文章目录
EleasticSearch7.2.0 (如果你需要推送数据到ES,请先部署她)
-- 拉取镜像
docker pull logstash:7.2.0
--创建挂载目录
mkdir -p /home/jamel/docker/software/logstash/conf.d
cat <<EOF > /home/jamel/docker/software/logstash/logstash.yml
node.name: logstash
http.host: "0.0.0.0"
# 192.168.1.168:9200 填写自己的ES服务地址,支持集群
xpack.monitoring.elasticsearch.hosts: ["192.168.1.168:9200"]
xpack.monitoring.enabled: true
path.config: /usr/share/logstash/conf.d/*.conf
path.logs: /var/log/logstash
EOF
cat <<EOF > /home/jamel/docker/software/logstash/conf.d/log.conf
input {
# 这块基于需求配置。我这边是SpringBoot项目日志直接推送至logstash
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
# 可以配置 filebeat推送
# beats {
# port => 5044
# }
# 可以配置 自动读取文件地址
# file{
# path=> "/home/jamel/docker/logs/*.log"
# }
}
output {
# 表示推送到es服务器上
elasticsearch {
# es服务器地址列表
hosts => ["192.168.1.168:9201"]
# 每个一个log
index => "log-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
docker run -it -d \
-p 5044:5044 \
-p 5045:5045 \
--name Logstash \
-e TZ=Asia/Shanghai \
-v /home/jamel/docker/software/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /home/jamel/docker/software/logstash/conf.d/:/usr/share/logstash/config/ \
-v /home/jamel/docker/software/logstash/conf.d/template/:/usr/share/logstash/config/template/ \
--restart=always \
-m 1024m \
logstash:7.2.0
# 查看启动日志
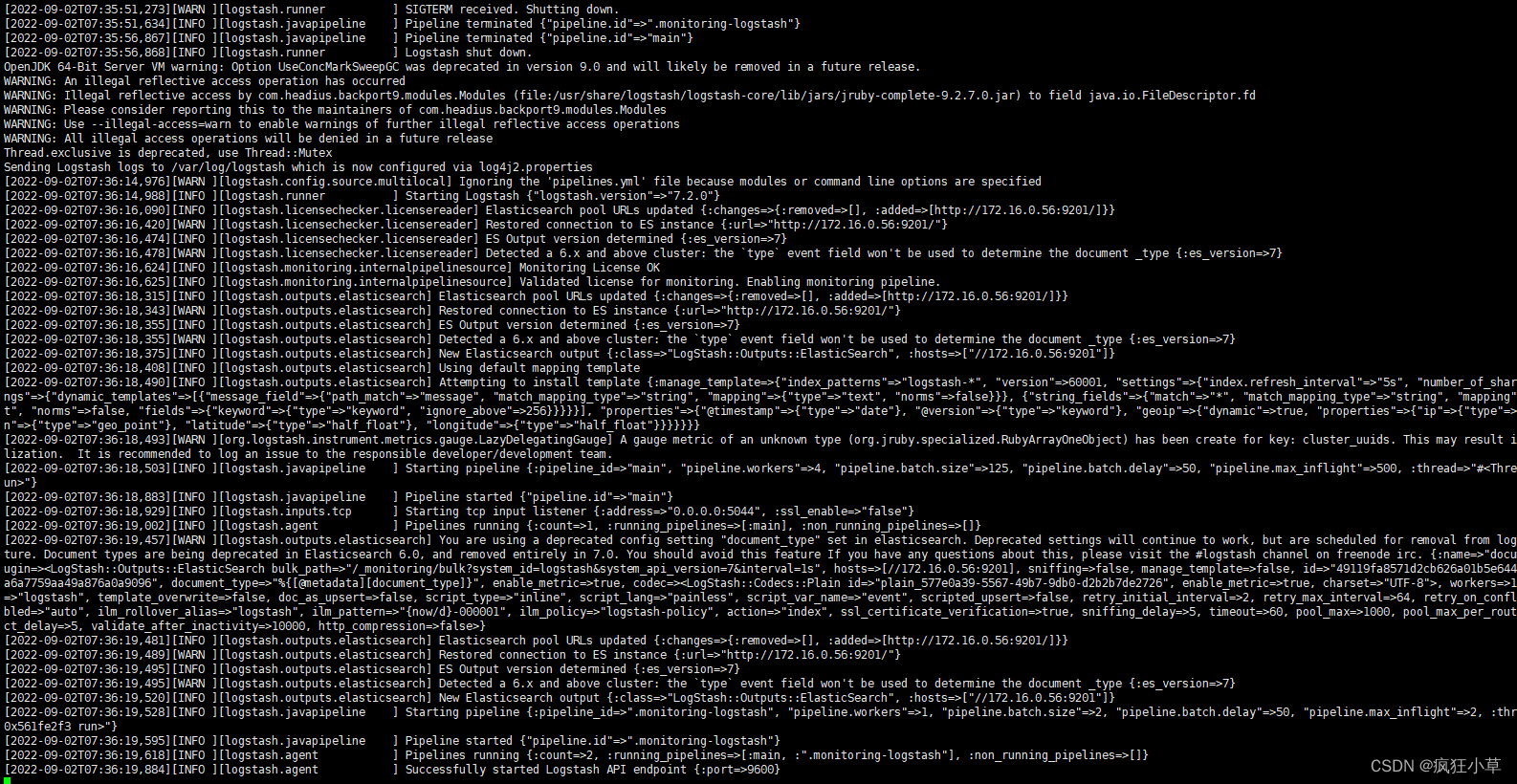
docker logs --tail=10 -f Logstash
启动成功图片
Docker推荐参数介绍
| 名称 | 描述 |
|---|---|
| -p ServerPort:DockerPort | 指定docker容器内部端口和服务器端口的的映射,最好配置成一样 |
| –name | 设置启动的docker容器名称,不填默认为镜像名称 |
| -e TZ=Asia/Shanghai | 指定docker容器时间为上海时间,否则会出现八小时数据时差问题 |
| –restart=always | 自动重启 |
| -m 1024m | 限制docker的运行内存 |
1.相关建议,启动后没有数据进入,请确认防火墙是否开启。
# 防火墙端口开放命令
firewall-cmd --zone=public --add-port=5044/tcp --permanent
firewall-cmd --zone=public --add-port=5045/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。问题1)我想知道rubyonrails是否有功能类似于primefaces的gem。我问的原因是如果您使用primefaces(http://www.primefaces.org/showcase-labs/ui/home.jsf),开发人员无需担心javascript或jquery的东西。据我所知,JSF是一个规范,基于规范的各种可用实现,prim
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我的项目布局如下:-Project-css-import.scss-_sass/main.scssimport.scss的内容是:------@import"main.scss";我期望发生的是将main.scss导入到import.scss中,然后,import.scss将在生成的_site/目录中编译为import.css。相反,我收到以下错误Conversionerror:Therewasanerrorconverting'css/import.scss'.jekyll2.0.3|Error:InvalidCSSafter"-":expectednumberorfunction,
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t