离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
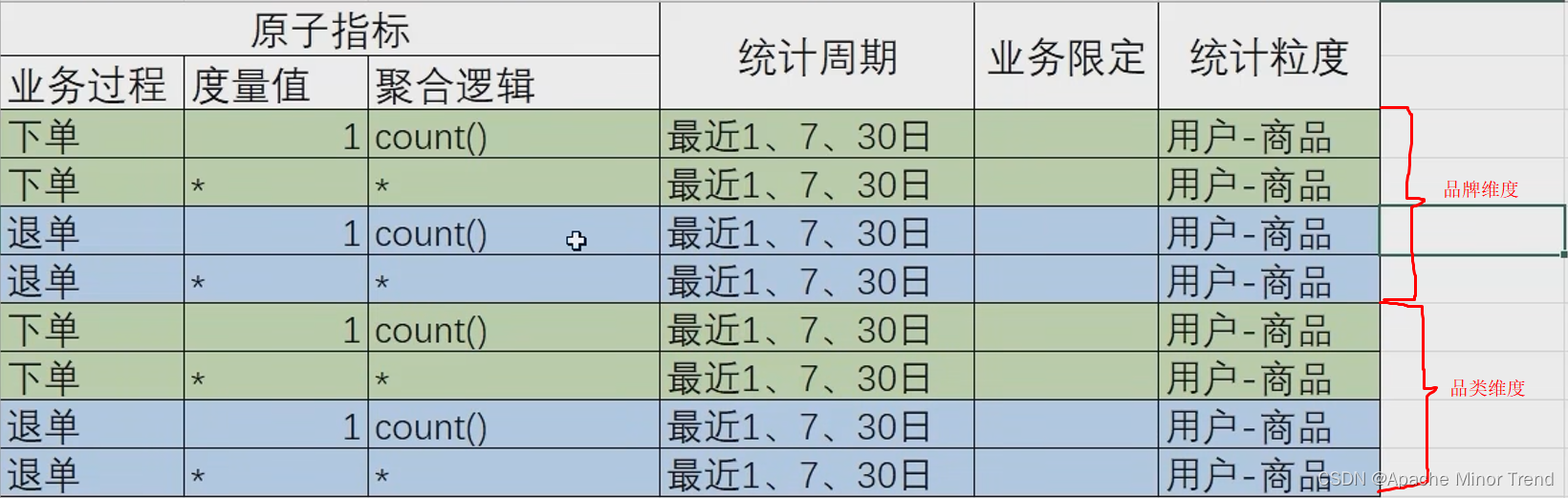
| 统计周期 | 统计粒度 | 指标 |
|---|---|---|
| 最近1、7、30日 | 品牌 | 订单数 |
| 最近1、7、30日 | 品牌 | 订单人数 |
| 最近1、7、30日 | 品牌 | 退单数 |
| 最近1、7、30日 | 品牌 | 退单人数 |
| 统计周期 | 统计粒度 | 指标 |
|---|---|---|
| 最近1、7、30日 | 品类 | 订单数 |
| 最近1、7、30日 | 品类 | 订单人数 |
| 最近1、7、30日 | 品类 | 退单数 |
| 最近1、7、30日 | 品类 | 退单人数 |
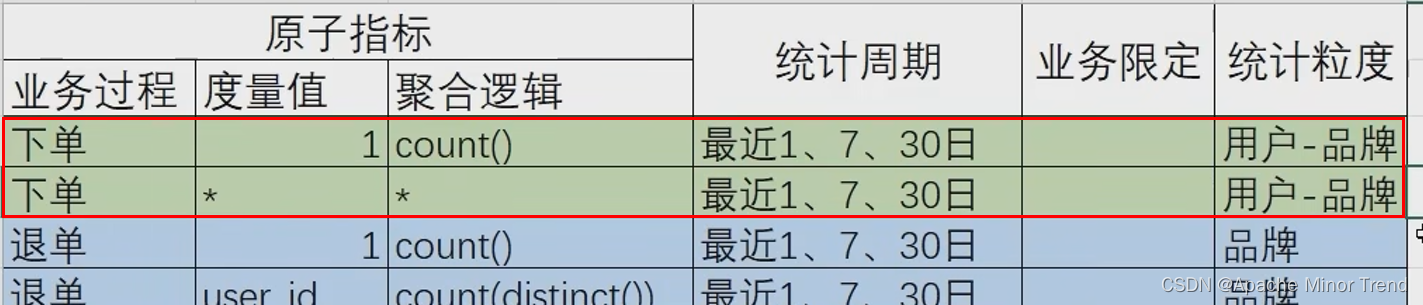
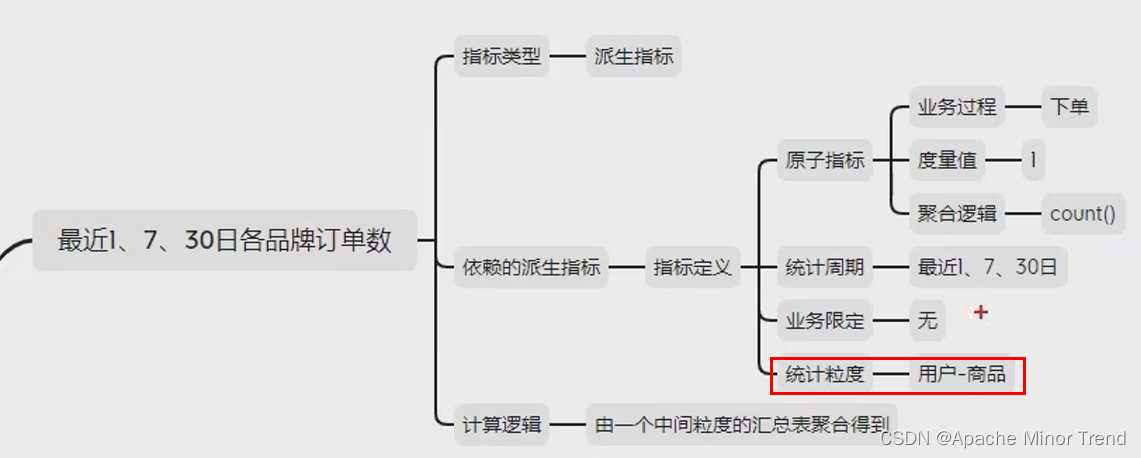
2.构建指标体系,对于需求进行指标分析,分析出每个需求对应什么类型指标
各品牌的指标体系分析
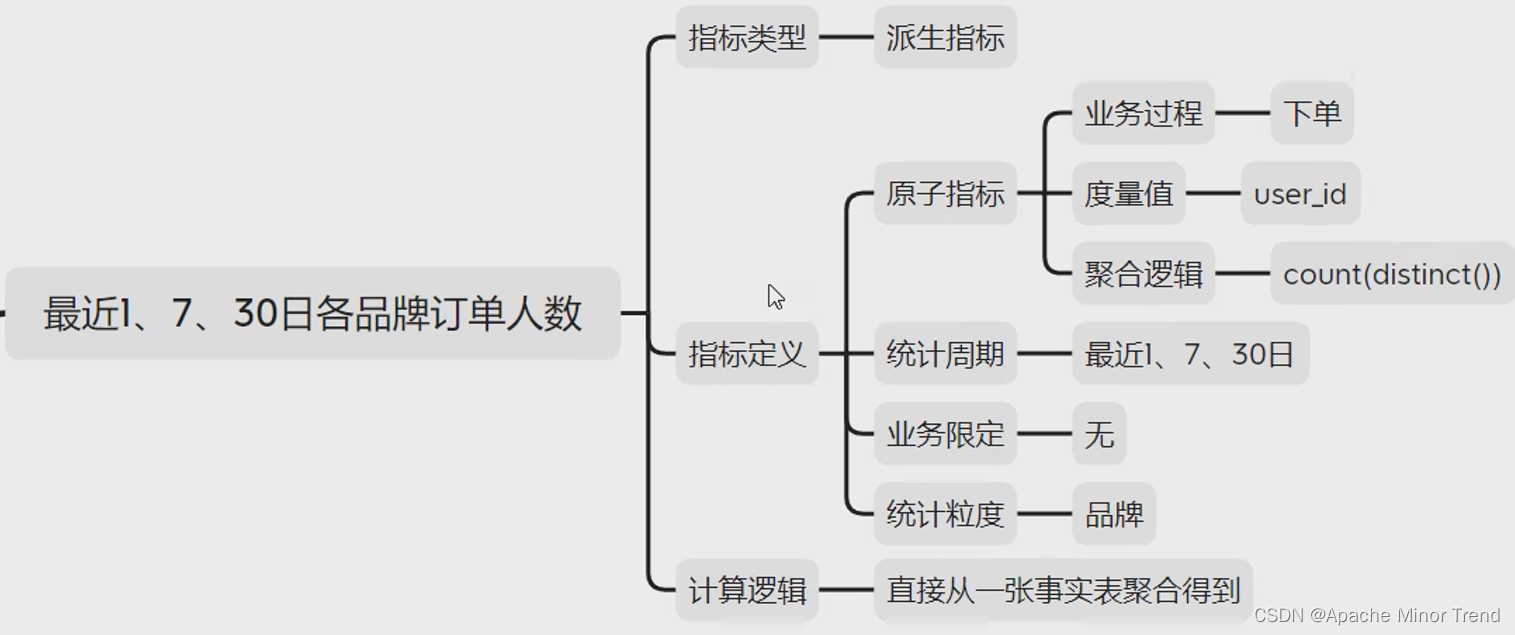
各品类的指标体系分析
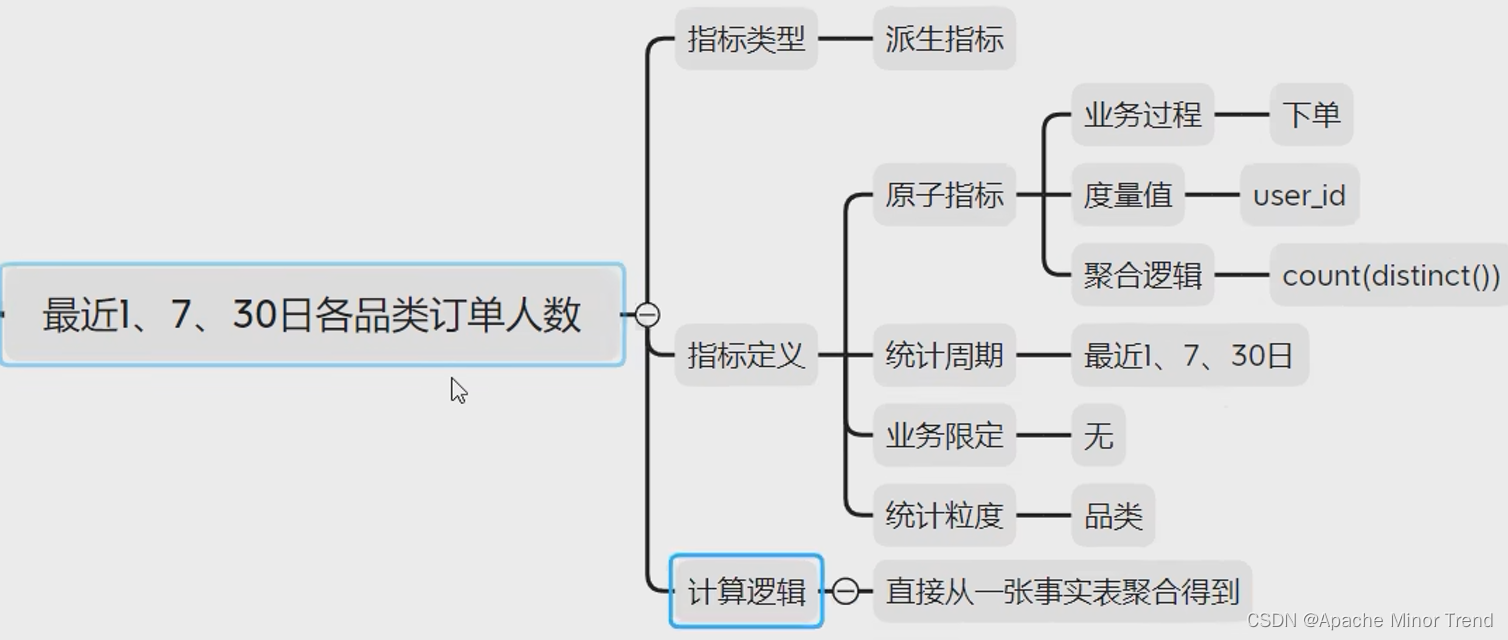
3.抽取派生指标,将刚刚思维导图中汇总的指标体系,梳理到表格中,抽取共用的派生指标
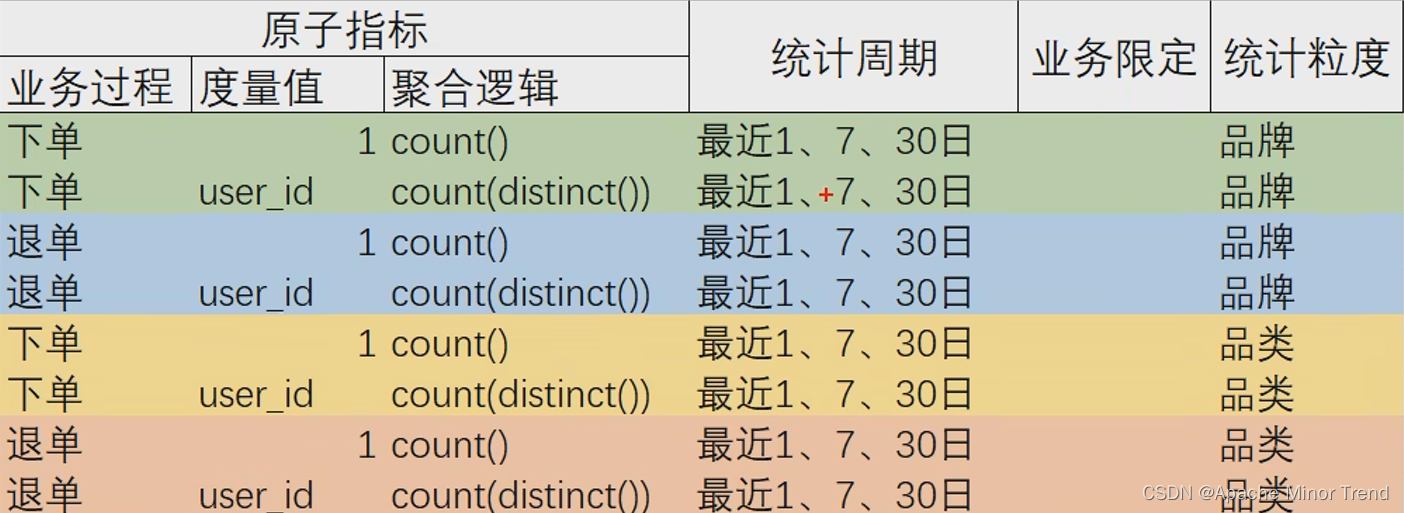
4.设计DWS层汇总表,根据刚刚梳理的指标体系表格,梳理出DWS层需要创建哪些表格。
DWS层表名的命名规范为:dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)
5.创建dwd_trade_tm_order_1d表格的DDL语句
create external table dws_trade_tm_order_1d
(
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count bigint comment '最近1日下单次数',
order_user_count bigint comment '最近1日下单人数',
order_num bigint comment '最近1日下单件数',
order_total_amount decimal(16,2) comment '最近1日下单金额'
) comment '交易域品牌粒度订单最近1日汇总事实表'
partition by (dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_1d'
tblproperties('orc.compress'='snappy')
insert overwrite table dws_trade_tm_order_1d partition(dt='2020-06-14'
SELECT
tm_id,
tm_name,
COUNT(1),
count(DISTINCT (user_id)),
sum(sku_num),
sum(split_total_amount)
from
(
SELECT
sku_id, user_id, sku_num, split_total_amount
from
dwd_trade_order_detail_inc
where
dt = '2020-06-14' )od
left JOIN (
select
id, tm_id, tm_name
FROM
dim_sku_full
where
dt = '2020-06-14' )sku on
od.sku_id = sku.id
GROUP by
tm_id,
tm_name;
create external table dws_trade_tm_order_nd
(
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count_7d bigint comment '最近7日下单次数',
order_user_count_7d bigint comment '最近7日下单人数',
order_num_7d bigint comment '最近7日下单件数',
order_total_amount_7d decimal(16,2) comment '最近7日下单金额',
order_count_30d bigint comment '最近30日下单次数',
order_user_count_30d bigint comment '最近30日下单人数',
order_num_30d bigint comment '最近30日下单件数',
order_total_amount_30d decimal(16,2) comment '最近30日下单金额'
) comment '交易域品牌粒度订单最近7日和30日汇总事实表'
partition by (dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_nd'
tblproperties('orc.compress'='snappy')
insert overwrite table dws_trade_tm_order_nd partition(dt='2020-06-14')
select
tm_id,
tm_name,
sum(if(dt>=date_sub('2020-06-14',6),order_count,0)), //计算最近7天的数据
sum(if(dt>=date_sub('2020-06-14',6),order_user_count,0)),
sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),
sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),
sum(order_count),
sum(order_user_count),
sum(order_num),
sum(order_total_amount),
from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)
group by tm_id,tm_name;
create external table dws_trade_user_tm_order_1d
(
user_id string comment '用户id',
