目录
对给定的n个插值点,可以构造n-1次Lagrange插值多项式。对插值区间内的任意x,对应的y值可由如下公式计算:
MATLAB中没有lagrange函数,需要提前自己构造。
构造函数代码如下:
function y=lagrange(x0,y0,x)
ii=1:length(x0);
y=zeros(size(x));
for i=ii
ij=find(ii~=i);
y1=1;
for j=1:length(ij),y1=y1.*(x-x0(ij(j)));
end
y=y+y1*y0(i)/prod(x0(i)-x0(ij));
end
end给定的部分数值表如下,用Lagrange插值法计算
的近似值。
| x | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 |
| f(x) | -0.916291 | -0.693147 | -0.510826 | -0.356675 | -0.223144 |
解:
MATLAB代码如下:
clc;clear;
x=[0.4:0.1:0.8];
y=[-0.916291,-0.693147,-0.510826,-0.356675,-0.223144];
lagrange(x,y,0.54)
%函数部分
function y=lagrange(x0,y0,x)
ii=1:length(x0);
y=zeros(size(x));
for i=ii
ij=find(ii~=i);
y1=1;
for j=1:length(ij),y1=y1.*(x-x0(ij(j)));
end
y=y+y1*y0(i)/prod(x0(i)-x0(ij));
end
end运行结果如下:
ans =-0.6161
不少实际文体不仅要求在节点上函数值相等,还要求导数值也相等,甚至高阶导数值也相等,满足此种要求的插值多项式就是Hermite插值多项式。
已知n个插值点,以及对应的一阶导数值
。则对插值区间内任意x的函数值,对应y的Hermite插值公式如下:
上式子中的给定如下:
给定如下:
需要提前利用数学基础,自己构建hermite函数,相关代码如下:
function y=hermite(x0,y0,y1,x)
n=length(x0);
m=length(x);
for k=1:m
yy=0.0;
for i=1:n
h=1.0;
a=0.0;
for j=1:n
if j~=i
h=h*((x(k)-x0(j))/(x0(i)-x0(j)))^2;
a=1/(x0(i)-x0(j))+a;
end
end
yy=yy+h*((x0(i)-x(k))*(2*a*y0(i)-y1(i))+y0(i));
end
y(k)=yy;
end
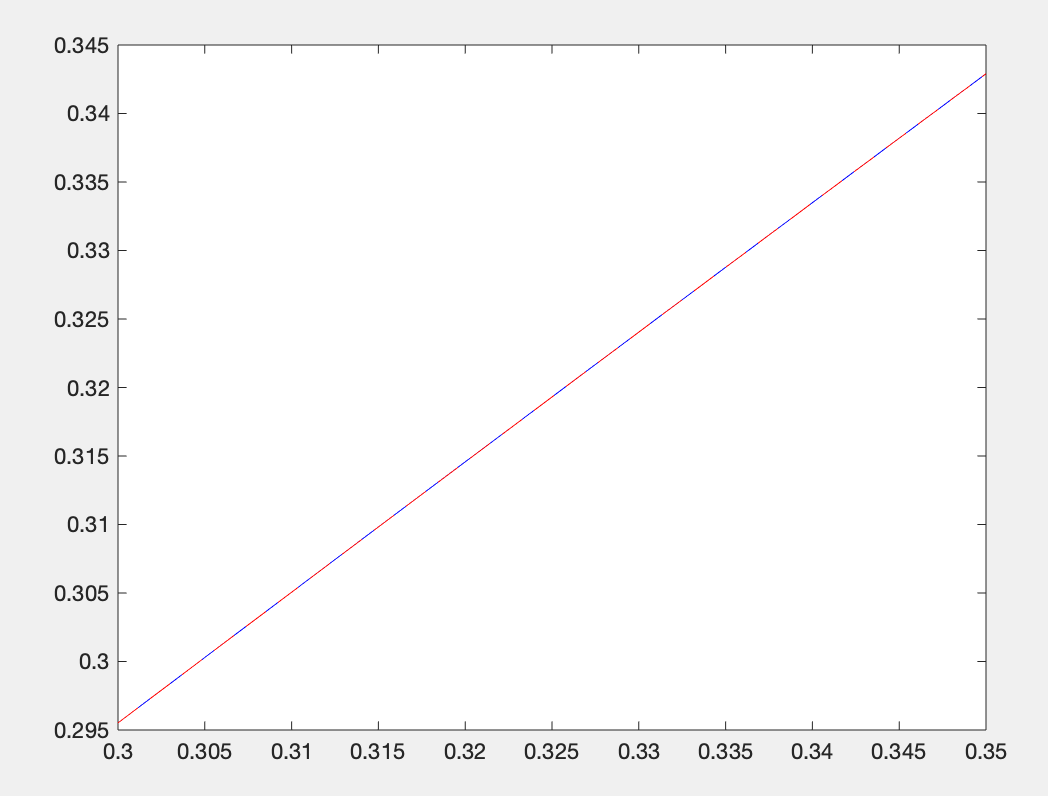
end给定如下数据,试构造Hermite多项式求出的近似值。并画图与标准值对比。
| 0.3 | 0.32 | 0.35 | |
| 0.29552 | 0.31457 | 0.34290 | |
| 0.95534 | 0.94924 | 0.93937 |
解:
MATLAB代码如下:
clc;clear;
x0=[0.3,0.32,0.35];
y0=[0.29552,0.31457,0.34290]; %函数值
y1=[0.95534,0.94924,0.93937]; %导数值
format long;
y=hermite(x0,y0,y1,0.34)
%画图
x=[0.3:0.005:0.35];
y=hermite(x0,y0,y1,x);
plot(x,y,'b') %蓝色为插值计算结果
y2=sin(x); %标准值
hold on
plot(x,y2,'r--') %红色为标准值
%函数部分
function y=hermite(x0,y0,y1,x)
n=length(x0);
m=length(x);
for k=1:m
yy=0.0;
for i=1:n
h=1.0;
a=0.0;
for j=1:n
if j~=i
h=h*((x(k)-x0(j))/(x0(i)-x0(j)))^2;
a=1/(x0(i)-x0(j))+a;
end
end
yy=yy+h*((x0(i)-x(k))*(2*a*y0(i)-y1(i))+y0(i));
end
y(k)=yy;
end
end
运行结果:
y =0.333488890074074
根据区间[a,b]上给出的节点做插值多项式p(x)的近似值,一般总认为p(x)的次数越高则越逼近f(x)的精度,也就越好。但实际上并非如此。
典型的反例函数如下:
此函数在区间[-5,5]上的各阶导数均存在,但是在此区间上取n个节点所构成的Lagrange插值多项式在全区间内并非都是收敛的。可能这么说还难以理解,我们来看一个例子。
函数f(x)在区间[-5,5]上,取n=10,利用Lagrange插值法进行插值计算,并画图和标准值对比。函数f(x)定义如下:
解:
MATLAB代码如下:
clc;clear;
%插值计算
x=[-5:1:5];
y=1./(1+x.^2);
x0=[-5:0.1:5];
y0=lagrange(x,y,x0);
%标准值
y1=1./(1+x0.^2);
%绘图
plot(x0,y0,'--r') %红色代表插值
hold on
plot(x0,y1,'-b') %蓝色代表原曲线
%函数部分
function y=lagrange(x0,y0,x)
ii=1:length(x0);
y=zeros(size(x));
for i=ii
ij=find(ii~=i);
y1=1;
for j=1:length(ij),y1=y1.*(x-x0(ij(j)));
end
y=y+y1*y0(i)/prod(x0(i)-x0(ij));
end
end
运行结果:
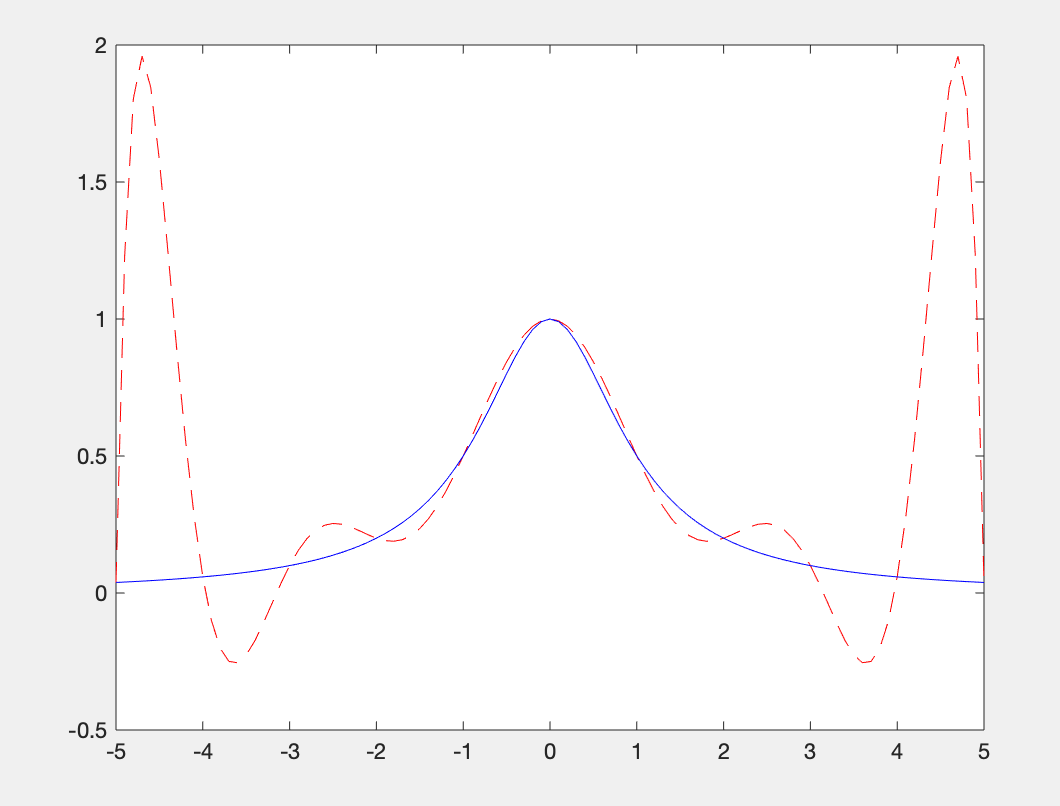
可以发现该插值公式出现了较大误差。
分段插值可以解决Rung问题,所谓分段插值就是通过插值点用折线或低次曲线连接起来逼近原曲线。在MATLAB中,可以直接调用内部函数interp1()来实现。
该命令借助表格查找,对数据点之间计算内插值,从而找出一元函数f(x)在某个点的数值。该命令的常用格式有五种。
yi=interp1(x,Y,xi)
该命令返回插值向量yi,每一个元素对应于参量xi,同时由向量x和Y的内插值决定
yi=interp1(Y,xi)
假定x=1:N,其中N为向量Y的长度
yi=interp1(x,Y,xi,method)
该方法可用指定的算法计算插值。此处列举出五处常用的算法:
- 'nearest':最近邻点插值,可直接完成计算
- 'linear':线性插值,属于缺省方式,可直接完成计算
- 'spline':三次样条函数插值
- 'pchip'与cubic:分段三次Hermite插值
- 'v5cubic'与‘makima':修改后的Akima三次Hermite插值
备注:对于超出x范围的xi分量,使用nearest,linear,v5cubic插值算法会返回NaN;如果使用其他方法,interp1将对超出的分量执行外插值算法
yi=interp1(x,Y,method,'extrap')
yi=interp1(x,Y,method,extrapval)
确定超出x范围的xi中的分量的外插值extrapval,该值通常取NaN或者0
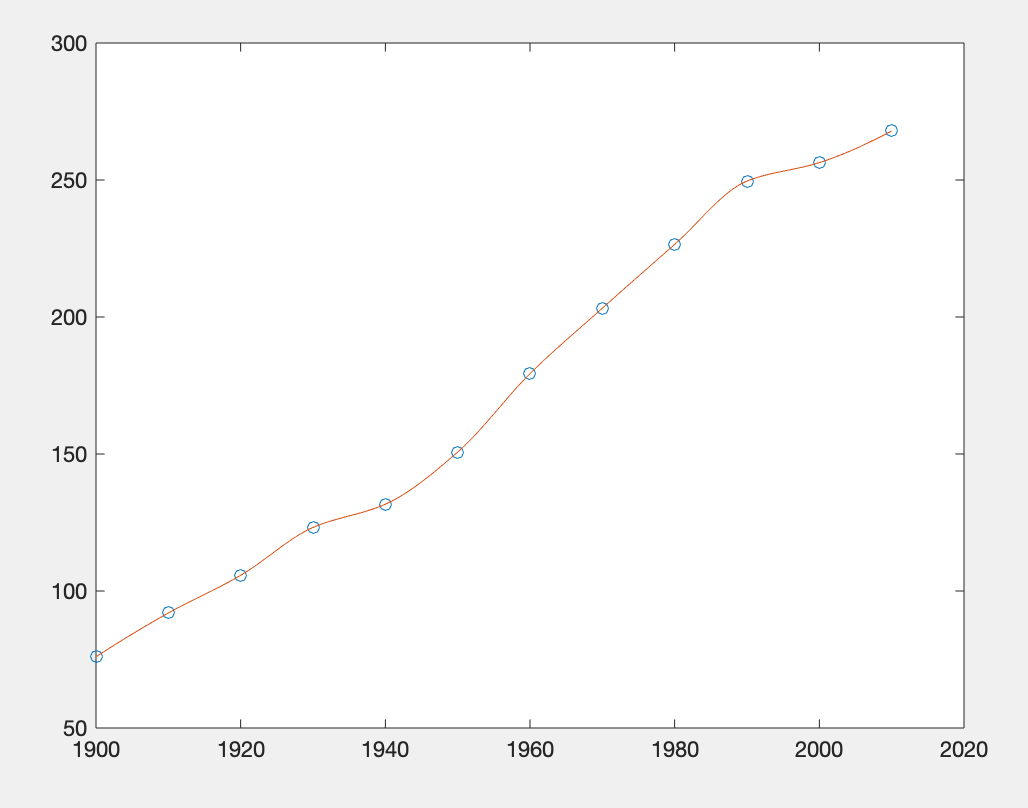
给定以下数据,计算1995年对应的product值,并将该插值计算的结果画图。
| year | 1900 | 1910 | 1920 | 1930 | 1940 | 1950 | 1960 | 1970 | 1980 | 1990 | 2000 | 2010 |
| product | 75.995 | 91.972 | 105.711 | 123.203 | 131.669 | 150.697 | 179.323 | 203.212 | 226.505 | 249.633 | 256.344 | 267.893 |
解:
MATLAB代码如下:
clc;clear;
year=1900:10:2010;
product=[75.995,91.972,105.711,123.203,131.669,...
150.697,179.323,203.212,226.505,249.633,256.344,267.893];
p1995=interp1(year,product,1995) %单独计算1995年
%画图
x=1900:1:2010;
y=interp1(year,product,x,'PCHIP'); %使用三段三次Hermite插值的方法计算
plot(year,product,'o',x,y)
%实际值在图像中用圈圈表示运行结果:
p1995 = 2.529885000000000e+02
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!