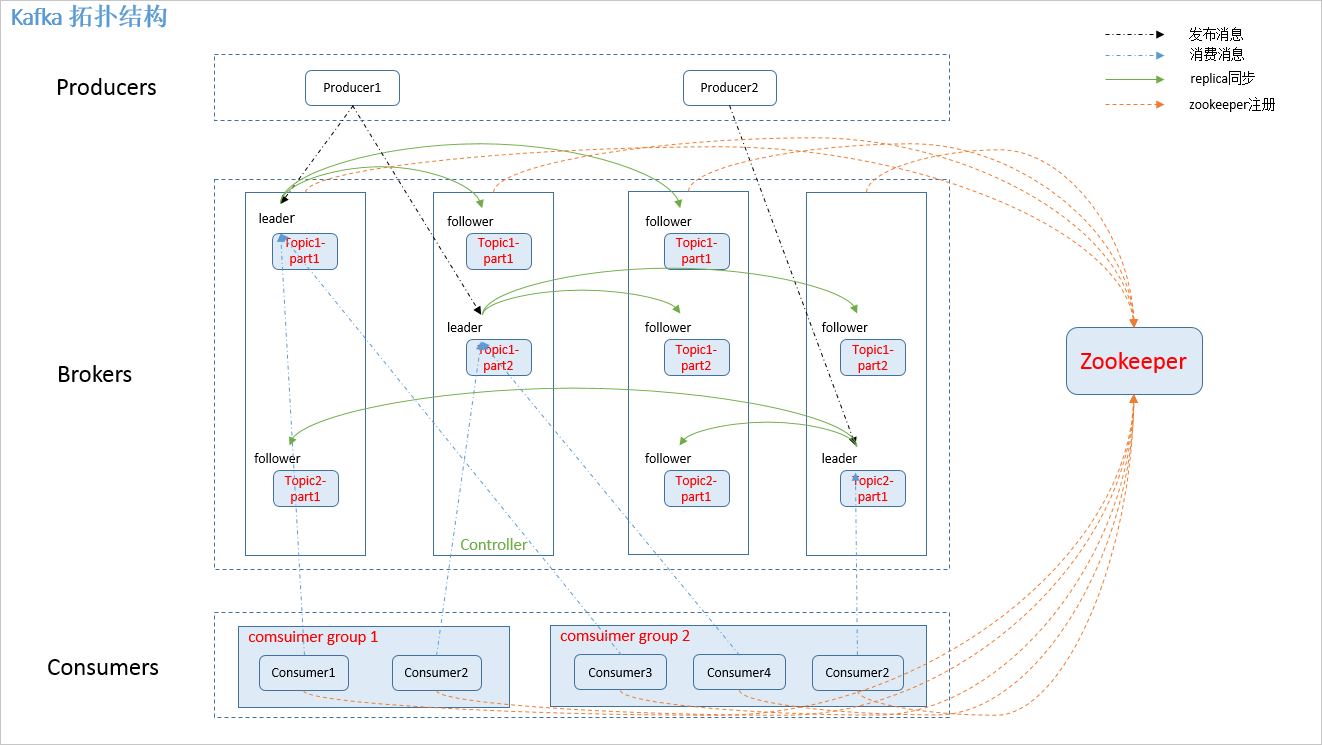
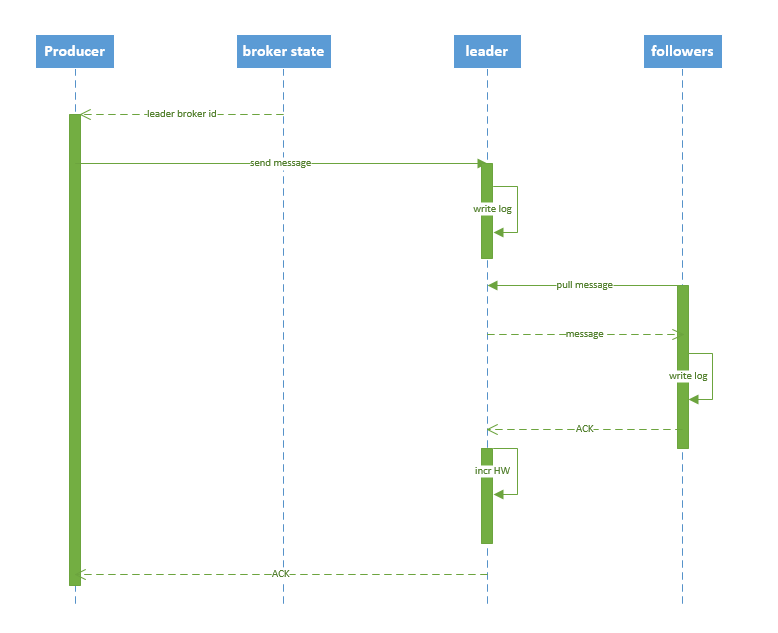
Kakfa Broker Leader的选举:Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。
Consumergroup:各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group )中的一个consumer(consumer 线程)消费,如果一个message可以被多个consumer(consumer 线程)消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的同一个consumer group下的consumer thread来处理,除非再启动一个新的consumer group。所以只能一个partition只能被一个consumer thread去处理。
Consumer Rebalance的触发条件:
Consumer: Consumer处理partition里面的message的时候是o(1)顺序读取的。所以必须维护着上一次读到哪里的offsite信息。high level API,offset存于Zookeeper中,low level API的offset由自己维护。一般来说都是使用high level api的。Consumer的delivery gurarantee,默认是读完message先commmit再处理message,autocommit默认是true,这时候先commit就会更新offsite+1,一旦处理失败,offsite已经+1,这个时候就会丢message;也可以配置成读完消息处理再commit,这种情况下consumer端的响应就会比较慢的,需要等处理完才行。
Topic & Partition:Topic相当于传统消息系统MQ中的一个队列queue,producer端发送的message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上( hash(message) % [broker数量] )。物理上存储上,这个topic会分成一个或多个partition,每个partiton相当于是一个子queue。在物理结构上,每个partition对应一个物理的目录(文件夹),文件夹命名是[topicname][partition][序号],一个topic可以有无数多的partition,根据业务需求和数据量来设置。在kafka配置文件中可随时更改num.partitions参数来配置更改topic的partition数量,在创建Topic时通过参数指定parittion数量。Topic创建之后通过Kafka提供的工具也可以修改partiton数量。
Partition Replica:kafka中,副本策略是基于partition,而不是topic;每个partition可以在其他的kafka broker节点上存副本,以便某个kafka broker节点宕机不会影响这个kafka集群。存replica副本的方式是按照kafka broker的顺序存。例如有5个kafka broker节点,某个topic有3个partition,每个partition存2个副本,那么partition1存broker1,broker2,partition2存broker2,broker3。。。以此类推(replica副本数目不能大于kafka broker节点的数目,否则报错。这里的replica数其实就是partition的副本总数,其中包括一个leader,其他的就是copy副本)。这样如果某个broker宕机,其实整个kafka内数据依然是完整的。但是,replica副本数越高,系统虽然越稳定,但是回来带资源和性能上的下降;replica副本少的话,也会造成系统丢数据的风险。
Partition leader与follower:partition也有leader和follower之分。leader是主partition,producer写kafka的时候先写partition leader,再由partition leader push给其他的partition follower。partition leader与follower的信息受Zookeeper控制,一旦partition leader所在的broker节点宕机,zookeeper会冲其他的broker的partition follower上选择follower变为parition leader。
Topic分配partition和partition replica的算法:
message持久化:Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的,这就是为了数据库的瓶颈经常在IO上,需要换SSD硬盘的原因。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。一般的机器,单机每秒100k条数据。
message有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
kafka delivery guarantee(message传送保证):
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
push-and-pull : Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
zookeeper 是 kafka 不可分割的一部分。接下来就来讲讲zookeeper在kafka中作用。
kafka 在 zookeeper 中的存储结构如下图所示:
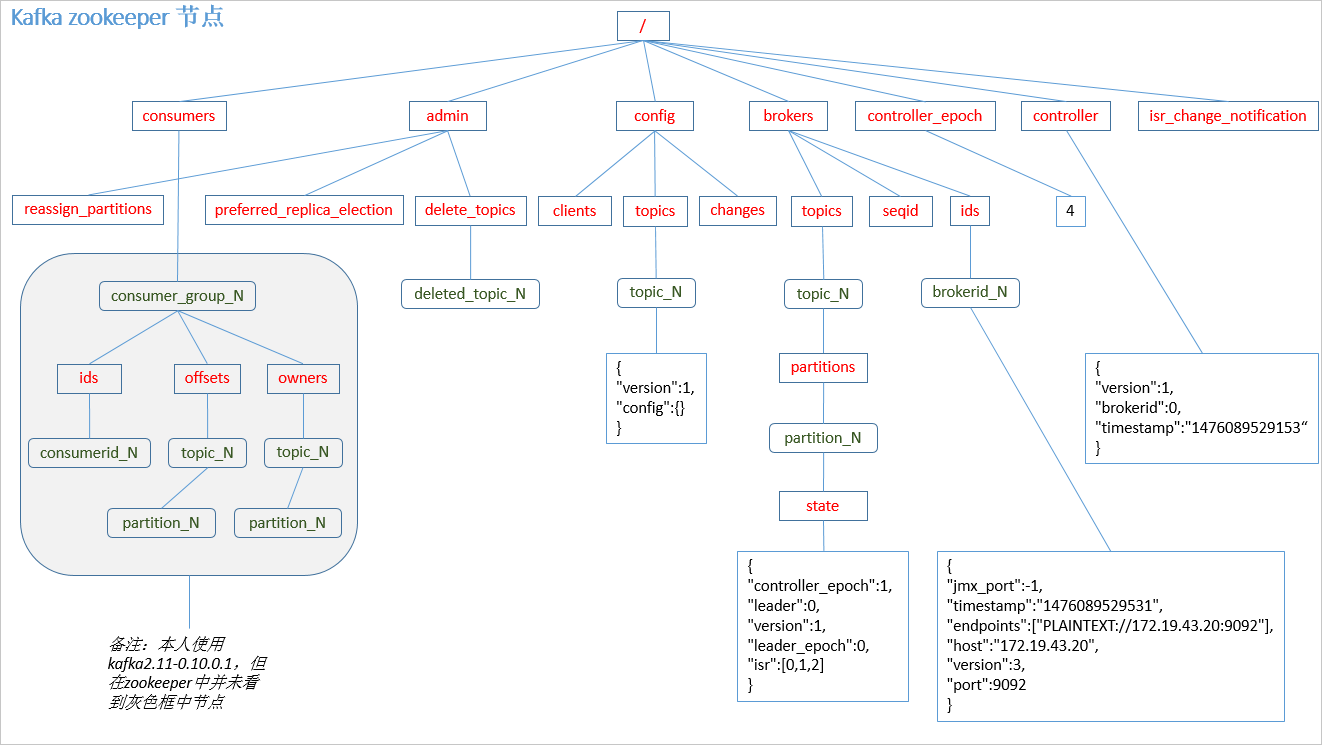
所谓控制器就是一个Borker,在一个kafka集群中,有多个broker节点,但是它们之间需要选举出一个leader,其他的broker充当follower角色。集群中第一个启动的broker会通过在zookeeper中创建临时节点/controller来让自己成为控制器,其他broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在zookeeper中创建watch对象,便于它们收到控制器变更的通知。
在kafka的集群中,会存在着多个主题topic,在每一个topic中,又被划分为多个partition,为了防止数据不丢失,每一个partition又有多个副本,在整个集群中,总共有三种副本角色:
默认的,如果follower与leader之间超过10s内没有发送请求,或者说没有收到请求数据,此时该follower就会被认为“不同步副本”。而持续请求的副本就是“同步副本”,当leader发生故障时,只有“同步副本”才可以被选举为leader。其中的请求超时时间可以通过参数replica.lag.time.max.ms参数来配置。
我们希望每个分区的leader可以分布到不同的broker中,尽可能的达到负载均衡,所以会有一个优先leader,如果我们设置参数auto.leader.rebalance.enable为true,那么它会检查优先leader是否是真正的leader,如果不是,则会触发选举,让优先leader成为leader。
组协调器会为消费组(consumer group)内的所有消费者选举出一个leader,这个选举的算法也很简单,第一个加入consumer group的consumer即为leader,如果某一时刻leader消费者退出了消费组,那么会重新 随机 选举一个新的leader。
k8s上安装kafka,可以使用helm,将kafka作为一个应用安装。当然这首先要你的k8s支持使用helm安装。helm的介绍和安装见:Kubernetes(k8s)包管理器Helm(Helm3)介绍&Helm3安装Harbor
1、创建命名空间
$ mkdir -p /opt/bigdata/kafka
$ cd /opt/bigdata/kafka
$ kubectl create namespace bigdata
2、创建持久化存储SC(bigdata-nfs-storage)
cat << EOF > bigdata-sc.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: bigdata #根据实际环境设定namespace,下面类同
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
namespace: bigdata
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: bigdata
# replace with namespace where provisioner is deployed
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: bigdata
# replace with namespace where provisioner is deployed
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: bigdata
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: bigdata
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
namespace: bigdata
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes #容器内挂载点
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.0.113
- name: NFS_PATH
value: /opt/nfsdata
volumes:
- name: nfs-client-root #宿主机挂载点
nfs:
server: 192.168.0.113
path: /opt/nfsdata
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: bigdata-nfs-storage
namespace: bigdata
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
reclaimPolicy: Retain #回收策略:Retain(保留)、 Recycle(回收)或者Delete(删除)
volumeBindingMode: Immediate #volumeBindingMode存储卷绑定策略
allowVolumeExpansion: true #pvc是否允许扩容
EOF
执行
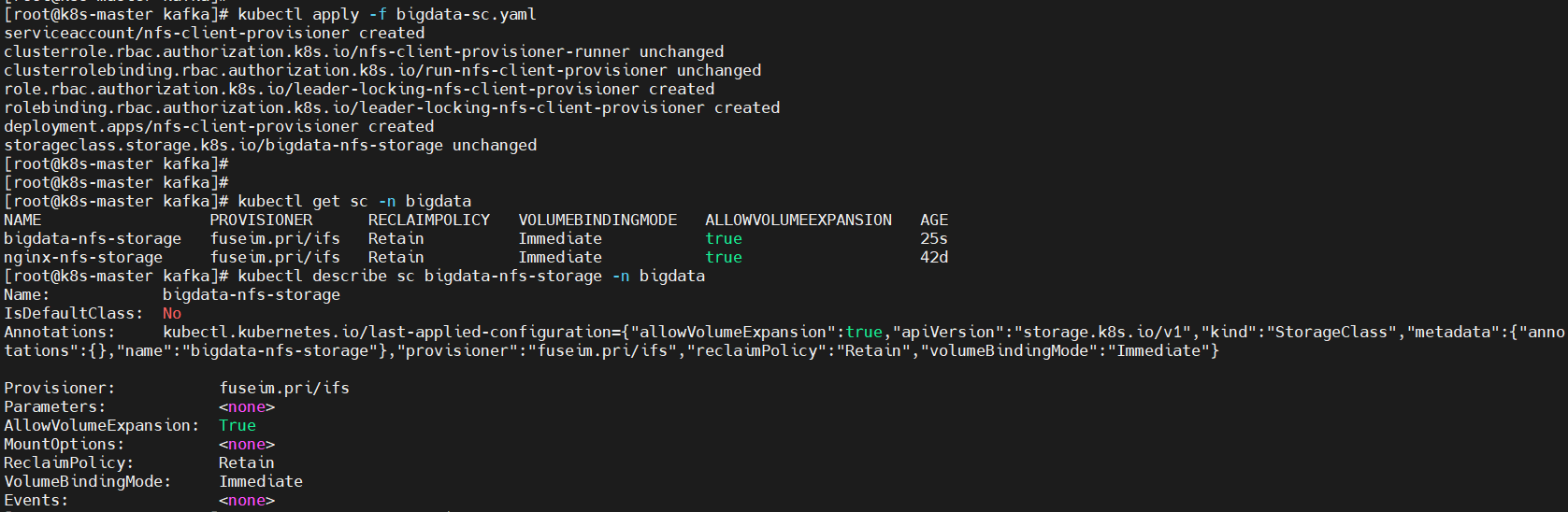
$ kubectl apply -f bigdata-sc.yaml
$ kubectl get sc -n bigdata
$ kubectl describe sc bigdata-nfs-storage -n bigdata
3、helm添加bitnami仓库
$ helm repo add bitnami https://charts.bitnami.com/bitnami
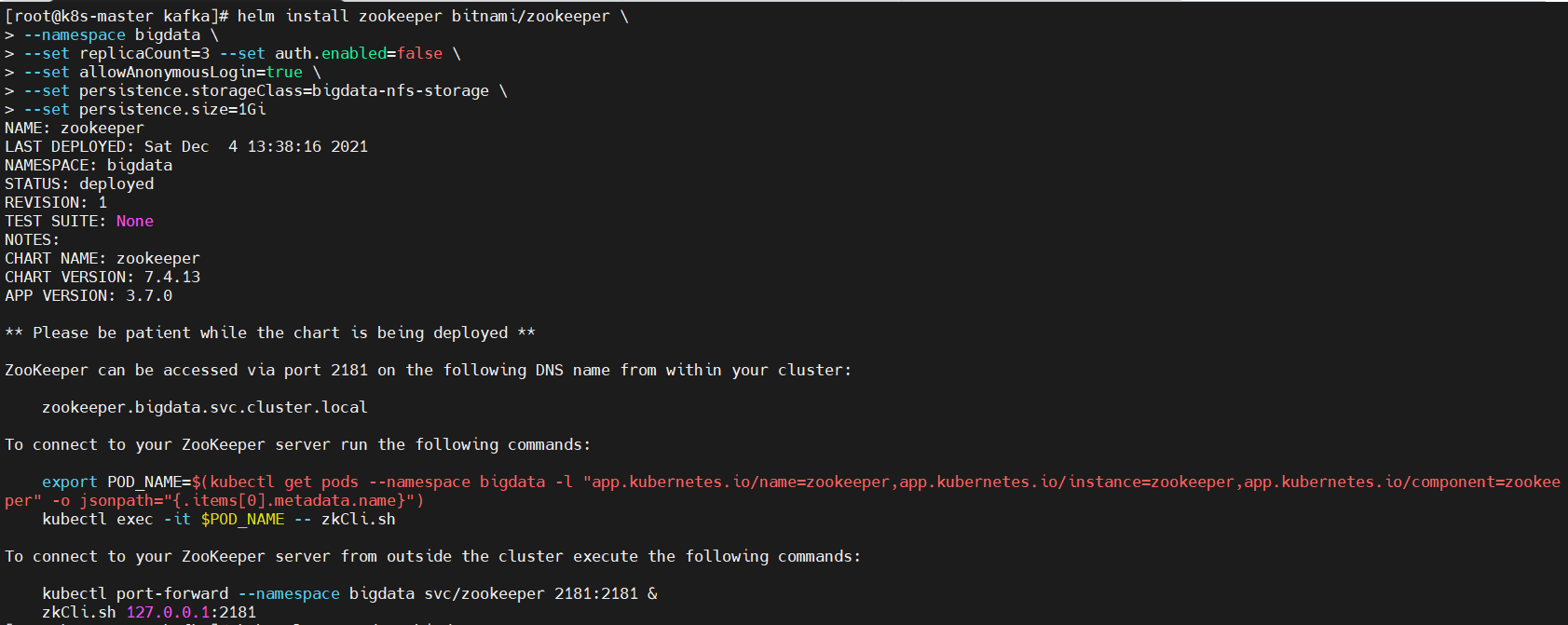
$ helm install zookeeper bitnami/zookeeper \
--namespace bigdata \
--set replicaCount=3 --set auth.enabled=false \
--set allowAnonymousLogin=true \
--set persistence.storageClass=bigdata-nfs-storage \
--set persistence.size=1Gi
查看,一定看到所有pod都是正常运行才ok
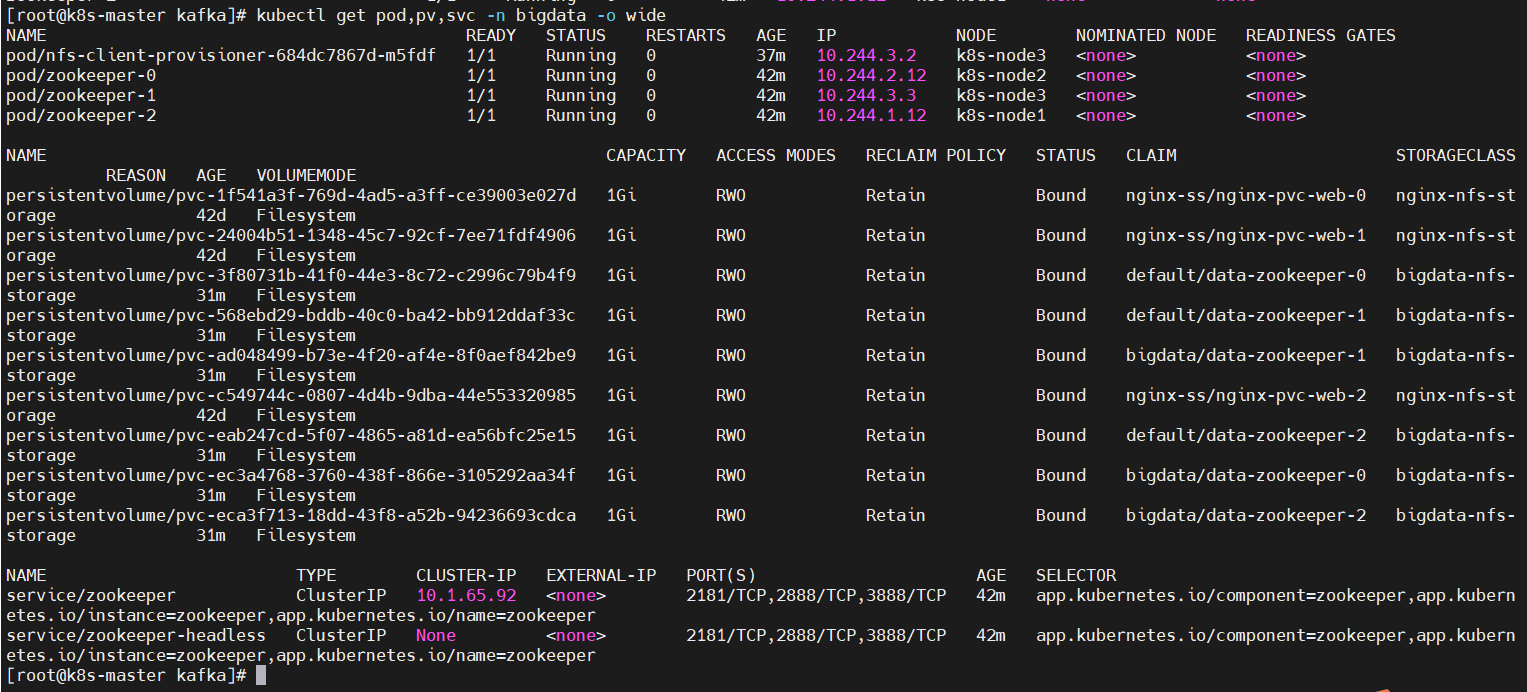
$ kubectl get pod,pv,svc -n bigdata -o wide
验证
内部连接测试
$ export POD_NAME=$(kubectl get pods --namespace bigdata -l "app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/component=zookeeper" -o jsonpath="{.items[0].metadata.name}")
$ kubectl exec -it $POD_NAME -n bigdata -- zkCli.sh

外部连接测试
# 先删掉本地端口对应的进程,要不然就得换连接端口了
$ netstat -tnlp|grep 127.0.0.1:2181|awk '{print int($NF)}'|xargs kill -9
# 外部连接测试
$ kubectl port-forward --namespace bigdata svc/zookeeper 2181:2181 &
# 需要本机安装zk客户端
$ zkCli.sh 127.0.0.1:21
1、查看zookeeper集群状态
$ helm status zookeeper -n bigdata
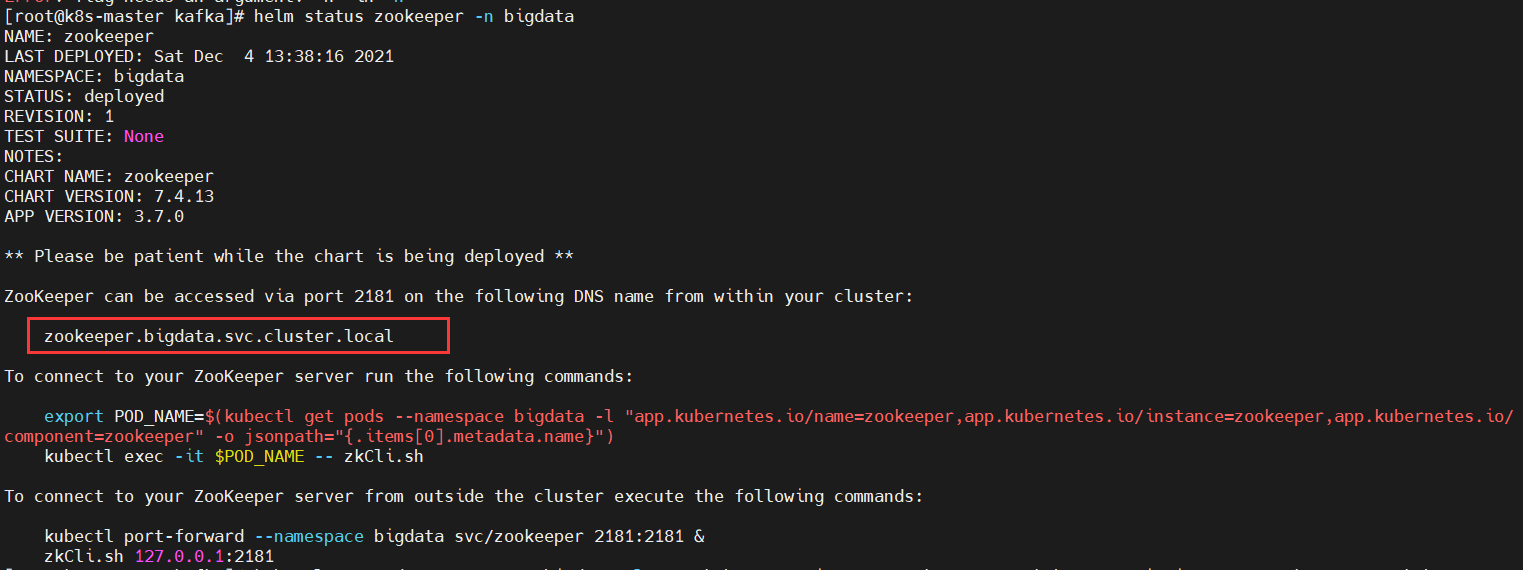
NAME: zookeeper
LAST DEPLOYED: Sat Dec 4 13:38:16 2021
NAMESPACE: bigdata
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: zookeeper
CHART VERSION: 7.4.13
APP VERSION: 3.7.0
** Please be patient while the chart is being deployed **
ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster:
zookeeper.bigdata.svc.cluster.local
To connect to your ZooKeeper server run the following commands:
export POD_NAME=$(kubectl get pods --namespace bigdata -l "app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/ component=zookeeper" -o jsonpath="{.items[0].metadata.name}")
kubectl exec -it $POD_NAME -- zkCli.sh
To connect to your ZooKeeper server from outside the cluster execute the following commands:
kubectl port-forward --namespace bigdata svc/zookeeper 2181:2181 &
zkCli.sh 127.0.0.1:2181
ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster:
zookeeper.bigdata.svc.cluster.local
安装
$ helm install kafka bitnami/kafka \
--namespace bigdata \
--set zookeeper.enabled=false \
--set replicaCount=3 \
--set externalZookeeper.servers=zookeeper.bigdata.svc.cluster.local \
--set persistence.storageClass=bigdata-nfs-storage
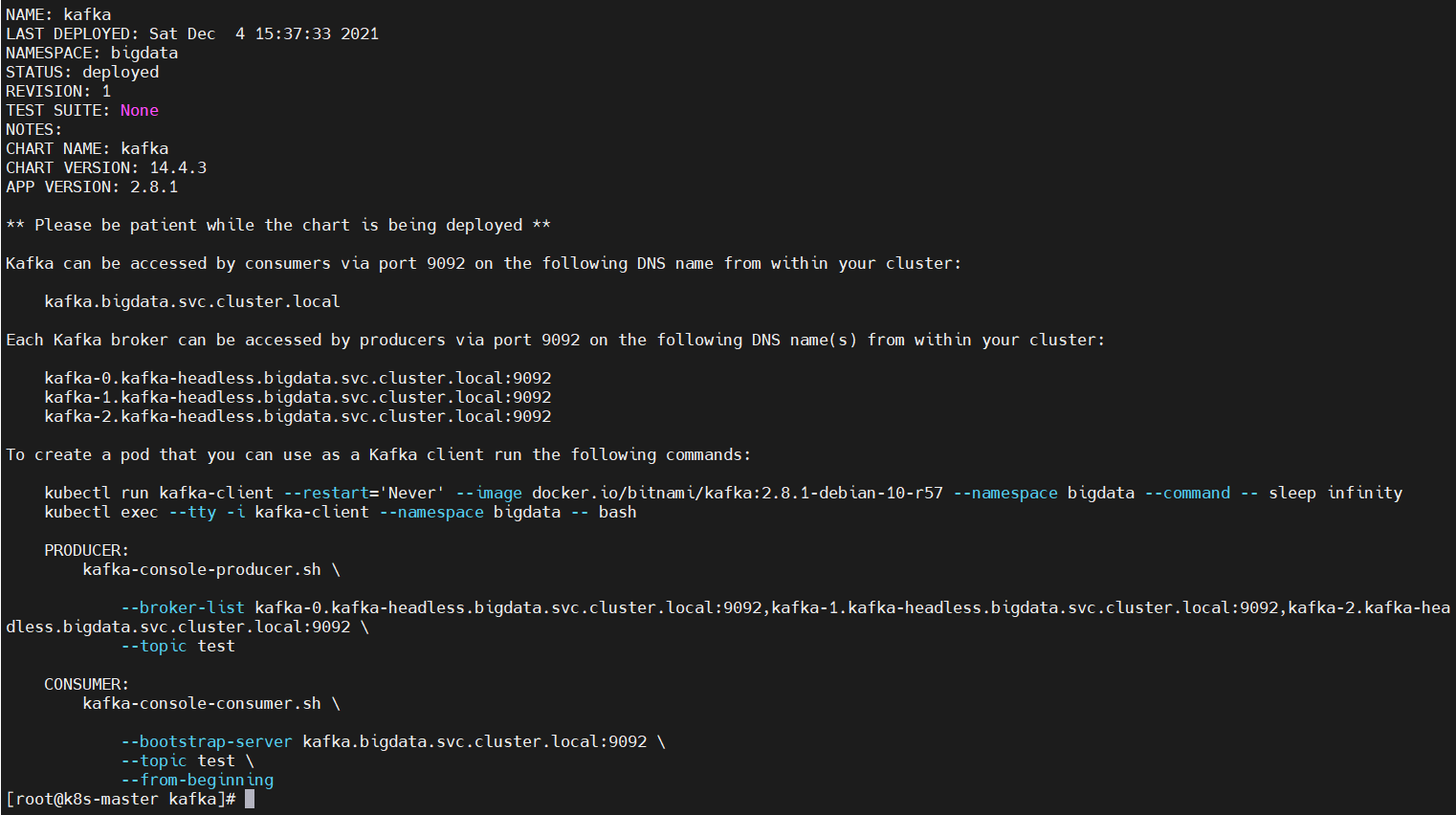
NAME: kafka
LAST DEPLOYED: Sat Dec 4 15:37:33 2021
NAMESPACE: bigdata
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 14.4.3
APP VERSION: 2.8.1
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.bigdata.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.bigdata.svc.cluster.local:9092
kafka-1.kafka-headless.bigdata.svc.cluster.local:9092
kafka-2.kafka-headless.bigdata.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.8.1-debian-10-r57 --namespace bigdata --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace bigdata -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-hea dless.bigdata.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.bigdata.svc.cluster.local:9092 \
--topic test \
--from-beginning
查看
$ kubectl get pod,svc -n bigdata
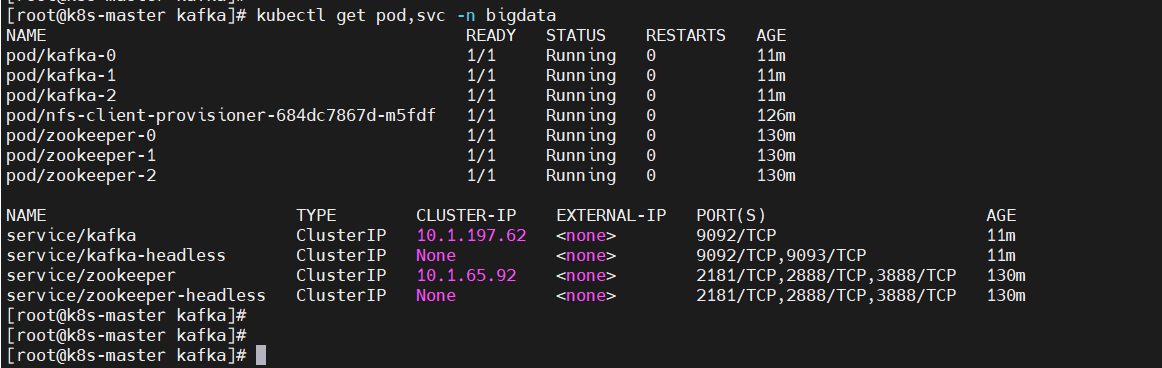
测试,安装上面提示,先创建一个client
$ kubectl run kafka-client --restart='Always' --image docker.io/bitnami/kafka:2.8.1-debian-10-r57 --namespace bigdata --command -- sleep infinity
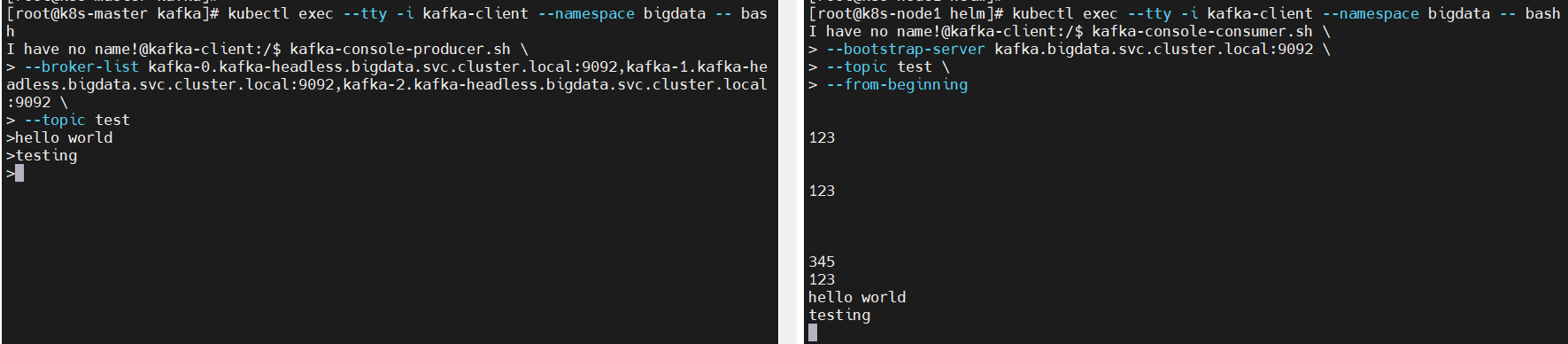
打开两个窗口(一个作为生产者:producer,一个作为消费者:consumer),但是两个窗口都得先登录客户端
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
producer
$ kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-headless.bigdata.svc.cluster.local:9092 \
--topic test
consumer
$ kafka-console-consumer.sh \
--bootstrap-server kafka.bigdata.svc.cluster.local:9092 \
--topic test \
--from-beginning
在producer端输入,consumer会实时打印
1、创建Topic(一个副本一个分区)
--create: 指定创建topic动作
--topic:指定新建topic的名称
--zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--config:指定当前topic上有效的参数值,参数列表参考文档为: Topic-level configuration
--partitions:指定当前创建的kafka分区数量,默认为1个
--replication-factor:指定每个分区的复制因子个数,默认1个
$ kafka-topics.sh --create --topic mytest --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --partitions 1 --replication-factor 1
# 查看
$ kafka-topics.sh --describe --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --topic mytest

2、删除Topic
# 先查看topic列表
$ kafka-topics.sh --list --zookeeper zookeeper.bigdata.svc.cluster.local:2181
# 删除
$ kafka-topics.sh --delete --topic mytest --zookeeper zookeeper.bigdata.svc.cluster.local:2181
# 再查看,发现topic还在
$ kafka-topics.sh --list --zookeeper zookeeper.bigdata.svc.cluster.local:2181
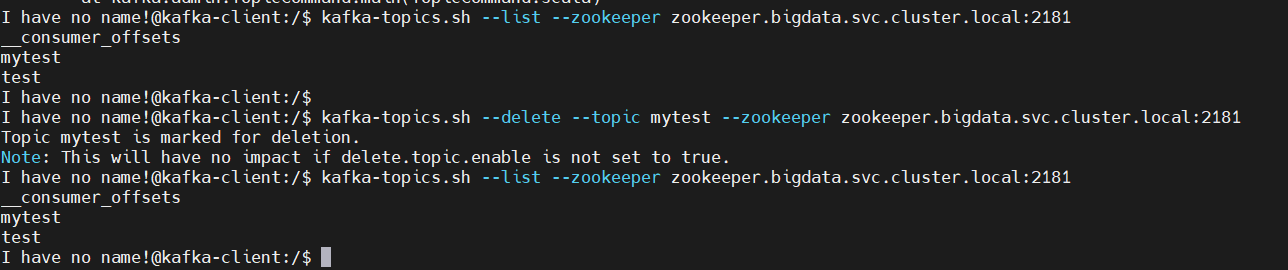
其实上面没删除,只是标记了(只会删除zookeeper中的元数据,消息文件须手动删除)
Note: This will have no impact if delete.topic.enable is not set to true.## 默认情况下,删除是标记删除,没有实际删除这个Topic;如果运行删除Topic,两种方式:
3、修改Topic信息
kafka默认的只保存7天的数据,时间一到就删除数据,当遇到磁盘过小,存放的数据量过大,可以设置缩短这个时间。
# 先创建一个topic
$ kafka-topics.sh --create --topic test001 --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --partitions 1 --replication-factor 1
# 修改,设置数据过期时间(-1表示不过期)
$ kafka-topics.sh --zookeeper zookeeper.bigdata.svc.cluster.local:2181 -topic test001 --alter --config retention.ms=259200000
# 修改多字段
$ kafka-topics.sh --zookeeper zookeeper.bigdata.svc.cluster.local:2181 -topic test001 --alter --config max.message.bytes=128000 retention.ms=259200000
$ kafka-topics.sh --describe --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --topic test001

4、增加topic分区数
$ kafka-topics.sh --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --alter --topic test --partitions 10
$ kafka-topics.sh --describe --zookeeper zookeeper.bigdata.svc.cluster.local:2181 --topic test

5、查看Topic列表
$ kafka-topics.sh --list --zookeeper zookeeper.bigdata.svc.cluster.local:2181

6、列出所有主题中的所有用户组
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --list
7、查询消费者组详情(数据积压情况)
# 生产者
$ kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-headless.bigdata.svc.cluster.local:9092 \
--topic test
# 消费者带group.id
$ kafka-console-consumer.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --topic test --consumer-property group.id=mygroup
# 查看消费组情况
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup
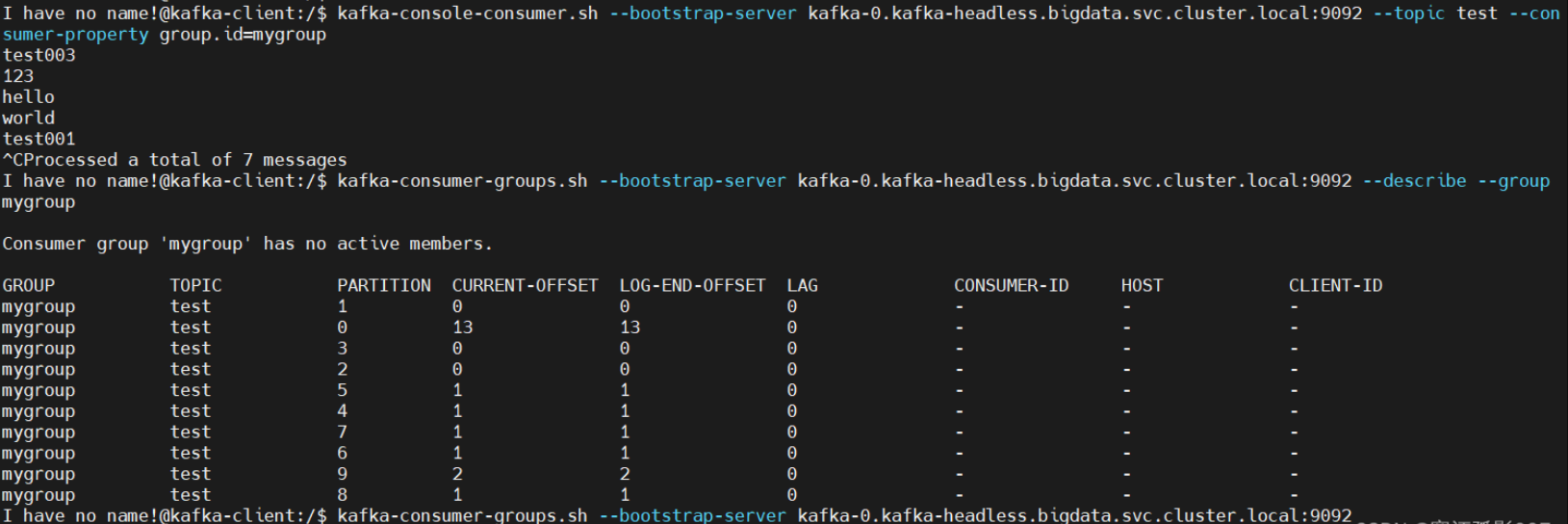
消费积压情况分析
生产和消费的操作上面已经实验过了,这里就不再重复了,更多的操作,可以参考kafka官方文档
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
当我执行>rvminstall1.9.2时一切顺利。然后我做>rvmuse1.9.2也很顺利。但是当涉及到ruby-v时..sam@sjones:~$rvminstall1.9.2/home/sam/.rvm/rubies/ruby-1.9.2-p136,thismaytakeawhiledependingonyourcpu(s)...ruby-1.9.2-p136-#fetchingruby-1.9.2-p136-#downloadingruby-1.9.2-p136,thismaytakeawhiledependingonyourconnection...%Total%Rece