目录
新建 xlsx 文件,插入数据、插入图标等表格操作。只能新建xlsx后写入xlsx文件。
pip3 install xlsxwriter
import xlsxwriter
import xlsxwriter
# 创建工作簿
workbook = xlsxwriter.Workbook('测试文件.xlsx') # 创建一个excel文件
# 创建工作表
worksheet = workbook.add_worksheet('这是sheet1') # 在文件中创建一个名为这是sheet1的sheet,不加名字默认为sheet1
# 写入数据
worksheet.write(0, 0, '写点什么好') # 第1行第1列(即A1)写入
workbook.close()

举例:
import xlsxwriter
from datetime import datetime
# 创建工作簿
workbook = xlsxwriter.Workbook('测试文件.xlsx') # 创建一个excel文件
# 创建工作表
worksheet = workbook.add_worksheet('这是sheet1') # 在文件中创建一个名为这是sheet1的sheet,不加名字默认为sheet1
# 写入数据
worksheet.write(0, 0, '写点什么好') # 写入字符串
worksheet.write(2, 0, '=SUM(B3:B4)') # 写入excel公式
worksheet.write_formula(4, 0, '=SUM(B3:B4)') # 写入excel公式
date_format = workbook.add_format({'num_format': 'yyyy-mm-dd H:M:S'})
date_format1 = workbook.add_format({'num_format': 'yyyy/m/d;@'})
worksheet.write_datetime(6, 0, datetime.today(),date_format ) # 写入自定义时间
worksheet.write_datetime(6, 2, datetime.today(),date_format1 ) # 写入日期
num_format = workbook.add_format({'num_format': '0.00_);[Red](0.00)'})
worksheet.write_number(8, 0, 1001) # 写入数字(常规)
worksheet.write_number(8, 2, 1001,num_format) # 写入数字(数值)
worksheet.write_row(row = 1 ,col = 3, data = ['嘿嘿','哈哈','呵呵']) # 按行写入:从第几行开始,从第几列开始,写入的值
workbook.close()
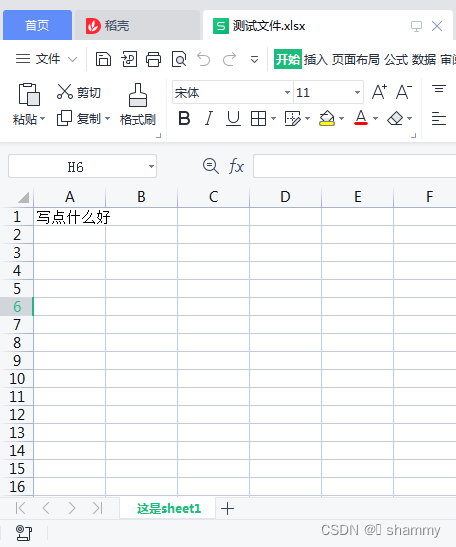
写入公式效果:

写入自定义时间、日期效果:


写入数据效果:

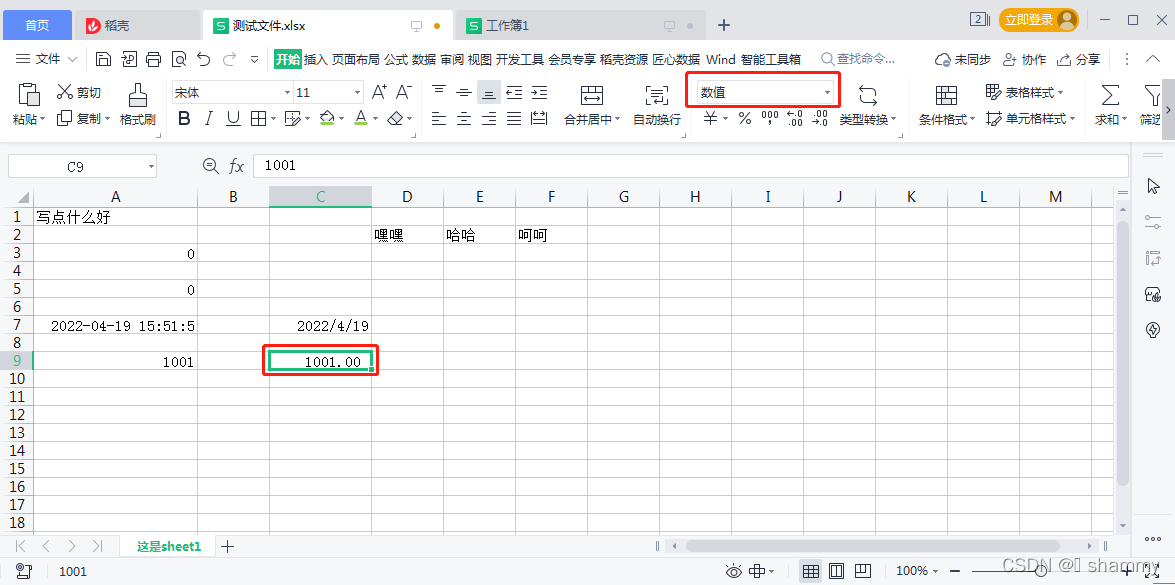
重要!!!怎么知道想要的格式如何表示?
