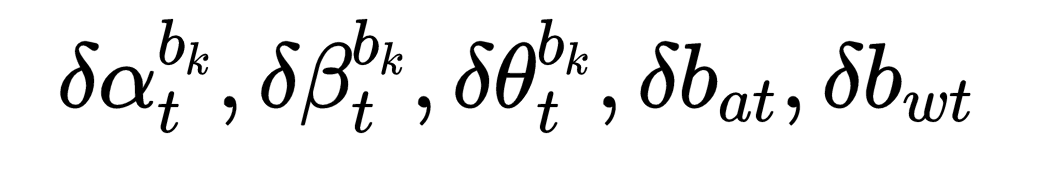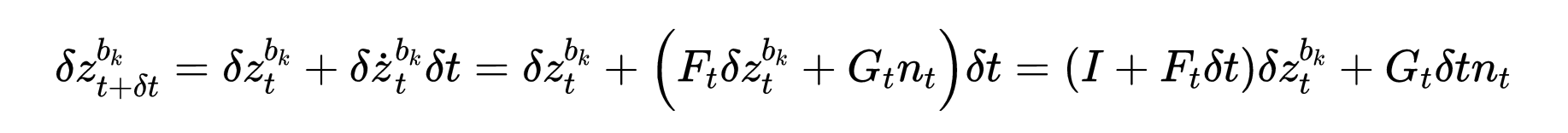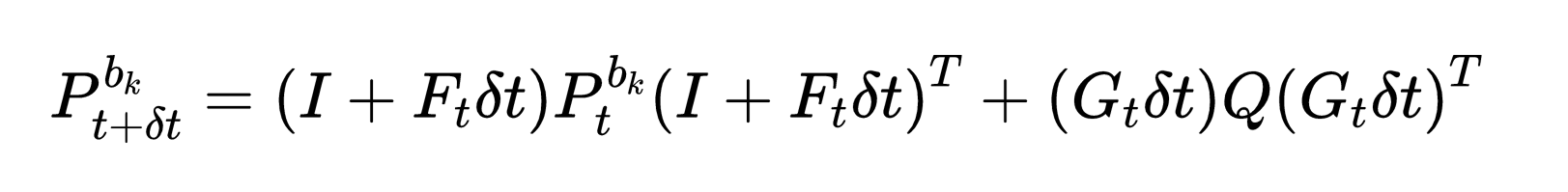1.IMU通过加速度计和陀螺仪测出的是加速度和角速度,通过积分获得两帧之间的旋转和位移的变换;
2.在后端非线性优化的时候,需要优化位姿,每次调整位姿都需要在它们之间重新传递IMU测量值,需要重新积分,这将非常耗时,为了避免重新传递测量值,所以采取预积分策略。
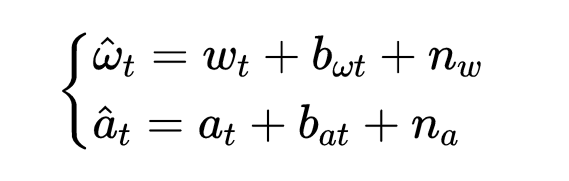
其中:
对图像第
k
k
k 帧和第
k
+
1
k+1
k+1 帧之间的所有IMU进行积分,对应的IMU坐标系为
b
k
b_k
bk 和
b
k
+
1
b_{k+1}
bk+1 ,根据k时刻的数据,积分求得
k
+
1
k+1
k+1 时刻的数据,求出的是在世界坐标系下的值:
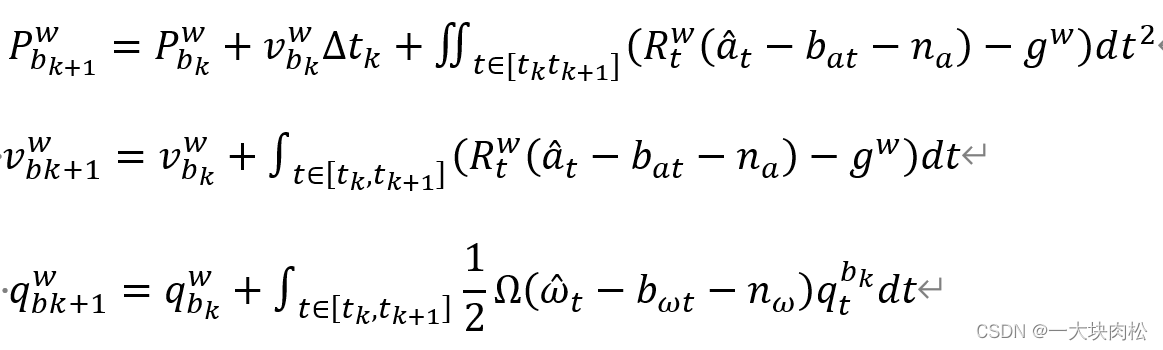
其中:
Δ t k Δt_k Δtk :表示[k,k+1]之间的时间间隔
q t b k q^{bk}_t qtbk:表示在本体(IMU)坐标系下,t 时刻到 b k b_k bk时刻位姿的变换矩阵 。
推导过程中旋转采用四元数表示。
对于上式中,第三个公式的推导过程如下:
首先需要先了解四元数的基本知识:
(1)四元数由实部和虚部构成,可以将实部写在前面,也可以将虚部写在前面,本文将实部写在前面:
q
=
[
q
0
,
q
1
,
q
2
,
q
3
]
=
[
s
,
v
⃗
]
q=[q_0,q_1,q_2,q_3]=[s,\vec{v}]
q=[q0,q1,q2,q3]=[s,v]
即:
q
=
q
0
+
q
1
i
+
q
2
j
+
q
3
k
q=q_0+q_1i+q_2j+q_3k
q=q0+q1i+q2j+q3k (虚部写在前)
(2)四元数与旋转向量
(
n
⃗
,
θ
)
(\vec{n},\theta)
(n,θ)的转换:
q
=
[
c
o
s
θ
2
n
⃗
s
i
n
θ
2
]
q=\begin{bmatrix} cos\frac{\theta}{2}\\ \vec{n}sin\frac{\theta}{2} \\ \end{bmatrix}
q=[cos2θnsin2θ]
当发生一个微小的旋转,即旋转角度趋近于0,则有:
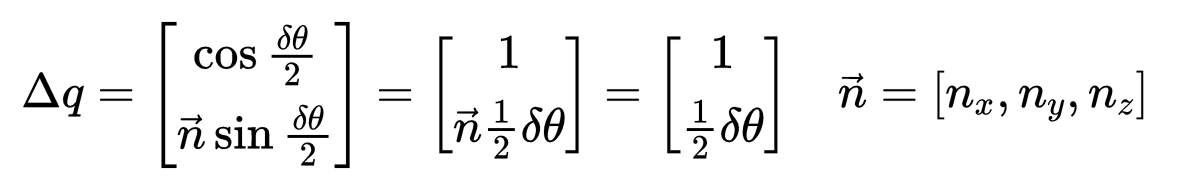 (3)四元数求导:
(3)四元数求导:
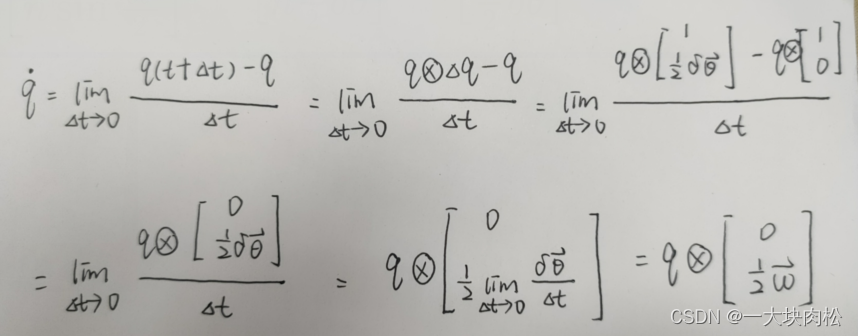
w
w
w:表示的是角速度,上式中对角度进行求导,得到角速度
由以上四元数的基本知识可以得到:第三个公式的推导过程如下::
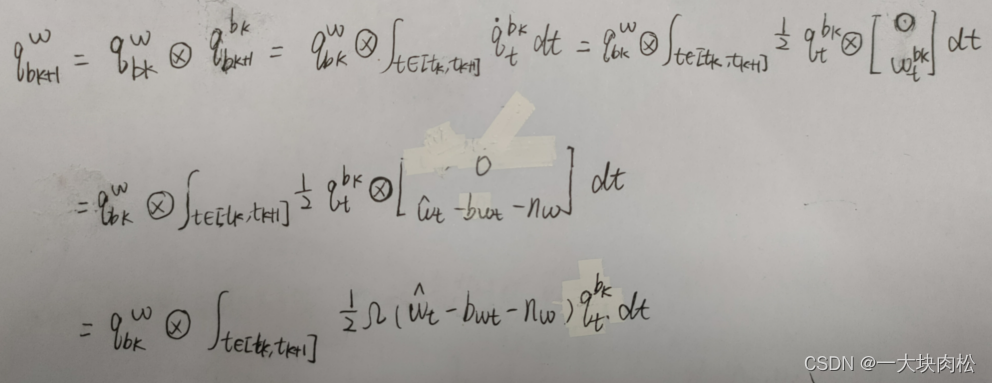
针对上述2.当前时刻的PVQ连续表达形式可知,若要求得当前时刻的旋转、位置、速度,需要前一时刻的状态量,但是当这些状态改变时,我们就需要重新传递IMU的测量值,特别是在基于优化的算法中,每次调整位姿都需要在它们之间重新传递IMU测量值,这种测量策略非常耗时,为了避免重新传递测量值,采用预积分算法。
通俗的解释:根据上一时刻计算出当前时刻的PVQ,当后端对上一时刻的值进行优化时,则需要根据优化好的值,重新计算当前帧的PVQ。
对第
i
i
i个IMU时刻到
i
+
1
i+1
i+1时刻的IMU进行积分
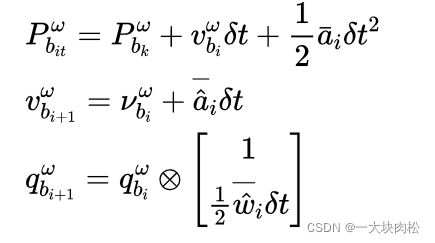
其中:
i i i 表示的是在 [ t k , t k + 1 ] [t_k,t_{k+1}] [tk,tk+1] 中IMU测量值对应的离散时刻;
δ t \delta{t} δt 是IMU测量值 i i i 和 i + 1 i+1 i+1 之间的时间间隔。
由以上四元数的基本知识可以得到:第三个公式的推导过程如下::
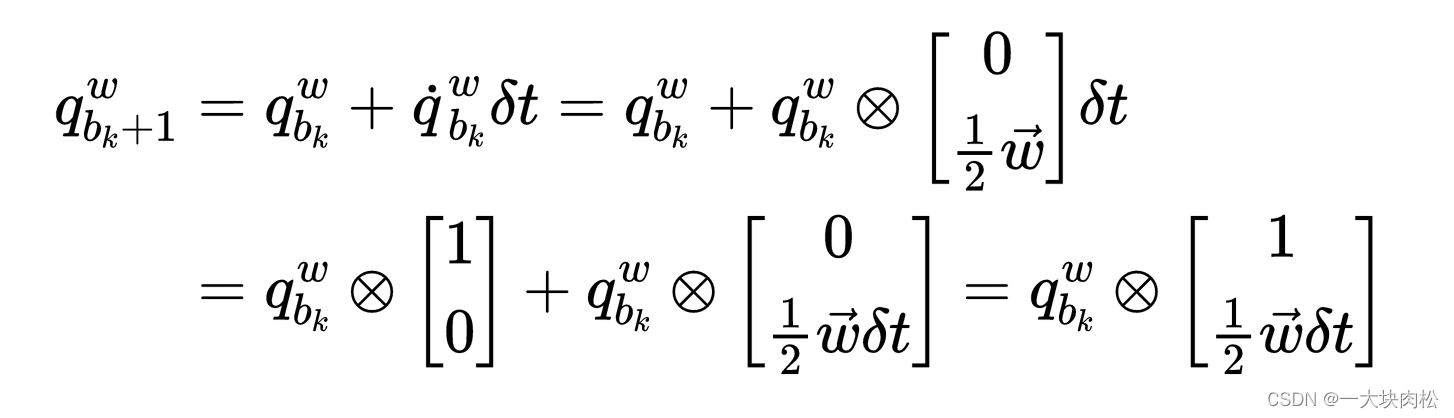
其中
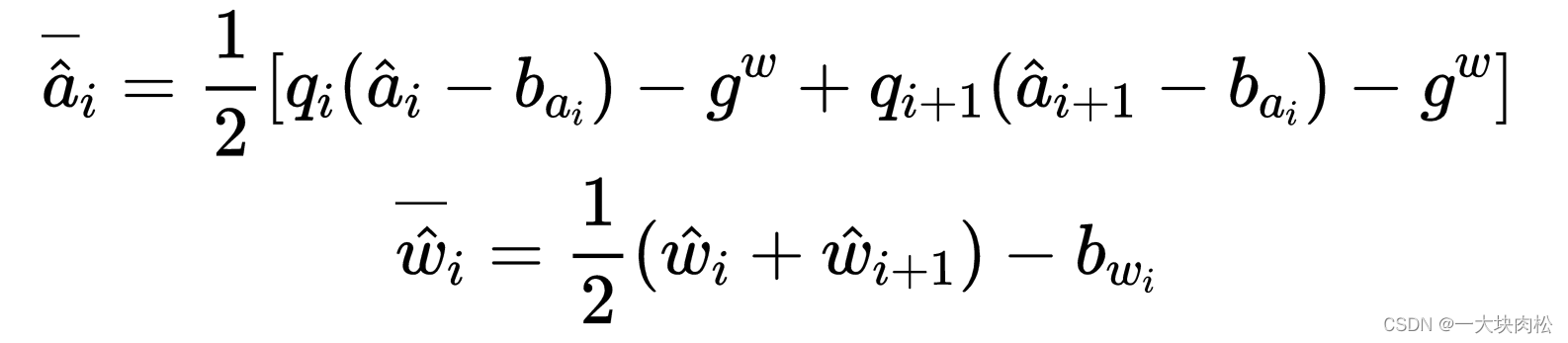
即取中值作为 i i i 时刻的预测值
q i q_i qi:用四元数表示,上式中表示imu坐标系到世界坐标系的变化。
文章开始讲述,预积分的目的,在后端进行非线性优化的时候,需要迭代更新
k
k
k帧的
v
v
v和
R
R
R,这将导致我们需要根据每次迭代后的新值进行积分,这非常耗时,此时就需要将优化变量从第
k
k
k帧到第
k
+
1
k+1
k+1帧的IMU预积分中分离出来,将2中各式左右两侧各乘
R
w
b
k
R^{b_k}_w
Rwbk 得:
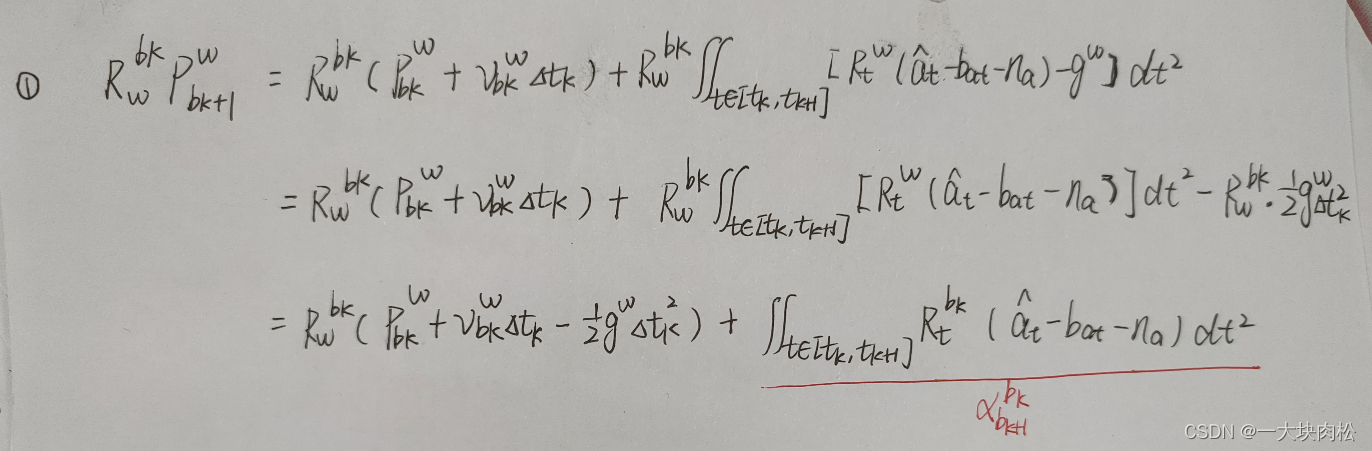
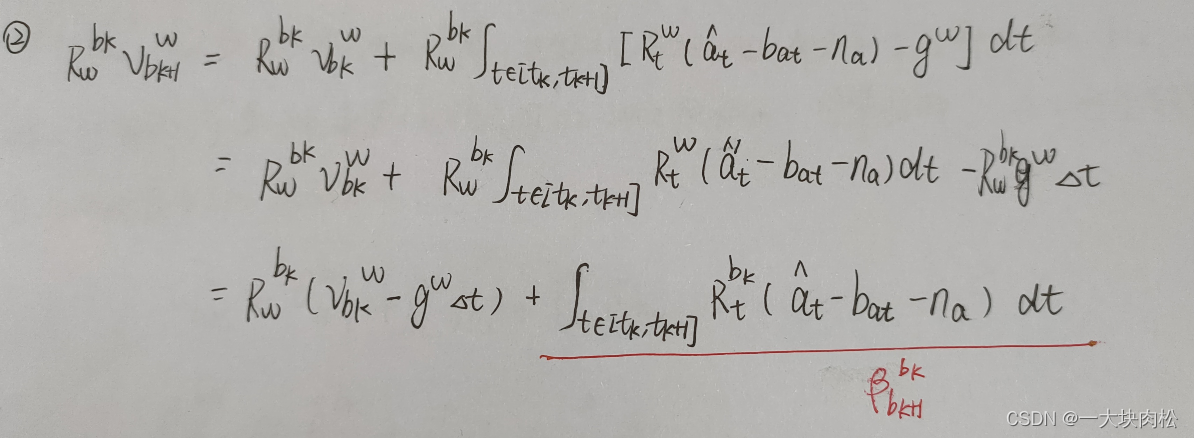
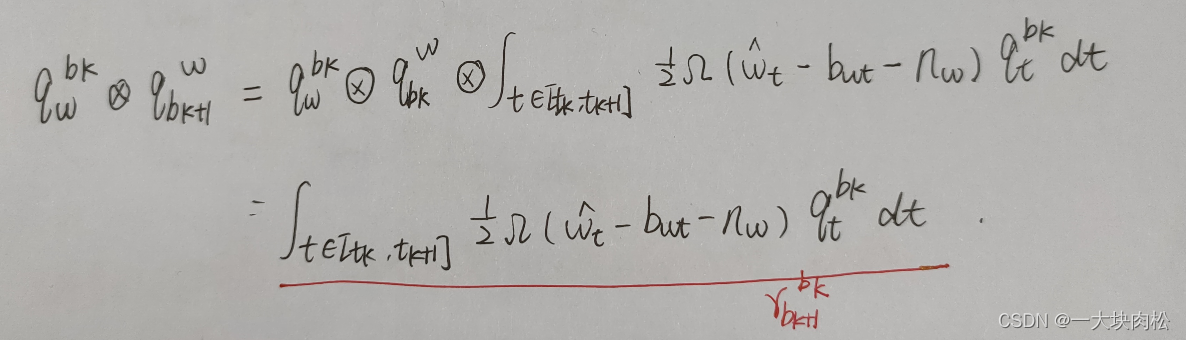
由以上三幅图可知:
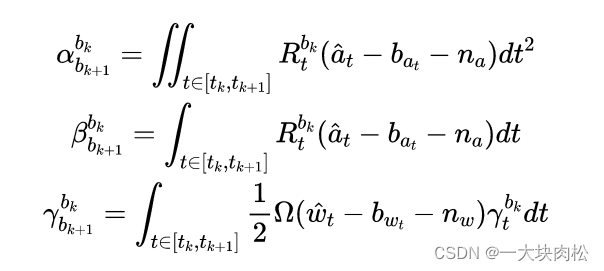
积分结果
α
b
k
+
1
b
k
\alpha^{b_k}_{b_{k+1}}
αbk+1bk、
β
b
k
+
1
b
k
\beta^{b_k}_{b_{k+1}}
βbk+1bk、
γ
b
k
+
1
b
k
\gamma^{b_k}_{b_{k+1}}
γbk+1bk,可以理解为
b
k
+
1
b_{k+1}
bk+1相对于
b
k
b_k
bk的相对运动量;
其中:积分中与IMU的测量值以及偏置有关;
关于状态量中预积分公式中只与IMU的偏置有关,与其他的状态量无关。所以,当偏置估计发生变化时,若偏置的变化很小,则将
α
\alpha
α、
β
\beta
β、
γ
\gamma
γ按其对偏置的一阶近似来调整,否则就进行重新传递,这种策略为基于优化算法节省大量的计算,因为不需要重复传递IMU测量值。
则线性关系表达式为:
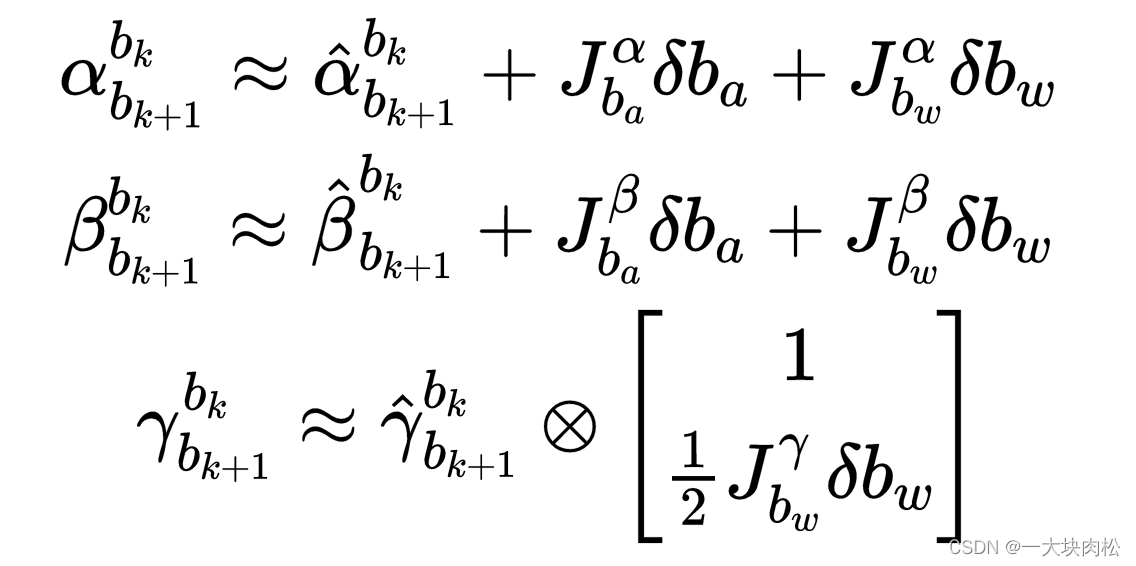
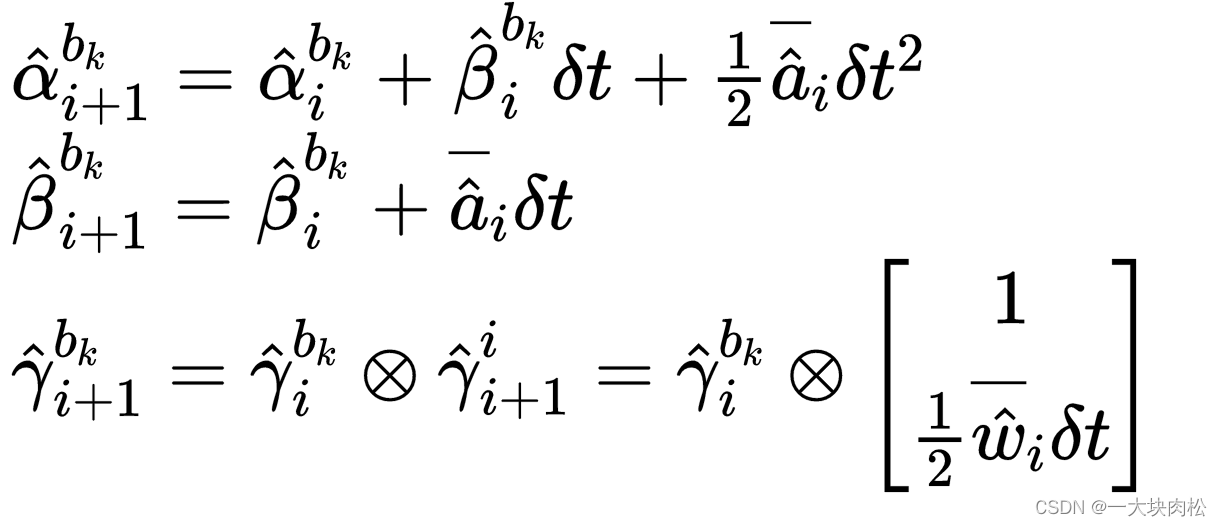
上式是直接根据预积分公式得出:
其中:
i i i:表示的是 [ t k , t k + 1 ] [t_k,t_{k+1}] [tk,tk+1] 中的IMU测量值对应的离散时刻;
δ t \delta t δt 是IMU测量值 i i i 和 i + 1 i+1 i+1 之间的时间间隔
其中:
接下来讨论
的增量的误差。
因为积分出来的值存在误差,所以需要对其进行分析处理。
IMU受到加速度计的偏置
b
a
b_a
ba,陀螺仪偏置
b
w
b_w
bw ,附加噪声
n
a
n_a
na、
n
w
n_w
nw 的影响。
假设附加噪声
n
a
n_a
na、
n
w
n_w
nw 符合高斯噪声
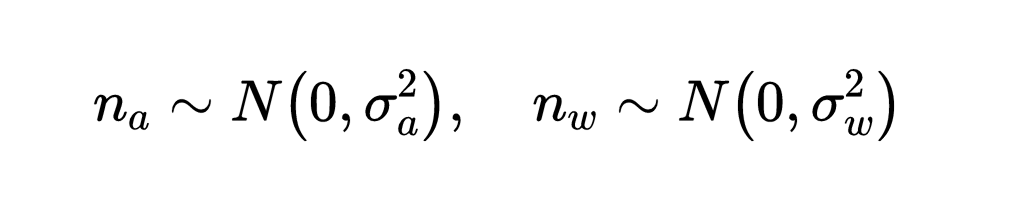
加速度偏置和陀螺仪偏置被建模为随机游走,其导数为高斯性的:
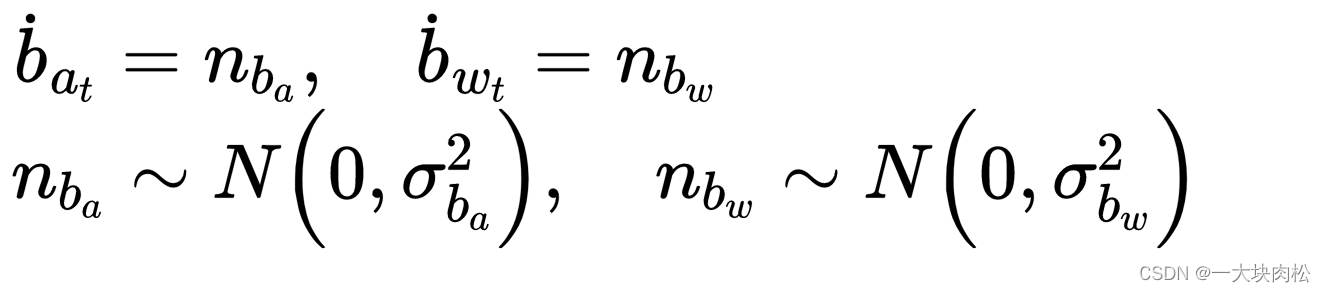
对上述误差项分别进行求导:
接下来是详细的求导过程
以上计算过程求出积分项误差的导数,根据导数的定义可得:
可得
\qquad δ t \delta t δt 的时间间隔,可以看出下一时刻( t + δ t t+\delta t t+δt)的IMU的测量误差与上一时刻( δ t \delta t δt)成线性关系。
\qquad 按此方式,可以根据当前时刻的值,预测出下一时刻的均值和协方差,上式给出了均值预测,同样可以得到协方差预测公式:
其中 P t b k P^{b_k}_t Ptbk表示t时刻的协方差, Q Q Q表示噪声项符合的协方差:
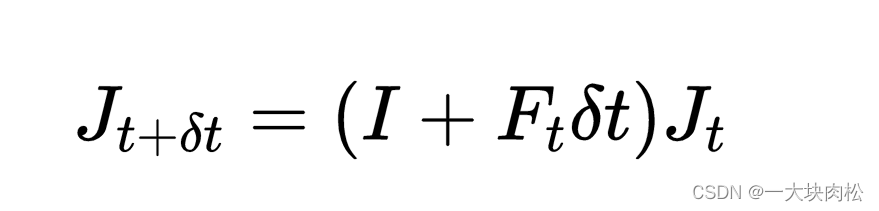
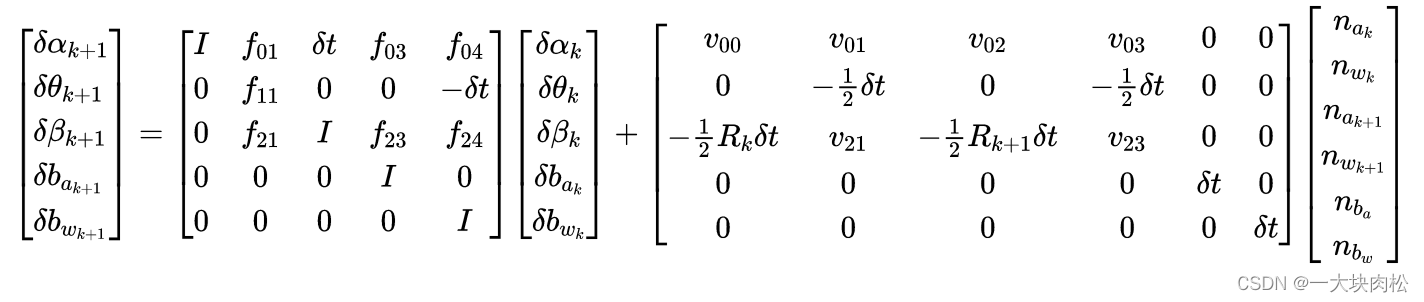
上述矩阵可以表示为:
δ
Z
k
+
1
=
F
δ
Z
k
+
V
n
\qquad\qquad\delta Z_{k+1}=F\delta Z_k+Vn
δZk+1=FδZk+Vn
同理得到协方差公式:
P
k
+
1
=
F
P
k
F
T
+
V
Q
V
T
\qquad \qquad P_{k+1}=FP_kF^T+VQV^T
Pk+1=FPkFT+VQVT
其中
Q
Q
Q表示噪声项符合的协方差:
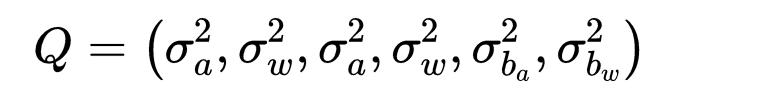
J k + 1 = F J k \qquad \qquad \qquad J_{k+1}=FJ_k Jk+1=FJk
总结:终于结束了IMU预积分的推导过程,作为一个记录(tips看了好多大佬的博客)
参考博客:
VINS-Mono理论学习——IMU预积分 Pre-integration (Jacobian 协方差)
【VINS论文翻译】VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
我已经开始学习Ruby,我已经阅读了一些教程,甚至还买了一本书(“ProgrammingRuby1.9-ThePragmaticProgrammers'Guide”),我遇到了一些以前从未见过的新东西使用我知道的任何其他语言(我是一名PHP网络开发人员)。block和过程。我想我明白它们是什么,但我不明白的是为什么它们如此伟大,以及我应该在何时何地使用它们。我到处都看到他们说block和过程是Ruby中的一个很棒的特性,但我不理解它们。这里有人能给像我这样的Ruby新手一些解释吗? 最佳答案 block有很多好处。电梯演讲:bloc
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
rails中View的解析过程是怎样的?我对View中erb标记中原始html与ruby代码的解析顺序部分感兴趣。我认为这是View代码被解析并最终发送给请求者的顺序:Controller调用ViewView代码从上到下解析当Rails在解析过程中遇到erb标记时:rails解析它并将结果附加到解析的html(这包括erb标签引用助手)一旦整个View被解析,整体结果将发送给请求者这似乎并非如此。看来View代码会扫描任何erb片段并首先解析那些片段(包括对助手的引用)。之后,rails然后从上到下解析所有View代码并将结果发送给请求者。以这个View为例:#_form.html
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
快速导航(持续更新中…)Cesium源码解析一(terrain文件的加载、解析与渲染全过程梳理)Cesium源码解析二(metadataAvailability的含义)Cesium源码解析三(metadata元数据拓展中行列号的分块规则解析)Cesium源码解析四(Quantized-Mesh(.terrain)格式文件在CesiumJS和UE中加载情况的对比)目录1.前言2.本篇的由来3.terrain文件的加载3.1更新环境3.2更新和执行渲染命令3.3数据优化3.4结束当前帧4.总结1.前言 目前市场上三维比较火的实现方案主要有两种,b/s的方案主要是Cesium,c/s的方案主要是u
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/