一个 JAVA 程序文件中主要由如下几部分构成:
package 声明
public 类:public 类与类文件名相同,因为其是作为该类文件唯一对外接口,所以需要唯一代表该类文件。
main 方法
一个带有包结构的 .java 文件以如下结构组织
package .... // 具有包结构时才需要声明,且声明必须放在第一行
import .... // 当使用了其他包的类时需要声明
public class NameOfClass{
public static void main(String[] args){
// 主方法体
}
}
在 JAVA 中,万物皆对象,所以每个 *.java 文件都是由一个类构成,我喜欢将其称为 类文件 ,一个类文件作为一个 编译单元 / 编辑单元 存在。
一个 *.java 有如下几个限制:
一个 *.java 文件只允许有一个 public class:这是为了给类装载器提供方便。同时,从设计思想的角度来说,一个文件实现一组相关的功能,并封装同时对外暴露一个接口即可,也
一个 *.java 文件允许有许多个 class:实现一个功能可能不仅靠一个类就能完成,所以允许在一个类文件中定义其它的类。在编译时,每个单独的类都会生成一个单独的 *.class 文件;
出于工程管理和设计思维:
通常不会这么做,一般一个类文件都只应该包含一个对外接口,如果需要定义和使用其他的类,通常都会在 public class 中使用内部类,内部类在编译时不会生成一个单独的
*.class文件,而是如下存在( Ttt 时 Demo01 的内部类 )。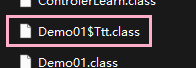
为每个
.java文件中只配备一个同名的顶级 public class 更加方便工程管理,因为这样直接从文件名就能直接知道这个文件能做什么。而不会因为在其中定义了其他类而导致文件混乱。需要实现其他功能的内部类应当定义在该 public class 中,辅助该public class 完成功能构建,而不是单独独立于 public class。单独独立于 public class 的类能被其他
*.java文件访问,这样破坏了封装。
一个 *.java 文件可以不必须包含 public class;
main 方法必须由 public static 修饰,但其并不一定存在于 public class 中(不过通常不推荐这么做)。且 *.java 文件并不一定需要包含 main 方法,只是其如果不包含则无法执行罢了。
(以上仅限于本人对该部分的思考和理解,并不一定完全正确,欢迎大家讨论。)
个人理解,包应当作为一系列相关功能的类文件(*.java)的集合,这些类共同构成一个相对较大的问题的解决方案。例如 java.utils.* 就是对一组编程过程中常常需要的功能分成各个类进行实现,并进行了打包。
包也是作为库的单元,一个库由一系列功能相关的 *.java 文件组成,编译后生成一组对应同名的 *.class 文件,由 JAVA 提供的 jar 工具打包,封装并压缩到 *.jar 文件中。JAVA 解释器负责对这些文件的寻找、装载和解释。[1]
在文件开头声明文件属于的包
包名使用域名倒置(因为域名是唯一的),保证了唯一性
什么是 classpath ?
classpath 是 JVM 用到的一个环境变量,用于指示 JVM 如何搜索 class
JVM 真正执行的是 .class 文件中的字节码。所以,JVM 需要在执行的时候知道上哪去搜索代码所需要的对应类,即上哪去找 *.class 文件。
通常情况下,JVM 搜索 abc.xyz.Hello 这个类会以如下路径搜索类:
<当前目录>\abc\xyz\Hello.class (默认)
C:\Work\project1\bin\abc\xyz\Hello.class
C:\shared\abc\xyz\Hello.class
一旦搜索到,就停止继续向下搜索。
当然,也可以在启动 JVM 时设置 classpath ,如:
java Hello -cp .;path\to\Class;...
什么是 jar ?
jar 包就是对一组 .class 文件按照 package 的目录层级进行打包,封装压缩。
在使用时可以直接导入 jar 包,直接使用其中的 .class ,运行在 JVM 上
该部分主要从 文章[3:1] 进行参考,这篇文章写的非常清晰,值得一读。本人是个初学者,为了笔记,大致记录一下文章的关键部分。
从 .java 到运行中间经历如下三个阶段:
编译:主要将 .java 变为 .class ,使得 JVM 可以加载。
加载:JVM 将需要运行的类装载进入内存,并分配空间和初始化
解释:将字节码文件解释为指令码,使其调用硬件指令进行执行
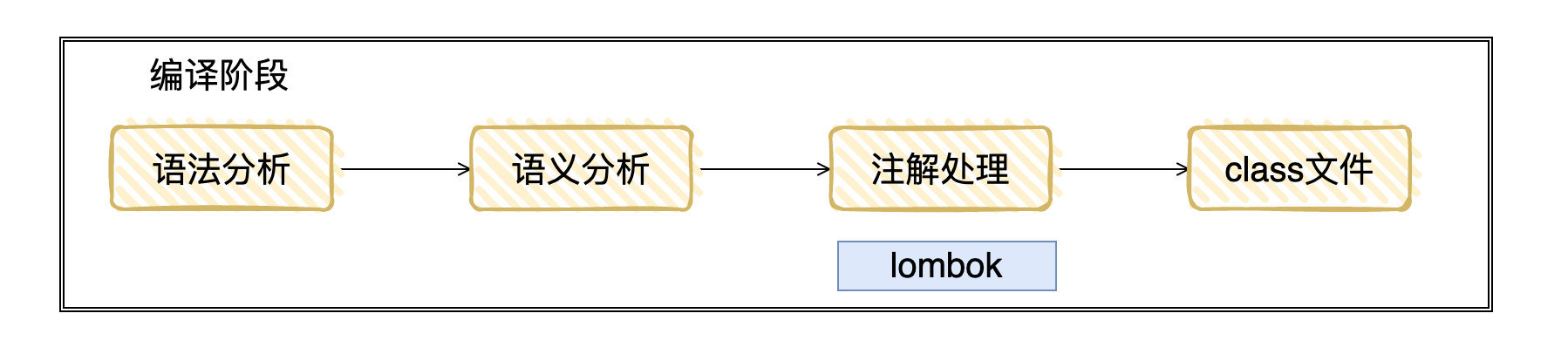
.java 文件通过编译阶段,变为 .class 文件的字节码,字节码能在 JVM 中运行,而 JVM 是我们能够跨平台运行的保证。
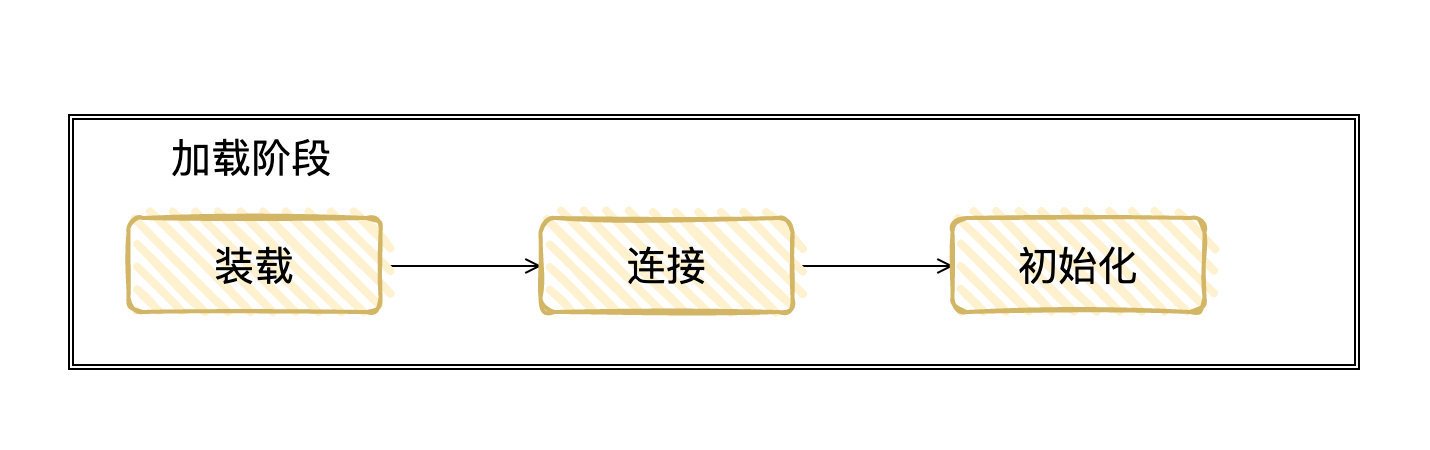
首先是装载:
java 是懒装载机制,并不会一次性将所有的类都装在进 JVM 中,而是在该类被用到时才会被装载。
装载阶段可以总结为:查找并加载类的二进制数据,在JVM「堆」中创建一个java.lang.Class 类的对象,并将类相关的信息存储在 JVM「方法区」中
然后是连接:
对 class 的信息进行验证,并且为 类变量 分配内存空间并对其赋默认值
最后是初始化:
为类的静态变量赋予正确的初始值。
解释阶段分为两种:直接解释 和 编译解释
JVM 会对“热点代码”做编译,非热点代码做解释。
热点代码:被频繁执行的代码块
在 JAVA 中,数据被分为两种类型:
基本数据类型:整型(byte,short,int, long)、浮点型(float,double)、布尔值(true,false);
引用类型:类、接口、数组。
引用类型指的是其在栈内存空间存放的并不是其数据,而是指向堆的地址。
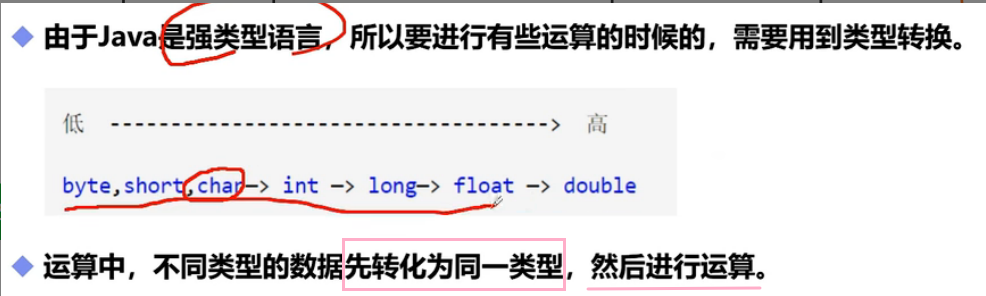
从 低 -----> 高 自动转换;
从 高 -----> 低 需要手动强制转换(强制转换就是 (目标类型) 变量 )。
看待类型转换其实可以从思考内存的角度来理解:
小内存到大内存,系统发现现有空间不够,重新为其开辟一个新的空间,并回收之前的空间即可,所以可以做到自动转换。
而大内存到小内存,如果不手动进行强制转换,系统在存数据的时候会发现现有内存空间够用,发现不了什么异常,就不管。但这样会造成数据溢出,超过对于类型存的数据时,就会发生移位,这样在内存中就超过了其类型可访问范围,那么在取数时,按照对应类型的地址访问范围就会取得一个错误的数据。
数组的使用分为:声明、创建、赋值。
声明:dataType[] arrayName,这一步只是将 arrayName 这个变量压入栈,但其并没有具体的数值内存空间;
创建:new dataType[arraySize] ,这一步才真正开辟了一个对应类型的数据空间;
赋值:赋值就是将声明的变量与创建的对象连接起来,使得声明的变量指向所创建的对象。其形式有:
按元素赋值:array[i] = value
直接:dataType[] araryName = new dataType[]{.....}
或者:dataType[] arrayName = {dataType1, dataType2, ......}
其实第二种和第三种在解释成字节码后的形式是一样的(通过看 .class 文件的反编译知道的)。
dataType[][] arrayName = new dataType[][]{ {}, {}, {} }
多维数组中除了最内层存的是实际的数据,外层全部存的是指向其下一层的地址。
主要控制语句就是:顺序、循环、分支选择
值得一提的就是 JAVA 对数组对象提供 for each 循环
方法就是为了解决一个小问题的有关控制语句和变量的集合。并没有什么很多值得说的,以下主要说一说方法中比较特别的几个知识点:
重载简单来说就是相同方法名,不同参数列表的一系列方法。在执行的时候,会根据传入的参数进行自动匹配对应的方法。
不同参数列表可以分为以下几种:
参数类型不同
参数个数不同
不同参数类型的排列顺序不同
以上三种不同单独或者混合存在都能构成重载的条件。
在编写程序时,我们有时候无法预知当前方法的参数个数,那么可以使用可变长参数,在参数类型后加 ... :
void methodName(dataType... para)
在方法体中,para 以数组的形式被访问。
限制:
一个方法至多只能有一个可变长参数;
如果存在可变长参数,那么可变长参数只能放在参数列表的末尾位置。
在我们使用 public static void main(String[] args){} 时,可以看到 main 方法是存在参数列表的,该参数由程序执行的时候传入:
java someClass args1 args2 ....
参数以字符串的形式被传入。
JAVA 中的内存可以看成如下结构:
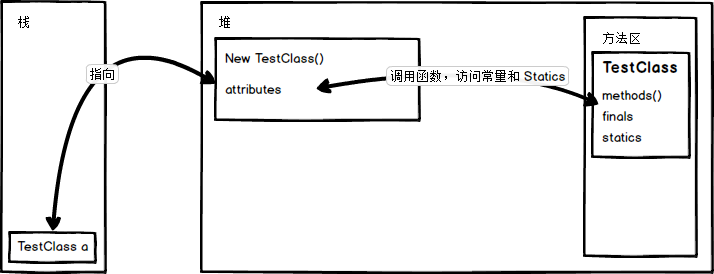
以 TestClass a = new TestClass() 在内存中的具体过程举例:
最开始在需要用到这个类的时候,JVM 就将对应的类加载进了方法区。
第一步:TestClass a 生成了一个变量 a ,能指向具有 TestClass 类结构的对象(这里用 TestClass 类结构的说法是为后面多态埋个坑);
第二步:在堆中开辟一个 TestClass 类大小的空间用于存放新实例化的对象,空间中需要存放属于该对象的属性(attributes)、以及类加载进方法区的地址,和对应方法的句柄,以便在调用时可以访问到;
常量和 statics 是可以被对象共享的,且只加载一次,所以应该跟着类走,放在类所在的空间。
第三步:变量 a 指向开辟出来的这个空间的地址,即在变量 a 中存放堆中这个新 new 出来的对象的地址。
堆中存放 new 出来的对象和数组;
可以被所有线程所共享,不会存放别的对象引用;
存放基本变量类型(会包含基本变量类型的具体数值)
存放引用对象的变量(存放这个引用在堆中的具体地址)
可以被所有线程所共享
包含了所有 class 和 静态变量
思想:封装就是将需要保护起来的变量和方法保护起来,不让外界访问,隐藏功能的实现细节,只暴露对应功能的接口,告诉使用者,你直接用我给你的这个方法即可,只要按照我的规矩用,你就能得到期望的结果。
具体做法:属性私有,不需要暴露的方法私有。即使用 private 关键字控制访问权限。
public(任意):任意位置都可以访问;
protected(父子):只有本身和具有继承关系的类内部可以访问,不同包的子类可以继承父类中 protected 修饰的变量和方法;
default(同包):只有在同一个包中的才具有访问资格,出了包,就算具有继承关系的子类,也不能访问,因为只有在同一个包中的子类才能继承 default 修饰的变量;
private(本类):只能被在该类的内部被访问到,出了{}就不能被访问。
JAVA 不支持多继承!!!
继承的内存本质是子类指向父类(最顶级的 object 类省略了):
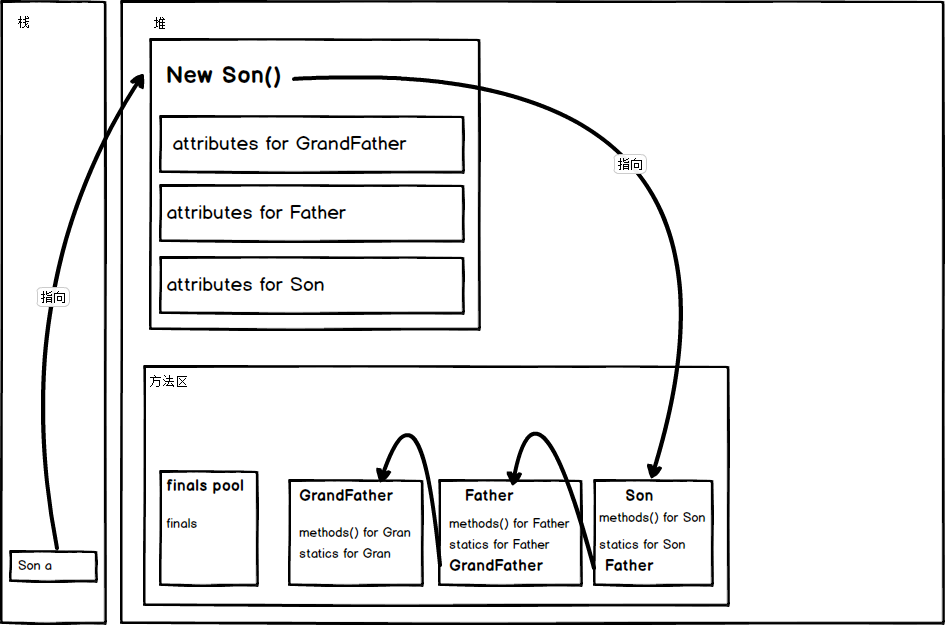
最开始,在类加载阶段:JVM 会从最顶层的类开始逐步将类导入内存,JAVA 中所有的类都是 Object 的子类,所以在导入时是从 Object 开始,然后一级一级导入,一直到 Son (本例中)。
其实从逻辑上也很好理解,子类在放入内存的时候是需要指向父类的地址的,如果父类都没有被放入内存中,那岂不是指不到,那么就会出错。
同样,在实例化 new Son() 时,是首先从基类的 Super() 出发,一级级完成初始化的。
在实例化子类时,会在子类中开辟一个属于父类成员的空间,父类成员的初始化时靠子类调用父类的构造函数执行的。
有趣的是,父类的私有属性其实也会在子类对象的空间中被分配空间,否则如果父类构造函数中有私有属性的初始化,而又没有对应的私有属性,那么岂不是会报错?
但是由于访问限制,子类对象是不能直接访问到的,需要使用父类的具有操作私有属性的
public修饰的方法才能访问。
在 JAVA 中,访问对象的属性和方法时,使用的是“搜到即停”的原则。
即在调用一个方法或者访问一个属性时,会先从子类开始搜索,如果没搜索到,则向上寻找父类中对应的方法。一旦找到,就停止搜索
重写的具体表现机制就是在子类中,声明和定义和父类相同的方法。重写是多态的基础。
这个相同的定义如下:
名称相同;
参数个数相同;
参数类型相同;
各个参数类型的排列位置相同;
缺一不可。
多态的具体表现为:父类的引用指向子类对象:
Father f = new Son();
这样做的好处就是:当 f 指向不同的子类,调用相同名称的方法时,会执行不同的函数体,得到不同的行为。
从内存角度分析多态:
子类在初始化的时候,会将父类的方法申明所使用的偏移量赋值一份。
JVM在执行
.class文件的时候,也就是在内存中执行 Java 的程序的时候,会将父类的 Method,放到 Method Table 里面,子类复写了父类中的方法后,初始化子类的时候,就会将 Method Table中相应的 Method 进行覆盖。
另一方面,所有派生类中继承于基类的方法在方法表中的偏移量跟该方法在基类方法表中的偏移量保持一致这也就是为什么可以准确的调用Method。[4]
在对象调用方法的时候,是从子类开始一级级向上搜索,当一旦找到对应的量就会直接停止搜索。
那么如果复写了父类的代码,则会在子类的方法区中相同偏移量的位置开辟一个方法空间,此时按照相同的偏移量去调用方法则会在子类中搜索到对应的方法,然后停止搜索并执行。如果没找到,才会去寻找父类的方法。
抽象类用于抽象一个领域的固有属性和方法,它存在的意义是定义和被继承。
具体形式:
public abstract AbstracClass{
// 定义属性
attributes;
// 定义具体方法
[public/protected/default/private] void/返回类型 method(){}
// 定义抽象方法,只能用 public 修饰,抽象方法必须被继承然后实现
public abstract void/返回类型 method();
}
在抽象类中:
我们可以定义属性;
我们可以具体方法;
我们可以定义抽象方法;(抽象方法只能存在于抽象类和接口中)
抽象方法就是没有方法体的方法,只声明这个方法,在被继承的时候会强制需要实现抽象方法。
接口存在的意义就是扩展类的功能,增强类的可扩展性和可维护性。
举个例子:我们可以定义一个人的基本属性(年纪,性别,体重等等一系列属性)和一些基本方法(呼吸,思考等一系列基本行为),但当这个人学了某个领域的专业知识,他就具备了这个领域的专业能力,这个时候他能解决的问题并不是每个人都能解决的,这个时候就可以通过定义接口来扩展这个人的方法库。例如会计接口中就可以定义一些专业的会计方法,而一个会计类就可以 extends Person implements Accountant
接口的特点:
接口中只允许存在抽象方法;
接口允许多继承;
接口可以包含变量,成员变量会被隐式地指定为public static final变量(并且只能是public static final变量,用private修饰会报编译错误);[5]
接口的实现类必须重写接口中定义的抽象方法;
具体形式:
// 定义接口
public interface InterfaceName{
// 接口内的方法修饰符为 public abstract
public abstract method1();
}
// 实现接口类
public class ClassName extends FatherClass Implements Interface1, Interface2(){
}
实现类通常会在类名的结尾加上 Impt (非强制),例如:ClassNameImpt
写在最后:文章中有一些自己的思考,并不保证一定正确,如果有错误欢迎在讨论区指出,一起学习。同时,也欢迎一起更加深入讨论编程中更加本质的东西。
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
目录1关系运算符2运算符优先级3关系表达式的书写代码实例:下面是面试中可能遇到的问题:1关系运算符C++中有6个关系运算符,用于比较两个值的大小关系,它们分别是:运算符描述==等于!=不等于小于>大于小于等于>=大于等于这些运算符返回一个布尔值,即true或false。例如,当x等于y时,x==y的结果为true,否则结果为false。2运算符优先级在C++中,关系运算符的优先级高于赋值运算符,但低于算术运算符。以下是关系运算符的优先级,从高到低排列:运算符描述>,,>=,关系运算符==,!=相等性运算符&&逻辑与`如果在表达式中有多个运算符,则按照优先级顺序依次进行运算。3关系表达式的书写在
一.计算机组成原理 这本书利用组合逻辑、同步时序逻辑电路设计的相关知识,从逻辑门开始逐步构建运算器、存储器、数据通路和控制器,最终集成为完整的CU原型系统,使读者从设计者的角度理解计算机部件构成及运行的基本原理,掌握软硬件协同的概念。 全书共9章,主要内容包括计算机系统概述、数据信息的表示、运算方法与运算器、存储系统、指令系统、中央处理器、指令流水线、总线系统、输入输出系统。1.计算机系统概述1.1计算机发展历程 计算机是一种能够按照事先存储的程序,自动、高速、准确地对相关信息进行处理的电子设备。1946年2月,世界上第一台电子数字计算机ENIAC(ElectronicNum
其实现在基础的资料和视频到处都是,就是看你有没有认真的去找学习资源了,去哪里学习都是要看你个人靠谱不靠谱,再好的教程和老师,你自己学习不进去也是白搭在正式选择之前,大可以在各种学习网站里面找找学习资源先自己学习一下为什么选择学软件测试?同学们理由众多!大概分这几类:①不受开发语言、行业产品变化限制;②入门更简单,对零基础、女生都友好;③软件项目都需要测试人员,职业生涯稳;④学习周期短,但薪资并不低。要想“肩扛”一条线?需掌握三大技能:技能1:掌握测试流程,熟悉系统框架能提前与开发人员一起制定测试计划,通过测试左移,推动代码评审,代码审计,单元测试,自动化冒烟测试,来保证研发阶段的质量。技能2: