Springboot集成kafka
上一期,我是带着大家入门了SpringBoot整合WebSocket,今天我再来一期kafka的零基础教学吧。不知道大家对kafka有多少了解,反正我就是从搭建开始,然后再加一个简单演示,这就算是带着大家了个门哈,剩下的我再后边慢慢出教程给大家说。
演示环境:idea2021 + springboot 2.3.1REALSE + CentOS7 + kafka
kafka是linkedin开源的分布式发布-订阅消息系统,目前归属于Apache的顶级项目。主要特点是基于pull模式来处理消息消费,追求高吞吐量,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统。
一开始的目的是日志的收集和传输。0.8版本开始支持复制,不支持事务,对消息的丢失,重复,错误没有严格要求 适用于产生大量数据的互联网服务的数据收集业务。在廉价的服务器上都能有很高的性能,这个主要是基于操作系统底层的pagecache,不用内存胜似使用内存。
综上所述,kafka是一款开源的消息引擎系统(消息队列/消息中间件) 分布式流处理平台
下载地址:https://kafka.apache.org/downloads.html
CSDN:kafka_2.12-2.2.1.zip
通过ftp将kafka安装包kafka_2.11-0.9.0.1.tgz上传到服务器 /opt/monitor/kafka目录下
执行命令unzip kafka_2.12-2.2.1.zip 解压上传的kafka安装包
unzip kafka_2.12-2.2.1.zip
输入命令ll查询解压情况
执行命令 cd /opt/monitor/kafka/kafka_2.12-2.2.1 进入kafka目录
cd /opt/monitor/kafka/kafka_2.12-2.2.1
1 配置并启动zookeeper
执行命令 创建zookeeper日志文件存放路径
mkdir zklogs
执行命令 修改zookeeper的配置信息
vim config/zookeeper.properties
按一下键盘上的 i 键进入编辑模式,将光标移动到日志文件存放路径配置信息所在行,并修改dataDir=/opt/monitor/kafka/kafka_2.12-2.2.1/zklogs
dataDir=/opt/monitor/kafka/kafka_2.12-2.2.1/zklogs
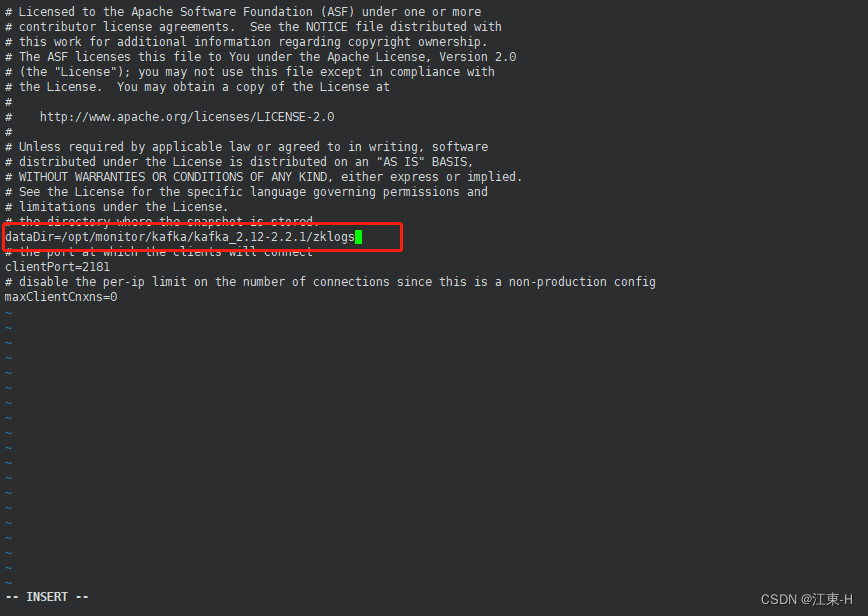
修改好后按下键盘上的Esc 键后 输入:wq 并按下Enter键保存修改的信息并退出,注意这里的:也是要输入的
执行sh./zookeeper-server-start.sh ./config/zookeeper.properties & 命令后台启动zookeeper

注意这里提示报错权限不足,使用命令修改权限(个人建议把bin的权限全部修改成777)
chmod 777 zookeeper-server-start.sh
显示没有报错启动zookeeper成功
sh ./zookeeper-server-start.sh /opt/monitor/kafka/kafka_2.12-2.2.1/config/zookeeper.properties
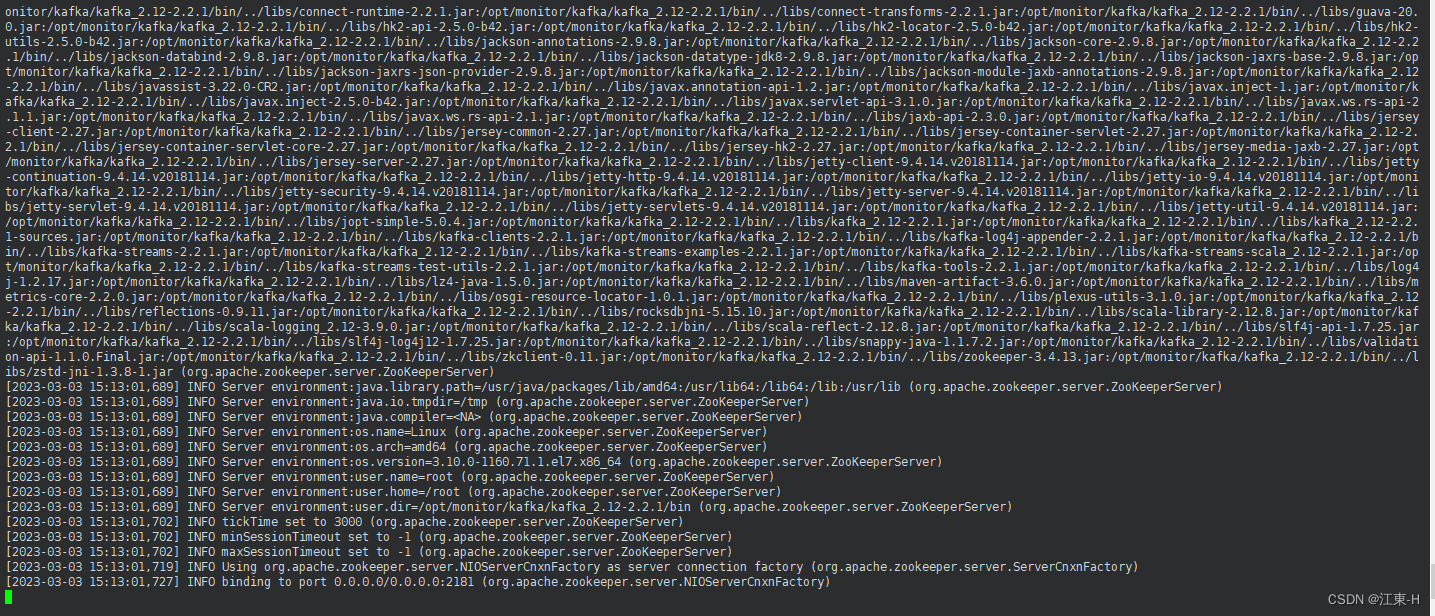
