原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明。
在之前的OOM问题复盘中,我们添加了jmap脚本来自动dump内存现场,方便排查OOM问题。
但当我反复模拟OOM场景测试时,发现jmap有时可以dump成功,有时会报错,如下:

经过网上一顿搜索,发现两种原因可能导致这个问题,一是执行jmap用户与jvm进程用户不一致,二是/tmp/.java_pidXXX文件被删除,但经过检查,这都不是我们jmap失败的原因。
经过了解,jmap导出内存的原理,大致如下:
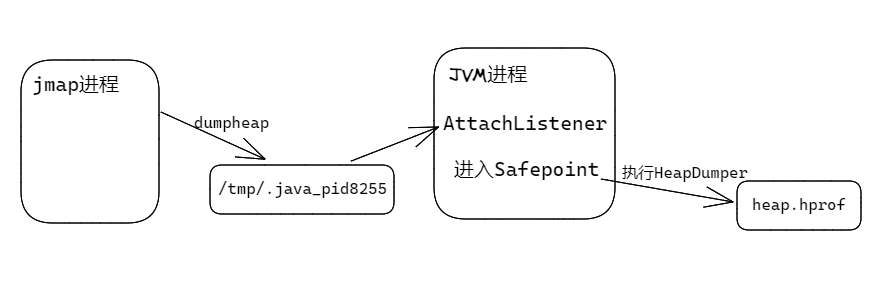
/tmp/.java_pid8255文件,然后发送SIGQUIT信号给jvm。/tmp/.java_pid8255文件,以接收命令。/tmp/.java_pid8255文件,并发送dumpheap命令给jvm,这个过程中jvm会检查命令发送方用户的euid/egid是否与自己一致。可以看出,当jvm已经卡死,或有长时间的GC正在Safepoint中执行,都会导致jmap长时间读不到命令的响应而超时失败!
当给jmap添加-F参数时,jmap会使用Linux的ptrace机制来导出堆内存,ptrace是Linux平台的一种调试机制,像strace、gdb都是基于它开发的,它使得调试进程(jmap)可以直接读取被调试进程(jvm)的原生内存,然后jmap再根据jvm的内存布局规范,将原生内存转换为hprof格式。
但在实际执行时,会发现jmap -F执行得非常慢,可能要几个小时,这是因为ptrace每次只能读一个字的内存,而我们的堆有10G,因此jmap -F对于我们几乎无法使用。
注:这里说的原生程序,指的是类似于C/C++这种直接编译出来、不需要依赖语言虚拟机的程序,而原生内存,指的是通过malloc或mmap等直接申请出来的内存。
有过Linux下原生程序调试经验的,应该会知道gcore这个实用工具,它可用来生成程序原生内存的core文件,然后jstack、jmap等都可以读取此类文件,如下:
# 生成core文件,8787是进程号
$ gcore -o core 8787
Saved corefile core.8787
[Inferior 1 (process 8787) detached]
$ ll -lh core.8787
-rw-r--r-- 1 work work 5.8G 2023-04-16 11:40:00 core.8787
# 从core文件中读取线程栈
$ jstack `which java` core.8787
# 将core文件转换为hprof文件,很慢,建议摘流量后执行
$ jmap -dump:format=b,file=heap.hprof `which java` core.8787
但是当我使用jmap转换core文件时,我发现我本机测试时可以成功,但在测试服务器上却一直报错,如下:

我网上找了好久,都没找到报此错误的原因...
但我发现gcore执行时,是有一些警告信息的,如下:
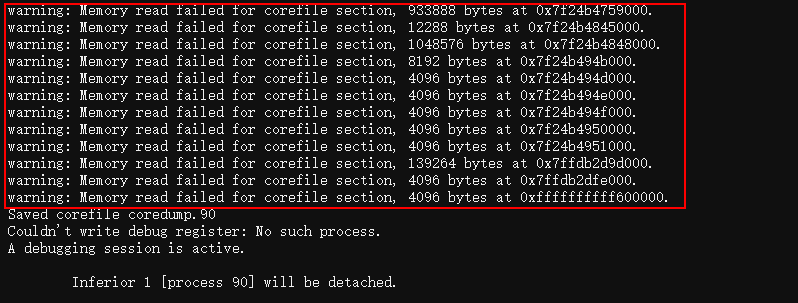
看起来可能是gcore导出的core文件不全,联想到jvm部署在容器中,怀疑是有某些权限限制,导致部分程序内存导出失败了。
除了gcore可以导原生内存,其实Linux内核也有自动的coredump机制,即进程在收到某些信号后,会自动触发内核的coredump机制,内核会负责将进程的原生内存保存为core文件,而内核一般是最高权限运行的,所以它生成的core文件应该是完整的。
先开启coredump机制,如下:
# 检查是否开启,输出unlimited表示core文件不受限制,即完全开启
$ ulimit -c
# 临时开启coredump
$ ulimit -c unlimited
# 永久开启
$ echo "ulimit -c unlimited" >> /etc/profile
然后,配置一下coredump文件保存位置,如下:
# 查看当前配置
$ cat /proc/sys/kernel/core_pattern
/home/core/core.%e.%p.%t
# 配置coredump文件保存位置,并使其生效
$ vi /etc/sysctl.conf
kernel.core_pattern=/home/core/core.%e.%p.%t
$ sysctl –p /etc/sysctl.conf
core_pattern占位符解释
| 占位符 | 解释 |
|---|---|
| %p | pid |
| %u | uid |
| %g | gid |
| %s | signal number |
| %t | UNIX time of dump |
| %h | hostname |
| %e | executable filename |
注:如果没有权限修改core_pattern路径,可考虑使用软链接
ln -s做路径跳转,当然,还需要保证coredump路径有写入权限。
配置ok后,可通过kill发送信号来触发内核coredump,可触发coredump的常见信号如下:
Ctrl+'\'可以产生此信号我选择了SIGABRT信号,即kill -6,经过验证,可生成core文件,而且core文件也能被jmap转换为hprof文件。
有了hprof文件,就可以愉快地使用MAT、JVisualVM、JMC等工具进行内存分析啦?
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
所以我开始关注ruby,很多东西看起来不错,但我对隐式return语句很反感。我理解默认情况下让所有内容返回self或nil但不是语句的最后一个值。对我来说,它看起来非常脆弱(尤其是)如果你正在使用一个不打算返回某些东西的方法(尤其是一个改变状态/破坏性方法的函数!),其他人可能最终依赖于一个返回对方法的目的并不重要,并且有很大的改变机会。隐式返回有什么意义?有没有办法让事情变得更简单?总是有返回以防止隐含返回被认为是好的做法吗?我是不是太担心这个了?附言当人们想要从方法中返回特定的东西时,他们是否经常使用隐式返回,这不是让你组中的其他人更容易破坏彼此的代码吗?当然,记录一切并给出