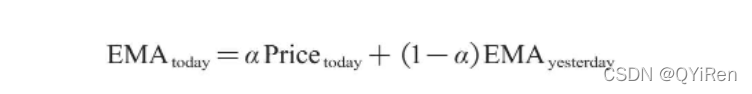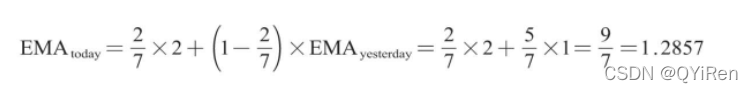目录
集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。
集成学习模型的常见算法有Bagging算法和Boosting算法两种。
Bagging算法的典型机器学习模型为随机森林模型,而Boosting算法的典型机器学习模型则为AdaBoost、GBDT、XGBoost和LightGBM模型。
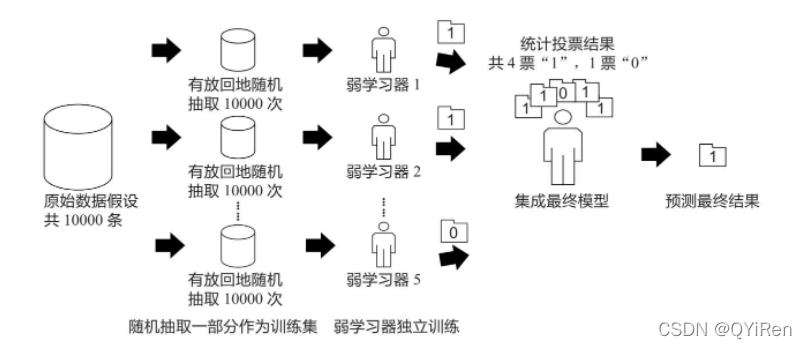
Bagging算法的原理类似投票,每个弱学习器都有一票,最终根据所有弱学习器的投票,按照“少数服从多数”的原则产生最终的预测结果,如下图所示。
假设原始数据共有10000条,从中随机有放回地抽取10000次数据构成一个新的训练集(因为是随机有放回抽样,所以可能出现某一条数据多次被抽中,也有可能某一条数据一次也没有被抽中),每次使用一个训练集训练一个弱学习器。这样有放回地随机抽取n次后,训练结束时就能获得由不同的训练集训练出的n个弱学习器,根据这n个弱学习器的预测结果,按照“少数服从多数”的原则,获得一个更加准确、合理的最终预测结果。
具体来说,在分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果。
Boosting算法的本质是将弱学习器提升为强学习器,它和Bagging算法的区别在于:Bagging算法对待所有的弱学习器一视同仁;而Boosting算法则会对弱学习器“区别对待”,通俗来讲就是注重“培养精英”和“重视错误”。
“培养精英”就是每一轮训练后对预测结果较准确的弱学习器给予较大的权重,对表现不好的弱学习器则降低其权重。这样在最终预测时,“优秀模型”的权重是大的,相当于它可以投出多票,而“一般模型”只能投出一票或不能投票。
“重视错误”就是在每一轮训练后改变训练集的权值或概率分布,通过提高在前一轮被弱学习器预测错误的样例的权值,降低前一轮被弱学习器预测正确的样例的权值,来提高弱学习器对预测错误的数据的重视程度,从而提升模型的整体预测效果。
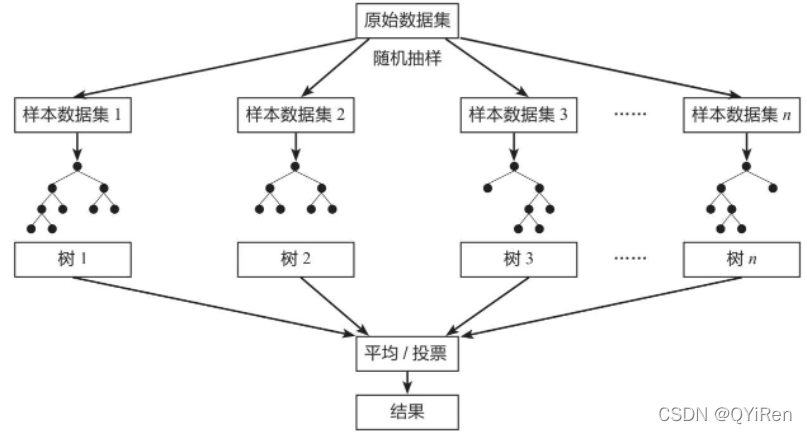
随机森林(Random Forest)是一种经典的Bagging模型,其弱学习器为决策树模型。如下图所示,随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型)或者投票情况(针对分类模型)来获取最终结果。
为了保证模型的泛化能力(或者说通用能力),随机森林模型在建立每棵树时,往往会遵循“数据随机”和“特征随机”这两个基本原则。
数据随机:从所有数据当中有放回地随机抽取数据作为其中一个决策树模型的训练数据。例如,有1000个原始数据,有放回地抽取1000次,构成一组新的数据,用于训练某一个决策树模型。
特征随机:如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征。
与单独的决策树模型相比,随机森林模型由于集成了多个决策树,其预测结果会更准确,且不容易造成过拟合现象,泛化能力更强。
随机森林模型既能进行分类分析,又能进行回归分析,对应的模型分别为:
·随机森林分类模型(RandomForestClassifier)
·随机森林回归模型(RandomForestRegressor)
随机森林分类模型的弱学习器是分类决策树模型,随机森林回归模型的弱学习器则是回归决策树模型。
代码如下。
from sklearn.ensemble import RandomForestClassifier
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,0,1,1]
# 设置弱学习器数量为10
model = RandomForestClassifier(n_estimators=10,random_state=123)
model.fit(X,y)
model.predict([[5,5]])
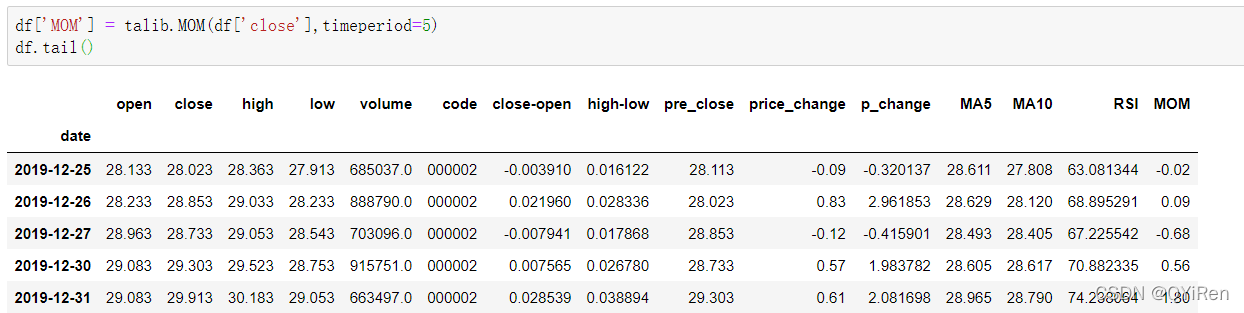
# 输出为:array([0])本节讲解如何利用股票的基本数据获取一些衍生变量数据,如股票技术分析常用的均线指标5日均线价格MA5与10日均线价格MA10、相对强弱指标RSI、动量指标MOM、指数移动平均值EMA、异同移动平均线MACD等。
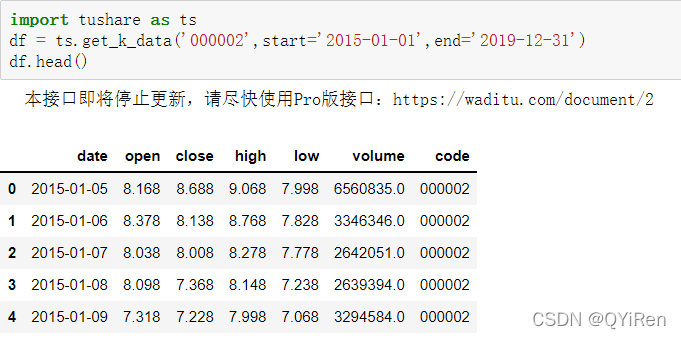
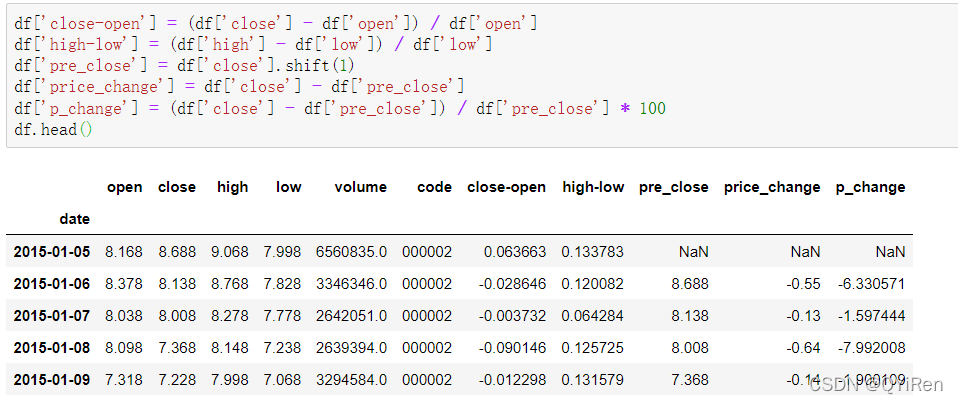
首先用get_k_data()函数获取2015-01-01到2019-12-31的股票基本数据,代码如下。
前5行数据如下图所示,其中缺失的数据为节假日(非交易日)数据。
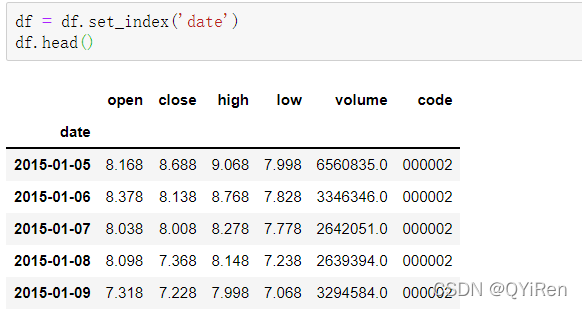
用set_index()函数将date列设置为行索引,代码如下。
通过如下代码可以生成一些简单的衍生变量数据。
close-open表示(收盘价-开盘价)/开盘价;
high-low表示(最高价-最低价)/最低价;
pre_close表示昨日收盘价,用shift(1)将close列的所有数据向下移动1行并形成新的1列,如果是shift(-1)则表示向上移动1行;
price_change表示今日收盘价-昨日收盘价,即当天的股价变化;
p_change表示当天股价变化的百分比,也称为当天股价的涨跌幅。
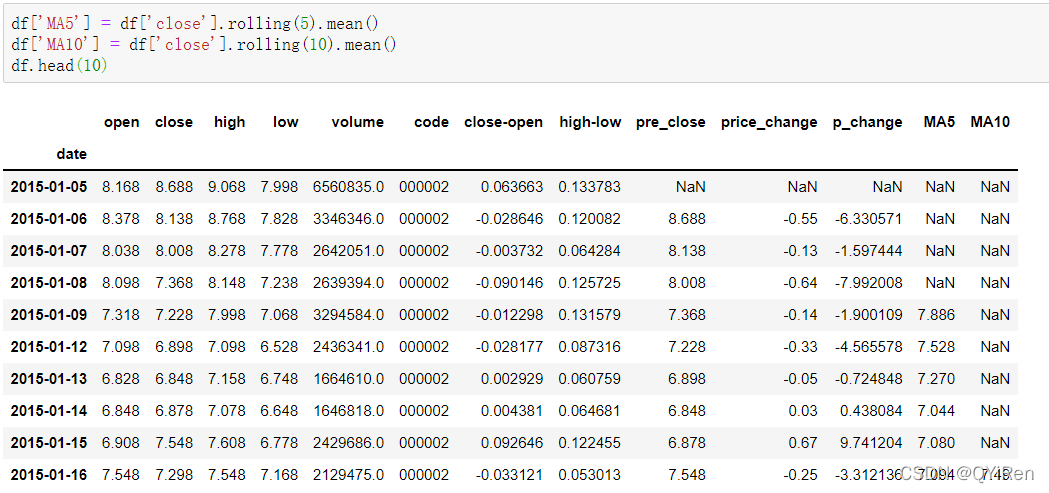
通过如下代码可以生成股价的5日移动平均值和10日移动平均值。
注意:rolling函数的使用
其中,MA是移动平均线的意思,“平均”是指最近n天收盘的算术平均值,“移动”是指在计算中始终采用最近n天的价格数据。
例如:MA5的计算
根据上述数据,5号的MA5值为(1.2+1.4+1.6+1.8+2.0)/5=1.6,而6号的MA5值则为(1.4+1.6+1.8+2.0+2.2)/5=1.8,依此类推。将一段时期内股价的移动平均值连成曲线,即为移动平均线。同理,MA10为从计算当天起前10天的股价平均值。
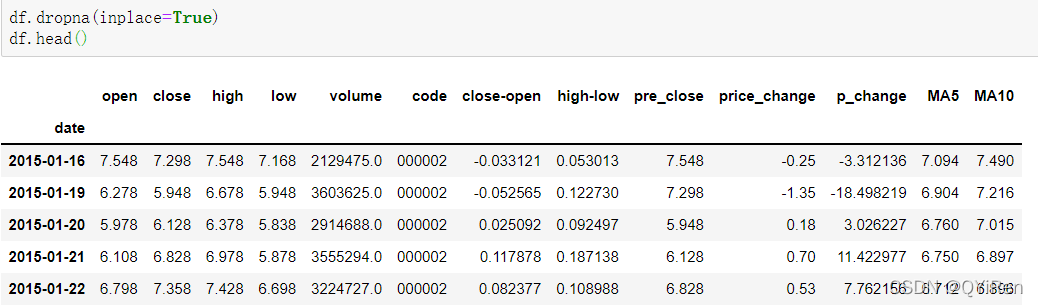
在计算像MA5这样的数据时,因为最开始的4天数据量不够,这4天对应的移动平均值是无法计算出来的,所以会产生空值NaN。通常会用dropna()函数删除空值,以免在后续计算中出现因空值造成的问题,代码如下。
可以看到16号以前的行被删除。
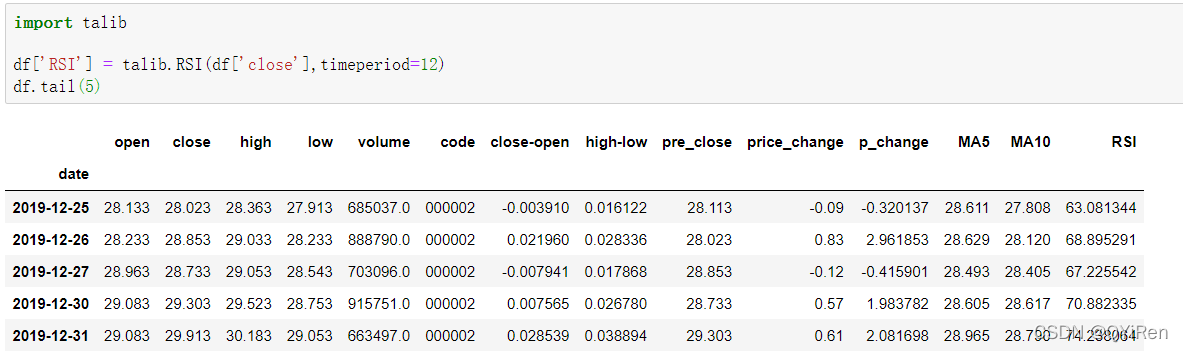
通过如下代码可以生成相对强弱指标RSI值。
RSI值能反映短期内股价涨势相对于跌势的强弱,帮助我们更好地判断股价的涨跌趋势。
RSI值越大,涨势相对于跌势越强,反之则涨势相对于跌势越弱。
RSI值的计算公式如下。
举例:
根据上表数据,取N=6,可求得6日平均上涨价格为(2+2+2)/6=1,6日平均下跌价格为(1+1+1)/6=0.5,所以RSI值为(1/(1+0.5))×100=66.7。
通常情况下,RSI值位于20~80之间,超过80则为超买状态,低于20则为超卖状态,等于50则认为买卖双方力量均等。例如,如果连续6天股价都是上涨,则6日平均下跌价格为0,6日RSI值为100,表明此时股票买方处于非常强势的地位,但也提醒投资者要警惕此时可能也是超买状态,需要预防股价下跌的风险。
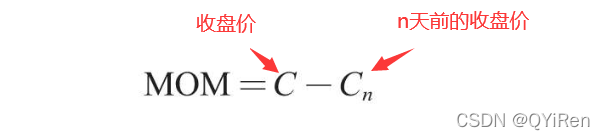
通过如下代码可以生成动量指标MOM值。
MOM是momentum(动量)的缩写,它反映了一段时期内股价的涨跌速度,计算公式如下。
举例:
假设要计算6号的MOM值,而前面的代码中设置参数timeperiod为5,那么就需要用6号的收盘价减去1号的收盘价,即6号的MOM值为2.2-1.2=1,同理,7号的MOM值为2.4-1.4=1。将连续几天的MOM值连起来就构成一条反映股价涨跌变动的曲线。
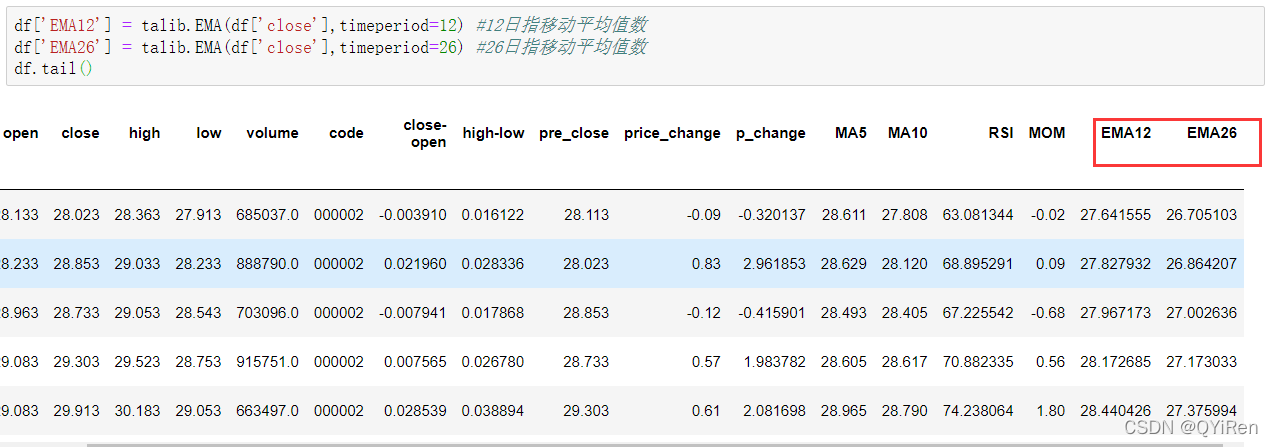
通过如下代码可以生成指数移动平均值EMA。
EMA是以指数式递减加权的移动平均,并根据计算结果进行分析,用于判断股价未来走势的变动趋势。
EMA的计算公式如下。
其中,EMAtoday为当天的EMA值;Pricetoday为当天的收盘价;EMAyesterday为昨天的EMA值;α为平滑指数,一般取值为2/(N+1),N表示天数,当N为6时,α为2/7,对应的EMA称为EMA6,即6日指数移动平均值。公式不断递归,直至第1个EMA值出现(第1个EMA值通常为开头5个数的均值)。
举例:EMA6
取第1个EMA值为开头5个数的均值,故前5天都没有EMA值;6号的EMA值就是第1个EMA值,为前5天的均值,即1;7号的EMA值为第2个EMA值,计算过程如下。
通过如下代码可以生成异同移动平均线MACD值。
MACD是股票市场上的常用指标,它是基于EMA值的衍生变量,计算方法比较复杂,感兴趣的读者可以自行了解。这里只需要知道MACD是一种趋势类指标,其变化代表着市场趋势的变化,不同K线级别的MACD代表当前级别周期中的买卖趋势。
# 导入相关库
import tushare as ts
import numpy as np
import pandas as pd
import talib
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 1.股票基本数据获取
import tushare as ts
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date')
# 2.简单衍生变量数据构造
df['close-open'] = (df['close'] - df['open']) / df['open']
df['high-low'] = (df['high'] - df['low']) / df['low']
df['pre_close'] = df['close'].shift(1)
df['price_change'] = df['close'] - df['pre_close']
df['p_change'] = (df['close'] - df['pre_close']) / df['pre_close'] * 100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True)
# 4.通过TA-Lib库构造衍生变量数据
df['RSI'] = talib.RSI(df['close'],timeperiod=12)
df['MOM'] = talib.MOM(df['close'],timeperiod=5)
df['EMA12'] = talib.EMA(df['close'],timeperiod=12) #12日指移动平均值数
df['EMA26'] = talib.EMA(df['close'],timeperiod=26) #26日指移动平均值数
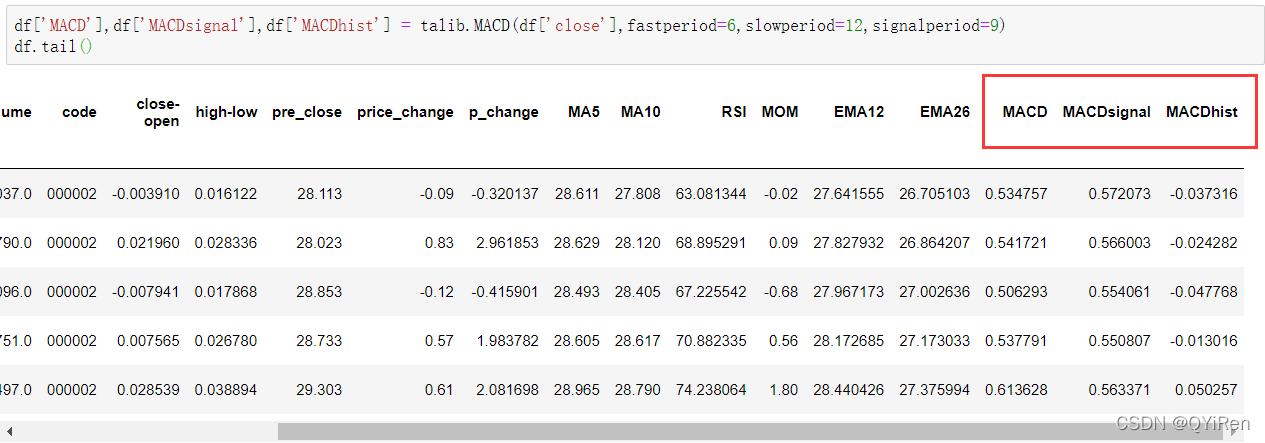
df['MACD'],df['MACDsignal'],df['MACDhist'] = talib.MACD(df['close'],fastperiod=6,slowperiod=12,signalperiod=9)
df.dropna(inplace=True)X = df[['close','volume','close-open','MA5','MA10','high-low','RSI','MOM','EMA12','MACD','MACDsignal','MACDhist']]
y = np.where(df['price_change'].shift(-1) > 0,1,-1)首先强调最核心的一点:应该是用当天的股价数据预测下一天的股价涨跌情况,所以目标变量y应该是下一天的股价涨跌情况。为什么是用当天的股价数据预测下一天的股价涨跌情况呢?这是因为特征变量中的很多数据只有在当天交易结束后才能确定(例如,收盘价close只有收盘了才有),所以当天正在交易时的股价涨跌情况是无法预测的,而等到收盘时尽管所需数据齐备,但是当天的股价涨跌情况已成定局,也就没有必要预测了,所以是用当天的股价数据预测下一天的股价涨跌情况。
第2行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df['price_change'].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。
这里需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征,所以需要根据当天的股价数据预测下一天的股价涨跌情况,而不能根据任意一天的股价数据预测下一天的股价涨跌情况。
将前90%的数据作为训练集,后10%的数据作为测试集,代码如下。
X_length = X.shape[0]
split = int(X_length * 0.9)
X_train,X_test = X[:split],X[split:]
y_train,y_test = y[:split],y[split:]model = RandomForestClassifier(max_depth=3,n_estimators=10,min_samples_leaf=10,random_state=123)
model.fit(X_train,y_train)设置模型参数:决策树的最大深度max_depth设置为3,即每个决策树最多只有3层;弱学习器(即决策树模型)的个数n_estimators设置为10,即该随机森林中共有10个决策树;叶子节点的最小样本数min_samples_leaf设置为10,即如果叶子节点的样本数小于10则停止分裂;随机状态参数random_state的作用是使每次运行结果保持一致,这里设置的数字123没有特殊含义,可以换成其他数字。
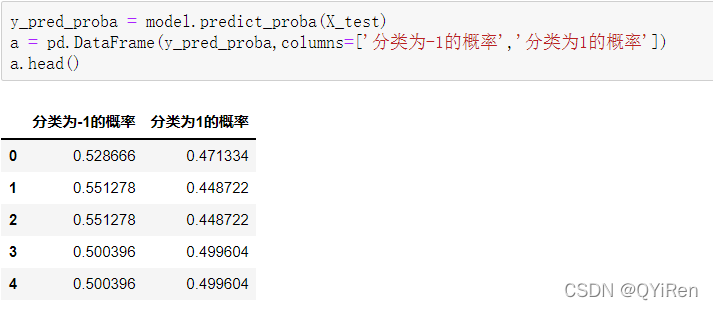
用predict_proba()函数可以预测属于各个分类的概率,代码如下。
通过如下代码可以查看整体的预测准确度。
打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。
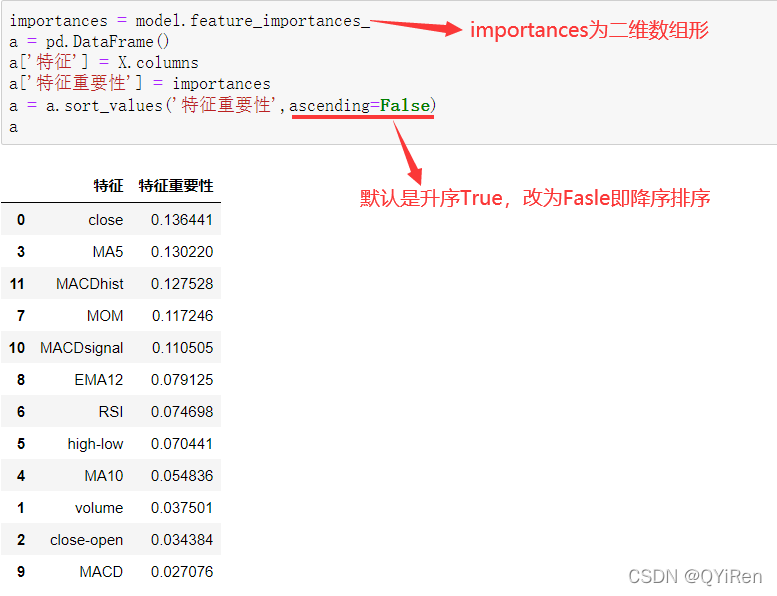
通过如下代码可以分析各个特征变量的特征重要性。
由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。
from sklearn.model_selection import GridSearchCV
parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]}
new_model = RandomForestClassifier(random_state=123)
grid_search = GridSearchCV(new_model,parameters,cv=6,scoring='accuracy')
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出
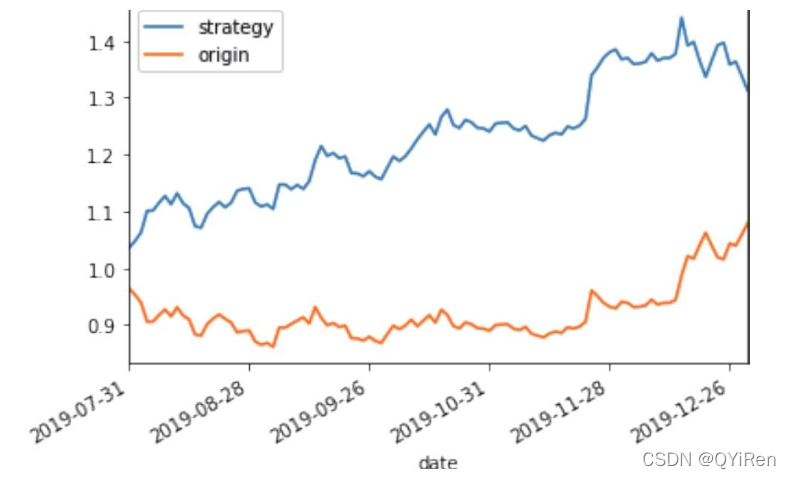
# {'max_depth': 5, 'min_samples_leaf': 20, 'n_estimators': 5}前面已经评估了模型的预测准确度,不过在商业实战中,更关心它的收益回测曲线(又称为净值曲线),也就是看根据搭建的模型获得的结果是否比不利用模型获得的结果更好。
# 在测试数据上添加一列,预测收益
X_test['prediction'] = model.predict(X_test)
# 计算每天的股价变化率
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
# 计算累积收益率
# 例如,初始股价是1,2天内的价格变化率为10%
# 那么用cumprod()函数可以求得2天后的股价为1×(1+10%)×(1+10%)=1.21
# 此结果也表明2天的收益率为21%。
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
# 计算利用模型预测后的收益率
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy','origin']].dropna().plot()
# 设置自动倾斜
plt.gcf().autofmt_xdate()
plt.show()可视化结果如下图所示。图中上方的曲线为根据模型得到的收益率曲线,下方的曲线为股票本身的收益率曲线,可以看到,利用模型得到的收益还是不错的。
要说明的是,这里讲解的量化金融内容比较浅显,搭建的模型过于理想化,真正的股市是错综复杂的,股票交易也有很多限制,如不能做空、不能T+0交易,还要考虑手续费等因素。
随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛。
《Python大数据分析与机器学习商业案例实战》
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序