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count bigint comment '最近1日下单次数',
order_num bigint comment '最近1日下单件数',
order_total_amount decimal(16,2) comment '最近1日下单金额'
) comment '交易域用户品牌粒度订单最近1日汇总事实表'
partition by (dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_1d'
tblproperties('orc.compress'='snappy')
insert overwrite table dws_trade_user_tm_order_1d partition(dt='2020-06-14'
SELECT
user_id,
tm_id,
tm_name,
COUNT(1),
sum(sku_num),
sum(split_total_amount)
from
(
SELECT
sku_id, user_id, sku_num, split_total_amount
from
dwd_trade_order_detail_inc
where
dt = '2020-06-14' )od
left JOIN (
select
id, tm_id, tm_name
FROM
dim_sku_full
where
dt = '2020-06-14' )sku on
od.sku_id = sku.id
GROUP by
user_id,
tm_id,
tm_name;
create external table dws_trade_user_tm_order_nd
(
user_id string comment '用户id',
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count_7d bigint comment '最近7日下单次数',
order_num_7d bigint comment '最近7日下单件数',
order_total_amount_7d decimal(16,2) comment '最近7日下单金额',
order_count_30d bigint comment '最近30日下单次数',
order_num_30d bigint comment '最近30日下单件数',
order_total_amount_30d decimal(16,2) comment '最近30日下单金额'
) comment '交易域用户品牌粒度订单最近7日和30日汇总事实表'
partition by (dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_nd'
tblproperties('orc.compress'='snappy')
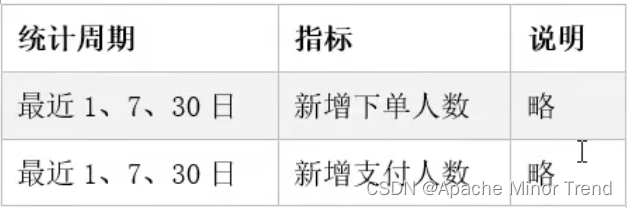
4.指标体系调整:其他指标也需要跟着调整
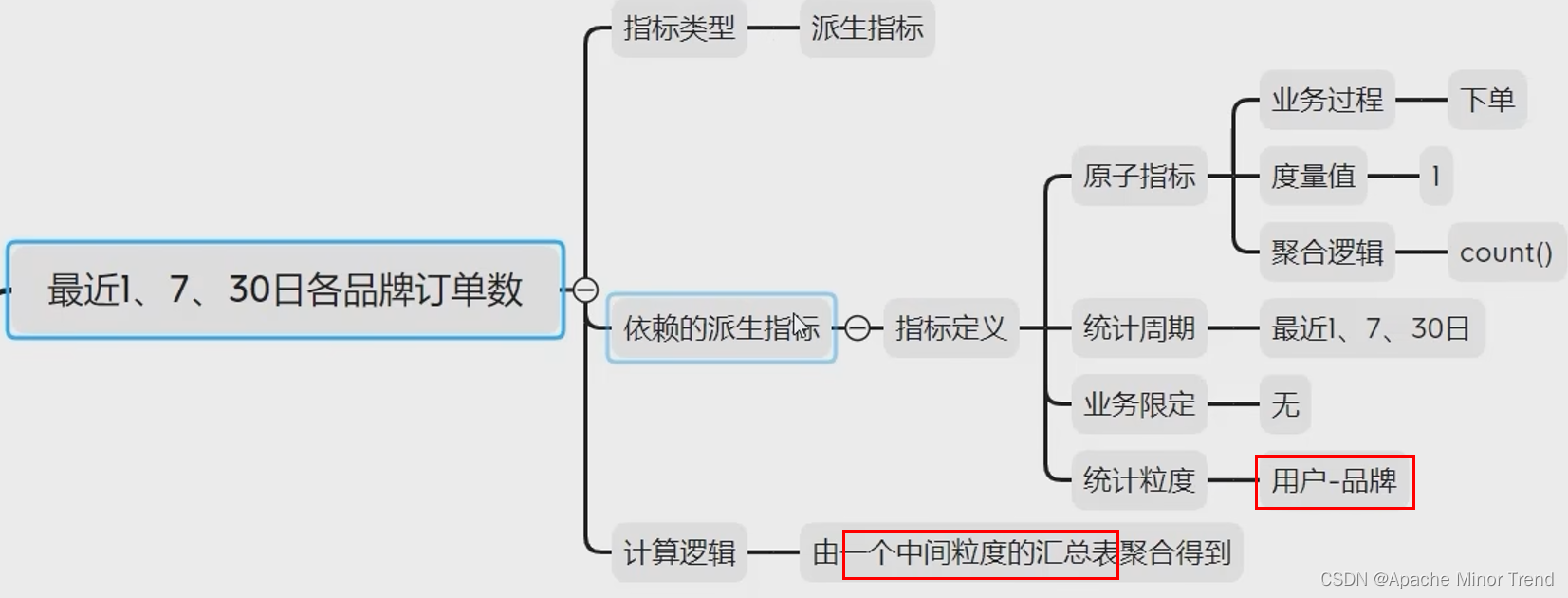
5.对应需求矩阵
6.nd表的数据装载
insert overwrite table dws_trade_user_tm_order_nd partition(dt='2020-06-14')
select
user_id ,
tm_id,
tm_name,
sum(if(dt>=date_sub('2020-06-14',6),order_count,0)), //计算最近7天的数据
sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),
sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),
sum(order_count),
sum(order_num),
sum(order_total_amount),
from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)
group by user_id ,tm_id,tm_name;
DROP TABLE IF EXISTS dws_trade_user_sku_order_1d;
CREATE EXTERNAL TABLE dws_trade_user_sku_order_1d
(
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'sku_id',
`sku_name` STRING COMMENT 'sku名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`category2_id` STRING COMMENT '一级分类id',
`category2_name` STRING COMMENT '一级分类名称',
`category3_id` STRING COMMENT '一级分类id',
`category3_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`order_count_1d` BIGINT COMMENT '最近1日下单次数',
`order_num_1d` BIGINT COMMENT '最近1日下单件数',
`order_original_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单原始金额',
`activity_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日活动优惠金额',
`coupon_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日优惠券优惠金额',
`order_total_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单最终金额'
) COMMENT '交易域用户商品粒度订单最近1日汇总事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_1d'
TBLPROPERTIES ('orc.compress' = 'snappy');
DROP TABLE IF EXISTS dws_trade_user_sku_order_nd;
CREATE EXTERNAL TABLE dws_trade_user_sku_order_nd
(
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'sku_id',
`sku_name` STRING COMMENT 'sku名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`category2_id` STRING COMMENT '一级分类id',
`category2_name` STRING COMMENT '一级分类名称',
`category3_id` STRING COMMENT '一级分类id',
`category3_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`order_count_7d` STRING COMMENT '最近7日下单次数',
`order_num_7d` BIGINT COMMENT '最近7日下单件数',
`order_original_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单原始金额',
`activity_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日活动优惠金额',
`coupon_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日优惠券优惠金额',
`order_total_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单最终金额',
`order_count_30d` BIGINT COMMENT '最近30日下单次数',
`order_num_30d` BIGINT COMMENT '最近30日下单件数',
`order_original_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单原始金额',
`activity_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日活动优惠金额',
`coupon_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日优惠券优惠金额',
`order_total_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单最终金额'
) COMMENT '交易域用户商品粒度订单最近n日汇总事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_nd'
TBLPROPERTIES ('orc.compress' = 'snappy');
DROP TABLE IF EXISTS dws_trade_user_order_td;
CREATE EXTERNAL TABLE dws_trade_user_order_td
(
`user_id` STRING COMMENT '用户id',
`order_date_first` STRING COMMENT '首次下单日期',
`order_date_last` STRING COMMENT '末次下单日期',
`order_count_td` BIGINT COMMENT '下单次数',
`order_num_td` BIGINT COMMENT '购买商品件数',
`original_amount_td` DECIMAL(16, 2) COMMENT '原始金额',
`activity_reduce_amount_td` DECIMAL(16, 2) COMMENT '活动优惠金额',
`coupon_reduce_amount_td` DECIMAL(16, 2) COMMENT '优惠券优惠金额',
`total_amount_td` DECIMAL(16, 2) COMMENT '最终金额'
) COMMENT '交易域用户粒度订单历史至今汇总事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_order_td'
TBLPROPERTIES ('orc.compress' = 'snappy');
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-14')
select
user_id,
min(dt) login_date_first,
max(dt) login_date_last,
sum(order_count_1d) order_count,
sum(order_num_1d) order_num,
sum(order_original_amount_1d) original_amount,
sum(activity_reduce_amount_1d) activity_reduce_amount,
sum(coupon_reduce_amount_1d) coupon_reduce_amount,
sum(order_total_amount_1d) total_amount
from dws_trade_user_order_1d
group by user_id;
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-15')
select
nvl(old.user_id,new.user_id),
if(new.user_id is not null and old.user_id is null,'2020-06-15',old.order_date_first),
if(new.user_id is not null,'2020-06-15',old.order_date_last),
nvl(old.order_count_td,0)+nvl(new.order_count_1d,0),
nvl(old.order_num_td,0)+nvl(new.order_num_1d,0),
nvl(old.original_amount_td,0)+nvl(new.order_original_amount_1d,0),
nvl(old.activity_reduce_amount_td,0)+nvl(new.activity_reduce_amount_1d,0),
nvl(old.coupon_reduce_amount_td,0)+nvl(new.coupon_reduce_amount_1d,0),
nvl(old.total_amount_td,0)+nvl(new.order_total_amount_1d,0)
from
(
select
user_id,
order_date_first,
order_date_last,
order_count_td,
order_num_td,
original_amount_td,
activity_reduce_amount_td,
coupon_reduce_amount_td,
total_amount_td
from dws_trade_user_order_td
where dt=date_add('2020-06-15',-1)
)old
full outer join
(
select
user_id,
order_count_1d,
order_num_1d,
order_original_amount_1d,
activity_reduce_amount_1d,
coupon_reduce_amount_1d,
order_total_amount_1d
from dws_trade_user_order_1d
where dt='2020-06-15'
)new
on old.user_id=new.user_id;
SELECT
user_id,
min(order_date_first) ,
max(order_date_last),
sum(order_count_td),
sum(order_num_td),
sum(original_amount_td),
sum(activity_reduce_amount_td),
sum(coupon_reduce_amount_td),
sum(total_amount_td)
from
(
select
user_id, order_date_first, order_date_last, order_count_td, order_num_td, original_amount_td, activity_reduce_amount_td, coupon_reduce_amount_td, total_amount_td
from
dws_trade_user_order_td
where
dt = date_add('2020-06-15',-1)
UNION ALL
select
user_id, '2020-06-15', '2020-06-15', order_count_1d, order_num_1d, order_original_amount_1d, activity_reduce_amount_1d, coupon_reduce_amount_1d, order_total_amount_1d
from
dws_trade_user_order_1d
where
dt = '2020-06-15'
GROUP by
user_id ) t1
group by
user_id ;
hive 中sql语法:
开窗和分组
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl