目录 三、爬取某个网站(以下我用之前的创建的项目,不是刚刚新创的)
pip install Scrapypip install seleniuma,查看Google Chrome浏览器版本
Chrome驱动下载地址http://chromedriver.storage.googleapis.com/index.html
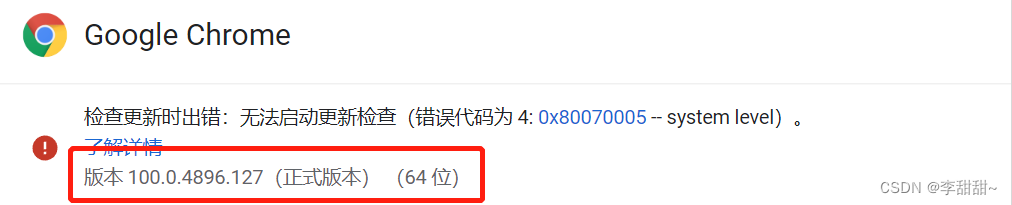
b,找到和你版本最接近的哪个安装包

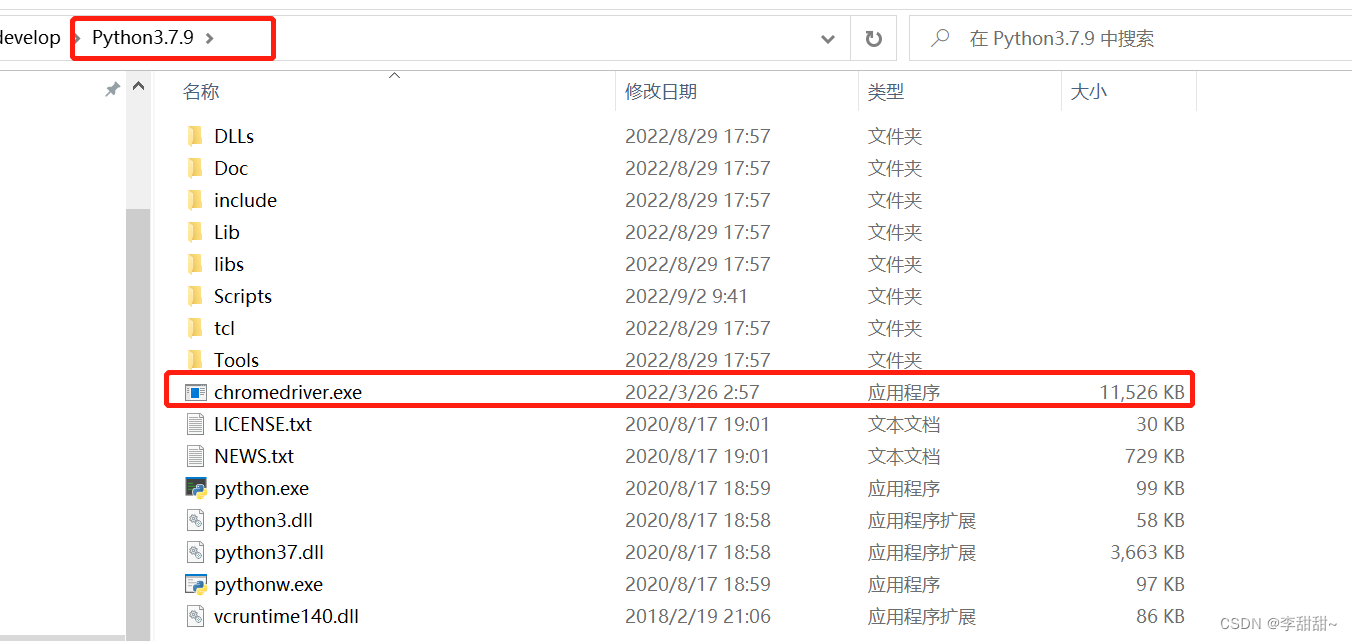
c,下载好之后将我们的chromedriver放到和我们python安装路径相同的目录下
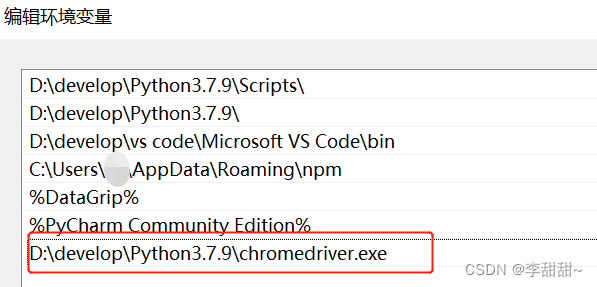
d,配置环境变量
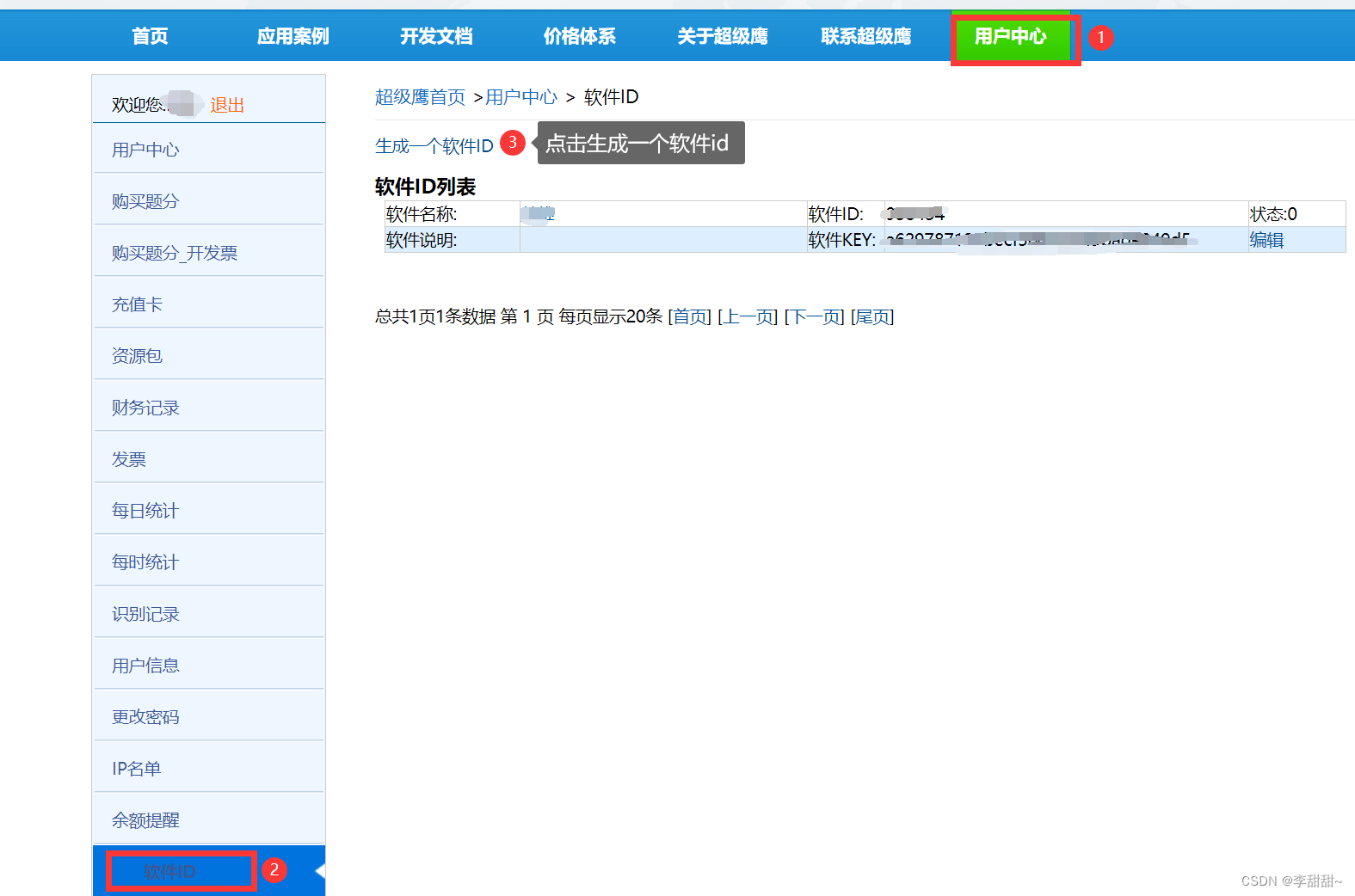
a,超级鹰官网 https://www.chaojiying.com/
b,注册,登入
c,生成软件id
d,下载,放置到爬虫工程目录下

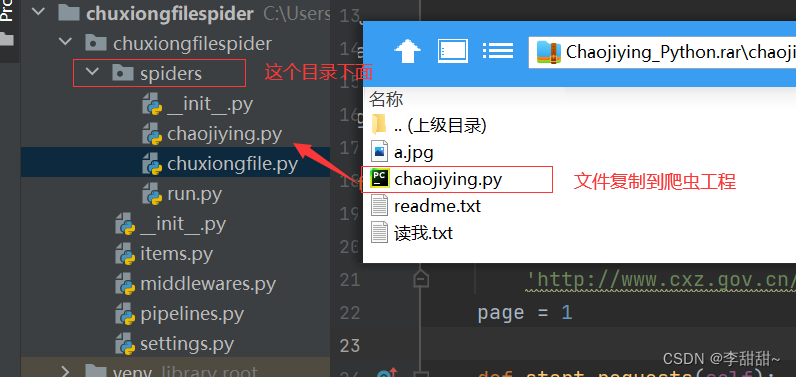
# 切换到自己想要的路径 cd C:\Users\(用户名)\Desktop\spider
# 创建工程 scrapy startproject (项目名)
# 切换到新创建的文件夹 cd hellospider
# 创建爬虫项目 scrapy genspider (爬虫名) (爬取网址的域名)



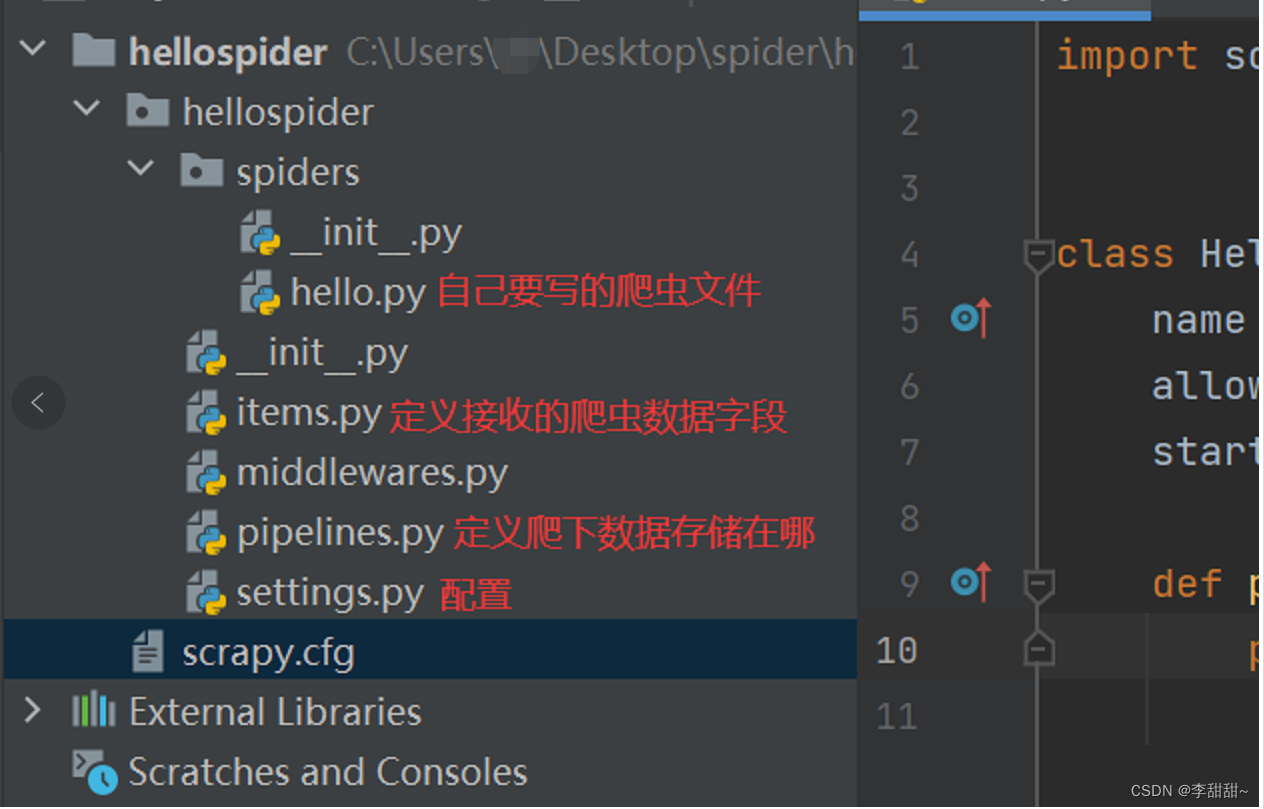
file->setting
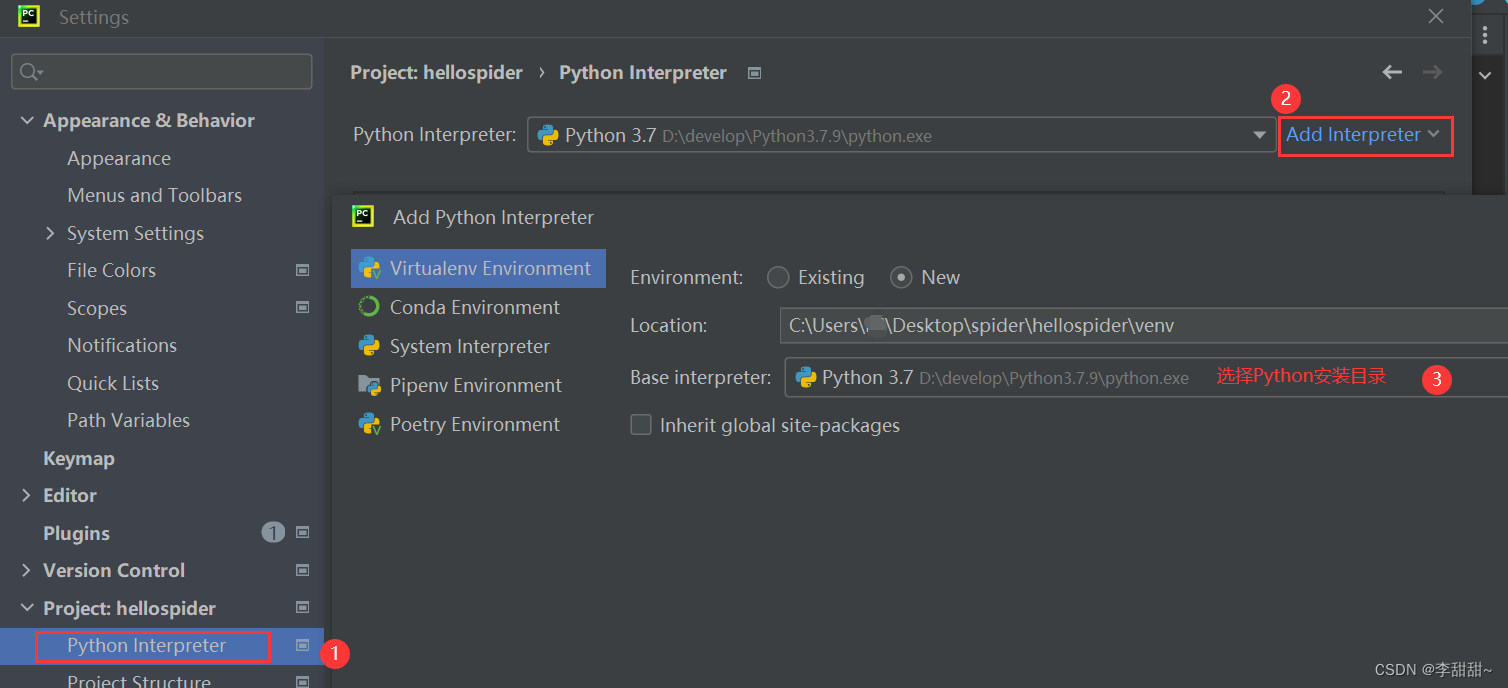
pycharm里面的命令行,再次安装scrapy,selenium
# 修改机器人协议
ROBOTSTXT_OBEY = False
# 下载时间间隙
DOWNLOAD_DELAY = 1
# 启用后,当从相同的网站获取数据时,Scrapy将会等待一个随机的值,延迟时间为0.5到1.5之间的一个随机值乘以DOWNLOAD_DELAY
RANDOMIZE_DOWNLOAD_DELAY=True
# 若是请求时间超过60秒,就会报异常,异常机制是会再次发起请求的
DOWNLOAD_TIMEOUT = 60
# 设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
# 打开一个管道
ITEM_PIPELINES = {
# '项目名称.pipelines.管道名': 300,
'chuxiongfilespider.pipelines.ChuxiongfilespiderPipeline': 300,
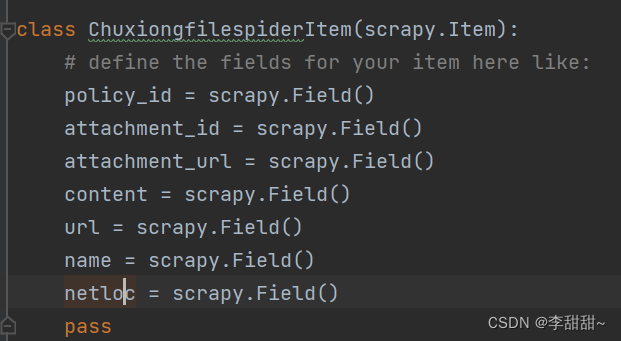
}定义需要的字段
import copy
from datetime import time
import scrapy
from pymysql.converters import escape_string
from scrapy.http import HtmlResponse
from selenium.common import NoSuchElementException
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from chuxiongfilespider.items import ChuxiongfilespiderItem
from chuxiongfilespider.spiders.chaojiying import Chaojiying_Client
import uuid
class ChuxiongfileSpider(scrapy.Spider):
name = 'chuxiongfile'
allowed_domains = ['网址']
start_urls = [
'爬取的网址']
page = 1
def start_requests(self):
web = Chrome()
web.get(self.start_urls[0])
try:
# selenium版本更新,原find_element_by_xpath需要改写,并导By包
web.find_element(By.XPATH, '/html/body/form/div/img')