执行命令ps -ef | grep zookeeper 查看zookeeper是否启动成功,出现类型如下信息表示成功启动
2 配置并启动kafka
执行命令 vim config/server.properties 修改kafka的配置信息
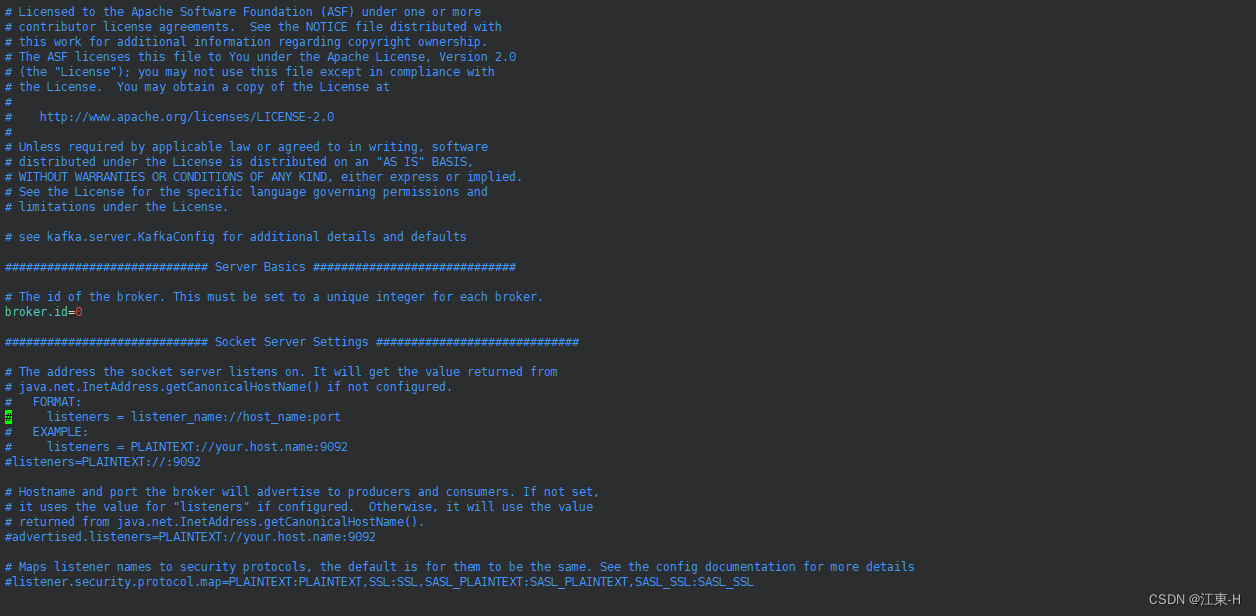
按一下键盘上的 i 键进入编辑模式,修改advertised.listeners=PLAINTEXT://外网IP:9092;
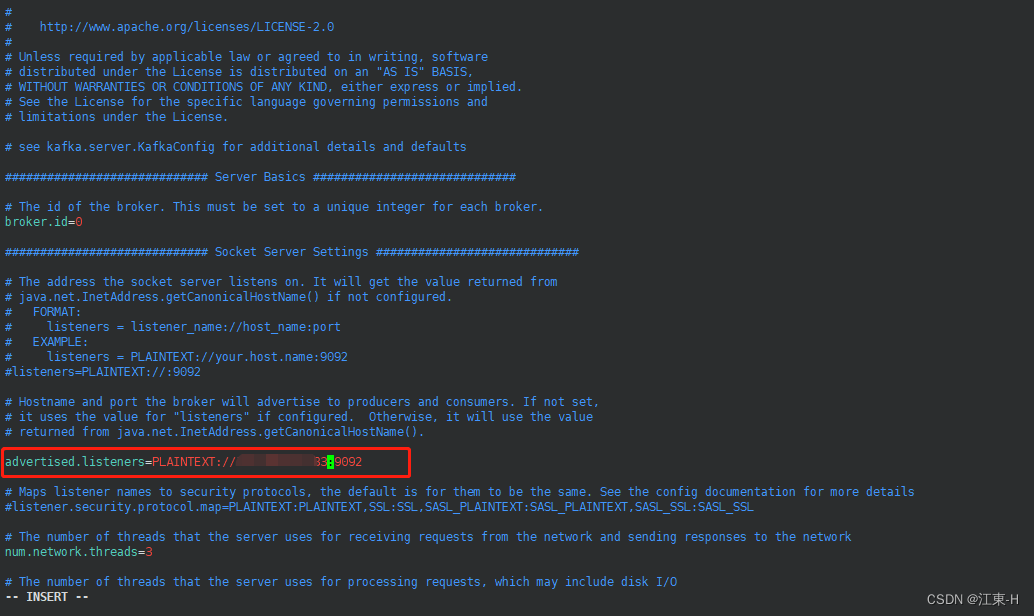
修改log.dirs=/opt/monitor/kafka/kafka_2.12-2.2.1/logs该参数为kafka日志文件存放路径
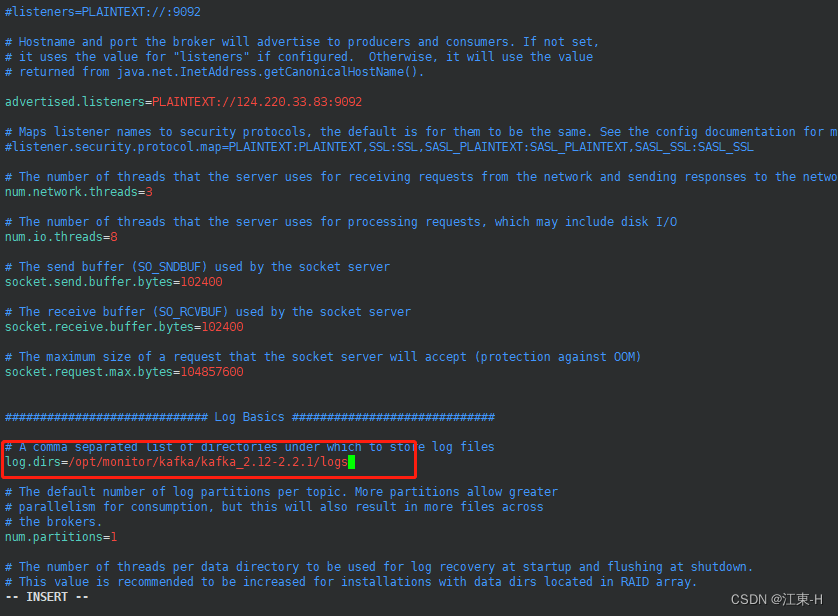
修改每个topic的默认分区参数num.partitions,默认是1,具体合适的取值需要根据服务器配置进程确定
修改完成后按下键盘上的Esc 键后 输入:wq 并按下Enter键 保存修改的信息并退出,注意这里的:也是要输入的.
cd /opt/monitor/kafka/kafka_2.12-2.2.1/bin #进入kafka启动目录
sh kafka-server-start.sh /opt/monitor/kafka/kafka_2.12-2.2.1/config/server.properties #启动kafka服务指定配置文件
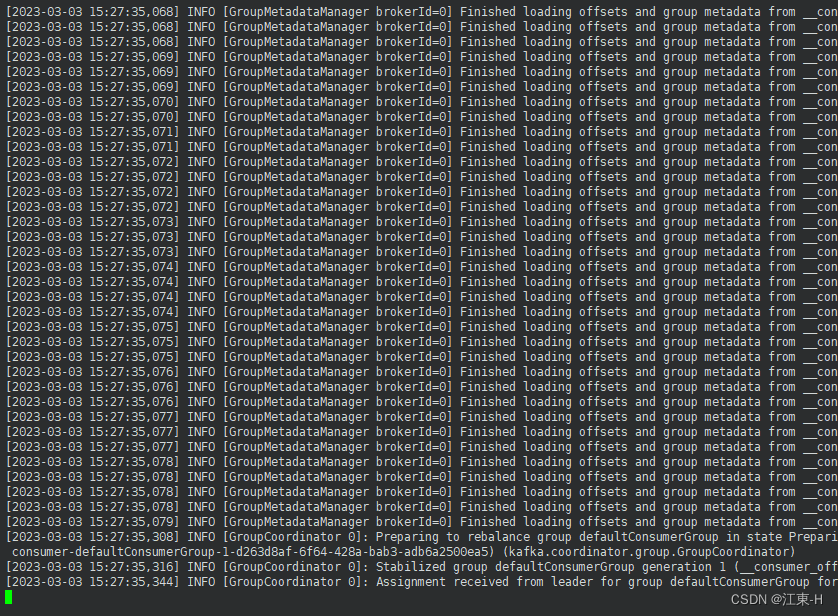
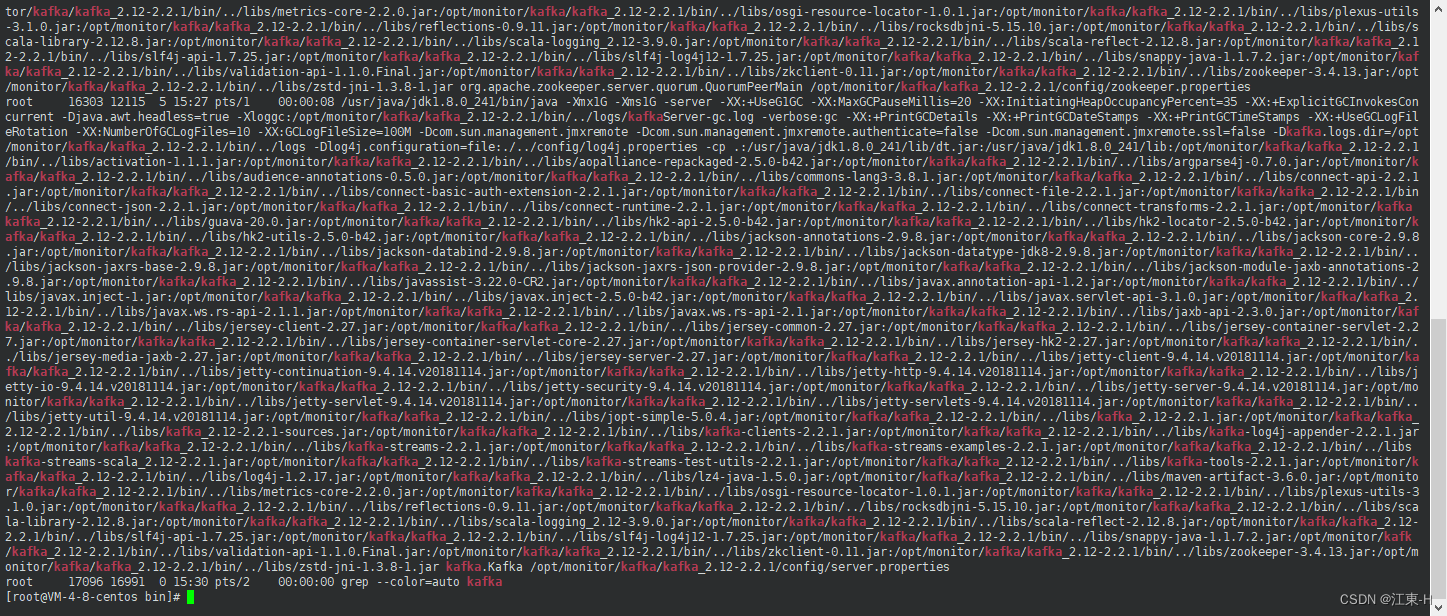
执行命令查看kafka是否启动成功
ps -ef | grep kafka #查看kafka是否启动成功
