利用Kafka实现延迟队列实践
阿里提供的RocketMq消息中间件是天然支持消息先延迟队列功能的,主要原理和实现方法可以参加以下链接:
https://blog.csdn.net/daimingbao/article/details/119846393
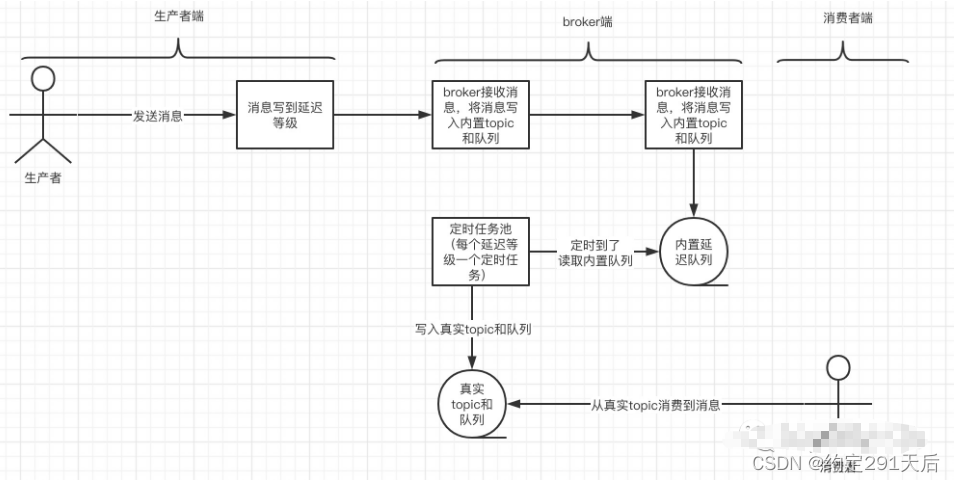
项目中采用的消息中间件是kafka,那如何在kafka上实现类似延迟队列的功能。
kafka本身是不支持延迟队列功能,我们可以通过消息延时转发新主题,曲线完成该功能。
主要实践原理是通过定阅原始主题,并判断是否满足延迟时间要求,满足要求后转发新主题,不满足则阻塞等待,同时外置一个定时器,每1秒进行唤醒锁协作。
为了避免消息长时间得不到消费使用导致kafka的rebalance,使用kafka自提供的api
consumer.pause(Collections.singletonList(topicPartition));
代码参考,详细参考代码里注释:
package com.zte.sdn.oscp.kafka;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Properties;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.ExecutionException;
@SpringBootTest(classes = TestMainApplication.class)
public class DelayQueueTest {
private KafkaConsumer<String, String> consumer;
private KafkaProducer<String, String> producer;
private volatile Boolean exit = false;
private final Object lock = new Object();
private final String servers = "127.0.0.1:4532";
@BeforeEach
void initConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "d");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "5000");
consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer());
}
@BeforeEach
void initProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
}
@Test
void testDelayQueue() throws IOException, InterruptedException {
//主题
String topic = "delay-minutes-1";
List<String> topics = Collections.singletonList(topic);
consumer.subscribe(topics);
//定时器,实时1s解锁
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
synchronized (lock) {
consumer.resume(consumer.paused());
lock.notify();
}
}
}, 0, 1000);
do {
synchronized (lock) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(200));
//消息为空,则阻塞,等待定时器来唤醒
if (consumerRecords.isEmpty()) {
lock.wait();
continue;
}
boolean timed = false;
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
//消息体固定为{"topic": "target","key": "key1","value": "value1"}
long timestamp = consumerRecord.timestamp();
TopicPartition topicPartition = new TopicPartition(consumerRecord.topic(), consumerRecord.partition());
//判断是否满足延迟要求,这里为1min,当然也可以设计更多延迟定义的主题
if (timestamp + 60 * 1000 < System.currentTimeMillis()) {
String value = consumerRecord.value();
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(value);
JsonNode jsonNodeTopic = jsonNode.get("topic");
String appTopic = null, appKey = null, appValue = null;
if (jsonNodeTopic != null) {
appTopic = jsonNodeTopic.asText();
}
if (appTopic == null) {
continue;
}
JsonNode jsonNodeKey = jsonNode.get("key");
if (jsonNodeKey != null) {
appKey = jsonNode.asText();
}
JsonNode jsonNodeValue = jsonNode.get("value");
if (jsonNodeValue != null) {
appValue = jsonNodeValue.asText();
}
// send to application topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(appTopic, appKey, appValue);
try {
producer.send(producerRecord).get();
// success. commit message
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(consumerRecord.offset() + 1);
HashMap<TopicPartition, OffsetAndMetadata> metadataHashMap = new HashMap<>();
metadataHashMap.put(topicPartition, offsetAndMetadata);
consumer.commitSync(metadataHashMap);
} catch (ExecutionException e) {
//异步停止,并重置offset
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed = true;
break;
}
} else {
//不满足延迟要求,并重置offset
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed = true;
break;
}
}
if (timed) {
lock.wait();
}
}
} while (!exit);
}
}
上面的实践存在什么样的问题,考虑一个场景,有一个延迟一小时的队列,这样消息发出后,实际上一个小时后在该主题上的消息拉取才有意义(之前即使拉取下来也发送不出去),但上面的实现仍然会不停阻塞唤醒,相当于在做无用功。如何避免该问题。
这边的原理是通过定阅原始主题,并判断是否满足延迟时间要求,满足要求后转发新主题,不满足则停止消费并等待。
package com.zte.sdn.oscp.kafka;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
@SpringBootTest(classes = TestMainApplication.class)
public class DelayQueueSeniorTest {
private KafkaConsumer<String, String> consumer;
private KafkaProducer<String, String> producer;
private volatile Boolean exit = false;
private final String servers = "127.0.0.1:4532";
@BeforeEach
void initConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "d");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "5000");
consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer());
}
@BeforeEach
void initProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
}
@Test
void testDelayQueue() throws IOException, InterruptedException {
String topic = "delay-minutes-1";
List<String> topics = Collections.singletonList(topic);
consumer.subscribe(topics);
do {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(200));
if (consumerRecords.isEmpty()) {
continue;
}
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
long timestamp = consumerRecord.timestamp();
TopicPartition topicPartition = new TopicPartition(consumerRecord.topic(), consumerRecord.partition());
//超时一分钟
long span = timestamp + 60 * 1000 - System.currentTimeMillis();
if (span <= 0) {
String value = consumerRecord.value();
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(value);
JsonNode jsonNodeTopic = jsonNode.get("topic");
String appTopic = null, appKey = null, appValue = null;
if (jsonNodeTopic != null) {
appTopic = jsonNodeTopic.asText();
}
if (appTopic == null) {
continue;
}
JsonNode jsonNodeKey = jsonNode.get("key");
if (jsonNodeKey != null) {
appKey = jsonNode.asText();
}
JsonNode jsonNodeValue = jsonNode.get("value");
if (jsonNodeValue != null) {
appValue = jsonNodeValue.asText();
}
// send to application topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(appTopic, appKey, appValue);
try {
producer.send(producerRecord).get();
// success. commit message
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(consumerRecord.offset() + 1);
HashMap<TopicPartition, OffsetAndMetadata> metadataHashMap = new HashMap<>();
metadataHashMap.put(topicPartition, offsetAndMetadata);
consumer.commitSync(metadataHashMap);
} catch (ExecutionException e) {
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
Thread.sleep(span);
consumer.resume(consumer.paused());
break;
}
} else {
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
//通过计算延迟时间差值,然后等待,避免空转
Thread.sleep(span);
consumer.resume(consumer.paused());
break;
}
}
} while (!exit);
}
}
当然还有一个更简单的方式,即利用定时器循环检测,可能会有一点时间上的误差,主要还是取决你的业务场景能否接受。
更高级一点则是使用时间轮机制。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来