# screenshot_as_png当前窗口的屏幕快照保存为二进制数据
img = web.find_element(By.XPATH, '/html/body/form/div/img').screenshot_as_png
# 超级鹰处理验证码
chaojiying = Chaojiying_Client('超级鹰登入账号', '超级鹰登入密码', '软件id')
# 1902处理验证码类型
dic = chaojiying.PostPic(img, 1902)
verify_code = dic['pic_str']
# 填写验证码
web.find_element(By.XPATH, '//*[@id="visitcode"]').send_keys(verify_code)
# 点击确定
time.sleep(2)
web.find_element(By.XPATH, '/html/body/form/div/input[4]').click()
# 获取验证码输入后的cookie
cookies_dict = {cookie['name']: cookie['value'] for cookie in web.get_cookies()}
web.close()
yield scrapy.Request(url=self.start_urls[0], cookies=cookies_dict, callback=self.parse)
except NoSuchElementException:
yield scrapy.Request(url=self.start_urls[0], callback=self.parse)
def parse(self, response: HtmlResponse, **kwargs):
items = ChuxiongfilespiderItem()
for item in response.css('.tml'):
items['name'] = item.css('.tcc a::text').extract()[0]
items['policy_id'] = ''.join(str(uuid.uuid5(uuid.NAMESPACE_DNS, items['name'])).split('-'))
items['attachment_id'] = '123'
items['url'] = response.urljoin(item.css('.tcc a::attr(href)').extract_first())
if item.css('.d a::attr(href)').extract_first() == '':
items['attachment_url'] = '无下载选项'
else:
items['attachment_url'] = response.urljoin(item.css('.d a::attr(href)').extract_first())
items['netloc'] = '网址'
yield scrapy.Request(url=items['url'], callback=self.get_details, meta={"items": copy.deepcopy(items)})
def get_details(self, response):
items = response.meta['items']
items['content'] =escape_string(" ".join(response.css('.xzgfwrap').getall()))
yield items
if self.page < 2:
self.page += 1
url = f'http://(网址)?totalpage=3&PAGENUM={str(self.page)}&urltype' \
f'=tree.TreeTempUrl&wbtreeid=3494'
yield scrapy.Request(url=url, callback=self.parse) # 使用callback进行回调
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class ChuxiongfilespiderPipeline(object):
mysql = None
cursor = None # 执行SQL语句返回游标接口
def open_spider(self, spider):
self.mysql = pymysql.Connect(host='localhost', user='数据库用户名', password='数据库用户密码', port=3306, charset='utf8',
database='库名')
self.cursor = self.mysql.cursor()
def process_item(self, items, spider):
# 创建表
table = 'create table if not exists cx_other(' \
'id int not null primary key auto_increment' \
',policy_id varchar(100)' \
',url varchar(1000)' \
',attachment_id varchar(100)' \
',attachment_url varchar(100)' \
',name varchar(150)' \
',netloc varchar(50)' \
');'
table_1 = 'create table if not exists cx_other_content(' \
'id int not null primary key auto_increment' \
',policy_id varchar(100)' \
',content MEDIUMTEXT NOT NULL' \
');'
insert = 'insert into cx_other(policy_id,url,attachment_id,attachment_url,name,netloc) ' \
'values("%s","%s","%s","%s","%s","%s")' \
% (items['policy_id'], items['url'], items['attachment_id'], items['attachment_url'], items['name'], items['netloc'])
insert_1 = 'insert into cx_other_content(policy_id,content) values("%s","%s")' % (
items['policy_id'], items['content'])
try:
# 数据库断开后重连
self.mysql.ping(reconnect=True)
# 创建表
self.cursor.execute(table)
self.cursor.execute(table_1)
# 插入数据
self.cursor.execute(insert)
self.cursor.execute(insert_1)
self.mysql.commit()
print('===============插入数据成功===============')
except Exception as e:
print('===============插入数据失败===============', e)
self.mysql.rollback()
return items
def close_spider(self, spider):
self.cursor.close()
self.mysql.close()给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
当我的预订模型通过rake任务在状态机上转换时,我试图找出如何跳过对ActiveRecord对象的特定实例的验证。我想在reservation.close时跳过所有验证!叫做。希望调用reservation.close!(:validate=>false)之类的东西。仅供引用,我们正在使用https://github.com/pluginaweek/state_machine用于状态机。这是我的预订模型的示例。classReservation["requested","negotiating","approved"])}state_machine:initial=>'requested
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri