目录
1.从github上下载docker-compose二进制文件安装
Compose 项目是 Docker 官方的开源项目,负责实现对 Docker 容器集群的快速编排。使用前面介绍的Dockerfile我们很容易定义一个单独的应用容器。然而在日常开发工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器;再比如在分布式应用一般包含若干个服务,每个服务一般都会部署多个实例。如果每个服务都要手动启停,那么效率之低、维护量之大可想而知。这时候就需要一个工具能够管理一组相关联的的应用容器,这就是Docker Compose。
Compose有2个重要的概念:
docker compose运行目录下的所有yml文件组成一个工程,一个工程包含多个服务,每个服务中定义了容器运行的镜像、参数、依赖。一个服务可包括多个容器实例。docker-compose就是docker容器的编排工具,主要就是解决相互有依赖关系的多个容器的管理。
官方文档地址:Install Docker Compose | Docker Documentation
https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-linux-x86_64[root@offline-client bin]# mv docker-compose-linux-x86_64 docker-compose
[root@offline-client bin]# docker-compose version
Docker Compose version v2.5.0pip install docker-composedocker run -itd -p 3306:3306 -m="1024M" --privileged=true \
-v /data/software/mysql/conf/:/etc/mysql/conf.d \
-v /data/software/mysql/data:/var/lib/mysql \
-v /data/software/mysql/log/:/var/log/mysql/ \
-e MYSQL_ROOT_PASSWORD=winner@001 --name=mysql mysql:5.7.19
version: "3"
services:
mysql:
image: mysql:5.7.19
restart: always
container_name: mysql
ports:
- 3306:3306
volumes:
- /data/software/mysql/conf/:/etc/mysql/conf.d
- /data/software/mysql/data:/var/lib/mysql
- /data/software/mysql/log/:/var/log/mysql
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_DATABASE: kangll
MYSQL_USER: kangll
MYSQL_PASSWORD: 123456MySQL 容器启动与关闭
[root@offline-client software]# docker-compose -f docker-compose-mysql.yml down
[root@offline-client software]# docker-compose -f docker-compose-mysql.yml up -ddocker ps 查看MySQL进程
FROM ubuntu:20.04
# 作者信息
LABEL kangll <kangll@winnerinf.com>
# 安装 依赖包
RUN apt-get clean && apt-get -y update \
&& apt-get install -y openssh-server lrzsz vim net-tools openssl gcc openssh-client inetutils-ping \
&& sed -ri 's/^#?PermitRootLogin\s+.*/PermitRootLogin yes/' /etc/ssh/sshd_config \
&& sed -ri 's/UsePAM yes/#UsePAM yes/g' /etc/ssh/sshd_config \
&& ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
# 修改 root 密码
&& useradd winner \
&& echo "root:kangll" | chpasswd \
&& echo "winner:kangll" | chpasswd \
&& echo "root ALL=(ALL) ALL" >> /etc/sudoers \
&& echo "winner ALL=(ALL) ALL" >> /etc/sudoers
# 生成密钥
#&& ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key \
#&& ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
# 执行后台启动 ssh 服务命令
CMD ["/usr/sbin/sshd", "-D"]FROM ubuntu20-ssh-base:v1.0 # 系统镜像
LABEL kangll <kangll@winnerinf.com>
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys && \
sed -i 's/PermitEmptyPasswords yes/PermitEmptyPasswords no /' /etc/ssh/sshd_config && \
sed -i 's/PermitRootLogin without-password/PermitRootLogin yes /' /etc/ssh/sshd_config && \
echo " StrictHostKeyChecking no" >> /etc/ssh/ssh_config && \
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config
# JDK
ADD jdk-8u162-linux-x64.tar.gz /hadoop/software/
ENV JAVA_HOME=/hadoop/software/jdk1.8.0_162
ENV CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH=$JAVA_HOME/bin:$PATH
# hadoop
ADD hadoop-2.6.0-cdh5.15.0.tar.gz /hadoop/software/
ENV HADOOP_HOME=/hadoop/software/hadoop
ENV HADOOP_CONF_DIR=/hadoop/software/hadoop/etc/hadoop
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# spark
ADD spark-1.6.0-cdh5.15.0.tar.gz /hadoop/software/
ENV SPARK_HOME=/hadoop/software/spark
ENV PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# hbase
ADD hbase-1.2.0-cdh5.15.0.tar.gz /hadoop/software/
ENV HBASE_HOME=/hadoop/software/hbase
ENV PATH=$PATH:$HBASE_HOME/bin
# hive
ADD hive-1.1.0-cdh5.15.0.tar.gz /hadoop/software/
ENV HIVE_HOME=/hadoop/software/hive
ENV HIVE_CONF_DIR=/hadoop/software/hive/conf
ENV PATH=$HIVE_HOME/bin:$PATH
# scala
ADD scala-2.10.5.tar.gz /hadoop/software/
ENV SCALA_HOME=/hadoop/software/scala
ENV PATH=$PATH:$SCALA_HOME/bin
ADD azkaban.3.30.1.tar.gz /hadoop/software/
WORKDIR /hadoop/software/
RUN ln -s jdk1.8.0_162 jdk \
&& ln -s spark-1.6.0-cdh5.15.0 spark \
&& ln -s scala-2.10.5 scala \
&& ln -s hadoop-2.6.0-cdh5.15.0 hadoop \
&& ln -s hbase-1.2.0-cdh5.15.0 hbase \
&& ln -s hive-1.1.0-cdh5.15.0 hive
WORKDIR /hadoop/software/hadoop/share/hadoop
RUN ln -s mapreduce2 mapreduce
WORKDIR /hadoop/software/
# 添加winner用户
RUN chown -R winner:winner /hadoop/software/ && \
chmod -R +x /hadoop/software/
## 集群启动脚本
COPY start-cluster.sh /bin/
RUN chmod +x /bin/start-cluster.sh
CMD ["bash","-c","/bin/start-cluster.sh && tail -f /dev/null"]start-cluster脚本, 方便多次启动和在log中查看启动日志
#!/bin/bash
#########################################################################
# #
# 脚本功能: winner-aio-docker, docker-compose安装,环境初始化 #
# 作 者: kangll #
# 创建时间: 2022-02-28 #
# 修改时间: 2022-04-07 #
# 当前版本: 2.0v #
# 调度周期: 初始化任务执行一次 #
# 脚本参数: 无 #
##########################################################################
source /etc/profile
source ~/.bash_profile
set -e
rm -rf /tmp/*
### 判断NameNode初始化文件夹是否存在,决定是否格式化
NNPath=/hadoop/software/hadoop/data/dfs/name/current
if [ -d "$NNPath" ];then
echo "------------------------------------------> NameNode已格式化 <--------------------------------------"
else
echo "------------------------------------------> NameNode开始格式化 <------------------------------------"
/hadoop/software/hadoop/bin/hdfs namenode -format
fi
# NameNode, SecondaryNameNode monitor
namenodeCount=`ps -ef |grep NameNode |grep -v "grep" |wc -l`
if [ $namenodeCount -le 1 ];then
/usr/sbin/sshd
echo "-----------------------------------------> Namenode 启动 <---------------------------------------- "
start-dfs.sh
else
echo "----------------------------> Namenode, SecondaryNameNode 正常 <---------------------------------- "
fi
#DataNode
DataNodeCount=`ps -ef |grep DataNode |grep -v "grep" |wc -l`
if [ $DataNodeCount == 0 ];then
/usr/sbin/sshd
echo "-------------------------------------> DataNode 启动 <-------------------------------------------"
start-dfs.sh
else
echo "-------------------------------------> DataNode 正常 <-------------------------------------------"
fi
#HBase Monitor
hmasterCount=`ps -ef |grep HMaster |grep -v "grep" |wc -l`
if [ $hmasterCount == 0 ];then
/usr/sbin/sshd
echo "-------------------------------------> hmaster 启动 <-------------------------------------------"
start-hbase.sh
else
echo "-------------------------------------> hmaster 正常 <-------------------------------------------"
fi
#HBase RegionServer Monitor
regionCount=`ps -ef |grep HRegionServer |grep -v "grep" |wc -l`
if [ $regionCount == 0 ];then
echo "--------------------------------------> RegionServer 启动 <---------------------------------------"
/usr/sbin/sshd
start-hbase.sh
else
echo "--------------------------------------> RegionServer 正常 <---------------------------------------"
fi
#yarn ResourceManager
ResourceManagerCount=`ps -ef |grep ResourceManager |grep -v "grep" |wc -l`
if [ $ResourceManagerCount == 0 ];then
/usr/sbin/sshd
echo "-------------------------------------> ResourceManager 启动 <------------------------------------"
start-yarn.sh
else
echo "-------------------------------------> ResourceManager 正常 <------------------------------------"
fi
#yarn NodeManager
NodeManagerCount=`ps -ef |grep NodeManager |grep -v "grep" |wc -l`
if [ $NodeManagerCount == 0 ];then
/usr/sbin/sshd
echo "-------------------------------------> NodeManager 启动 <-----------------------------------------"
start-yarn.sh
else
echo "-------------------------------------> NodeManager 正常 <-----------------------------------------"
fi
#hive
runJar=`ps -ef |grep RunJar |grep -v "grep" |wc -l`
if [ $runJar == 0 ];then
/usr/sbin/sshd
echo "-----------------------------------------> hive 启动 <-----------------------------------------"
hive --service metastore &
else
echo "------------------------------------------> hive 正常 <-----------------------------------------"
fiversion: "3" services: cdh: image: hadoop-cluster:v1.0 container_name: hadoop-cluster hostname: hadoop networks: - hadoop-network ports: - 9000:9000 - 8088:8088 - 50070:50070 - 8188:8188 - 8042:8042 - 10000:10000 - 9083:9083 - 8080:8080 - 7077:7077 - 8444:8444 # 数据与日志路径映射到本地数据盘 volumes: - /data/software/hadoop/data:/hadoop/software/hadoop/data - /data/software/hadoop/logs:/hadoop/software/hadoop/logs - /data/software/hadoop/conf:/hadoop/software/hadoop/etc/hadoop - /data/software/hbase/conf:/hadoop/software/hbase/conf - /data/software/hbase/logs:/hadoop/software/hbase/logs - /data/software/hive/conf:/hadoop/software/hive/conf networks: hadoop-network: {}2.6CDH 启动
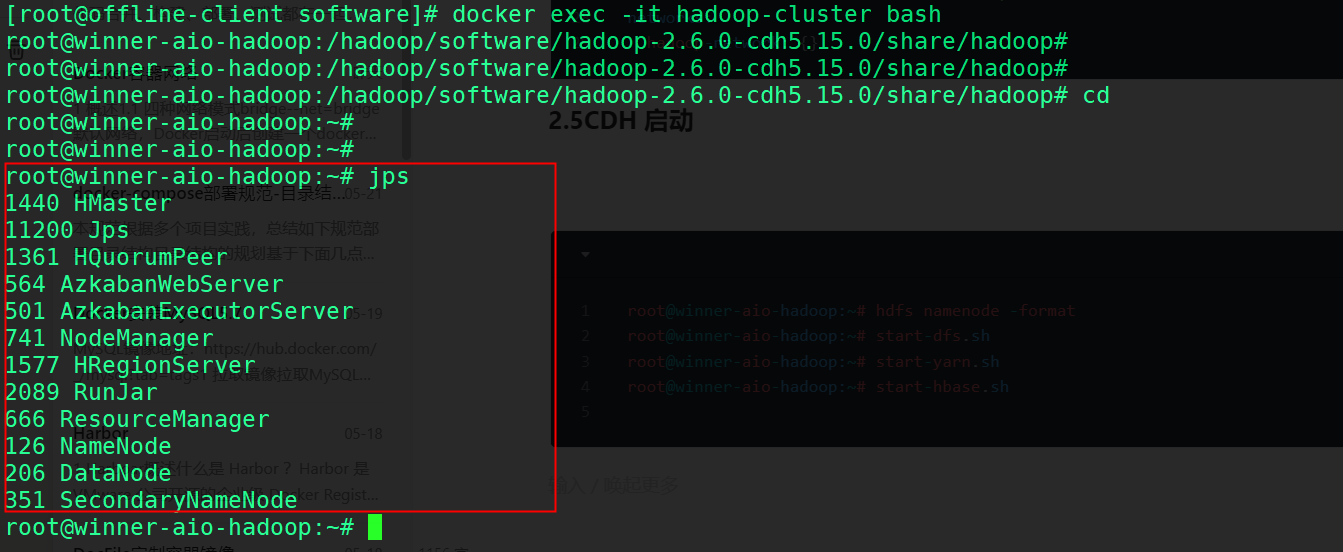
docker-compose -f dockerfile-hadoop-cluster up -d使用JPS查看服务进程
访问hadoop-web
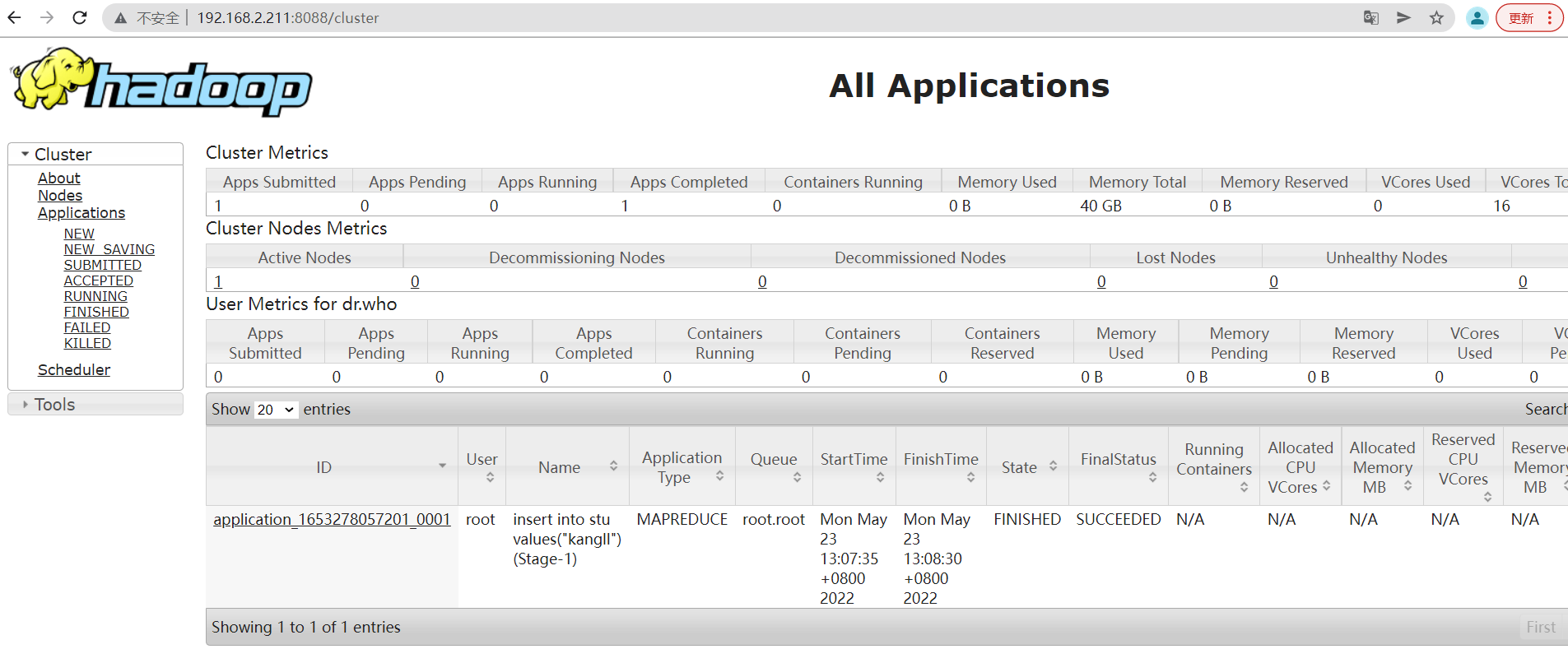
访问yarn-web
------------------------ 感谢点赞!-------------------------------------
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po