作者:vivo 互联网前端团队- Yang Kun
本文是上篇文章《Node.js 应用全链路追踪技术——全链路信息获取》的后续。阅读完,再来看本文,效果会更佳哦。
本文主要介绍在Node.js应用中, 如何用全链路信息存储技术把全链路追踪数据存储起来,并进行相应的展示,最终实现基于业界通用 OpenTracing 标准的 Zipkin 的 Node.js 方案。
目前业界主流的做法是使用分布式链路跟踪系统,其理论基础是来自 Google 的一篇论文 《大规模分布式系统的跟踪系统》。
论文如下图所示:
(图片来源:网络)
在此理论基础上,诞生了很多优秀的实现,如 zipkin、jaeger 。同时为了保证 API 兼容,他们都遵循 OpenTracing 标准。那 OpenTracing 标准是什么呢?
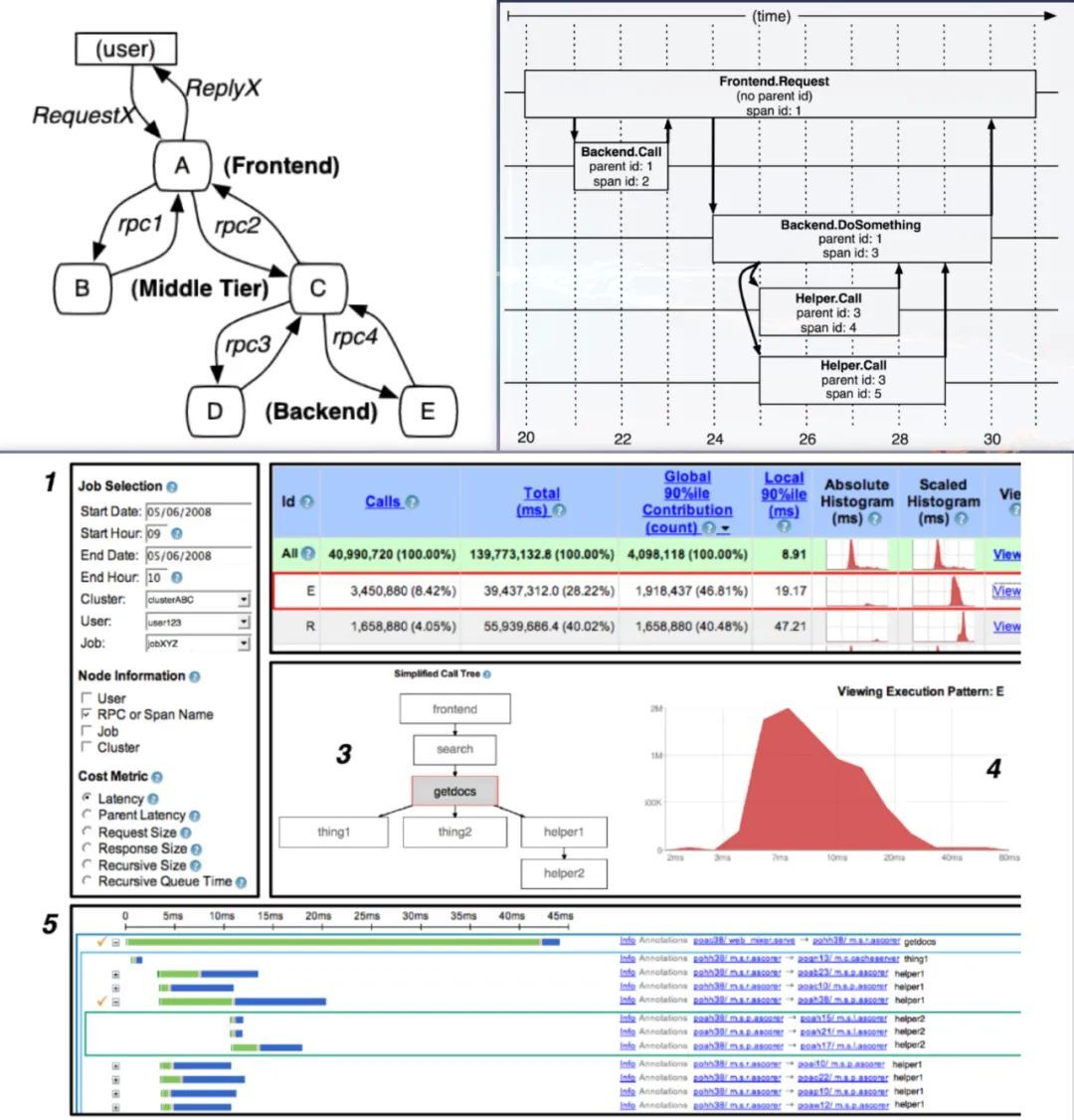
OpenTracing 翻译为开发分布式追踪,是一个轻量级的标准化层,它位于应用程序/类库和链路跟踪系统之间的一层。 这一层可以用下图表示:
从上图可以知道, OpenTracing 具有以下优势:
统一了 API ,使开发人员能够方便的添加追踪系统的实现。
OpenTracing 已进入 CNCF ,正在为全球的分布式链路跟踪系统,提供统一的模型和数据标准。
大白话解释下:它就像手机的接口标准,当今手机基本都是 typeC 接口,这样方便各种手机能力的共用。因此,做全链路信息存储,需要按照业界公认的 OpenTracing 标准去实现。
本篇文章将通过已有的优秀实现 —— zipkin ,来给大家阐述 Node.js 应用如何对接分布式链路跟踪系统。
zipkin 是 Twitter 基于 Google 的分布式追踪系统论文的开发实现,其遵循 OpenTracing 标准。
zipkin 用于跟踪分布式服务之间的应用数据链路。
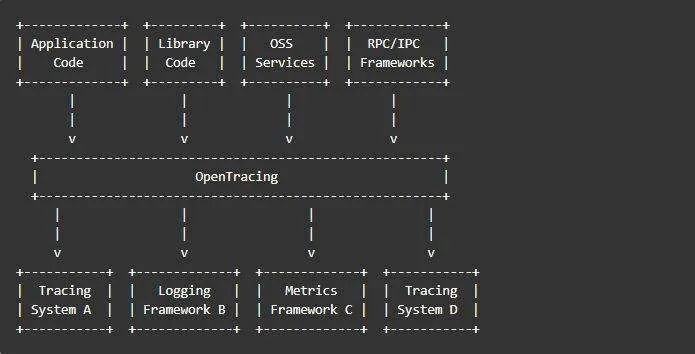
官方文档上的架构如下图所示:
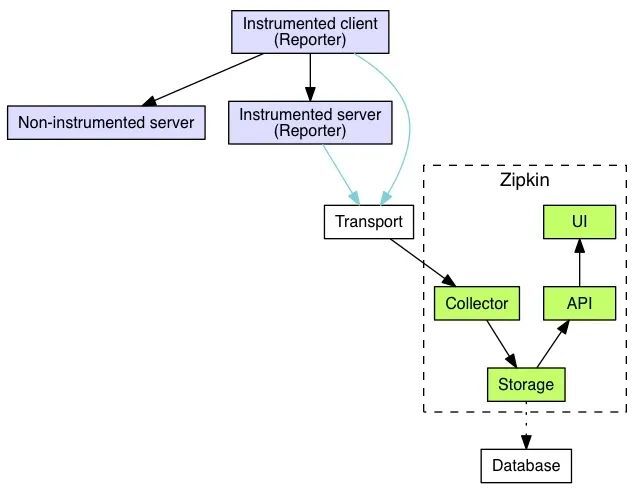
为了更好的理解,我这边对架构图进行了简化,简化架构图如下所示:
从上图可以看到,分为三个部分:
第一部分:全链路信息获取,我们不使用 zipkin 自带的全链路信息获取,我们使用 zone-context 去获取全链路信息
第二部分:传输层, 使用 zipkin 提供的传输 api ,将全链路信息传递给 zipkin
第三部分: zipkin 核心功能,各个模块介绍如下:
collector 就是信息收集器,作为一个守护进程,它会时刻等待客户端传递过来的追踪数据,对这些数据进行验证、存储以及创建查询需要的索引。
storage 是存储组件。zipkin 默认直接将数据存在内存中,此外支持使用 ElasticSearch 和 MySQL 。
search 是一个查询进程,它提供了简单的 JSON API 来供外部调用查询。
web UI 是 zipkin 的服务端展示平台,主要调用 search 提供的接口,用图表将链路信息清晰地展示给开发人员。
至此, zipkin 的整体架构就介绍完了,下面我们来进行 zipkin 的环境搭建。
采用 docker 搭建, 这里我们使用 docker 中的 docker-compose 来快速搭建 zipkin 环境。
docker-compose.yml 文件内容如下:
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.0
container_name: elasticsearch
restart: always
ports:
- 9200:9200
healthcheck:
test: ["CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- TZ=Asia/Shanghai
ulimits:
memlock:
soft: -1
hard: -1
zipkin:
image: openzipkin/zipkin:2.21
container_name: zipkin
depends_on:
- elasticsearch
links:
- elasticsearch
restart: always
ports:
- 9411:9411
environment:
- TZ=Asia/Shanghai
- STORAGE_TYPE=elasticsearch
- ES_HOSTS=elasticsearch:9200
在上面文件所在的目录下执行 docker-compose up -d 即可完成本地搭建。
搭建完成后,在浏览器中打开地址 http://localhost:9411 ,会看到如下图所示页面:
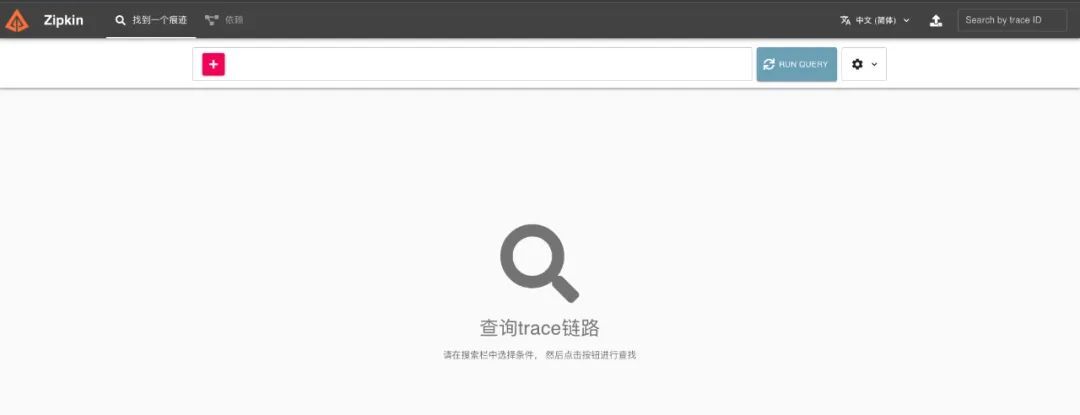
接着打开地址 http://localhost:9200 ,会看到如下图所示页面:
至此, zipkin 的本地环境就搭建好啦。 下面我就将介绍 Node.js 应用如何对接 zipkin。
这个我在 《Node.js 应用全链路追踪技术——全链路信息获取》 文章中,已经详细阐述了,如何去获取全链路信息。
因为 zipkin 是基于 OpenTracing 标准实现的。因此我们只要搞定了 zipkin 的传输层,也就搞定了其他主流分布式追踪系统。
这里我们用到了 zipkin 官方提供的两个 npm 包,分别是:
zipkin
zipkin-transport-http
zipkin 包是官方对支持 Node.js 的核心包。 zipkin-transport-http 包的作用是将数据通过 HTTP 异步发送到 zipkin 。
下面我们将详细介绍在传输层,如何将将数据发送到 zipkin 。
核心代码实现和相关注释如下:
const {
BatchRecorder,
Tracer,
// ExplicitContext,
jsonEncoder: { JSON_V1, JSON_V2 },
} = require('zipkin')
const { HttpLogger } = require('zipkin-transport-http')
// const ctxImpl = new ExplicitContext();
// 配置对象
const options = {
serviceName: 'zipkin-node-service',
targetServer: '127.0.0.1:9411',
targetApi: '/api/v2/spans',
jsonEncoder: 'v2'
}
// http 方式传输
async function recorder ({ targetServer, targetApi, jsonEncoder }) => new BatchRecorder({
logger: new HttpLogger({
endpoint: `${targetServer}${targetApi}`,
jsonEncoder: (jsonEncoder === 'v2' || jsonEncoder === 'V2') ? JSON_V2 : JSON_V1,
})
})
// 基础记录
const baseRecorder = await recorder({
targetServer: options.targetServer
targetApi: options.targetApi
jsonEncoder: options.jsonEncoder
})
至此,传输层的基础封装就完成了,我们抽离了 baseRecorder 出来,下面将会把全链路信息接入到传输层中。
这里说下官方提供的接入 SDK ,代码如下:
const { Tracer } = require('zipkin')
const ctxImpl = new ExplicitContext()
const tracer = new Tracer({ ctxImpl, recorder: baseRecorder })
// 还要处理请求头、手动层层传递等事情
上面的方式缺点比较明显,需要额外去传递一些东西,这里我们使用上篇文章提到的 Zone-Context , 代码如下:
const zoneContextImpl = new ZoneContext()
const tracer = new Tracer({ zoneContextImpl, recorder: baseRecorder })
// 仅此而已,不再做额外处理
对比两者,明显发现, Zone-Context 的实现方式更加的隐式,对代码入侵更小。这也是单独花一篇文章介绍 Zone-Context 技术原理的价值体现。
自此,我们完成了传输层的适配, Node.js 应用接入 zipkin 的核心步骤基本完成。
这部分中的收集、展示功能, zipkin 官方自带完整实现,无需进行二次开发。存储这块,提供了 MySQL 、 Elasticsearch 等接入方式。可以根据实际情况去做相应的接入。本文采用 docker-compose 集成了 ElasticSearch 。
自此,我们已经完成基于业界通用 OpenTracing 标准实现的 zipkin 的 Node.js 方案。希望大家看完这两篇文章,对 Node.js 全链路追踪,有一个整体而清晰的认识。
参考资料:
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.