<!--kafka依赖-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
profiles:
active: dev
server:
port: 8070
package com.suihao.kafka;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* @author suihao
* @Title: KafkaProducer
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@Component
@Slf4j
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
//自定义topic
public static final String TOPIC_TEST = "topic.test";
//
public static final String TOPIC_GROUP1 = "topic.group1";
//
public static final String TOPIC_GROUP2 = "topic.group2";
public void send(Object obj) {
String obj2String = JSONUtil.toJsonStr(obj);
log.info("准备发送消息为:{}", obj2String);
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
//发送失败的处理
log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
}
});
}
}
package com.suihao.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* @author suihao
* @Title: KafkaConsumer
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = KafkaProducer.TOPIC_TEST, groupId = KafkaProducer.TOPIC_GROUP1)
public void topic_test(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
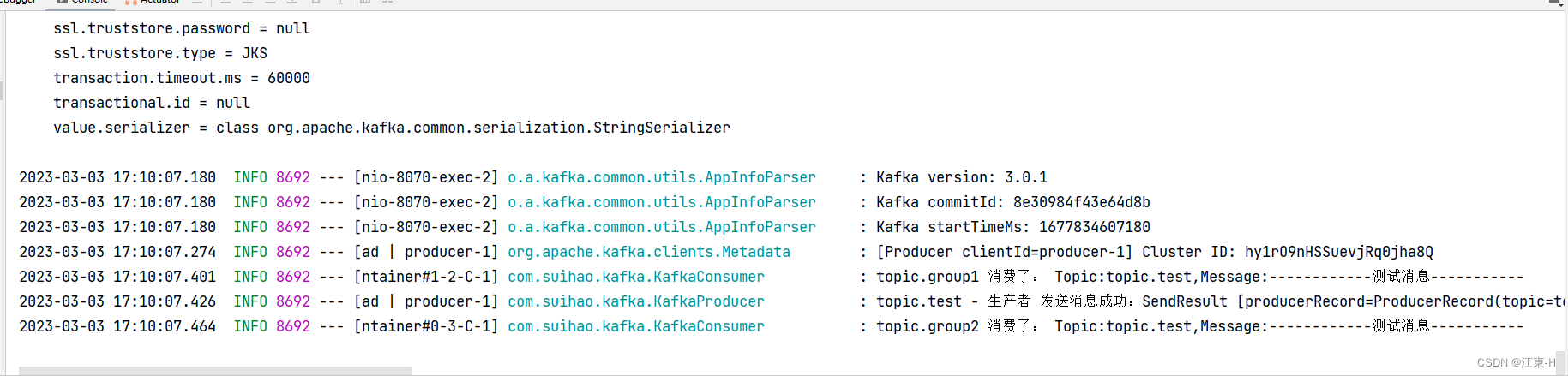
log.info("topic.group1 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
@KafkaListener(topics = KafkaProducer.TOPIC_TEST, groupId = KafkaProducer.TOPIC_GROUP2)
public void topic_test1(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("topic.group2 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
package com.suihao.controller;
import com.suihao.kafka.KafkaProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author suihao
* @Title: KafkaController
* @Description TODO
* @date: 2023/03/03 17:
* @version: V1.0
*/
@RestController
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@GetMapping("/send")
public void sendMsg(){
kafkaProducer.send("------------测试消息-----------");
}
}
彩蛋: https://gitee.com/suihao666/SpringBoot-Kafka
你不一定逆风翻盘,但一定要向阳而生。山水相逢,我们江湖见。我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
从一开始,我就是一个Windows高手。我从MS-DOS开始。我安装了Windows2.1以及此后的所有Windows。现在,我家里有10台不同的Windows机器在运行,从Windows7Ultimate到各种版本的WindowsServer。我还没有完成Windows8,也不想去那里。我在服务器和各种软件方面都有UNIX经验,但它并不是我的首选环境。但是,我想我正在转换。我试图假装使用Cygwin和MSYS在Windows下运行UNIX。我的目的是搭建一个开发环境。两者都让我失望了。我花了比开发更多的时间来解决一系列技术问题。这是NotAcceptable。到目前为止,我的Ruby