idea 实现git rebase操作详解
本文结合idea工具进行rebase的各种场景的操作,借助工具更能直观地观察到分支之间地操作差异,方便我们理解rebase的各种操作以及场景的使用。
rebase:翻译成中文是重新设定,在这里可以理解为重新设置基线,也可以这么理解,将当前分支重新设置起始点。
rebase会把你当前分支的 commit 放到最后面,将rebase后的目标分支的commit当作基点放在前面,通俗的说就是将目标分支的提交作为你当前分支的基点,所以叫变基。
先准备好一个主基线:
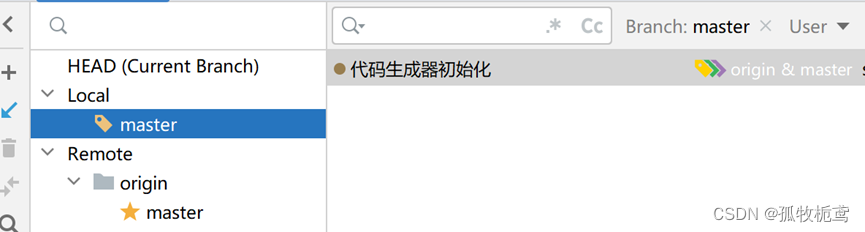
在此基础上创建一个分支:名字为fenzhi_1,创建另一个分支,名字为fenzhi_2
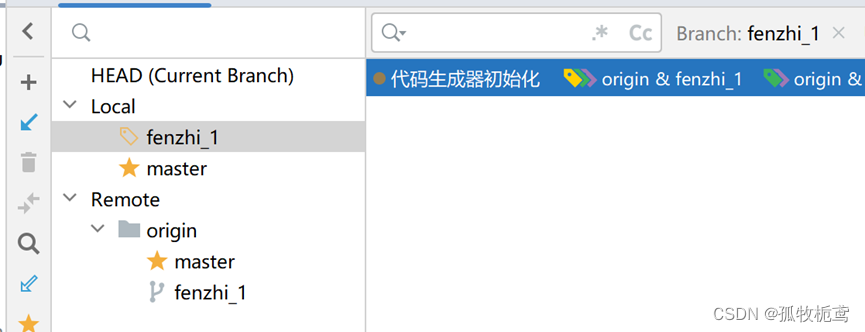
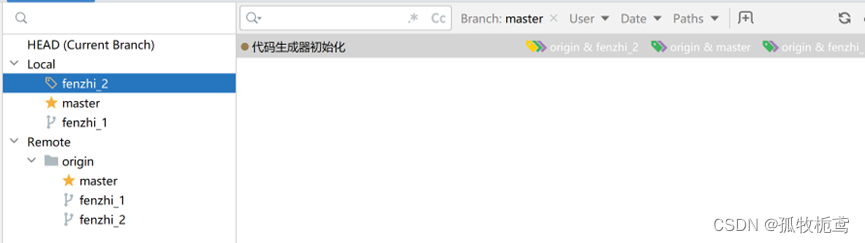
最开始fenzhi_1和fenzhi_2以及master的基线是同一个。
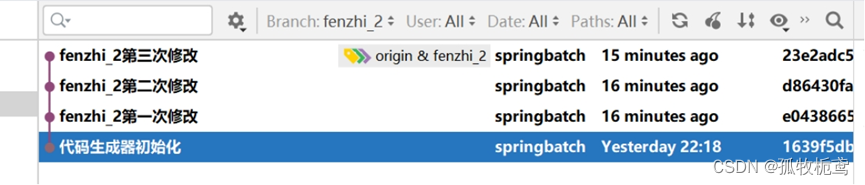
当前分支为fenzhi_2,共有三个提交记录:
在第一次修改上进行右击鼠标:选择图中的选项,翻译一下就是在此处进行交互式改变基址。
交互式可以理解为可自定义的选择不同rebase行为进行操作。
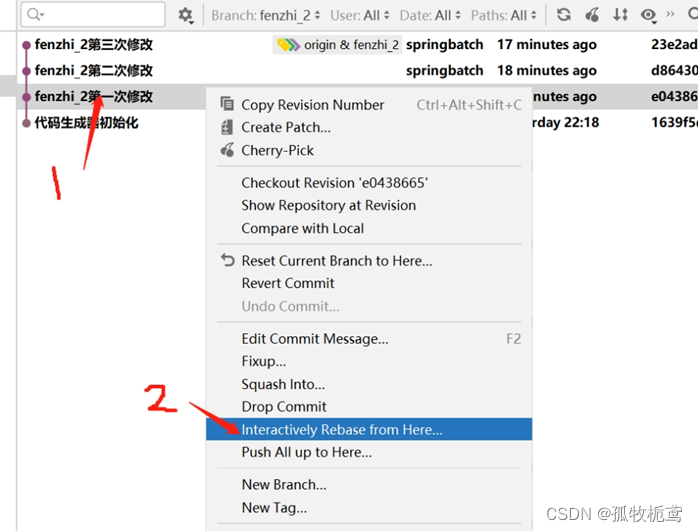
可以看到下面的界面,我们讲解一下:红色部分是操作栏,绿色部分是显示的提交记录,黄色部分是显示选择提交记录的详情信息,黑色部分就是执行rebase操作或者取消
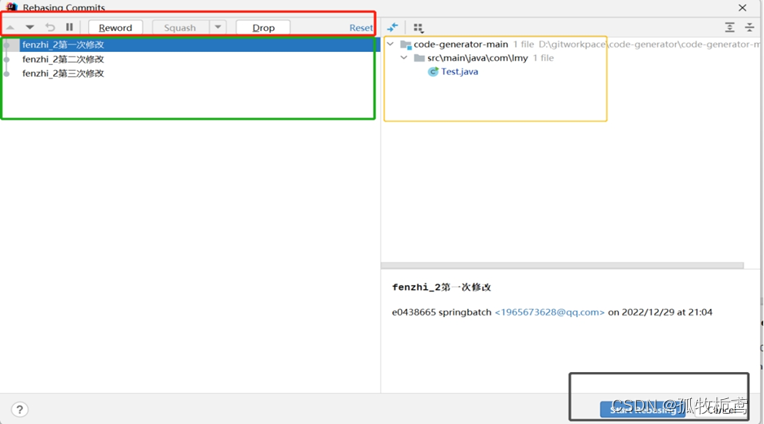
着重讲解红色部分:
Rebase的行为可以大致分为三类:
第一类:保留commit,不合并
1、pick: 标记为pick的commit会在rebase操作后会直接保留下来,不做任何改动,也不会合并,最上面的commit最好标记为这一类
2、reword: 这一类commit也会保存下来,不过在保存下来之前会有一次修改commit message的机会
3、edit:这一类的commit也会直接保存下来,不过,当合并到这种类型的commit时,整个合并经常会暂停下来,你可以重新修改这次commit中的变动内容,比如给这个commit继续新增一些代码改动、或者修改commit message,然后git add(不要忘记 git add了), 再继续使用git rebase —continue,来继续rebase操作。
第二类:不保留commit,与上一次commit合并
1、squash:标记为squash的commit在rebase操作完成后不会保留,它会与之相邻的上一次commit进行合并。同时它的commit message也会与上一次commit的message合并。
2、fixup: 这类commit不会保留,会直接与相邻的上一次commit合并,与squash不同之处在于,它的commit message回直接丢弃,即这次commit会被视为对前一次commit的一次小的补充修改(fixup),commit message就以前一次为准
第三类:不保留,直接删除commit
1、drop:标记为skip的commit会直接被删除,就相当于这次commit从来没有发生过。同时,这个commit中涉及的所有代码修改全部会被删除。
值得注意的是:
不能全部选择 drop commit,不然就没有需要改变的了
squash 和 fixup 不能在第一个commit,因为他们需要与前一个commit配合
A、红色的部分就是对提交记录的操作,左边的上下箭头可以改变提交记录的顺序:
操作一下,选中第一次修改记录然后点击下箭头:如图所示可以第一次记录跟第二次记录的顺序发生了变化
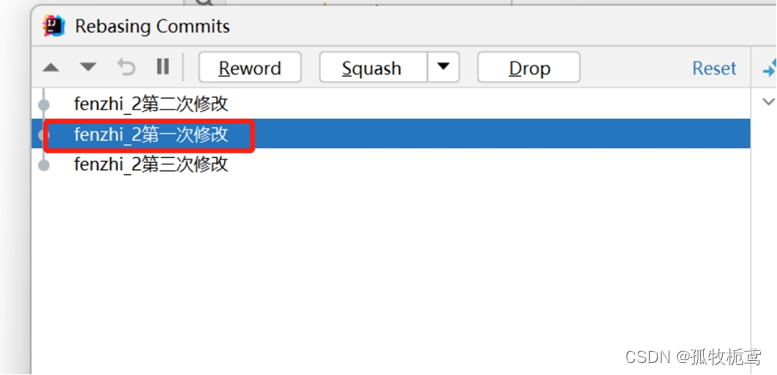
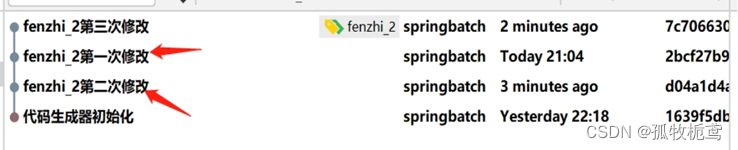
执行rebase结果看一下:可以看到第一次提交记录已经在第二次修改上面了。(若其中有对同一个文件修改时,会出现冲突并处理完后,将同个文件所有的提交记录折成一个)所以可以看出rebase操作其实也是有风险的,容易把别人的提交记录删除掉,在解决冲突时也就会出现替换别人的改动。
B、第三个按钮它显示的提示是pick,其实它是对每个提交记录的所有的操作恢复到最初的配置,记住不是所有提交记录的操作回退,其实最初的操作就是默认pick。
C、第四个是stop to edit,指的是不修改提交信息,点击后:还是在第一次修改记录中点击这个按钮,可以看到左边显示了按钮。但双击鼠标后可以解除此操作;
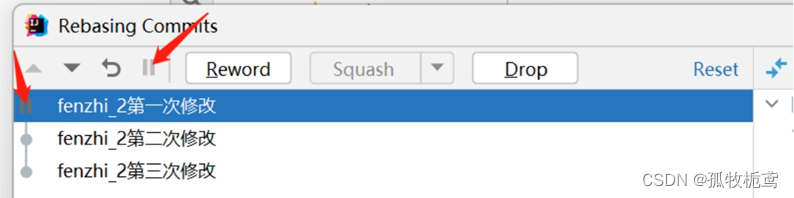
若修改第一次修改记录,再点击这个按钮呢:
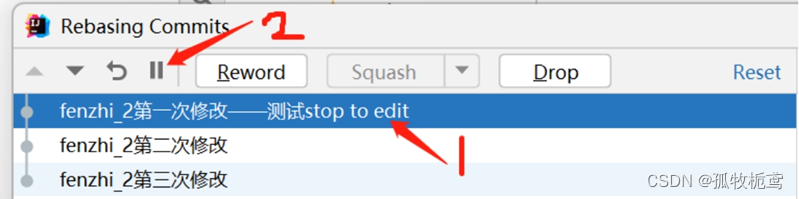
可以看到记录给恢复原初的信息。
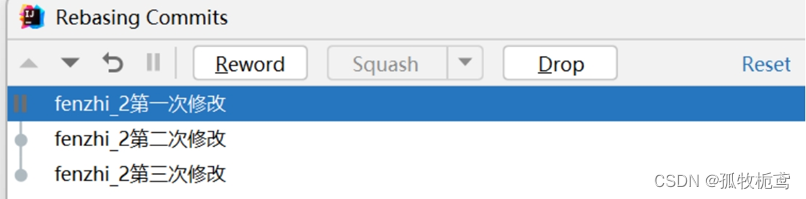
D、reword:通俗的说就是修改提交信息
E、Squash和Fixup是一组的,squash的操作会合并俩个提交的信息:如图操作,也可以在选择第二次操作后点上面的按钮也可以的,这里是方便展示进行的操作,点击后我们看下结果:
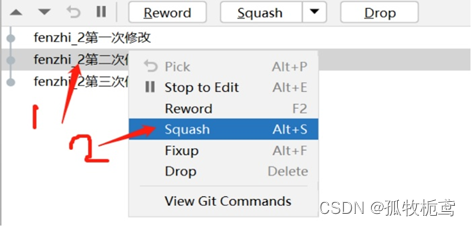
可以看到第二次提交记录合并到了第一次提交记录上
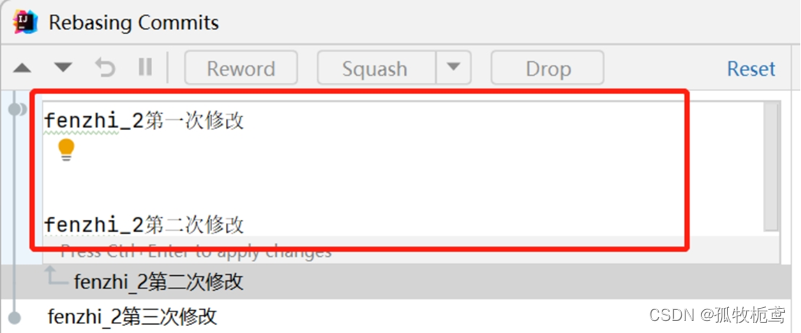
执行结果看一下:

要是点击Fixup呢:可以看到若第二次合并到第一次后,提交记录沿用第一次的提交记录。

执行结果看一下:
Rebase之前:可以看到俩次的提交记录


Rebase之后,可以看到提交记录合并到了一起。

F、drop:可以理解为丢弃,就是将删除当前提交的所有修改。将所有修改恢复到修改之前的样子,并且删除此次提交记录。

执行结果看一下:可以看到直接删除了第二次的所有改动记录,也可以理解为回退了第二次的所有操作。

G、reset:这个操作就简单了,就是还原对所有commit的操作
rebase操作后,又该如何push呢
比如我们执行的是将第二次提交合并到第一次提交上:

可以看到有俩个操作提示:更新和推送。从操作来看,若rabase后不推送,执行的是更新就会是远程的最新记录替换本地的改变。但不能这么做,那rebase操作就白整了。我们得需要push
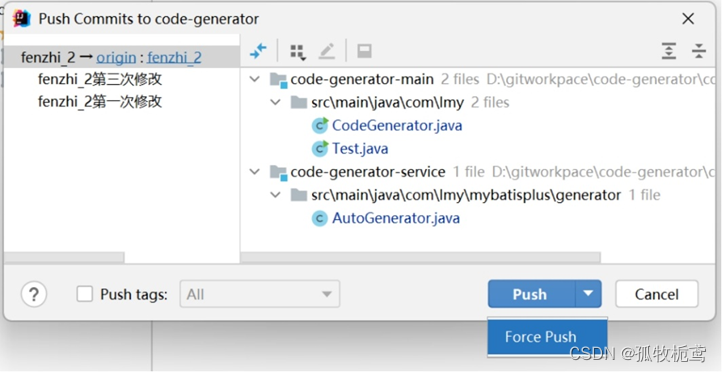
可以看到push有俩种选择:若直接选择的push,看下结果:
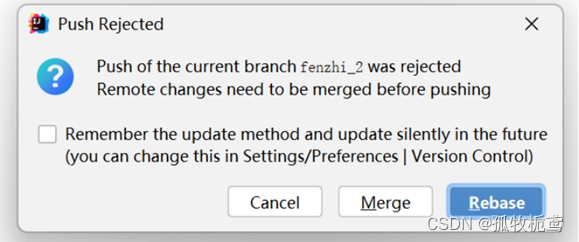
翻译一下:push的时候它认为你本地的变更与远程版本不一致
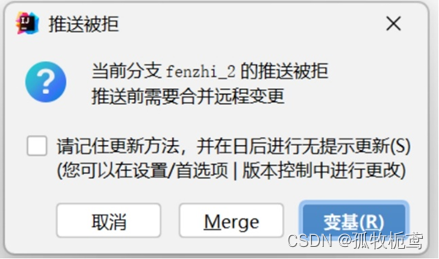
若选择rebase的话,就会发现恢复到rebase操作之前的记录
若选择merge的话,可以看到处理的结果,原先的2条提交信息还在,只是会新生成一个整合后的提交。

看下面的记录发现很奇怪。为啥第二次第三次提交成为了一个临时提交,然后第三次提交又成为了第一次提交后的版本,然后第二次提交成为了新的一个提交记录。
我们再次回到操作的时候:查看一下git的命令
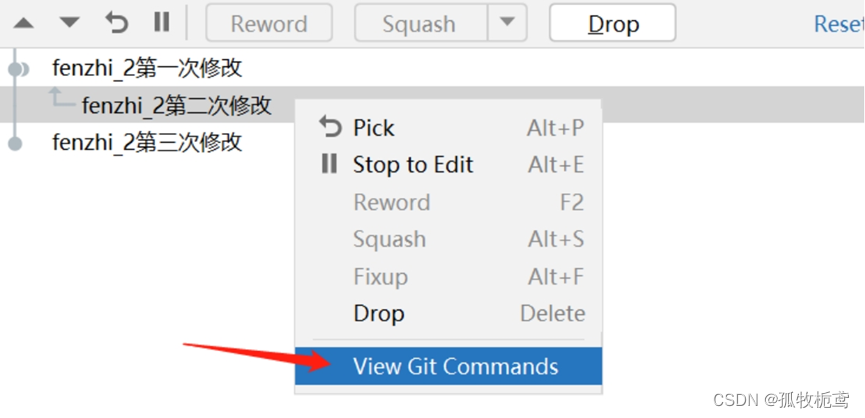
可以看到第一次和第三次的行为是pick,而第二次的是fixup,所以进行push时选择的是merge时会出现上述的提交记录。
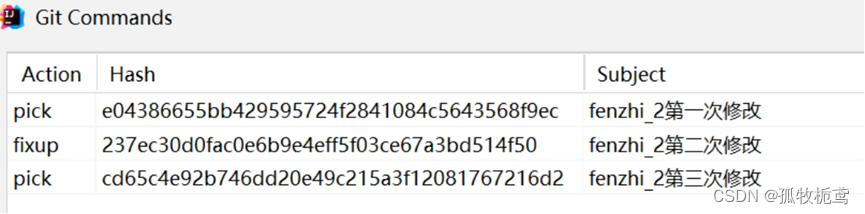
如果自己分支的几个提交都是本地的,还没有提交到远程分支fenzhi_2上,那么就可以直接push推到远程,但一般我们总要合自己代码到dev/test,所以必然是已经提交到自己远程分支上了, 此时当你去push你的commit时,会再次与你远程分支的commit合并,之前本地rebase的那些commit又会出现了。
若选择force push呢,翻译过来就是强制推送,看一下操作结果:有个提示,翻译一下就是:强制推送,可能会覆盖远程服务器的提交。
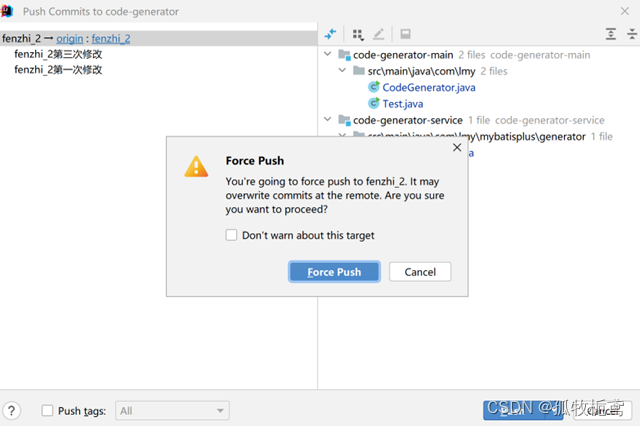
点击强制推送

可以看到这个结果是想要的,但是这个也有不同的情况:
若这个远程分支只有你一个人在开发:强制推送是可以的,没有人会在你rebase没完成时提代码,可以直接理解为用你本地分支的状态区覆盖掉远端origin分支的状态,也就是执行过后,本地的分支什么样,远端分支就什么样
Rebase的本意是改变基线,意思就是当从master拉取的分支1开发一段时间后,master也提交了几个版本,这就使得分支1的基线与现在的master不是同一个版本。需要将分支1的基线改成最新master。那就需要rebase操作了。看案例效果:
看一下fenzhi_2的基线是在提交id为1639f5db的基础上拉的分支,然后做了俩次变更

再看一下master的提交记录:master在 1639f5db上提交了一次变更。

这就造成了fenzhi_2的基线不是最新的master了,现在要将fenzhi_2的基线改为提交id为f7ec72e7,看下面操作
本地分支改为fenzhi_2:
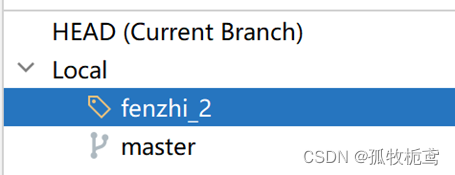
在master上右击鼠标:第二步操作翻译一下就是在master基础上改变fenzhi_2的基线。
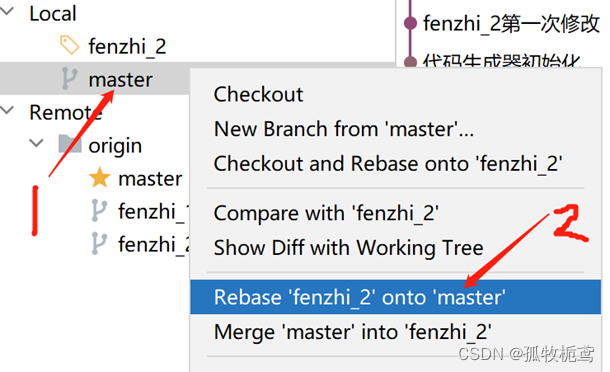
点击操作:若看到有冲突,手动处理一下即可,
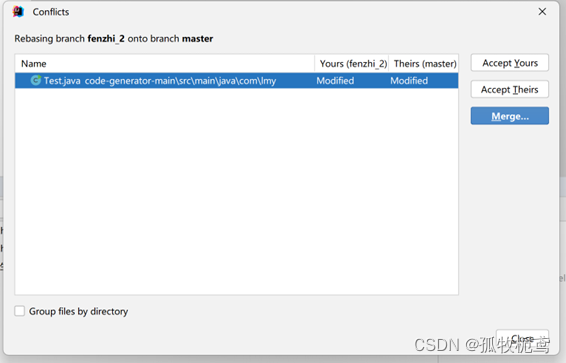
可以看到同一个位置都有改动,这就根据实际情况合并代码了,这里我的目的是master的改动和本分支的改动都要保留。
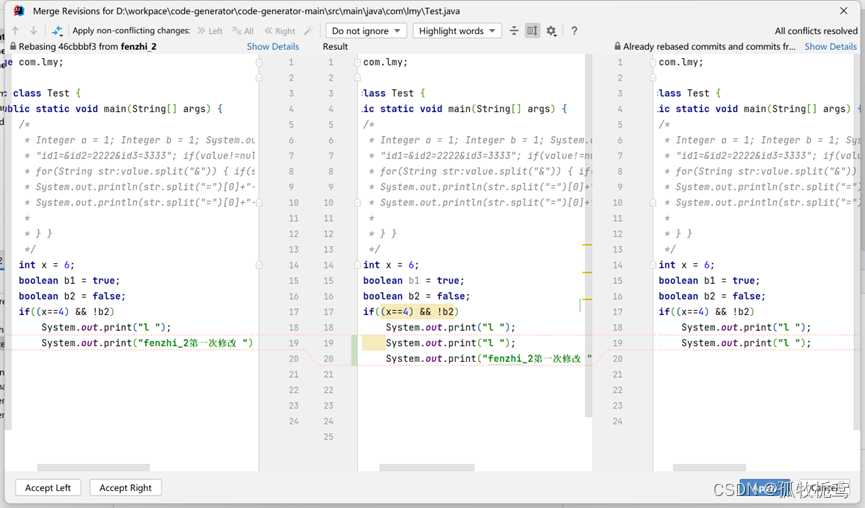
解决完后,会自动弹出一个窗口:是提交信息的修改,这个也是根据实际情况定,这里我不改,点击继续rebase。
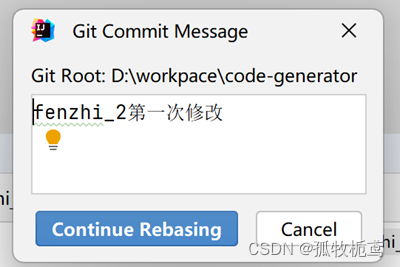
看结果:提交id为f7ec72e7的成为了fenzhi_2的基线。

我们再看一下上面解决冲突后的代码变更记录:
先看基线的变更是Test.java文件进行了变更

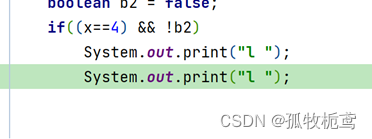
分支第一次提交id为a6330cc0的也修改了这个Test.java。那我们上面rebase后,本次变更就得在基线的基础上变更,那我们看看是不是
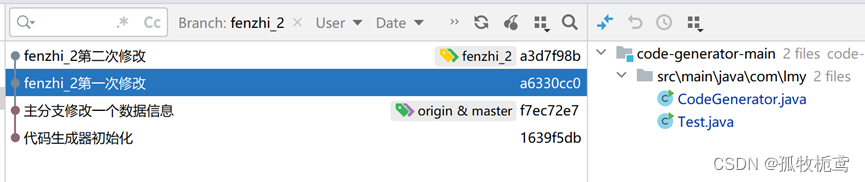
结果来看,是我们想要的。这个结果是上面解决冲突的结果。
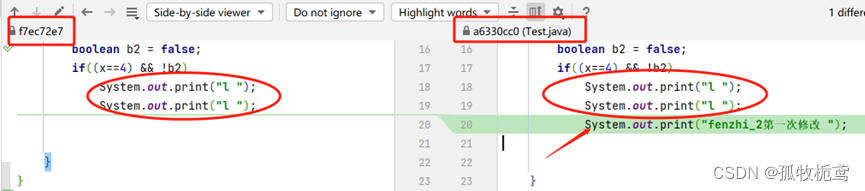
接下来push:可以看到push有俩个操作,一个push一个是force push(强制推送)。
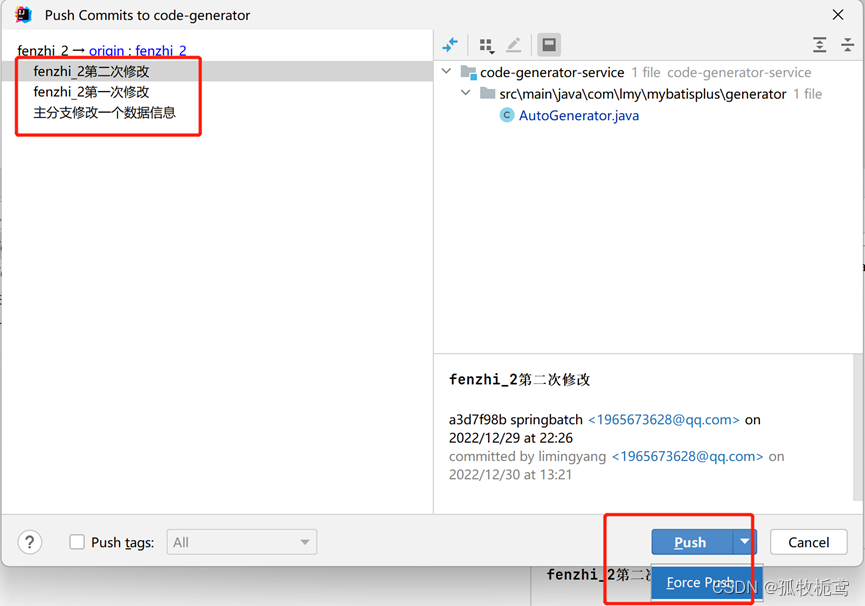
若分支是自己使用,那我们就强制推送。本地的分支提交记录覆盖远程的。
看一下远程仓库记录:
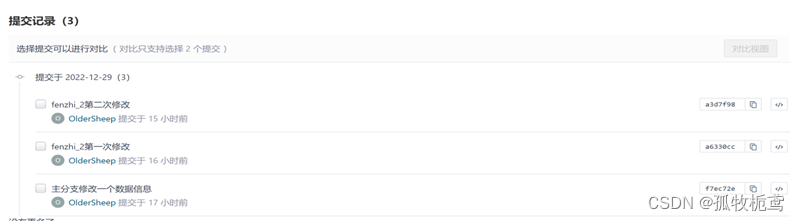
上面的操作是分支改变基线,那反过来操作呢,在master上rebase呢。
看一下分支fenzhi_3:这个分支做了俩次变更
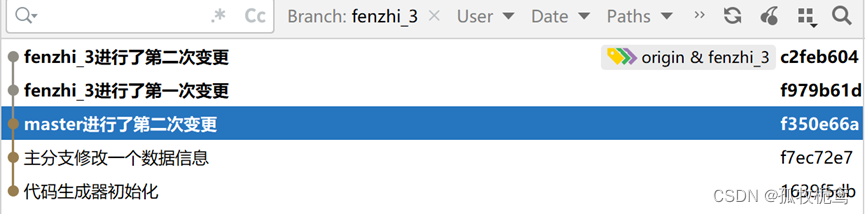
Master也做了俩次变更
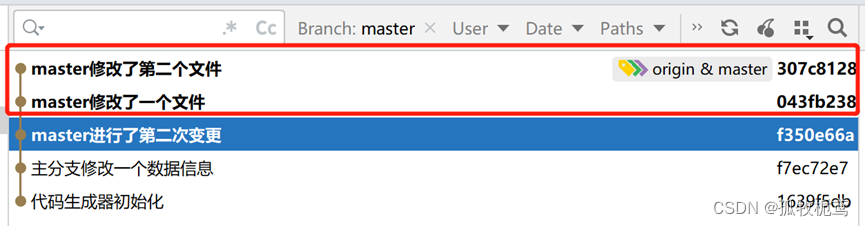
在master上进行rebase onto fenzhi_3:
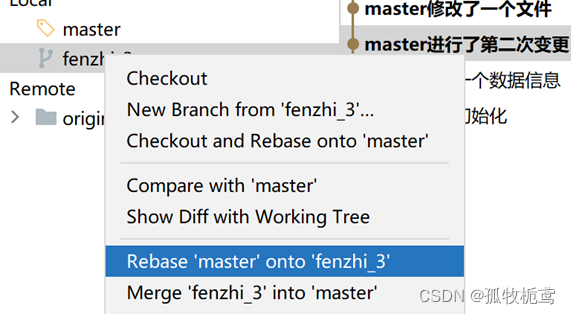
可以看到有个提示:
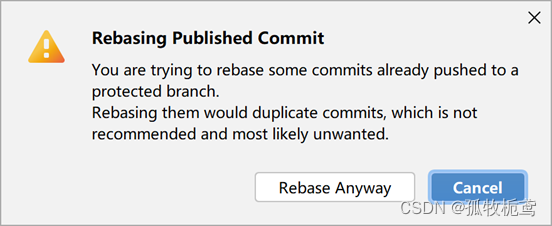
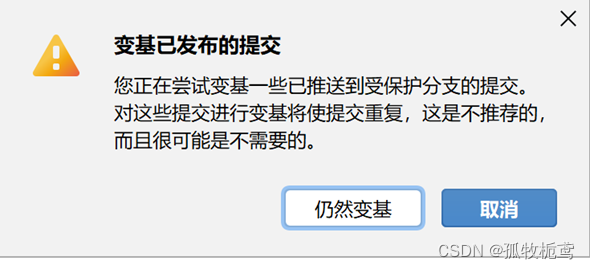
大概意思就是会对master的提交记录进行修改,看下执行结果:
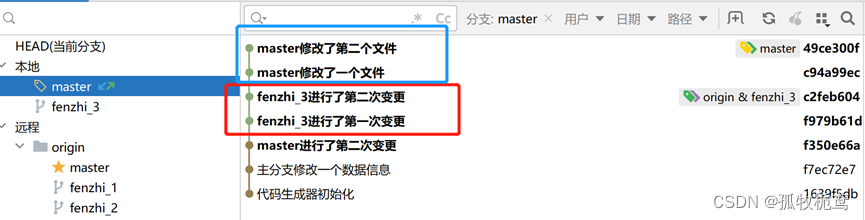
发现分支的提交记录在master记录之前,这个与merge操作是相反的。继续操作push
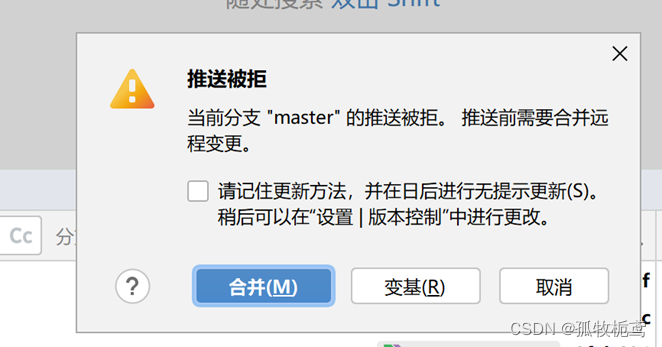
可以看到上面提示,若点击合并呢:可以看到分支的提交跟master在一条线上,但最上面又有一条合并记录。
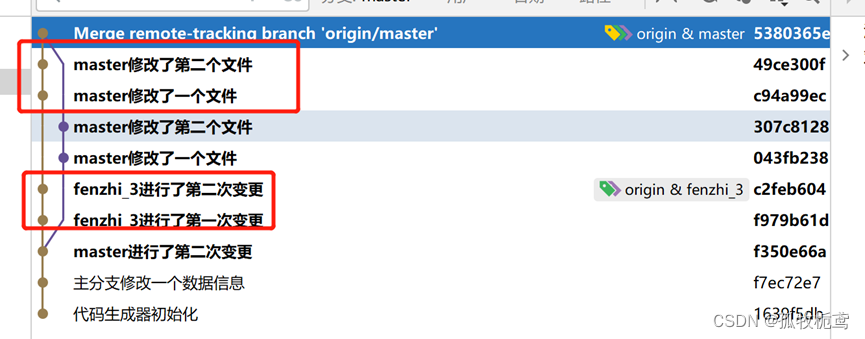
若点击的是rebase呢:可以看到是将分支fenzhi_3的提交放在了最前面。这个操作就模拟了代码merge,但提交记录是一条线。这个才是我们的本意。
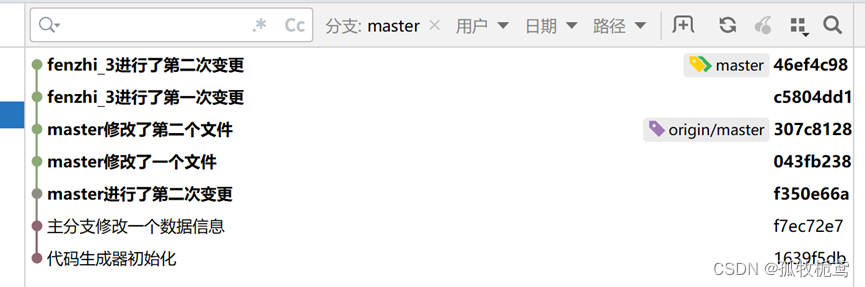
这个时候若继续将fenzhi_3 merge到master时只会产生一个合并记录:
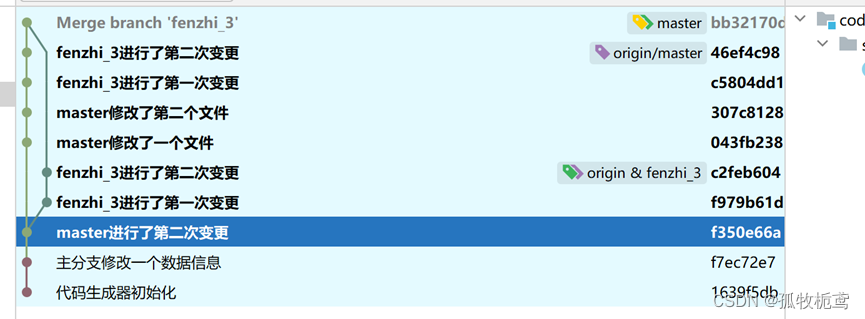
不同分支之间的rebase操作是一个分支合并另一个分支的变更。这种操作的应用场景是啥呢?看下面案例:
比如有个fenzhi_2和fenzhi_3


比如fenzhi_2开发的时候需要fenzhi_3的代码,并把fenzhi_3的提交信息合并到fenzhi_2上,后续代码都将在fenzhi_2上继续开发。那rebase操作就相当于使用了cherry-pick操作。但是fenzhi_2和fenzhi_3的基线不一致的话。就要考虑cherry-pick操作了,后面会通过案例详细说明。
开始操作:
指定当前分支是fenzhi_2,在fenzhi_3上右击鼠标选择变基操作:
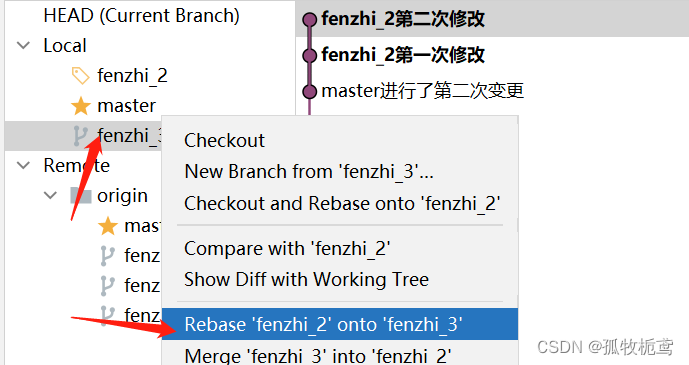
可以看到有代码冲突,说明在将fenzhi_3的提交变更一次依次合并到本分支的时候,遇到了fenzhi_2在同一文件的变更记录。这时候要慎重选择了。我这里需要保留俩个分支的变更。解决完冲突后,继续rebase即可
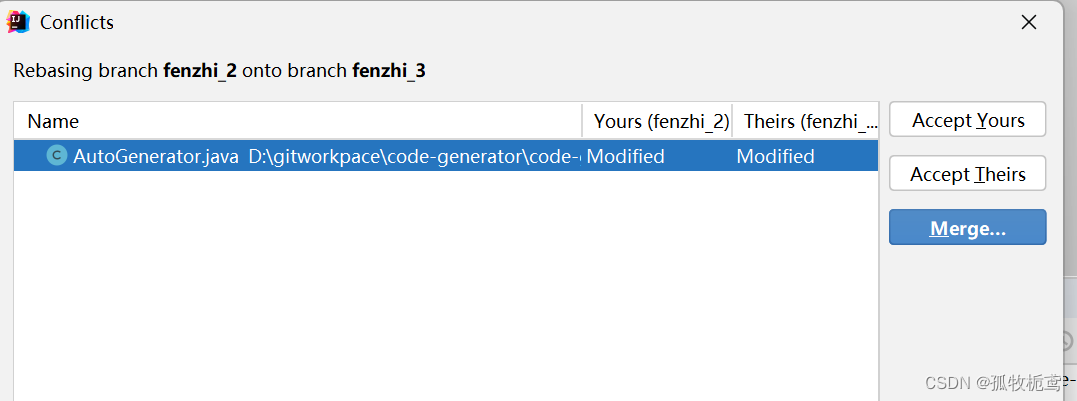
看下结果,可以看到,它是将fenzhi_3的变更记录放在了fenzhi_2的前面,这跟cherry-pick是不一样的。所以选择合并不同分支代码的时候就要想清楚了。
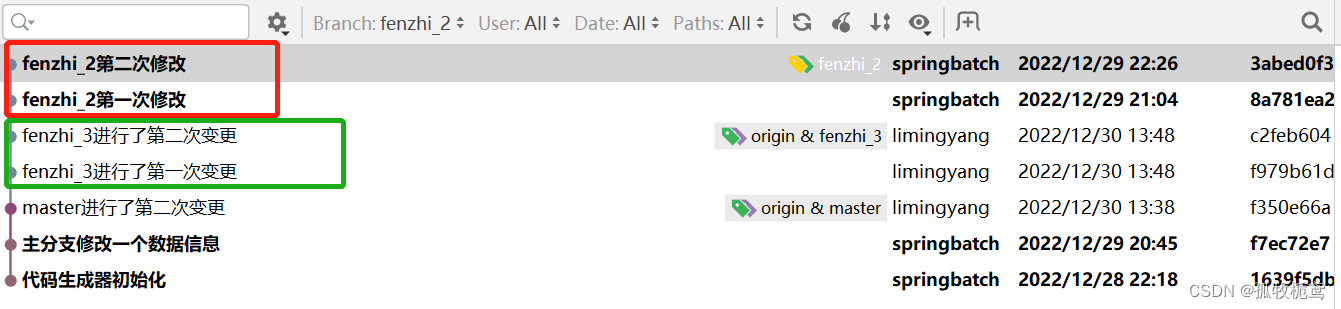
推送代码即可:这里是强制推送。这里前提是必须保证fenzhi_2的最新提交记录与远程仓库一样的,若不确定的话,还是不要进行强制推送了。
看下分支fenzhi_1的基线是1639f5db,并提交俩次变更

看下分支fenzhi_2的基线是b269d2a0,提交一次变更。

从上面可以看到fenzhi_2的基线比fenzhi_1的基线高一个版本,这就会有俩种rebase情况,fenzhi_1 rebase onto fenzhi_2 或者 fenzhi_2 rebase onto fenzhi_1。
1、先看一下fenzhi_1 rebase onto fenzhi_2,操作步骤跟上面的一样,这里直接看结果:

看结果,这里不仅把fenzhi_2的提交合并,也会把master的新提交合并过来,这里很容易理解,因为rebase的操作就是从共同基线开始的。
2、看一下fenzhi_2 rebase onto fenzhi_1:可以看到有个提示
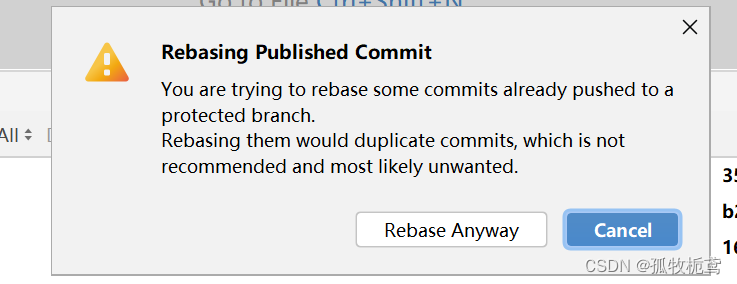
翻译下:
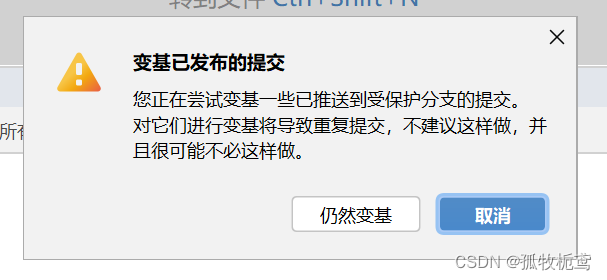
若继续rebase呢:看下结果,很明显fenzhi2_的基线就变了。

Rebase操作可实现的功能有:
1、 同分支的多次提交合并、提交顺序改变,提交记录修改;
2、 修改下游分支的基线,同步上游的变更,将下游分支基线修改为最新;
3、 实现分支代码合并到主线上,类似于merge操作,但区别是提交路径的不同;
4、 实现不同分支之间的代码提交合并。
根据上面的操作就可以看到rebase的主要核心用途是下游分支与上游分支的基线同步、同分支的提交记录合并或者提交信息的修改。其他的操作只有特殊情况下才可以使用。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定