 一方面,生成式AI可以让人类更有生产力和创造力。另一方面,它们可能会放大社会偏见,甚至破坏我们对信息的信任。我们相信,跨学科的合作对于确保这些 技术惠及我们所有人。以下是斯坦福大学的观点 医学、科学、工程、人文学科和社会科学领域的领导人关于「生成式人工智能」如何影响其领域和我们世界的观点。本文,我们选取了李飞飞和Percy Liang对当前生成式AI的见解。完整观点报告请参见:https://hai.stanford.edu/generative-ai-perspectives-stanford-hai
一方面,生成式AI可以让人类更有生产力和创造力。另一方面,它们可能会放大社会偏见,甚至破坏我们对信息的信任。我们相信,跨学科的合作对于确保这些 技术惠及我们所有人。以下是斯坦福大学的观点 医学、科学、工程、人文学科和社会科学领域的领导人关于「生成式人工智能」如何影响其领域和我们世界的观点。本文,我们选取了李飞飞和Percy Liang对当前生成式AI的见解。完整观点报告请参见:https://hai.stanford.edu/generative-ai-perspectives-stanford-hai 人类大脑可以识别世界上的所有模式,并且据此构建模型或生成概念。几代人工智能科学家的梦想,就是将这种生成能力赋予机器,他们在生成模型算法开发这一领域做过很长时间的努力。1966年,麻省理工学院的研究人员发起了 「夏季视觉项目」(Summer Vision Project),旨在用技术有效搭建视觉系统的一个重要部分。这就是计算机视觉和图像生成领域研究的开端。近期,得益于深度学习和大数据的密切关联,人们似乎已经到达了一个重要拐点,即将让机器具备生成语言、图像、音频等的能力。尽管计算机视觉的灵感来源是打造能看到人类所能看到东西的AI,但现在这一学科的目标远不限于此,未来要打造的AI应当看到人类所不能看到的东西。如何使用生成式人工智能来增强人类的视觉呢?比如,在美国医疗错误造成的死亡是一个令人担忧的问题。生成式AI可以协助医疗保健提供者看到潜在的问题。如果错误产生于罕见情况,生成式AI可以创建模拟版本的类似数据,来进一步训练AI模型,或者是为医疗人员提供训。
人类大脑可以识别世界上的所有模式,并且据此构建模型或生成概念。几代人工智能科学家的梦想,就是将这种生成能力赋予机器,他们在生成模型算法开发这一领域做过很长时间的努力。1966年,麻省理工学院的研究人员发起了 「夏季视觉项目」(Summer Vision Project),旨在用技术有效搭建视觉系统的一个重要部分。这就是计算机视觉和图像生成领域研究的开端。近期,得益于深度学习和大数据的密切关联,人们似乎已经到达了一个重要拐点,即将让机器具备生成语言、图像、音频等的能力。尽管计算机视觉的灵感来源是打造能看到人类所能看到东西的AI,但现在这一学科的目标远不限于此,未来要打造的AI应当看到人类所不能看到的东西。如何使用生成式人工智能来增强人类的视觉呢?比如,在美国医疗错误造成的死亡是一个令人担忧的问题。生成式AI可以协助医疗保健提供者看到潜在的问题。如果错误产生于罕见情况,生成式AI可以创建模拟版本的类似数据,来进一步训练AI模型,或者是为医疗人员提供训。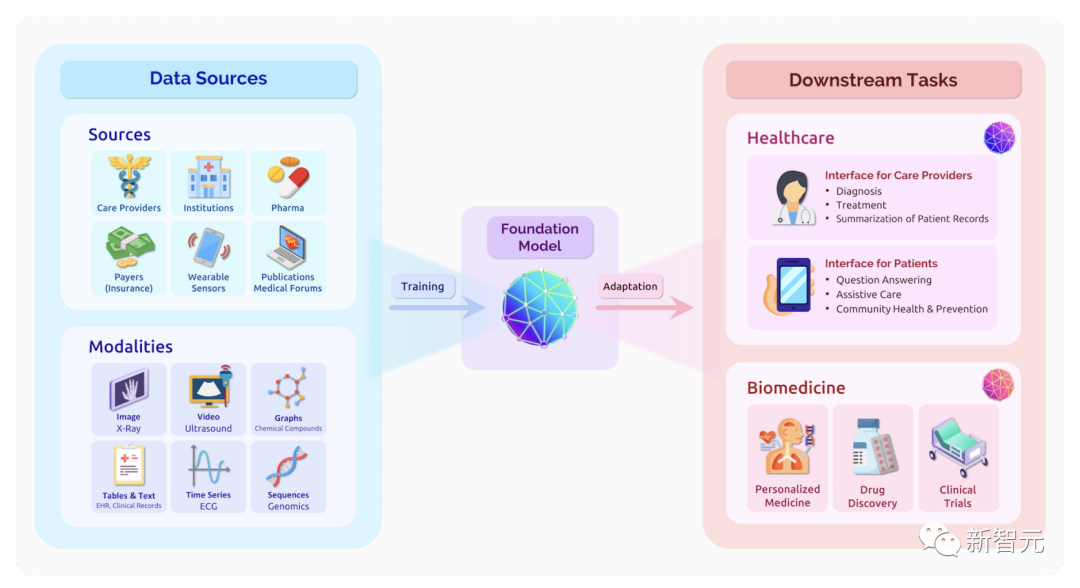 在开始开发新的生成式工具之前,应当关注人们希望通过工具获得什么。在近期的一个为机器人任务制定基准的项目中,研究团队在开始工作前进行了一次大规模的用户研究,询问人们如果由机器人来完成某些任务,他们会受益多少,使人受益最多的任务成为项目研究的重点。为了抓住生成式人工智能创造的重大机遇,相关风险也需要合理评估。Joy Buolamwini领导了一项名为「性别阴影」的研究,发现AI经常在识别女性和有色人种时出现问题。类似这样对缺乏代表性群体的偏见,在生成式AI中还会继续出现。
在开始开发新的生成式工具之前,应当关注人们希望通过工具获得什么。在近期的一个为机器人任务制定基准的项目中,研究团队在开始工作前进行了一次大规模的用户研究,询问人们如果由机器人来完成某些任务,他们会受益多少,使人受益最多的任务成为项目研究的重点。为了抓住生成式人工智能创造的重大机遇,相关风险也需要合理评估。Joy Buolamwini领导了一项名为「性别阴影」的研究,发现AI经常在识别女性和有色人种时出现问题。类似这样对缺乏代表性群体的偏见,在生成式AI中还会继续出现。 判断一张图片是否是使用AI生成的,也是十分重要的能力。人类社会是建立在在对公民身份的信任之上,如果缺乏这种能力,我们的信任感就会降低。机器生成能力方面的进展是非常令人振奋的,发掘人工智能看到人类无法看到的东西的潜力也是如此。然而,我们需要警惕,这些能力可能扰乱我们的日常生活、我们所处的环境,破坏我们作为世界公民的角色。
判断一张图片是否是使用AI生成的,也是十分重要的能力。人类社会是建立在在对公民身份的信任之上,如果缺乏这种能力,我们的信任感就会降低。机器生成能力方面的进展是非常令人振奋的,发掘人工智能看到人类无法看到的东西的潜力也是如此。然而,我们需要警惕,这些能力可能扰乱我们的日常生活、我们所处的环境,破坏我们作为世界公民的角色。 在人类史上,创造新鲜事物总是很困难的,而且这种能力几乎只有专家才具备。但随着近期基础模型的进步,人工智能的「寒武纪爆炸」正在发生,人工智能将可以创造任何东西,从视频到蛋白质再到代码。这种能力降低了创造的门槛,但它也剥夺了我们辨认真实的能力。基于深度神经网络和自我监督学习而建立的基础模型已经存在有几十年了。然而,最近这些模型所能训练的庞大数据量使模型的能力突飞猛进。2021年发布的一篇论文详细介绍了基础模型的机会和风险,这些新出现的能力会成为「科学界兴奋的来源」,也会导致「意料之外的后果」。
在人类史上,创造新鲜事物总是很困难的,而且这种能力几乎只有专家才具备。但随着近期基础模型的进步,人工智能的「寒武纪爆炸」正在发生,人工智能将可以创造任何东西,从视频到蛋白质再到代码。这种能力降低了创造的门槛,但它也剥夺了我们辨认真实的能力。基于深度神经网络和自我监督学习而建立的基础模型已经存在有几十年了。然而,最近这些模型所能训练的庞大数据量使模型的能力突飞猛进。2021年发布的一篇论文详细介绍了基础模型的机会和风险,这些新出现的能力会成为「科学界兴奋的来源」,也会导致「意料之外的后果」。 论文中还讨论了同质化问题。同样的几个模型被重复使用作为许多应用的基础,这样能使研究人员集中精力在一小部分模型上。但集中化也使这些模型成为单一的故障点,潜在的危害会影响到诸多下游应用。
论文中还讨论了同质化问题。同样的几个模型被重复使用作为许多应用的基础,这样能使研究人员集中精力在一小部分模型上。但集中化也使这些模型成为单一的故障点,潜在的危害会影响到诸多下游应用。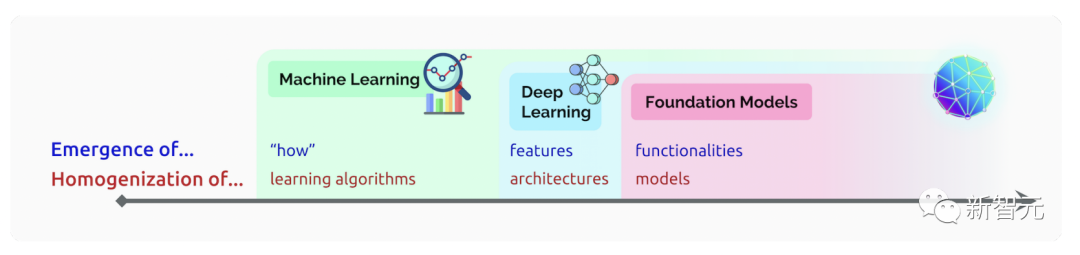 对基础模型进行基准测试也是十分重要的,以便研究人员更好地了解其能力与缺陷,制定更合理的发展战略。HELM(语言模型的整体评估)的开发就是为了这个目的。HELM以准确性、稳健性、公平性等多种指标,对30多个著名的语言模型在一系列场景中的表现做出了评估。新的模型、新的应用场景和新的评价指标还会出现,我们欢迎大家为HELM的发展添砖加瓦。
对基础模型进行基准测试也是十分重要的,以便研究人员更好地了解其能力与缺陷,制定更合理的发展战略。HELM(语言模型的整体评估)的开发就是为了这个目的。HELM以准确性、稳健性、公平性等多种指标,对30多个著名的语言模型在一系列场景中的表现做出了评估。新的模型、新的应用场景和新的评价指标还会出现,我们欢迎大家为HELM的发展添砖加瓦。 导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
目录前言一、什么是AIGC?1、什么是PGC?2、什么是UGC?3、什么是PUCG?4、什么是AIGC?二、总结前言很明显,ChatGPT的爆火,带动了AIGC(AI-GeneratedContent)概念的火热。一、什么是AIGC?GC,全称GeneratedContent,是指创作内容。与之相对应的概念中,有PGC、UGC、PUGC、AIGC。1、什么是PGC?PGC,全称ProfessionalGeneratedContent,指专业生产内容。专业生产内容模式,主要表现为由专家或者机构来进行内容的生产,具备专业的内容生产能力,能够保证内容的专业性。主要应用在知识付费、在线教育、学习平台等
这个问题在这里已经有了答案:WhydoRubysettersneed"self."qualificationwithintheclass?(3个答案)关闭29天前。给定这段代码:classSomethingattr_accessor:my_variabledefinitialize@my_variable=0enddeffoomy_variable=my_variable+3endends=Something.news.foo我收到这个错误:test.rb:9:in`foo':undefinedmethod`+'fornil:NilClass(NoMethodError)fromtes
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭9年前。Improvethisquestion首先,我想避免一场关于语言的口水战。可供选择的语言有Perl、Python和Ruby。我想提一下,我对所有这些都很满意,但问题是我不能只专注于一个。例如,如果我看到一个很棒的Perl模块,我必须尝试一下。如果我看到一个不错的Python应用程序,我必须知道它是如何制作的。如果我看到RubyDSL或一些Ruby巫术,我就会迷上Ruby一段时间。目前我是一名Java开发人员,但计划在不久的将来
我爱Sanitize.这是一个了不起的实用程序。我遇到的唯一问题是,它需要永远准备一个开发环境,因为它使用Nokogiri,这对编译时间来说是一种痛苦。是否有任何程序可以在不使用Nokogiri的情况下执行Sanitize的操作(如果没有别的,只是温和地执行它的操作)?这将以指数方式提供帮助! 最佳答案 Rails有自己的SanitizeHelper。根据http://api.rubyonrails.org/classes/ActionView/Helpers/SanitizeHelper.html,它将Thissanitizehe
操作系统:CentOS6.2x86_64很抱歉缩进太古怪了。这是我的第一篇SO帖子,我是新来设置服务器的。不过,我正在学习,并将详细说明我尝试解决此问题所采取的步骤以及寻求帮助的地方。我是一位有抱负的年轻Web开发人员,并且我在其他人配置的服务器上工作,因此,这对我来说是全新的。我正在准备我最近购买的用于运行Rails应用程序的linode。我遵循了此处http://blog.blenderbox.com/2011/01/07/installing-rvm-ruby-rails-passenger-nginx-on-centos/提供的初始安装指南,并更改了步骤:sudobash反射(
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我正在寻找一个用ruby或rails完成的报告生成器,它允许用户首先定义一个模板,然后将数据提取到模板中。我一直在浏览“TheRubyBox:报告部分”(https://www.ruby-toolbox.com/categories/reporting.html)有两个报告工具类似于我正在寻找的:ThinReports:这真的很好。您下载一个模板编辑器,然后定义您自己的报告模板,然后通过组合thinreportsgem,您可以从您的应用程序中获取SVG或PDF报告。ODFReport:它使用ODF文件作为模板,可以通过OpenOffice和MSWord2010进行编辑。然后你就可以
我想知道NokogiriXPath或CSS解析是否可以更快地处理HTML文件。速度有何不同? 最佳答案 Nokogiri没有XPath或CSS解析。它将XML/HTML解析为单个DOM,然后您可以使用CSS或XPath语法进行查询。CSS选择器在要求libxml2执行查询之前在内部转换为XPath。因此(对于完全相同的选择器)XPath版本会快一点点,因为CSS不需要先转换成XPath。但是,您的问题没有通用答案;这取决于您选择的是什么,以及您的XPath是什么样的。很有可能,您不会编写与Nokogiri创建的相同的XPath。例如
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动