最近在看一些大数据的东西,发现对其中的shuffle过程很模糊,于是决定学习一下,深入之后又发现对整个mapreduce的数据完成处理过程也同样模糊。
所以本文将从以下几个角度来展开:
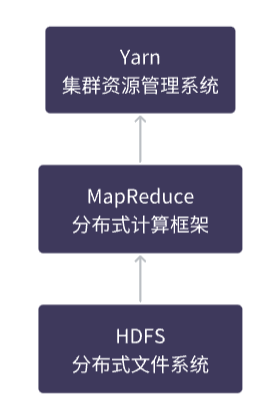
Hadoop是一个由Apache开发的大数据处理框架,它包括了HDFS(Hadoop分布式文件系统)、YARN(Yet Another Resource Negotiator,资源管理器)以及MapReduce计算框架。
HDFS是Hadoop的存储组件,YARN则是用于资源管理和调度的组件,而MapReduce是Hadoop用于分布式计算的框架。
在Hadoop中,数据通常存储在HDFS中,通过MapReduce框架进行分布式计算,YARN负责管理计算资源,并协调MapReduce等计算框架的运行。
MapReduce、Hadoop、HDFS和YARN之间是相互依存、协同工作的关系,它们共同构成了一个完整的大数据处理系统。
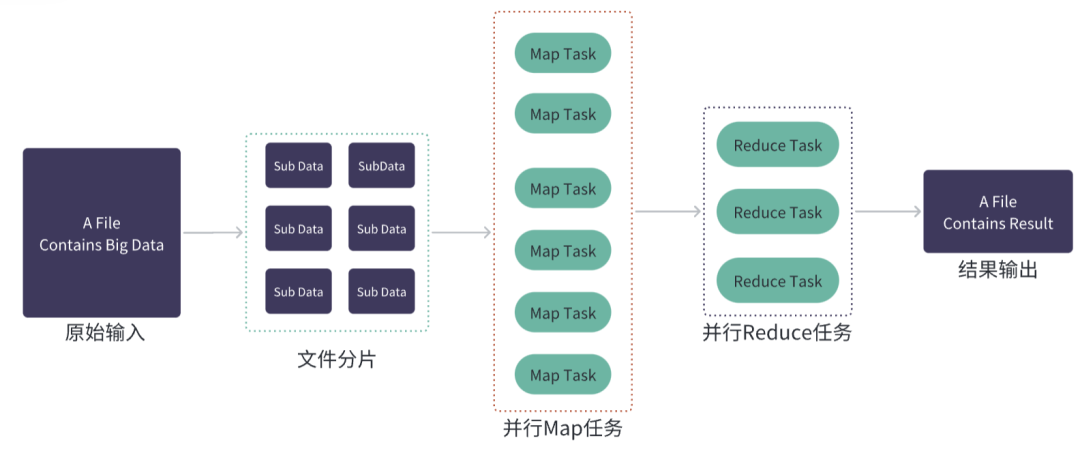
MapReduce的主要思想是将大规模数据处理任务分解成多个小任务,并在分布式计算集群上并行执行,从而实现高效的数据处理和分析。
MapReduce数据处理任务分为两个主要阶段:Map阶段和Reduce阶段。
在Map阶段中,MapReduce将输入数据分割成若干个小块,然后在分布式计算集群上同时执行多个Map任务,每个任务都对一个小块的数据进行处理,并将处理结果输出为一系列键值对,Map任务的输出结果会被临时存储在本地磁盘或内存中,以供Reduce任务使用。
在Reduce阶段中,它主要负责对Map任务的输出结果进行整合和汇总,生成最终的输出结果。Reduce任务会将所有Map任务输出的键值对按照键进行排序,并将相同键的值合并在一起,Reduce任务的输出结果通常会写入到文件系统中
在传统的分布式计算中,数据通常需要从存储介质中读取到计算节点进行处理,这会造成大量的数据传输和网络延迟,导致计算效率较低。
"计算向数据靠拢"是MapReduce的一个设计思想,旨在最大化利用数据本地性(data locality)来提高作业的性能。
在MapReduce中,数据通常分布在集群的不同节点上,而处理数据的任务(Map任务和Reduce任务)尽量在数据所在的节点上执行,减少数据的网络传输和节点间的通信开销,提高作业的性能。
我们尝试从头来推演整个MapReduce任务的大致执行过程:
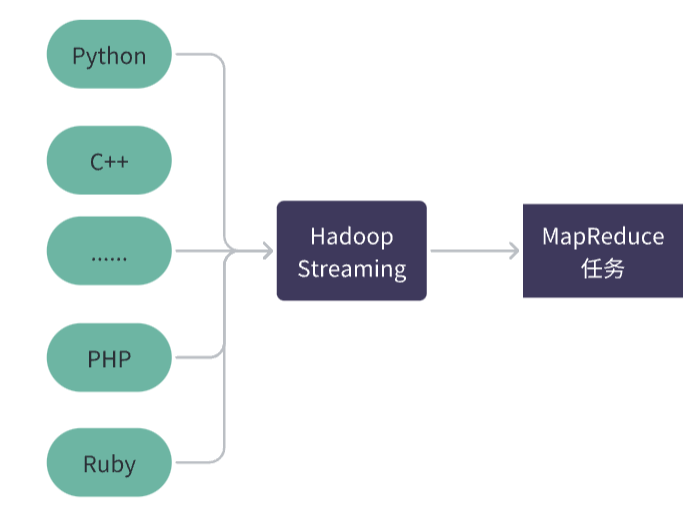
如果使用非 Java 编程语言来实现 MapReduce 任务,或者希望更灵活地定制 Map 和 Reduce 函数的实现方式,可以考虑使用 Hadoop Streaming。
Hadoop Streaming 是 Hadoop 提供的一个工具,可以让用户通过标准输入和标准输出来实现自定义 Map 和 Reduce 函数的功能。使用 Hadoop Streaming 可以使用任何语言来实现 Map 和 Reduce 函数,而不仅仅局限于 Java。
当使用 Hadoop Streaming 时,客户端会将 Map 和 Reduce 函数打包成可执行文件,然后提交给 Hadoop 集群来执行。这些可执行文件可以用任何编程语言编写,例如 Python、Perl、Ruby、C++ 等。
在提交任务之前,客户端需要将任务的输入数据和输出路径等信息设置好,以便Hadoop集群能够正确地执行任务并将结果输出到指定的路径。
MapReduce的客户端JobClient通常会将任务打包成JAR包,然后将该JAR包提交给Hadoop集群来执行任务。
JAR包中包含了MapReduce任务所需的输入数据、输出路径、 Map 和 Reduce 的数量,以及每个任务需要的内存和 CPU 资源等参数,这样可以保证任务在集群中的任何节点上都能够正常运行。
在Hadoop 1.x版本中,JobTracker和TaskTracker是Hadoop集群中的两个重要组件,其中JobTracker负责整个集群中所有MapReduce任务的协调和管理,而TaskTracker负责具体的任务执行。
在Hadoop 2.x版本中引入了YARN框架,将JobTracker的功能拆分成两部分,一部分是ResourceManager,负责集群资源的管理和分配,另一部分是ApplicationMaster,负责具体任务的管理和协调。
在Hadoop 2.x版本及以后的版本中,ApplicationMaster扮演的角色类似于JobTracker。
在 Hadoop YARN 中,ApplicationMaster是一个关键的组件,它负责在集群中管理和监控一个特定的应用程序。
