💐文章适合于所有的相关人士进行学习💐
🍀各位看官看完了之后不要立刻转身呀🍀
🌿期待三连关注小小博主加收藏🌿
🍃小小博主回关快 会给你意想不到的惊喜呀🍃
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!
文章目录


我们上次已经讲解完了关于KNN也就是K近邻模型得相关知识,我们知道了邻居得重要性!!!这节课我们主要讲解朴素贝叶斯模型得相关知识和实践内容,那么他这个模型为什么朴素,是这个朴素吗?

是这样得朴素之美吗???这节课我们将解开大家得谜团。
朴素贝叶斯模型主要也是做分类用得,那么什么是分类呢?就比如说好或者不好,一件商品买或者不买,一次相亲去或者不去这都属于分类问题。我们去相亲这个事男生倒是很随意,女孩子可能要求得比较多一点,比如会看重男孩子的工作啦,收入啦,或者是相貌了,或者是教育程度啦等等,往往通过这些个因素我们可以进行分析,然后通过数学公式得计算,来去预测这场相亲去或者不去?还有很多例子,比如说银行得借贷系统,通过判断一个人过去得信用、收入等等因素来判断是否向该人进行借贷。生活中这种例子数不胜数,所以说机器学习和我们得生活就是息息相关得,我们要让其为我们服务,也是未来一个主流得方向。那么闲话少说我们进入今天得正题。

该分类器的实现思想非常简单,即通过已知类别的训练数据集,计算样本的先验概率,然后利用贝叶斯概率公式测算未知类别样本属于某个类别的后验概率,最终以最大后验概率所对应的类别作为样本的预测值。这就是我们所谓得朴素贝叶斯模型得思想。那么我们需要什么呢?概率公式是什么呢?贝叶斯计算得数学公式又是什么呢?它们分别适合于什么方面呢?
条件概率公式也就是我们说的后验概率:

对于条件概率公式,如果我们学习过统计学或者概率论,这个公式并不难理解,很简单。全概率公式:
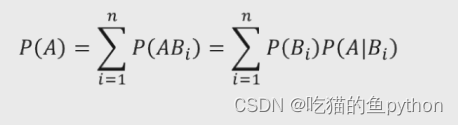
我们将上方公式进行了整理,就得到了下方公式:
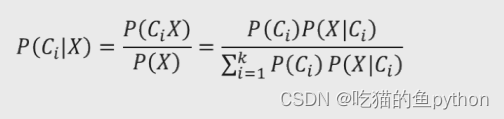
这里表达得意思就是在我们已经X得发生情况概率下,求发生Ci得概率。最后我们得到的公式中分母是已经知道得,且P(Ci)也是已经得表达得意思就是频数除以总数得意思,也就是我们常说的频率,所以如果我们像要求得P(Ci|X)得最大概率值,那么我们也就是只要求P(X|Ci)得最大概率值就OK了!
这里我们依旧举一个例子:
比如说一件商品我们想要在已知收入得情况下看购买得概率或者不购买得概率,那么我们P(购|X)=0.7,P(不购|X)=0.3,那么我们果断得选择购买啊!这就是这个意思。上图公式也可以遵循这个例子来理解。
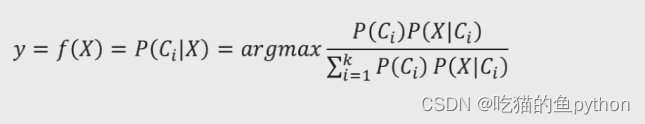
目标函数就是这个!!经过上方得分析我们可以得到
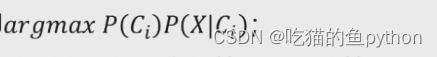
假设数据集包含p个变量,那么我们X可以表示为(x1,x2…xp),进而条件概率可以表示为:
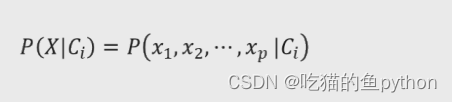
然后我们可以假设自变量之间是独立得,那么我们就可以得到:
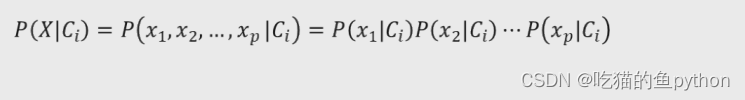
如果数据集中得自变量X均为连续得数值类型,那么我们可以在计算上方得P(Xi|C)时会假设自变量X服从高斯正态分布,所以自变量X得条件概率可以表示为:
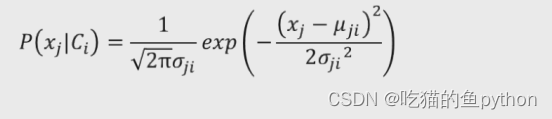
两个位置变量一个表示均值一个表示标准差,那么我们以一个实例为例子了解一下关于这个公式得相关内容:
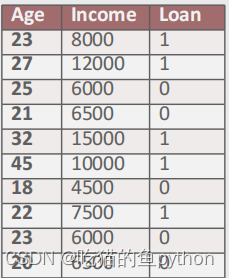
这是是我们得数据,然后我们来提出问题,我们根据上方得数据,想要知道假设某金融公司是否愿意给客户放贷会优先考虑两个因素,分别是年龄和收入。现在根据已知的数据信息考察一位新客户,他的年龄为24岁,并且收入为8500元,请问该公司是否愿意给客户放贷?
那么我们对于这个问题怎么解决呢?直接按照上方得公式,先把均值和标准差算出来。