举个例子:我想要写入excel的单元格格式是:货币
1、先在excel写入数据并设置成货币类型

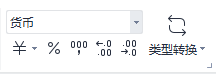
2、按照下图所示在excel设置成自定义,可以看到刚才设置的货币对应的样式:‘¥#,##0.00;¥-#,##0.00’

验证一下:
import xlsxwriter
from datetime import datetime
# 创建工作簿
workbook = xlsxwriter.Workbook('测试文件.xlsx') # 创建一个excel文件
# 创建工作表
worksheet = workbook.add_worksheet('这是sheet1') # 在文件中创建一个名为这是sheet1的sheet,不加名字默认为sheet1
# 写入数据
num_format = workbook.add_format({'num_format': '¥#,##0.00;¥-#,##0.00'})
worksheet.write(8, 0, 120,num_format) # 写入数字(常规)
workbook.close()

import xlsxwriter
workbook = xlsxwriter.Workbook('测试文件.xlsx')
worksheet = workbook.add_worksheet('这是sheet1')
title_format = {
'font_name' : '微软雅黑', # 字体
'font_size': 12, # 字体大小
'font_color': 'black', # 字体颜色
'bold': True, # 是否粗体
'bg_color': '#101010', # 表格背景颜色
'fg_color': '#00FF00', # 前景颜色
'align': 'center', # 水平居中对齐
'valign': 'vcenter', # 垂直居中对齐
# 'num_format': 'yyyy-mm-dd H:M:S',# 设置日期格式
# 后面参数是线条宽度
'border': 1, # 边框宽度
'top': 1, # 上边框
'left': 1, # 左边框
'right': 1, # 右边框
'bottom': 1 # 底边框
}
format = {
'font_size': 10, # 字体大小
'font_color': 'blue', # 字体颜色
'bold': False, # 是否粗体
'bg_color': '#101010', # 表格背景颜色
'fg_color': '#00FF00', # 前景颜色
'align': 'center', # 水平居中对齐
'valign': 'vcenter', # 垂直居中对齐
# 'num_format': 'yyyy-mm-dd H:M:S',# 设置日期格式
# 后面参数是线条宽度
'border': 1, # 边框宽度
'top': 1, # 上边框
'left': 1, # 左边框
'right': 1, # 右边框
'bottom': 1 # 底边框
}
title_style = workbook.add_format(title_format) # 设置样式format是一个字典
style = workbook.add_format(format) # 设置样式format是一个字典
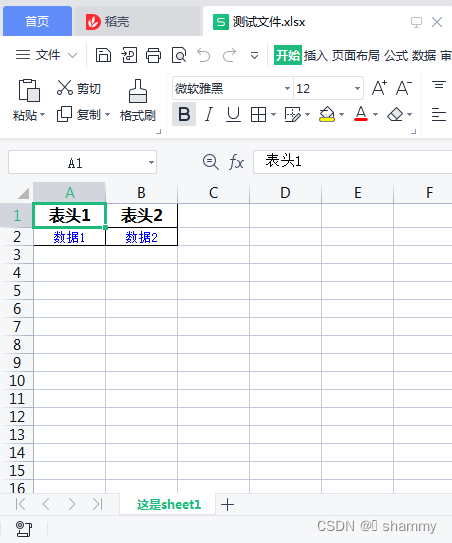
worksheet.write_row(0, 0, ['表头1','表头2'], title_style) # 第一行第一列开始写入表头
worksheet.write_row(1, 0, ['数据1','数据2'], style) # 第二行第一列开始写入数据
workbook.close()
import xlsxwriter
workbook = xlsxwriter.Workbook('测试文件.xlsx')
worksheet1 = workbook.add_worksheet('这是sheet1')
worksheet1.set_tab_color('#0000FF')
worksheet2 = workbook.add_worksheet('这是sheet2')
workbook.close()
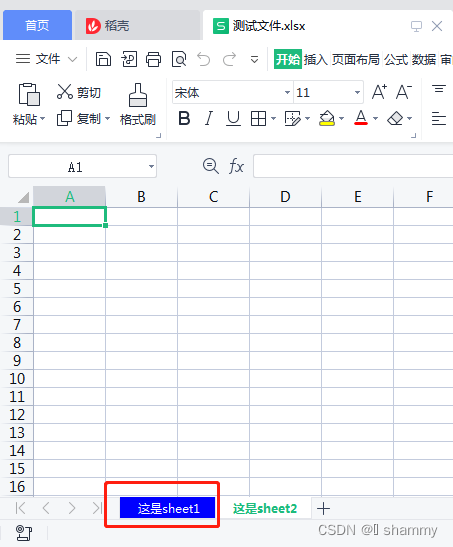
import xlsxwriter
# 创建工作簿
workbook = xlsxwriter.Workbook('测试文件.xlsx')
# 创建工作表
worksheet = workbook.add_worksheet('这是sheet1')
# 写入数据
worksheet.write(0, 0, '这是个很长的字段')
worksheet.write(2, 2, '这是个特别长的字段')
# 设置行宽
worksheet.set_row(0, 60)# 第一行行宽
# 设置列宽
worksheet.set_column(1, 2, 30) # 第二、三列列宽
workbook.close()
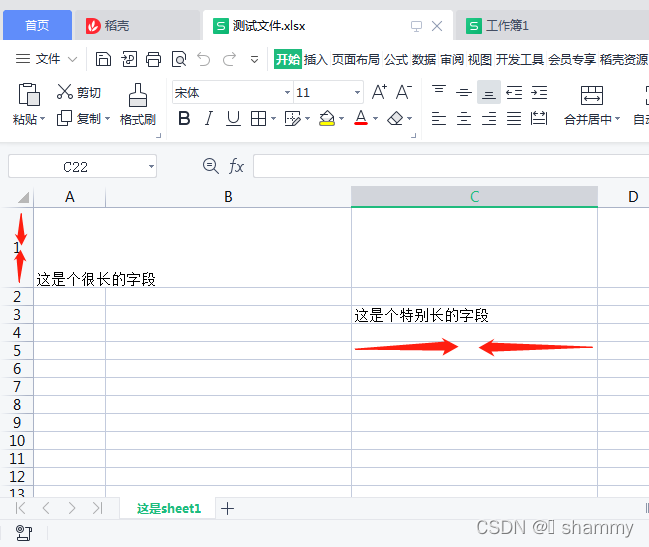
语法:
merge_range(first_row, first_col, last_row, last_col, data[, cell_format])
举例:
import xlsxwriter
from datetime import datetime
# 创建工作簿
workbook = xlsxwriter.Workbook('测试文件.xlsx')
# 创建工作表
worksheet = workbook.add_worksheet('这是sheet1')
# 写入数据
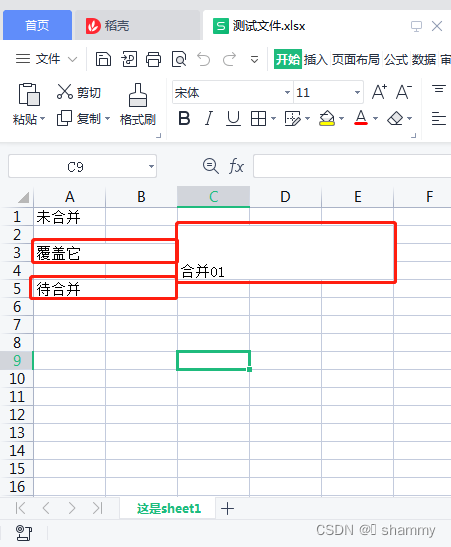
worksheet.write(0, 0, '未合并') # 第一行第一列,A1写入'未合并'
worksheet.write(2, 0, '会被覆盖') # 第三行第一列,A3写入'会被覆盖'
worksheet.write(4, 0, '待合并') # 第五行第一列,A5写入'待合并'
worksheet.merge_range(1,2,3,4,'合并01') # 合并第二行-四行,第三列-五列,即:C2:E4
worksheet.merge_range('A3:B3','覆盖它') # 合并A3:B3,并写入'覆盖它'
worksheet.merge_range('A5:B5','') # 合并A5:B5,'待合并'并不被覆盖
workbook.close()
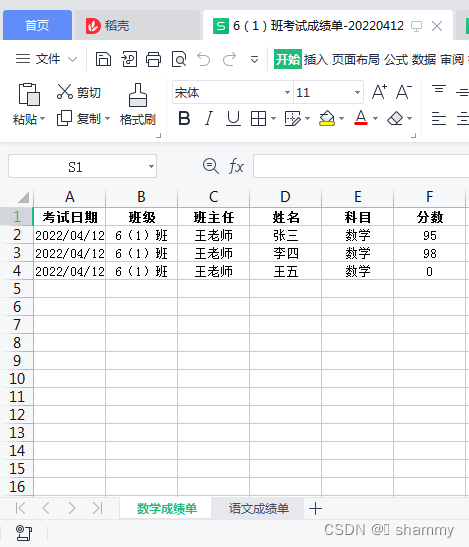
功能描述:
从数据库取数,写入xlsx,并发送邮件。
代码实现:
# util为博主封装的模块
from util import config
from util.gmail import Mail
from util.gstring import convert_df_to_html
from util.logger import log
from util.db import get_db
import pandas as pd
import os
from datetime import datetime
import xlsxwriter
def run(init_date):
#创建excel文件
new_excel = "6(1)班考试成绩单-" + init_date +".xlsx" # 附件
if os.path.exists(new_excel) :
os.remove(new_excel)
workbook = xlsxwriter.Workbook(new_excel)
# 数据库连接
db = get_db("dbcenter")
# 数据库取数
log.info('开始从数据库取数...')
math_sql = f'''
select '张三' as name
,'6(1)班' as class
,'数学' as subject
,95 as score
,{init_date} as init_date
union all
select '李四' as name
,'6(1)班' as class
,'数学' as subject
,98 as score
,{init_date} as init_date
union all
select '王五' as name
,'6(1)班' as class
,'数学' as subject
,null as score
,{init_date} as init_date
'''
chinese_sql = f'''
select '张三' as name
,'6(1)班' as class
,'语文' as subject
,90 as score
,{init_date} as init_date
union all
select '李四' as name
,'6(1)班' as class
,'语文' as subject
,88 as score
,{init_date} as init_date
union all
select '王五' as name
,'6(1)班' as class
,'语文' as subject
,70 as score
,{init_date} as init_date
'''
sqls = [math_sql,chinese_sql]
sheets = ['数学成绩单','语文成绩单']
title_format = {
'font_name': '宋', # 字体
'font_size': 10, # 字体大小
'font_color': 'black', # 字体颜色
'bold': True, # 是否粗体
'align': 'center', # 水平居中对齐
'valign': 'vcenter' # 垂直居中对齐
}
format = {
'font_name': '宋', # 字体
'font_size': 10, # 字体大小
'font_color': 'black', # 字体颜色
'bold': False, # 是否粗体
'align': 'center', # 水平居中对齐
'valign': 'vcenter' # 垂直居中对齐
}
date_format = {
'font_name': '宋', # 字体
'font_size': 10, # 字体大小
'font_color': 'black', # 字体颜色
'align': 'center', # 水平居中对齐
'valign': 'vcenter', # 垂直居中对齐
'num_format': 'yyyy/mm/dd'
}
title_style = workbook.add_format(title_format)
style = workbook.add_format(format)
date_style = workbook.add_format(date_format)
for i in range(0,len(sqls)) :
datas = db.query(sqls[i], {init_date : init_date})
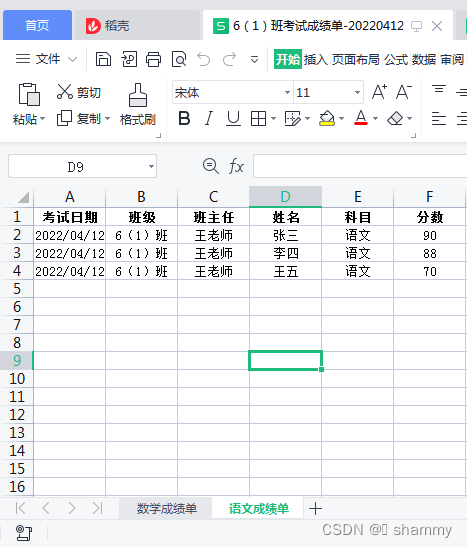
df = pd.DataFrame(datas, columns=['name', 'class', 'subject', 'score', 'init_date'])
df["班主任"] = '王老师'
df["考试日期"] = datetime.strptime(init_date, '%Y%m%d').date()
df = df.rename(columns= {"name":"姓名","class":"班级","subject":"科目","score":"分数"})
order = ["考试日期","班级","班主任","姓名","科目","分数"]
df = df[order].fillna(0)#缺考分数为0
log.info(df)
datas = [tuple(xi) for xi in df.values]
excel_data = [tuple(order)] + datas
worksheet = workbook.add_worksheet(sheets[i])
for i in range(0,len(excel_data)):
for j in range(0,len(excel_data[i])):
if i == 0:
worksheet.write(i, j, excel_data[i][j], title_style)
elif j == 0:
worksheet.write_datetime(i, j, datetime.strptime(init_date, '%Y%m%d').date(), date_style) # 写入时间
else:
worksheet.write(i, j, excel_data[i][j], style)
workbook.close()
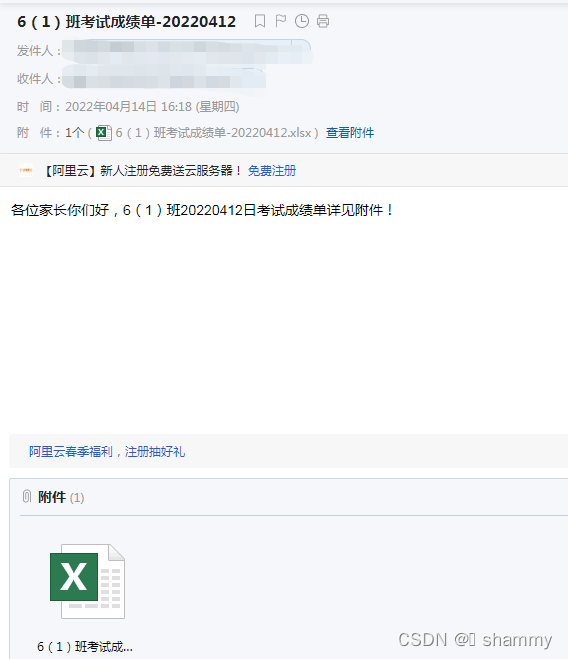
#发邮件
#html = convert_df_to_html(df)
mail_config = config.get_config("email.send_fxm")# 发件人
mail = Mail(mail_config)
title = '6(1)班考试成绩单-' + init_date # 邮件标题
to_list = 'xxx.com' # 收件人
mail.send_email(to_list, title,content_text = '各位家长你们好,6(1)班'+ init_date + '日考试成绩单详见附件!', attachment_list=[new_excel])
if __name__ == "__main__":
init_date = '20220412'
run(init_date)
效果:
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht