事务指逻辑上的举例:一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。 在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。 事务就是把若干个SQL的操作打包成了一个整体,实际执行的时候,如果这个整体执行了一半,就遇到了突发情况,MySQL就能保证突发情况恢复之后,数据库的数据没有受到破坏. 不是说一定能保证所有的操作都能一口气执行完,实际上是通过"回滚"(Roll Back)机制来对数据进行还原.MySQL中有一个机制 binlog,记录了每一个MySQL的具体操作,就可以依据这个历史记录,把执行一半的事务给还原回去.
在引入事务的概念之前,我们先来设想一下这样的场景,假如数据库中存有两个人,A和B,他们的账户余额分别为1000和800,现在A给B转账50元. 转账这个操作,可以分为两步: ① 先把A的余额减50 ② 再把B的余额加50 本来转的好好的,但是忽然出现了断电/断网/程序崩溃/主机重启等等情况,俗话说,技术再牛逼,也抵不过挖掘机的一铲子啊此时只执行了 ①没有执行② 这个时候该怎么办呢? 为了解决上面的问题,于是引入了事务.
创建一个学生表,同时往里插入一些记录,此处在业务中认为创建学生表并插入10个记录,这是一件事,就可以通过事务把多个SQL打包成一个.
如果这其中的代码执行了一半,Java程序崩溃了,此时就相当于事务没有完全执行完,MySQL就会自动把前面已经执行了的操作进行还原,还原到事务执行之前的模样.
这么做的目的就是为了保证这些SQL是一个整体,要么全都执行,要么全都不执行,不能存在执行一半,剩一半没执行的中间状态.
保证数据库的数据在执行事务之前和之后,都是合理的.
合理性通过人工约定的,比如可以通过约束实现.假如A只有100块,但是要给B转账200,这个时候就是不合理的,就会回滚到转账之前的状态.
一旦事务执行成功,此时这样的数据就是持久保存在磁盘上,就算重启主机,也不会改变.
考虑多个事务并发执行的时候,多线程.
MySQL也是支持并发的,可以有多个客户端同时来执行一些SQL,如果是普通的SQL,MySQL自身可以保证并发执行的结果是对的.如果是多个事务(包含多个SQL),此时并发执行事务,就可能出现一些问题,我们下面就来介绍具体都会出现哪些问题.
比如说:我们此时坐在同一个考场进行笔试。我们在写一到编程题。 当我们写代码的过程中,我们创建一个表,参数(…)。 就在我们写的时候,有个人偷偷在瞄我们的代码。 他就看到我们是怎么去创建这个表的。然后他就咔咔飞速的写起来。 但是呢!我们觉得这个表不合适,把它擦掉改了。 等交的时候,他一看我们的代码怎么改了?? 然后他就GG了。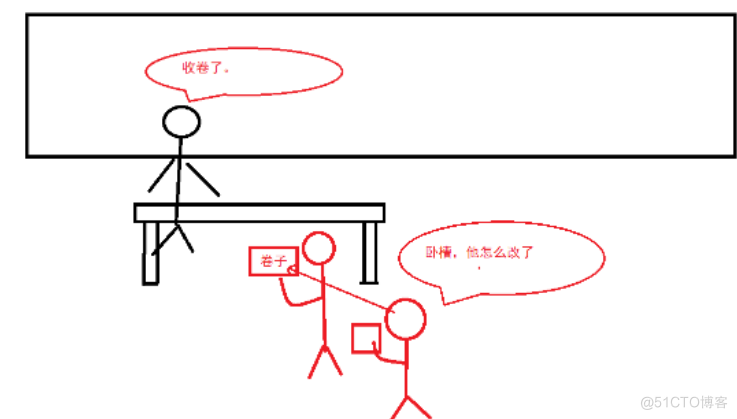
也就是说这个人,他瞄到的数据 不是我们的最终结果,而是我们中间过程的数据。 这个中间过程的数据是能会被改的。 此时的情况,就是脏读。 放在数据库中:事务A在对某个数据进行修改的同时,事务B 去 读取了 这个 数据。 此时,事务B 读到的很可能是一个“脏数据”(这个数据是一个临时的结果,而不是最终的结果) 再举一个例子:测体温,填体温表。 我们测完体温之后,去填体温表。 不知道哪根筋断了,把 36.7, 写成了 46.7。 此时被后方的同志看到了,立马就去打报告了。 等我们将体温改回来的时候。 发现此时,我们被人围住。。。 结果可想而知,不管你是不是真的填错了,都要抓你去隔离了。** 此时的 46.7 就是一个“脏数据”
就是给 写操作 加上锁。 意思就是 在 写的过程中,别人看不到的。(加锁的状态) 写完之后,别人看到了。(解除枷锁)
举个例子: 还是前面的例子,只不过改一下。笔试偷窥不太好。 假设 我们和自己的朋友一起学习代码,遇到他们一道题他们不会,想借鉴一下我们的代码思维。 但是我们和朋友不要急,等我写完,你们再来看。 免得你们看的都是错误的, 现在我们在写代码的时候,就不会有人回过来看。 等我们写完了,才有人来看我们代码。 此时我们就避免了脏读的发生。别人看到的是最终结果,而不是中间数据。 放在数据库中,事务A 在 访问 一个数据的时候,将这个数据上锁,一旦上锁之后,其它事务就不能访问这个数据了,意味着事务之间的隔离性提高了。 并发发生的概率就降低了。【简称并发性降低】
疑问:当我们给数据上锁了,那么我们的事务就没有问题了吗? 答案:不是的!
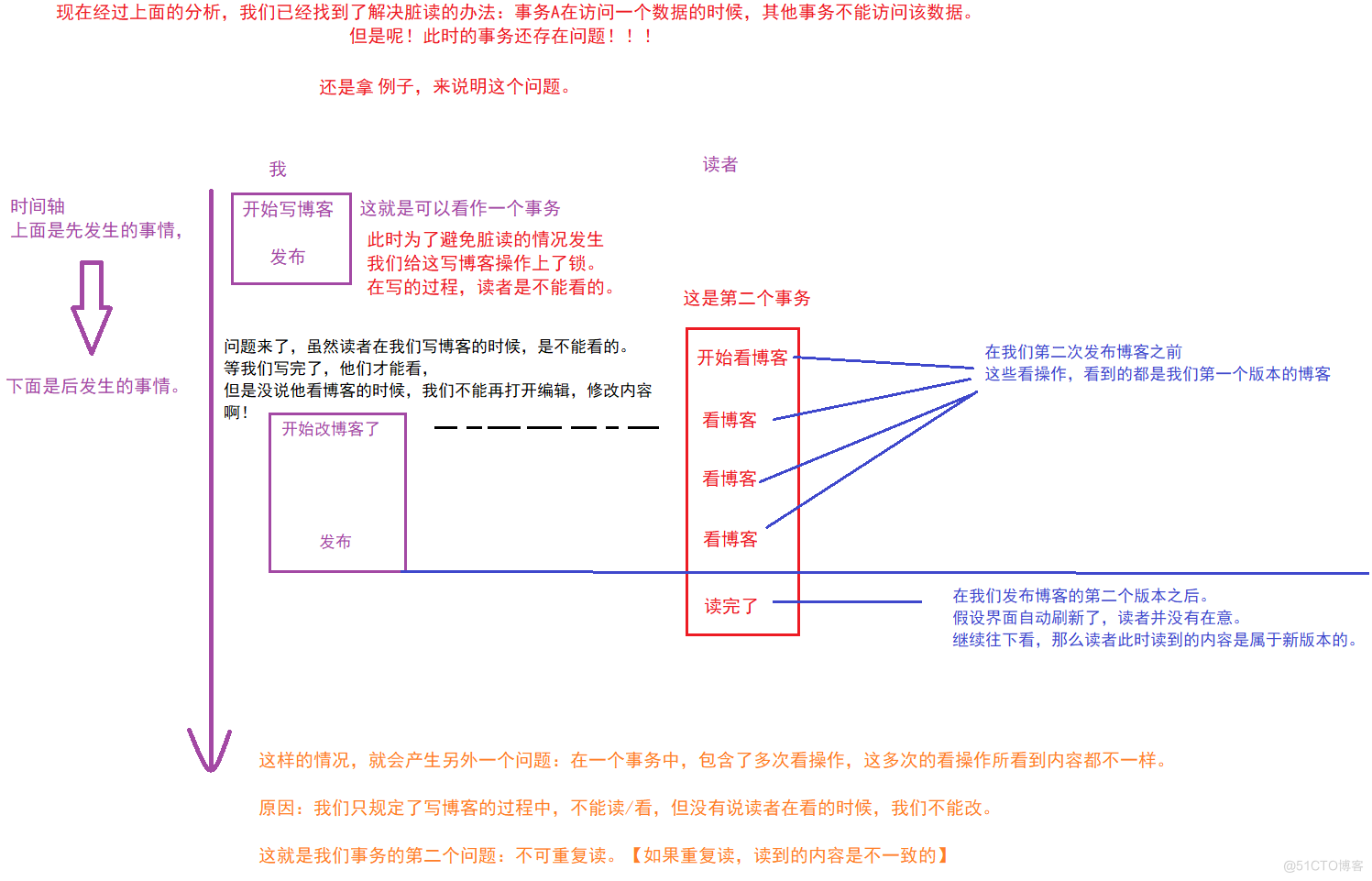
有了脏读的处理经验,不可重复读的问题也就很好处理。 即:当读者进行阅读博客的时候,身为作者的我们不能改动博客。 反过来说:当读者看完了我们的博客,我们才能对其进行改动。 综合来讲:给 读操作也上锁。 也就是说:现在的 情况就是 我们写博客的时候,读者不能阅读;读者阅读的时候,我们不能改博客。 意味着我们必须得等到读者读完了,才能进行修改。 因此通过给读操作也加上锁,就可以解决不可重复读的问题。
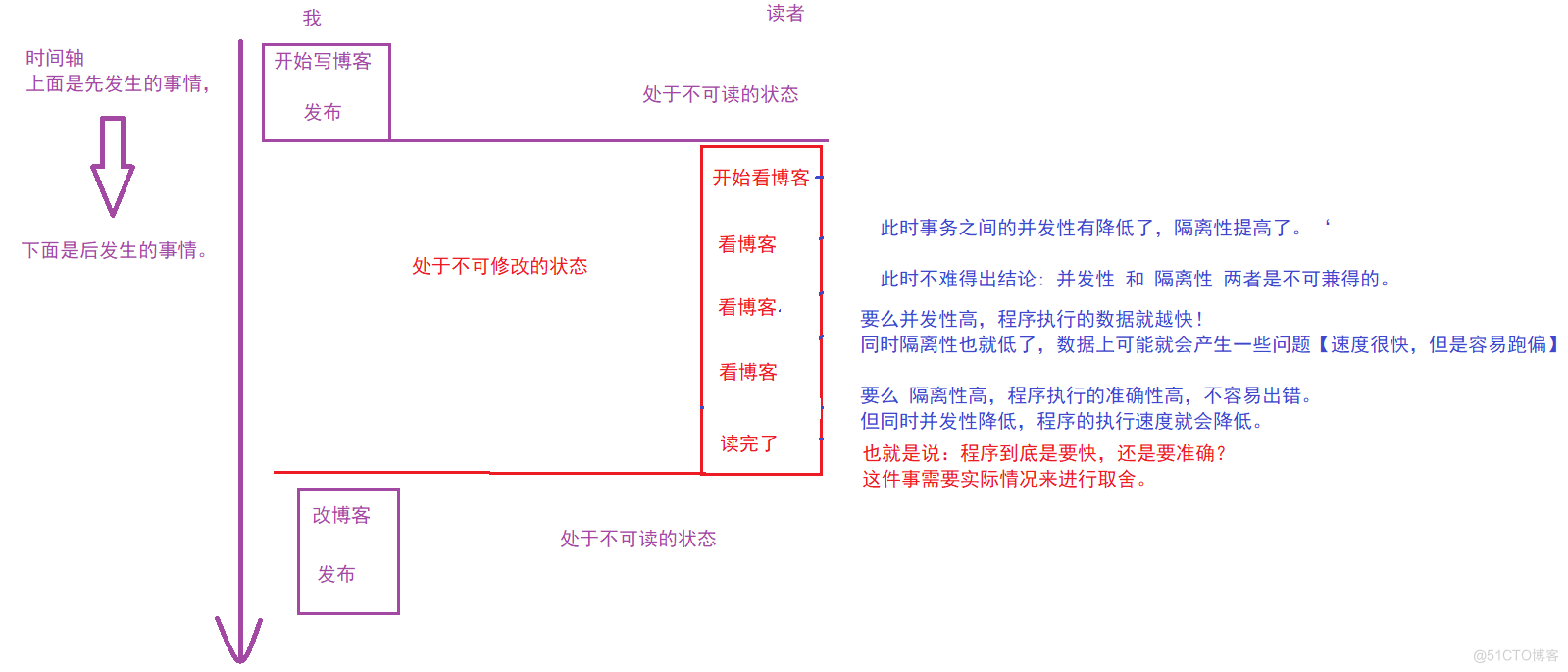
小结
并发性 与 隔离性。 简单来说:并发就是多个事务一起运行。 隔离就是 处理完一个事务后,再处理它的事务(就是一个个来)。
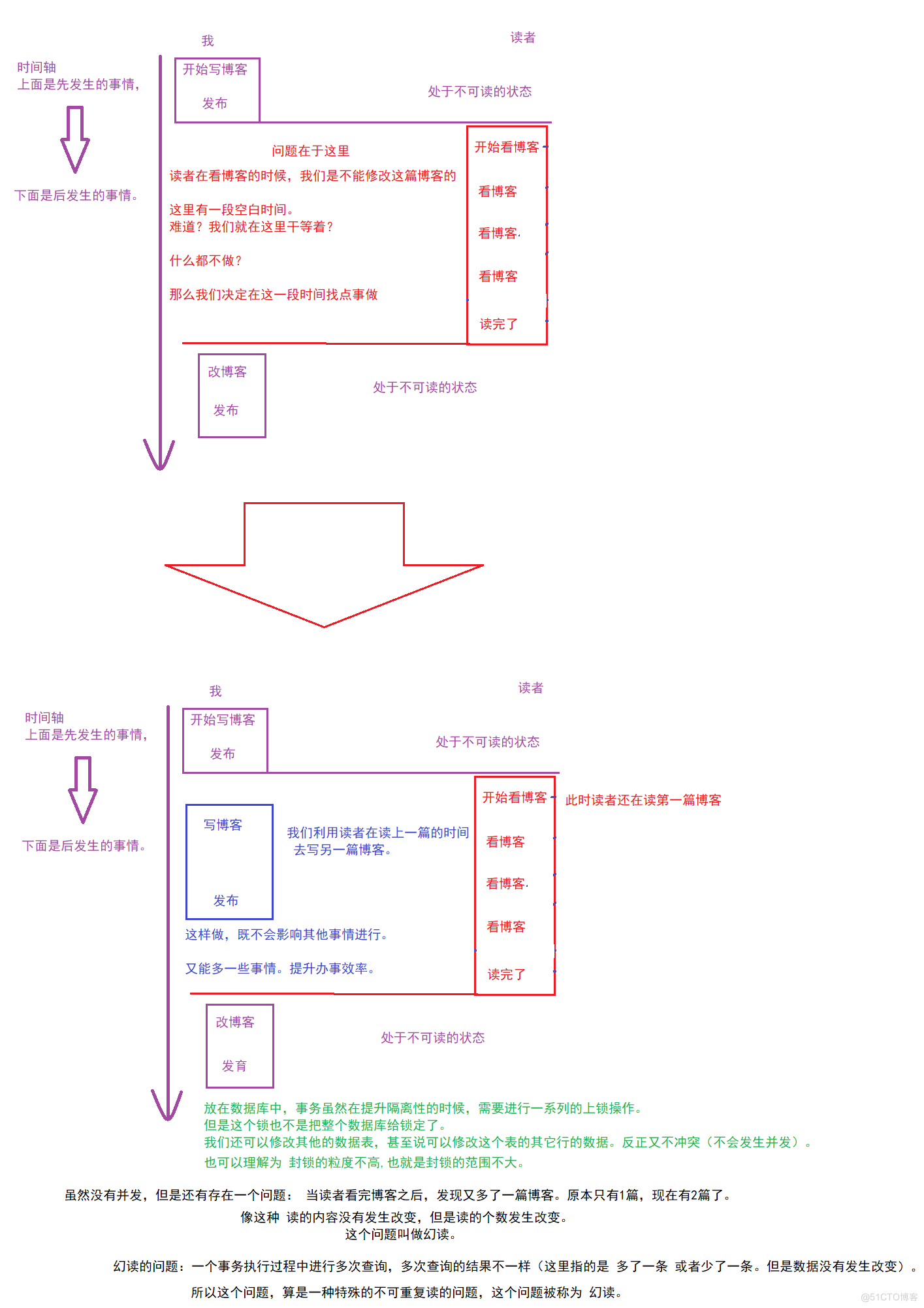
想要解决幻读问题的办法至于一个,彻底串行化执行。 也就是说:读者在读我们的博客的时候,叫我们摸鱼。不要写任何博客了!让我们来卷一卷。 简单来说,就是一个个来,出完一个事务,再处理一下事务,以此类推。(期间不能做任何其他的事务操作。)这种执行方式,隔离性最高,并发性最低,数据最可靠,速度最慢。
以上我所讲的这些,就是关于隔离性相关问题。 并发执行的速度很快;隔离执行的数据最为准确,但是两者是不可以兼得的。 需要根据实际情况进行调整隔离的级别。 通过不同的隔离级别,就控制了事务之间的隔离性,也就是控制了并发程度。 从而在 快与 准之间,找到一个平衡点。
1、read uncommitted:允许读取未提交的数据,并发程度最高,隔离最低,会带有脏读 + 不可重复读 + 幻读问题2、read committed:只允许读取 提交之后的数据,相当于写加锁。并发性降低,隔离性提高。解决脏读,但带有 不可重复读 + 幻读问题3、repeatable read:相当于给读和写操作都上锁了,并发性进一步降低,隔离性进一步提高。解决脏读、不可重复读,但带有 幻读问题。4、serializable:串行化,并发性降到最低(串行执行),隔离程度最高。解决了脏读、不可重复读、幻读问题。但是运行的速度是最低的。MySQL 可以通过修改 配置文件(my.ini) 来进行设置当前的隔离级别。 这样就可以根据实际情况,来决定使用哪种隔离级别。
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和