然后根据高斯贝叶斯模型公式代入,然后分别求的年龄和收入得相关计算:
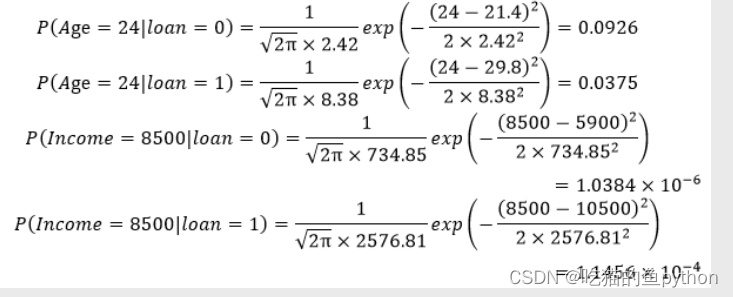
然后我们求得最后得后验概率是:
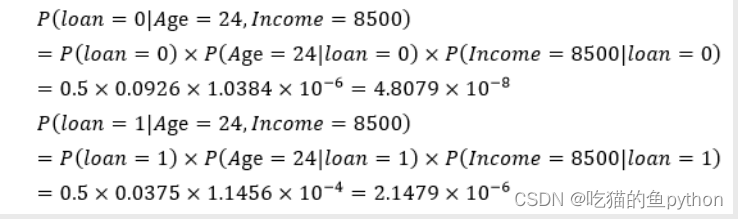
然后根据计算结果我们得到在满足24岁,并且收入为8500元得时候,银行会同意放贷!
如果数据都是离散型变量,那么就满足使用多项式计算公式:
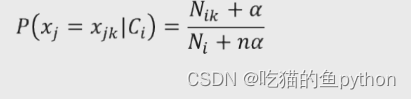
a表示平滑系数,为了避免概率值为0,所以做了一次拉普拉斯平滑,n表示因变量类别个数。具体我们还是来看例子:
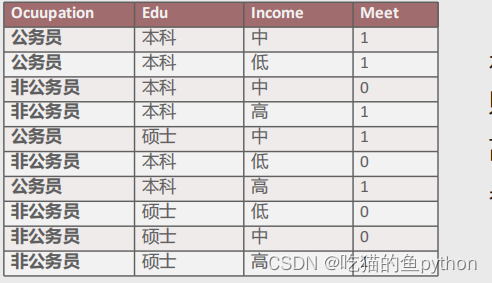
这是一个相亲得一份数据,我们以第一行为例子,比如说公务员,学历是本科,收入是中,那么女方选择见你!就是这个意思。请问在给定的信息下,对于高收入的公务员,并且其学历为硕士的男生来说,女孩是否愿意参与他的相亲?这个我们来计算一下:
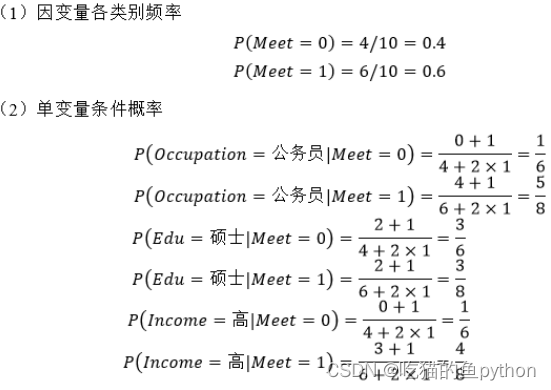
分别对应公式我们就明白了,然后我们求得最后得后验概率公式为:

所以最后我们分析得到,女方愿意和你见面。
当数据只有0-1这两种也被称为二元值类型得数值时候,那么我们通常会选择伯努利贝叶斯分类器公式:

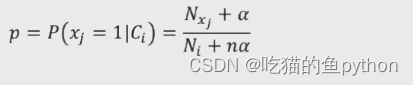
其中得p也是这样表示。
那么我们还是来看例子:
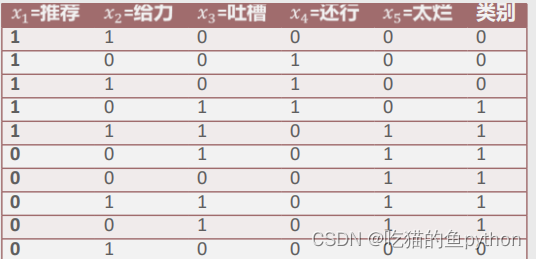
假设对10条评论数据做分词处理后,得到如表所示的文档词条矩阵,矩阵中含有5个词语和1个表示情感的结果,其中类别为0表示正面情绪,1表示负面情绪。如果一个用户的评论中仅包含“还行”一词,请问该用户的评论属于哪种情绪?也就是说为00010这种类型我们判断最后得类别是什么?

最后求得的后验概率是:

那么我们得出结论:
当用户的评论中只含有“还行”一词时,计算该评论为正面情绪的概率约为0.015,评论为负面情绪的概率约为0.00073,故根据贝叶斯后验概率最大原则将该评论预判为正面情绪。
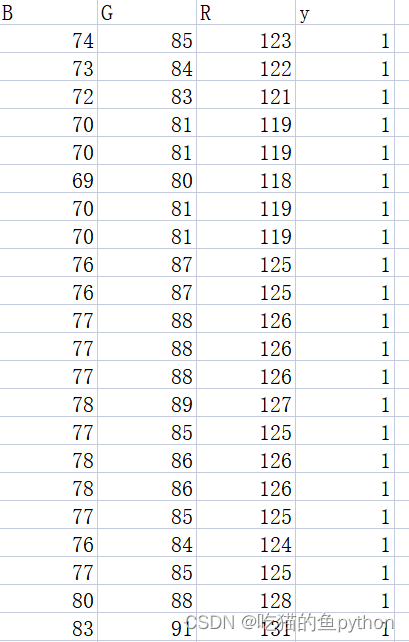
import pandas as pd
# 读入数据
skin = pd.read_excel(r'Skin_Segment.xlsx')
# 设置正例和负例
skin.y = skin.y.map({2:0,1:1})
skin.y.value_counts()
导入设置正负例子,把2换成0
from sklearn import model_selection
# 样本拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(skin.iloc[:,:3], skin.y,
test_size = 0.3, random_state=1234)
from sklearn import naive_bayes
# 调用高斯朴素贝叶斯分类器的“类”
gnb = naive_bayes.GaussianNB()
# 模型拟合
gnb.fit(X_train, y_train)
# 模型在测试数据集上的预测
gnb_pred = gnb.predict(X_test)
# 各类别的预测数量
pd.Series(gnb_pred).value_counts()
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
# 构建混淆矩阵
cm = pd.crosstab(gnb_pred,y_test)
# 绘制混淆矩阵图
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
# 去除x轴和y轴标签
plt.xlabel('Real')
plt.ylabel('Predict')
# 显示图形
plt.show()
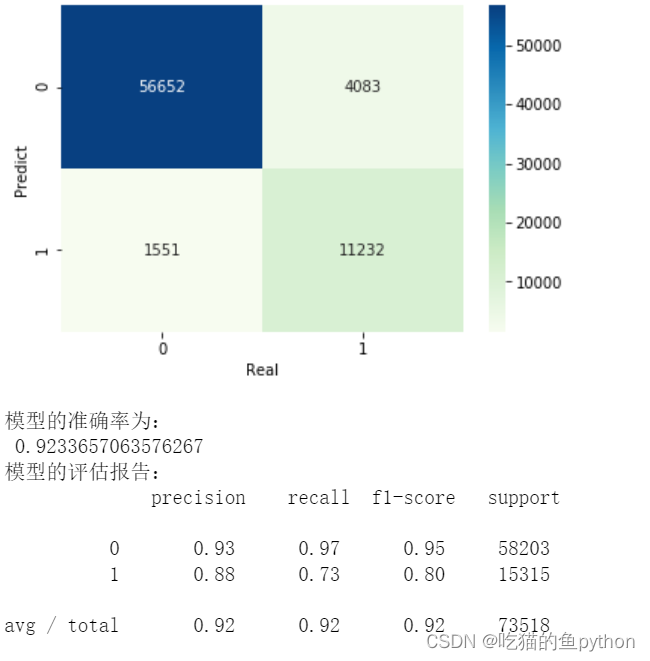
print('模型的准确率为:\n',metrics.accuracy_score(y_test, gnb_pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, gnb_pred))
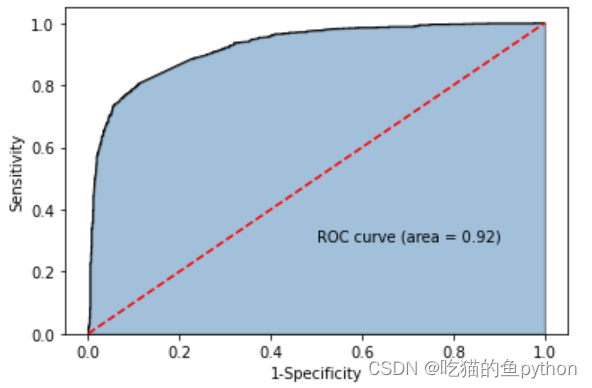
y_score = gnb.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
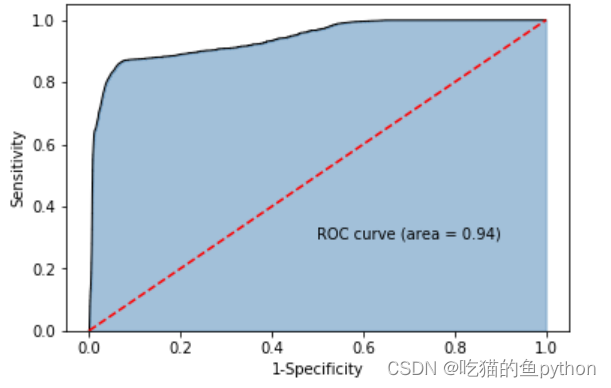
这里说明我们的模型是合格哒!!!
import pandas as pd
# 读取数据
mushrooms = pd.read_csv(r'mushrooms.csv')
# 数据的前5行
mushrooms.head()
columns = mushrooms.columns[1:]
for column in columns:
mushrooms[column] = pd.factorize(mushrooms[column])[0]
mushrooms.head()
from sklearn import model_selection
# 将数据集拆分为训练集合测试集
Predictors = mushrooms.columns[1:]
X_train,X_test,y_train,y_test = model_selection.train_test_split(mushrooms[Predictors], mushrooms['type'],
test_size = 0.25, random_state = 10)
from sklearn import naive_bayes
from sklearn import metrics
import seaborn as sns
import matplotlib.pyplot as plt
# 构建多项式贝叶斯分类器的“类”
mnb = naive_bayes.MultinomialNB()
# 基于训练数据集的拟合
mnb.fit(X_train, y_train)
# 基于测试数据集的预测
mnb_pred = mnb.predict(X_test)
# 构建混淆矩阵
cm = pd.crosstab(mnb_pred,y_test)
# 绘制混淆矩阵图
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
# 去除x轴和y轴标签
plt.xlabel('Real')
plt.ylabel('Predict')
# 显示图形
plt.show()
# 模型的预测准确率
print('模型的准确率为:\n',metrics.accuracy_score(y_test, mnb_pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, mnb_pred))
y_score = mnb.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test.map({'edible':0,'poisonous':1}), y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()

import pandas as pd
# 读入评论数据
evaluation = pd.read_excel(r'Contents.xlsx',sheet_name=0)
# 查看数据前10行
evaluation.head(10)
evaluation.Content = evaluation.Content.str.replace('[0-9a-zA-Z]','')
evaluation.head()
jieba.load_userdict(r'all_words.txt')
# 读入停止词
with open(r'mystopwords.txt', encoding='UTF-8') as words:
stop_words = [i.strip() for i in words.readlines()]
# 构造切词的自定义函数,并在切词过程中删除停止词
def cut_word(sentence):
words = [i for i in jieba.lcut(sentence) if i not in stop_words]
# 切完的词用空格隔开
result = ' '.join(words)
return(result)
# 对评论内容进行批量切词
words = evaluation.Content.apply(cut_word)
# 前5行内容的切词效果
words[:5]
from sklearn.feature_extraction.text import CountVectorizer
# 计算每个词在各评论内容中的次数,并将稀疏度为99%以上的词删除
counts = CountVectorizer(min_df = 0.01)
# 文档词条矩阵
dtm_counts = counts.fit_transform(words).toarray()
# 矩阵的列名称
columns = counts.get_feature_names()
# 将矩阵转换为数据框--即X变量
X = pd.DataFrame(dtm_counts, columns=columns)
# 情感标签变量
y = evaluation.Type
X.head()
from sklearn import model_selection
from sklearn import naive_bayes
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
# 将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.25, random_state=1)
# 构建伯努利贝叶斯分类器
bnb = naive_bayes.BernoulliNB()
# 模型在训练数据集上的拟合
bnb.fit(X_train,y_train)
# 模型在测试数据集上的预测
bnb_pred = bnb.predict(X_test)
# 构建混淆矩阵
cm = pd.crosstab(bnb_pred,y_test)
# 绘制混淆矩阵图
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
# 去除x轴和y轴标签
plt.xlabel('Real')
plt.ylabel('Predict')
# 显示图形
plt.show()
# 模型的预测准确率
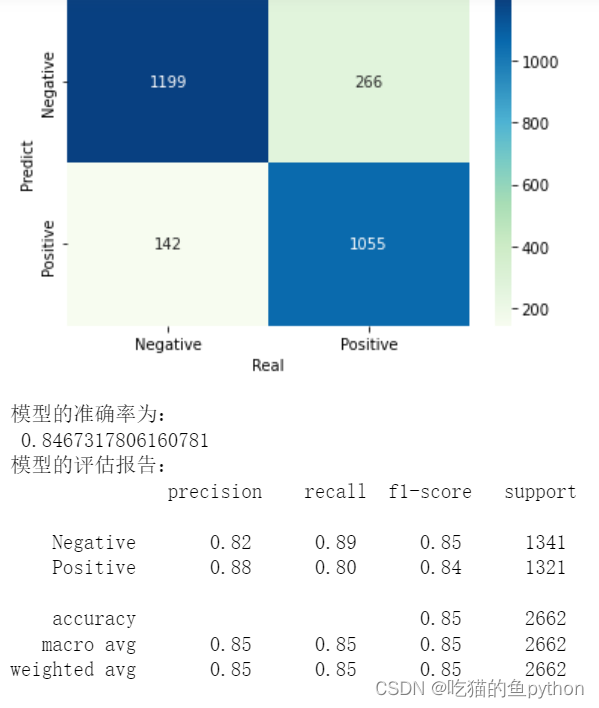
print('模型的准确率为:\n',metrics.accuracy_score(y_test, bnb_pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, bnb_pred))
y_score = bnb.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test.map({'Negative':0,'Positive':1}), y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
💐文章适合于所有的相关人士进行学习💐
🍀各位看官看完了之后不要立刻转身呀🍀
🌿期待三连关注小小博主加收藏🌿
🍃小小博主回关快 会给你意想不到的惊喜呀🍃
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#