✨个人主页: 夜 默
🎉所属专栏: C++修行之路
🎊每篇一句: 图片来源
- The power of imagination makes us infinite.
- 想象力的力量使我们无限。
文章目录
vector 是 STL 中的容器之一,其使用方法类似于数据结构中的 顺序表,得益于范型编程和 C++ 特性的加持,vector 更强大、更全能;在模拟实现 vector 时,还需要注意许多细枝末节,否则就很容易造成重复析构及越界访问

出自书籍《STL源码剖析》 侯捷著
本文重点: 深度拷贝、迭代器失效
vector 的结构比较特殊,成员变量为三个指针
#pragma once
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
#include <string>
using std::string;
namespace Yohifo
{
template<class T>
class vector
{
public:
typedef T value_type;
typedef value_type* pointer; //指针
typedef const value_type* const_pointer;
typedef value_type* iterator; //迭代器
typedef const value_type* const_iterator;
typedef value_type& reference; //引用
typedef const value_type& const_reference;
private:
iterator _start; //指向起始位置
iterator _finish; //指向有效元素的下一个位置
iterator _end_of_storage; //指向可用空间的下一个位置
};
}

默认成员函数需要自己设计,因为涉及深浅拷贝问题
默认构造函数、带参构造函数、迭代器区间构造
//默认构造
vector() :_start(nullptr), _finish(nullptr), _end_of_storage(nullptr) {}
//带参构造
vector(size_t n, const T& value = T())
:vector()
{
reserve(n); //扩容
while (n--) push_back(value); //逐个尾插
}
//额外版本,避免匹配上迭代器区间构造
vector(int n, const T& value = T())
:vector()
{
reserve(n); //扩容
while (n--) push_back(value); //逐个尾插
}
//迭代器区间构造
template<class InputIterator>
vector(InputIterator first, InputIterator last)
:vector()
{
//考虑提前计算容量
InputIterator cur = first;
int len = 0;
while (cur != last) ++len, ++cur;
reserve(len);
while (first != last) push_back(*first), ++first;
}
注意: 在设计带参构造函数时,需要再额外提供一个 vector(int n, const T& value = T()) 版本,以防使用 vector<int> v(10, 6) (构造对象,内容为10个6)优先匹配上迭代器构造,此时会造成 非法间接寻址 错误

此时多处用到了 匿名对象 作为缺省值
vector(size_t n, const T& value = T());
vector(int n, const T& value = T());
因为 T 类型不确定,在设置缺省值时,只能使用 匿名对象 的方式
匿名对象 生命周期只有一行,但在被 const 修饰后,其生命周期会延长int()、char() 是合法可用的带参构造、拷贝构造、迭代器区间构造等函数创建新对象前,需要先初始化,有多种初始化方法:
默认构造函数 进行初始化这里采用的是初始化列表调用 默认构造函数 初始化的方式
拷贝构造
//拷贝构造-传统写法
vector(const vector<T>& v)
:vector()
{
reserve(v.capacity()); //扩容
size_t pos = 0;
while (pos < v.size()) *(_start + pos) = *(v.begin() + pos), ++pos;
_finish = begin() + v.size();
}
拷贝构造-现代写法
//vector(const vector<T>& v)
// :vector()
//{
// vector<T> tmp(v.begin(), v.end()); //构造临时对象
// swap(tmp); //直接交换
//}
拷贝构造对象前可以 先进行扩容,避免空间浪费; 采用逐个数据赋值拷贝的方式进行拷贝,因为 T 有可能是自定义类型,逐个赋值可以避免浅拷贝问题
T 为 string 类型,实际调用时是这样的 this[pos] = v[pos](string 对象,调用对应的赋值重载函数)注意: vector 的拷贝构造函数必须自己写,默认生成的是 浅拷贝
现代写法着重交换思想,利用迭代器区间构造出临时对象,再将临时对象 “交换” 给当前对象即可
这种方式有点窃取劳动成果的感觉~
赋值重载
//赋值重载-传统写法
vector<T>& operator=(const vector<T>& v)
{
if (this != &v)
{
reserve(v.capacity()); //扩容
size_t pos = 0;
while (pos < v.size()) *(_start + pos) = *(v.begin() + pos), ++pos;
_finish = begin() + v.size();
}
return *this;
}
赋值重载-现代写法
//vector<T>& operator=(vector<T> tmp)
//{
// swap(tmp);
// return *this;
//}
赋值重载的传统写法与拷贝构造基本一致,赋值重载中不需要新建对象,因为是 “赋值”
注意: 赋值前,可以先判断两个对象是否为同一个,如果是,则不需要进行操作
析构函数
//析构函数
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
_start 指向已开辟空间的首位置,可以直接进行空间释放
注意: 空间申请时,使用的是 new [],因此释放时需要使用 delete []
众多构造函数都离不开空间调整函数 reserve,所以这里提前进行学习,并且 reserve 在实现时会出现一个经典问题:深浅拷贝
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size(); //需要先保存 _start 与 _finish 间的距离
pointer tmp = new value_type[n]; //开辟新空间
if (begin())
{
//memcpy(tmp, begin(), size() * sizeof(T)); //不能直接移动
size_t pos = 0;
while (pos < sz)
{
//调用自定义类型的赋值重载函数,完成深拷贝
*(tmp + pos) = *(begin() + pos); //深拷贝
pos++;
}
}
delete[] begin(); //释放原空间
_start = tmp; //赋值新空间
_finish = _start + sz;
_end_of_storage = _start + n;
}
}
函数执行步骤:
n 是否大于容量,大于才需要进行扩容注意: 在将旧空间中的数据移动至新空间时,不能直接通过 memcpy/memmove 的方式进行数据移动,因为这些库函数都是 浅拷贝,使用后会造成重复析构问题
举例:使用 memcpy 进行数据迁移
对象中已存在字符串 This is a string,现在进行空间调整

旧空间释放后,其 string 对象被释放,与此同时新空间中的 string 对象也将同步失效

程序运行结束时,调用析构函数进行空间释放(此时会调用 string 的析构函数进行字符串释放),因为旧空间与新空间中的成员皆为同一个,所以会出现 空间重复释放问题

改良:调具体对象的赋值重载函数进行深拷贝(赋值),不再使用 memcpy 浅拷贝

实际上,拷贝构造、赋值重载、reserve 都需考虑深度拷贝的问题
一句话总结:对于自定义类型来说,在进行拷贝/赋值等操作时,调用对应的赋值重载函数即可
reserve 扩容时,发生了这些事情:

出自 《STL源码剖析》
vector 中的迭代器就是原生指针,如 begin() == _start、end() == _finish
typedef T value_type;
typedef value_type* iterator; //迭代器
typedef const value_type* const_iterator;
//=====迭代器设计=====
iterator begin() { return _start; }
iterator end() { return _finish; }
const_iterator begin() const { return _start; }
const_iterator end() const { return _finish; }
注意:
const 对象的 const 迭代器利用前面的函数构造对象,在通过迭代器遍历对象,结果如下

直接通过迭代器获取值
//=====容量相关=====
size_t size() const { return end() - begin(); }
size_t capacity() const { return _end_of_storage - begin(); }
bool empty() const { return begin() == end(); }
可以调整容量(reserve),也可以调整大小(resize)
reserve 前面已经介绍过了,这里来看看 resize
void resize(size_t n, const_reference val = value_type())
{
if (n < size())
erase(begin() + n, end());
else
insert(end(), n - size(), val);
}
操作步骤:
n 是否大于大小[begin() + n, end()][end(), n - size(), val]value_type 就是 T,缺省值为默认对象值
下标访问有两种方式:operator[] 和 at
//=====数据访问=====
reference operator[](size_t pos)
{
assert(pos >= 0 && pos < size());
return *(begin() + pos);
}
const_reference operator[](size_t pos) const
{
assert(pos >= 0 && pos < size());
return *(begin() + pos);
}
reference at(size_t pos) { return (*this)[pos]; }
const_reference at(size_t pos) const { return (*this)[pos]; }
at 复用 operator[] 的代码,确保函数的稳定性~
获取首尾数据也可以直接复用 operator[]
reference front() { return (*this)[0]; }
const_reference front() const { return (*this)[0]; }
reference back() { return (*this)[size() - 1]; }
const_reference back() const { return (*this)[size() - 1]; }
测试结果如下:

void push_back(value_type val)
{
if (size() == capacity())
reserve(capacity() == 0 ? 4 : capacity() * 2); //考虑容量为0的情况
*_finish++ = val; //在最后一个位置插入
}
void pop_back()
{
assert(!empty());
--_finish;
}
注意: 尾插时,需要先判断容量是否足够,不够则需要扩容;同时因为容量默认从 0 开始,假若是第一次插入,需将容量扩容为 4
关于尾插,还有一个类似的拼接函数 assign,将某段区间或 n 个 val 值,拼接至对象后面
//=====数据修改=====
template <class InputIterator>
void assign(InputIterator first, InputIterator last)
{
//迭代器区间拼接
InputIterator cur = first;
int len = 0;
while (cur != last) ++len, ++cur;
reserve(len);
while (first != last) push_back(*first), ++first;
}
void assign(int n, const value_type& val)
{
reserve(n); //提前扩容
while (n--) push_back(val);
}
执行结果如下:

任意位置插删更为自由,同时也更加 “危险”
iterator insert(iterator pos, const_reference val)
{
//先记录当前迭代器的位置
size_t sz = pos - begin();
if (size() == capacity())
reserve(capacity() == 0 ? 4 : capacity() * 2); //考虑容量为0的情况
pos = begin() + sz; //更新迭代器
iterator cur = end();
while (cur != pos) *cur = *(cur - 1), --cur;
*cur = val; //插入数据
++_finish; //尾向后移动
return pos; //返回新迭代器位置
}
iterator insert(iterator pos, size_t n, const_reference val)
{
while (n--) pos = insert(pos, val), pos++; //正确写法
return pos;
}
void erase(iterator pos)
{
assert(pos >= begin() && pos < end());
while (pos != end()) *pos = *(pos + 1), ++pos;
--_finish;
}
void erase(iterator first, iterator last)
{
//迭代器区间删除
//两个结束条件:last == _finish
while (last != _finish) *first = *(last + 1), ++first, ++last;
_finish = first;
}
注意: insert 后迭代器 pos,需要及时更新
若产生扩容行为,迭代器 pos 将指向失效空间,这就是迭代器失效情况之一

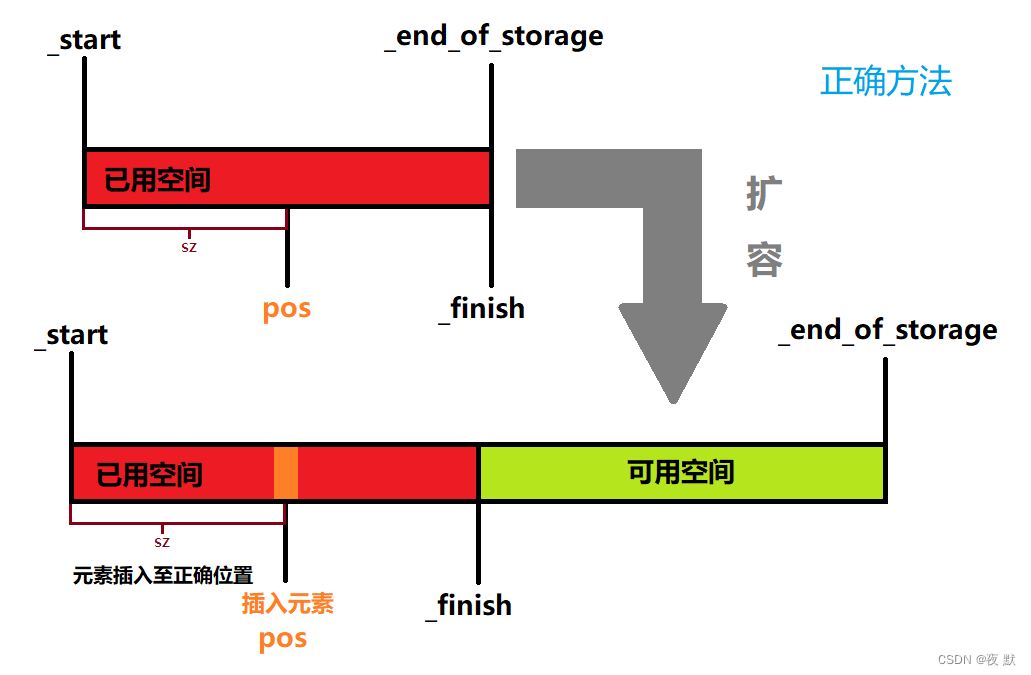
迭代器失效时的具体表现:
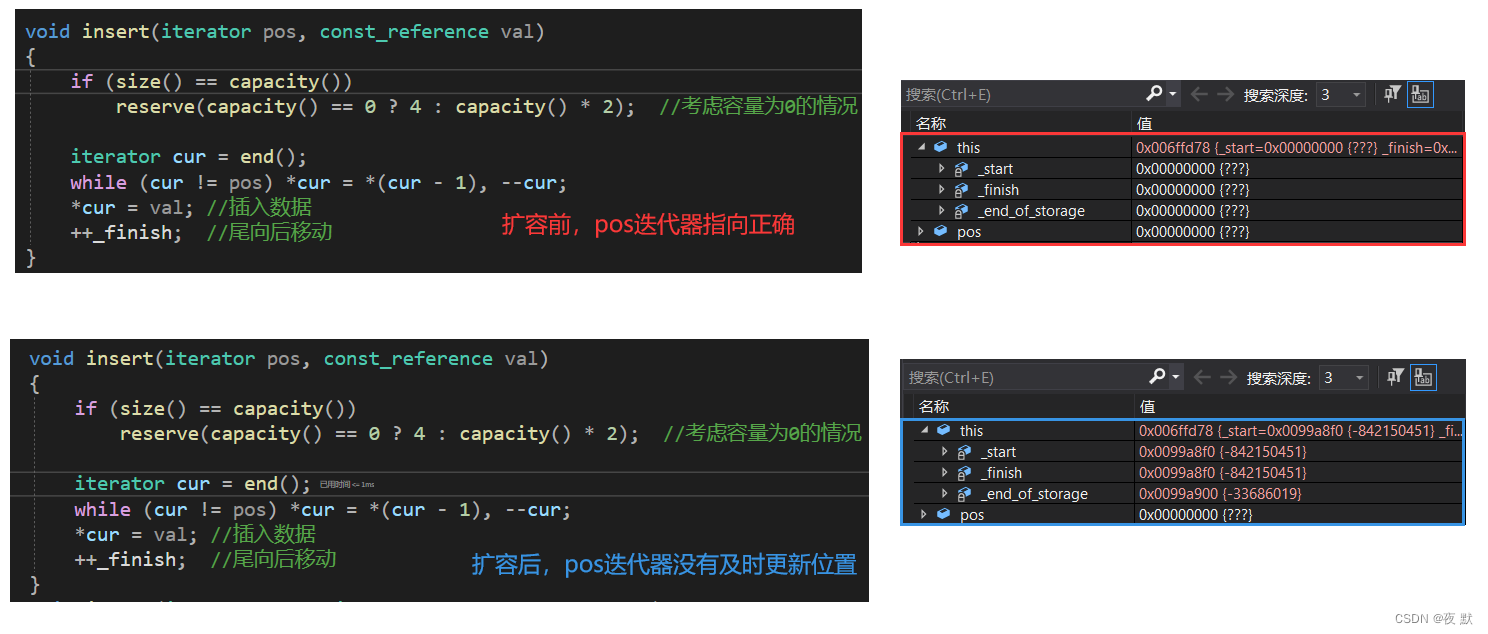
这只是迭代器失效的其中一种情况:没有更新迭代器位置
下面再来看一个迭代器失效场景
比如下标这段代码会运行失败
void TestVector3()
{
vector<int> v;
auto it = v.begin();
int val = 0;
while (val < 100)
v.insert(it++, val++);
for (auto e : v)
cout << e << " ";
}
结果:

原因:
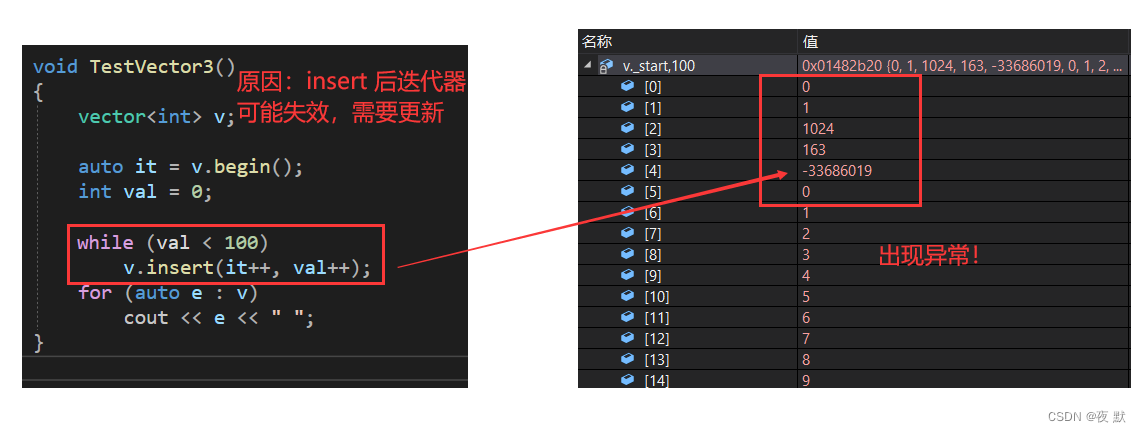
我们通常认为,在 insert 后,迭代器失效,不能再使用,当然将此迭代器更新,也能正常使用
while (val < 100)
{
it = v.insert(it, val++);
it++: //接收 insert 返回值,更新迭代器
}

注意: erase 后,也会出现迭代器失效情况,在 PJ 版本中,对 erase 迭代器失效情况零容忍,只要是删除后没有即使更新迭代器,就会直接报错;而在 SGI 版中,检查相对比较薄弱,即使是删除最后一个元素,它也不报错,这会导致异常行为
对于 erase 迭代器实现情况:
PJ 版:零容忍,检查很严格SGI 版:结果未定义,缺乏检查从实用角度来看,PJ 版的处理方法明显更合理
再补充一些常用函数
void swap(vector<T>& v)
{
//交换三个内置类型,效率要高得多
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
void clear() { erase(begin(), end()); }
即使库中提供了全局性的 std::swap 函数,vector 还是提供了额外的 swap 交换函数,因为 std::swap 中会发生多次拷贝构造,效率较低,而 swap 效率是极高的,只需交换三个成员变量
vector 中使用的是随机迭代器,可以使用库中的排序函数 std::sort
void TestVector8()
{
int arr[] = { 1,9,5,4,3,2,6,7,10,8 };
vector<int> v(arr, arr + sizeof(arr) / sizeof(arr[0]));
//使用库中的排序函数
std::sort(v.begin(), v.end()); //默认为升序(仿函数)
//std::sort(v.begin(), v.end(), std::less<int>()); //其实默认是这样的,为缺省值
for (auto e : v)
cout << e << " ";
cout << endl;
//利用仿函数,进行降序排序
std::sort(v.begin(), v.end(), std::greater<int>());
for (auto e : v)
cout << e << " ";
cout << endl;
}

这里是第一次用到仿函数,后续在进行适配器讲解时,会详细介绍,现在只需知道怎么用就行了
对于 std::sort 来说
std::less<T>()std::greater<T>()注意: 使用仿函数需要头文件 functional,使用 std::sort 需要头文件 algorithm;std::sort 函数只能用于 随机迭代器
本文中涉及的所有代码都在这个仓库中:Gitee

以上就是本篇关于 vector 模拟实现的全部内容了,感兴趣的同学可以自己试着写一下,不过需要特别注意 深度拷贝 和 迭代器失效 问题
如果你觉得本文写的还不错的话,可以留下一个小小的赞👍,你的支持是我分享的最大动力!
如果本文有不足或错误的地方,随时欢迎指出,我会在第一时间改正

相关文章推荐
C++ STL学习之【vector的使用】
===============
STL 之 string 类
C++ STL学习之【string类的模拟实现】
C++ STL 学习之【string】
===============
内存、模板
C++【模板初阶】
C/C++【内存管理】

是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
假设我在Store的模型中有这个非常简单的方法:defgeocode_addressloc=Store.geocode(address)self.lat=loc.latself.lng=loc.lngend如果我想编写一些不受地理编码服务影响的测试脚本,这些脚本可能已关闭、有限制或取决于我的互联网连接,我该如何模拟地理编码服务?如果我可以将地理编码对象传递到该方法中,那将很容易,但我不知道在这种情况下该怎么做。谢谢!特里斯坦 最佳答案 使用内置模拟和stub的rspecs,你可以做这样的事情:setupdo@subject=MyCl
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我有一个gem,它有一个根据Rails.env的不同行为的方法:defself.envifdefined?(Rails)Rails.envelsif...现在我想编写一个规范来测试这个代码路径。目前我是这样做的:Kernel.const_set(:Rails,nil)Rails.should_receive(:env).and_return('production')...没关系,只是感觉很丑。另一种方法是在spec_helper中声明:moduleRails;end而且效果也很好。但也许有更好的方法?理想情况下,这应该有效:rails=double('Rails')rails.sho