在 MapReduce 中,每个 MapReduce 作业都有一个对应的 ApplicationMaster 实例,该实例负责协调整个作业的执行过程,包括分配任务、监控任务的进度和状态、处理任务失败等。
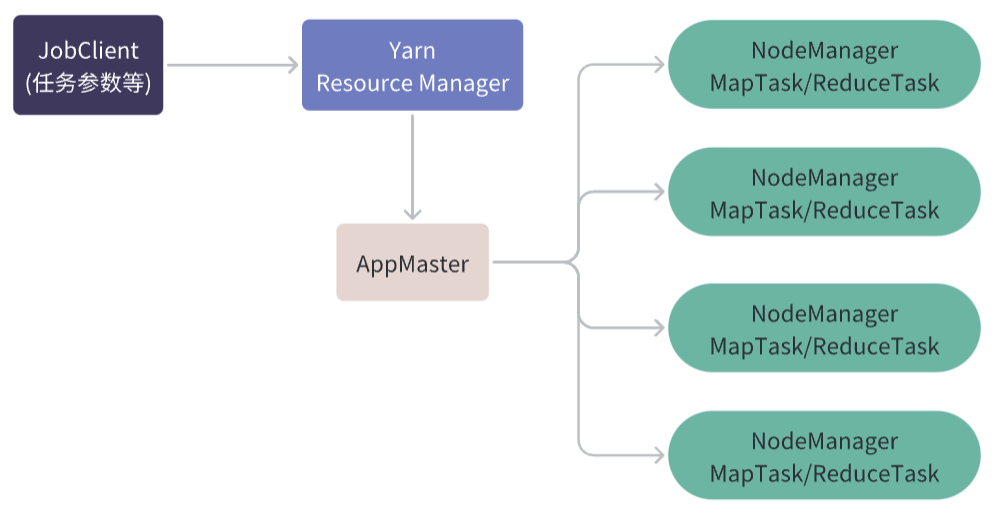
当客户端提交 MapReduce 作业时,YARN 资源管理器会为该作业启动一个 ApplicationMaster 实例。
ApplicationMaster 将向资源管理器请求分配资源,并与各个 NodeManager 协商任务的执行。它还负责将 MapReduce 作业的逻辑划分为多个 Map 和 Reduce 任务,并将任务分配给相应的 NodeManager 执行。
在任务执行期间,ApplicationMaster 将持续监控任务的进度和状态,并在任务出现错误或失败时进行相应的处理。
AppMaster和NodeManager不同,它们是YARN框架中的两个不同的组件,分别扮演着不同的角色。
AppMaster是一个应用程序级别的组件,它运行在分布式集群中的一个节点上,负责协调和管理应用程序的生命周期。它向ResourceManager请求资源,然后将这些资源分配给它的任务(如Map和Reduce任务)。在任务运行期间,AppMaster监视任务的进度并与ResourceManager通信,以确保应用程序在分布式集群上有效地运行。
NodeManager是一个节点级别的组件,它运行在每个节点上,负责管理该节点上的容器和资源。在应用程序启动时,AppMaster向ResourceManager请求节点资源,并指示NodeManager在该节点上启动容器来执行应用程序的任务。
NodeManager负责启动容器并为它们分配资源,同时监视它们的进度,并向ResourceManager报告资源使用情况。
客户端程序中的Job对象会设置输入文件的路径和InputFormat类,在提交作业之前,Job会调用InputFormat的getSplits()方法来获取输入文件的切片信息。
InputFormat 是针对输入文件进行逻辑分割,将一个或多个输入文件划分为一组输入切片InputSplit,以便于 MapReduce 作业的并行处理。
对于大多数常见的数据类型,Hadoop 提供了一些内置的 InputFormat 实现,如下:
输入文件的切片由InputFormat的getSplits()方法生成,这个方法会计算输入文件的切片,并返回一个切片数组。每个切片都包含了一个起始偏移量和一个长度,这些信息告诉了Map任务它需要处理的输入数据的范围,ResourceManager会根据Split对象数组来计算作业需要的资源,并分配相应的资源来运行作业。
当Map任务启动时,它会使用InputFormat提供的InputSplit信息来创建一个RecordReader实例,用于读取该Map任务需要处理的输入数据。
RecordReader从HDFS或其他存储系统中读取数据,将数据划分成适当大小的记录,然后将它们转换为键值对(key-value pairs),再将它们传递给Mapper进行处理。
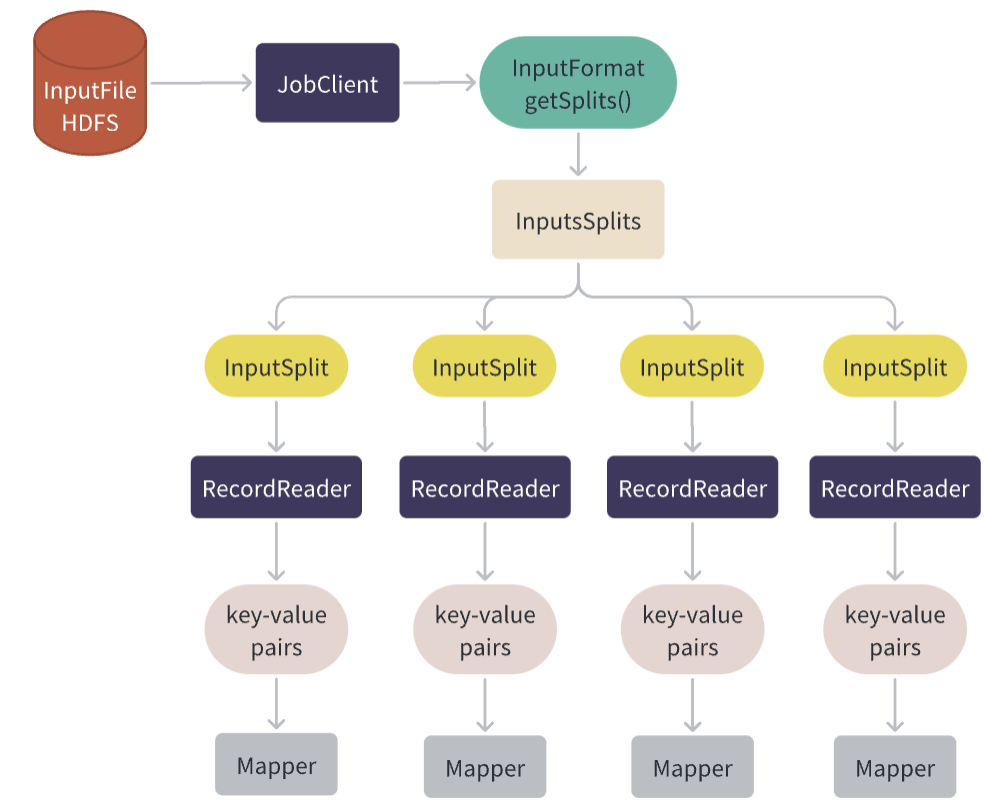
先看一个完整的图,接下来会进行展开:
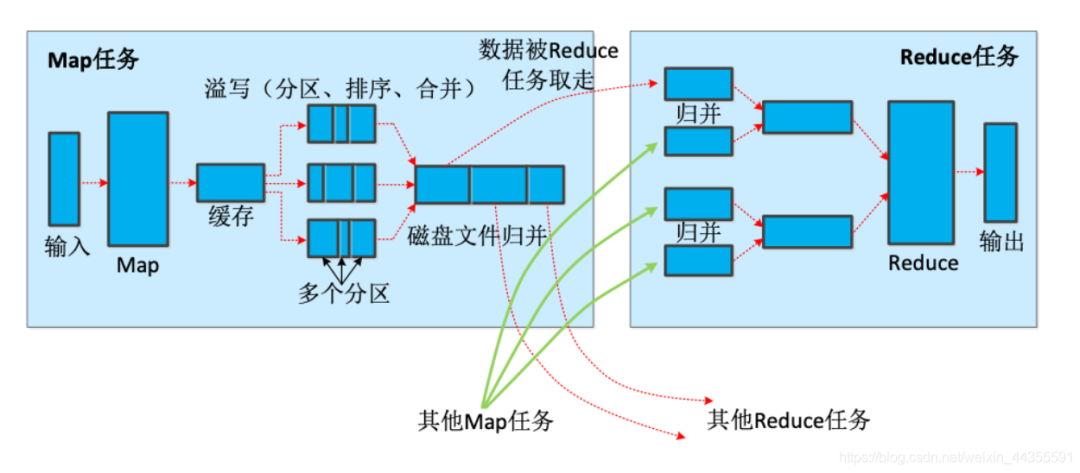
在 MapReduce 中,Map 和 Reduce 任务都是并行执行的,Map 任务负责对输入数据进行处理,将其转换为键值对的形式,而 Reduce 任务负责对 Map 任务的输出结果进行聚合和计算。
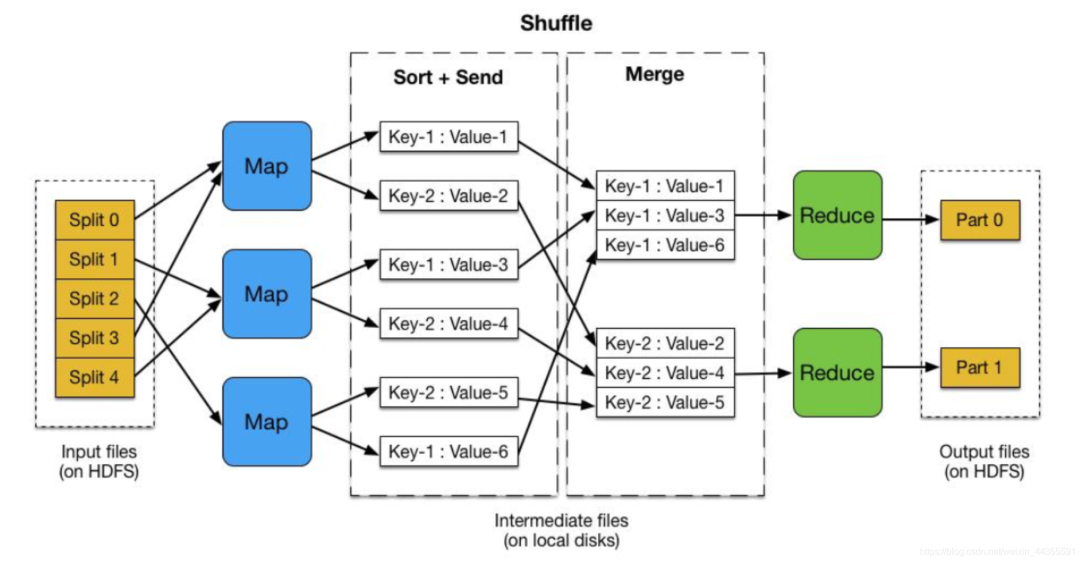
在 MapReduce 中,Shuffle 过程的主要作用是将 Map 任务的输出结果传递给 Reduce 任务,并为 Reduce 任务提供输入数据,它是 MapReduce 中非常重要的一个步骤,可以提高 MapReduce 作业效率。
Shuffle 过程的作用包括以下几点:
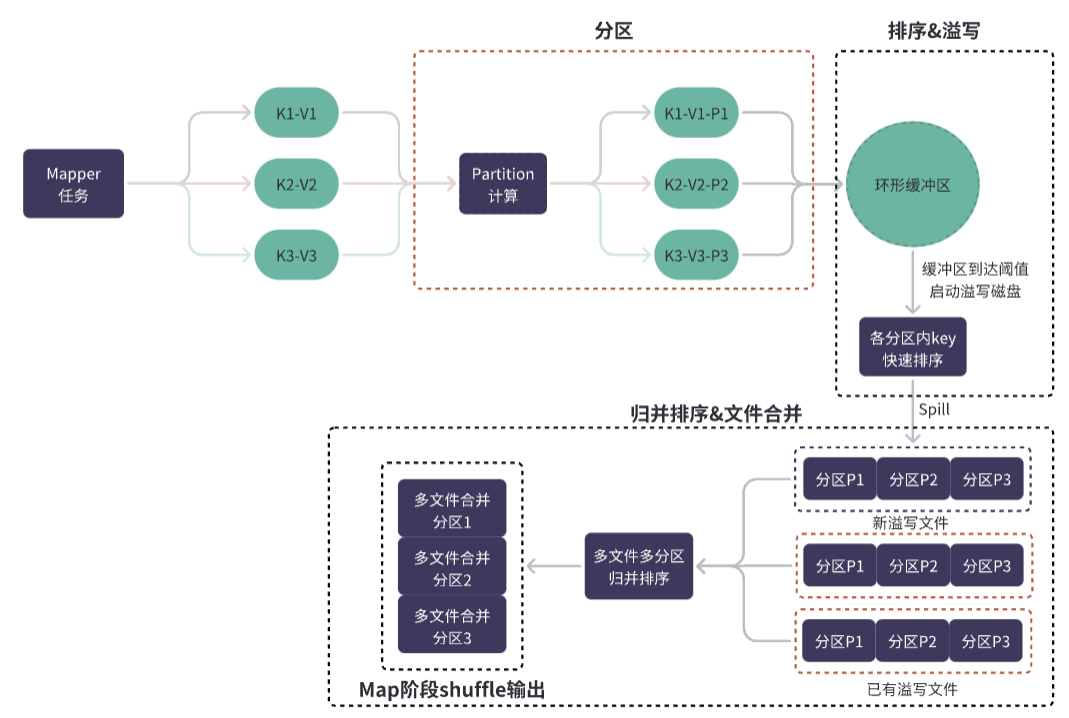
环形缓冲区是一种特殊的缓冲区,它将数据存储在一个固定大小的、循环的缓冲区中,当缓冲区满时,新的数据将覆盖最老的数据,于链表和数组等数据结构,环形缓冲区具有以下优势:
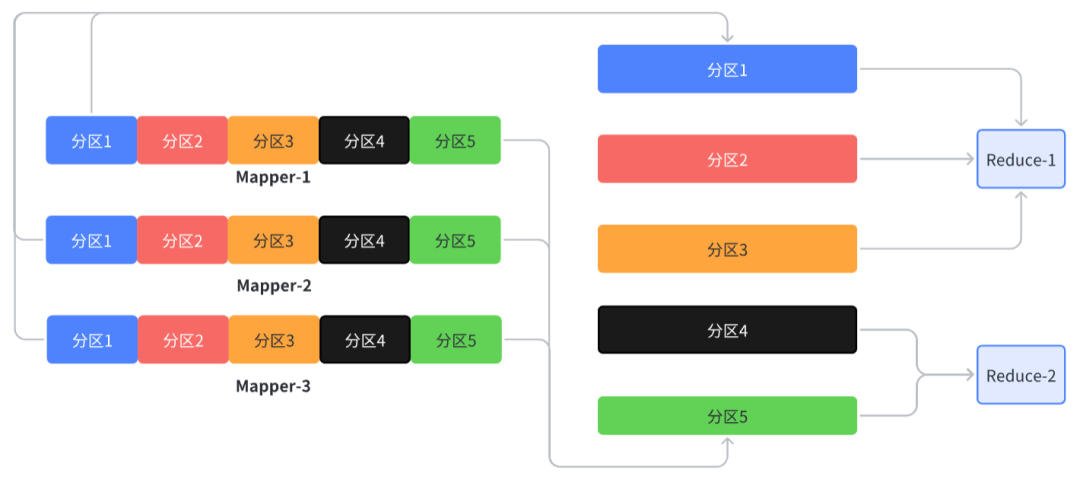
在 Map 阶段中,Map 任务会将输出数据写入环形缓冲区,而这些数据会被分为多个分区,并且每个分区内的数据是按照键(Key)进行排序的。
分区的划分是由 Partitioner 类完成的,默认情况下,Partitioner 类会根据键值对的键(Key)来计算分区编号(Partition ID),从而将数据分配到对应的分区中。
不同的键(Key)可能会被分到同一个分区中,而相同的键(Key)则一定会被分到同一个分区中,这是为了保证相同键(Key)的数据能够被发送到同一个 Reduce 任务中进行处理。
Map 任务向环形缓冲区中写入数据时,先将数据插入到分区内,然后对该分区内的所有数据进行快速排序。
当环形缓冲区中的数据量达到一定阈值(MapReduce 1.x 中默认为环形缓冲区大小的 0.8 倍),或者某个分区内存放的数据大小达到一定阈值(MapReduce 1.x 中默认为 100MB),就会触发溢写操作,将数据按照分区写到磁盘上的临时文件中。
很多时候明确问题比知道答案更重要,多想为什么、多在脑海里去推演过程、最终才能自洽吸收外界知识,化为自己的经验。
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
文章目录实验二:HDFS+MapReduce数据处理与存储实验1.实验目的2.实验环境3.实验内容3.1HDFS部分3.1.1上传文件3.1.2下载文件3.1.3显示文件信息3.1.4显示目录信息3.1.5删除文件3.1.6移动文件3.2MapReduce部分3.2.0Mapreduce原理3.2.1合并和去重3.2.1.1编写Merge.java代码3.2.1.2编译执行3.2.2文件的排序3.2.2.1编写Sort.java代码3.2.2.2编译执行4.踩坑记录5.心得体会6.源码附录6.1Merge.java完整代码6.2Sort.java完整代码实验二:HDFS+MapReduce数据
🖥️NodeJS专栏:Node.js从入门到精通🖥️博主的前端之路(源创征文一等奖作品):前端之行,任重道远(来自大三学长的万字自述)🖥️TypeScript知识总结:TypeScript从入门到精通(十万字超详细知识点总结)🧑💼个人简介:大三学生,一个不甘平庸的平凡人🍬👉你的一键三连是我更新的最大动力❤️!文章目录1、浅拷贝要求思路代码2、简易深拷贝要求思路代码3、完整深拷贝要求思路代码1、浅拷贝要求补全JavaScript代码,要求实现一个对象参数的浅拷贝并返回拷贝之后的新对象。注意:参数可能包含函数、正则、日期、ES6新对象是对对象的参数进行浅拷贝,并不是直接对整个对象进行浅拷贝(整个
图片png无损压缩,尺寸体积要比jpg的大,适合做小图标jpg采用压缩算法,有一点失真,比png体积要小,适合做中大图片gif一般是做动图的webp同时支持有损或者无损压缩,相同质量的图片,webp具有更小的体积css的盒子模型标准盒子模型margin/border/padding/contentie盒子模型margin/content(border+padding+content)盒子模型转换box-sizing/content-box标准/border-boxie模型行高line-height每一行文字的高度,如果文字有多行,则高度为行数*高度height是一个死值,就是这个盒子的高度cs
我正在结合riak/riak-js开发nodejs应用程序并遇到以下问题:运行这个请求db.mapreduce.add('logs').run();正确返回存储在存储桶日志中的所有155.000个项目及其ID:['logs','1GXtBX2LvXpcPeeR89IuipRUFmB'],['logs','63vL86NZ96JptsHifW8JDgRjiCv'],['logs','NfseTamulBjwVOenbeWoMSNRZnr'],['logs','VzNouzHc7B7bSzvNeI1xoQ5ih8J'],['logs','UBM1IDcbZkMW4iRWdvo4W7zp6d
MapReduce序列化之统计各部门员工薪资总和文章目录MapReduce序列化之统计各部门员工薪资总和1.1实验目的1.2实验环境1.3需求描述1.4实验步骤1.4.1采用IDEA创建一个Maven工程1.4.2自己动手开发Java程序1.4.3使用maven生命周期package打jar包1.4.4通过xftp将jar包上传到linux系统1.4.5在hadoop环境运行jar包1.4.6查看输出结果1.5实验中遇到的问题总结1.5.1问题描述1.5.2问题分析1.5.3解决方法1.1实验目的通过MapReduce的序列化方法统计各个部门员工薪水总和。1.2实验环境搭建IDEA+Maven
我正在实现几个Hopscotch在我的应用程序中游览。到目前为止,我已经成功地完成了许多巡回演出,但今天,我面临着一个我无法解决的挑战。我的问题是:如何获得一个游览步骤目标来处理动态生成的内容?这是HTML:TodososDestinos每当我单击链接时,它都会动态创建一个包含许多元素的div;其中之一是带有名为.quarto-config-wrapper的类的div。如果我尝试让我的Hopscotch之旅转到这个元素,那是行不通的;我猜动态创建的元素在DOM中不可用于操作。这是我的跳房子步骤代码:{title:"Adicionarumnovoquarto",content:"cont
我是Go语言的新手,在这里学习:https://tour.golang.org/concurrency/1当我运行https://play.golang.org/p/9JvbtSuv5o结果是:worldhellohello所以添加了sync.WaitGroup:https://play.golang.org/p/vjdhnDssGkpackagemainimport("fmt""sync""time")varwsync.WaitGroupfuncsay(sstring){fori:=0;i但结果是一样的:worldhellohello我的代码有什么问题?请帮忙,感谢您的帮助。
当一个从未接触过多线程程序的PHP开发人员开始学习golang和channel时,可能会发生这种情况。我正在进行围棋之旅的最后一个练习,[Exercise:WebCrawler](在此之前,我对其他练习没有任何问题)虽然我正在尝试编写尽可能简单的代码,我的Crawl方法如下所示:funcCrawl(urlstring,depthint,fetcherFetcher){//kickoffcrawlingbypassinginitialUrltoaJobqueueQueuegorun说我不应该写任何go代码然后返回PHP:fatalerror:allgoroutinesareasleep-
import"github.com/globalsign/mgo"job:=&mgo.MapReduce{Map:"function(){emit(this.name,1)}",Reduce:"function(key,values){returnArray.sum(values)}",Out:"res",}_,err=c.Find(nil).MapReduce(job,nil)如何在上面的golangmgomapreduce中添加'query'?引用:https://docs.mongodb.com/manual/core/map-reduce/https://godoc.org/g