咱们今天就来说一下Python的虚拟环境,可能有的小伙伴会疑惑,Python的虚拟环境有什么用呢?接下来我们一起来探讨一下。
咱们今天就来说一下Python的虚拟环境,可能有的小伙伴会疑惑,Python的虚拟环境有什么用呢?接下来我们一起来探讨一下。
我们先来举个例子,来说明为什么需要虚拟环境。我们在学习Python的时候,可能会学到越来越多的第三方库,比如爬虫,我们需要安装requests,可能学着学着,我们还需要安装bs4,或者又学着学着,我们还需要安装scrapy,再学着学着,又需要安装lxml…
嗯…,没错,我们安装了很多的第三方库,但是我们仍然每天嗨皮敲着代码,丝毫没有发现任何问题。如果你用的是Pycharm,直到有一天,你会发现你的Pycharm会启动越来越慢,就比如下图这样。
嗯…我的算是比较快了,因为我有优化过了。
这只是其中一个问题,还有一个问题就是,比如你帮别人做了个东西,肯定所有的功能都不是自己写的,有一些东西是别人写的,你需要安装一些第三方包。之后你咔咔咔把代码写完了,你怀着兴奋的心情把东西发给他,然后他发现自己竟然用不了,而且那边还会报下图所示的错误…
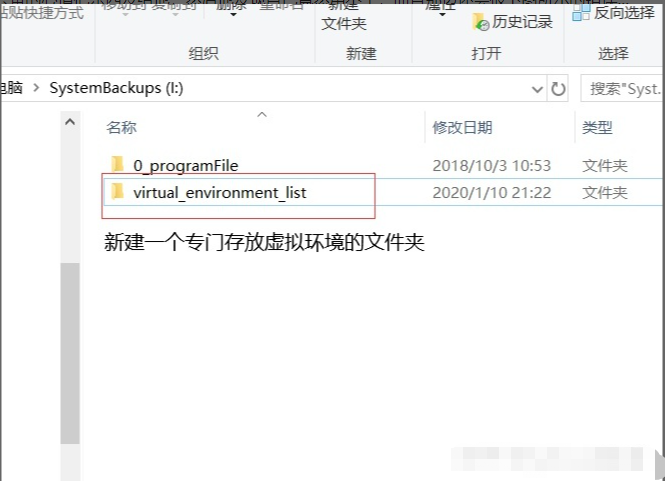
然后你还要一步一步一步教他安装,嗯,多么的痛苦!关键是,能一步安装到位还好,但是很可能的是,你用的某个包版本是2.0,现在最新版本是2.2,他那边直接pip install package,安装的是最新版本的包,可能和你的效果不太一样。哦嚯,完了,又是莫名其妙的调试。嗯…骚年,加班吧…
上面说的,只是其中的一些问题,但是大概我们能猜测出来,如果我们不对我们的第三方库加以管理,可能会造成莫名其妙的问题,导致效率低下,bug多,如果是一个团队的话,我想会更糟糕,后果不堪设想。
那说到这里,我们有没有什么办法,能够管理一下这些东西呢?
答案是肯定的,我们能想到这个问题,我们的大佬前辈当然也想到了,他都替我们安排好了,我们来一一讲解。
咱们今天就来说一下Python的虚拟环境,可能有的小伙伴会疑惑,Python的虚拟环境有什么用呢?接下来我们一起来探讨一下。
virtualenv这个是目前最通用的虚拟环境,安装(直接安装最新版)指令是:pip3 install virtualenv,其安装中间过程,这里就不展开了,等着装完就行。这里重点讲一下virtualenv的具体操作步骤。
1、新建虚拟环境列表文件夹,专门用于存放虚拟环境。
2、之后输入cmd命令,切换到该虚拟环境文件夹下,如下图所示。
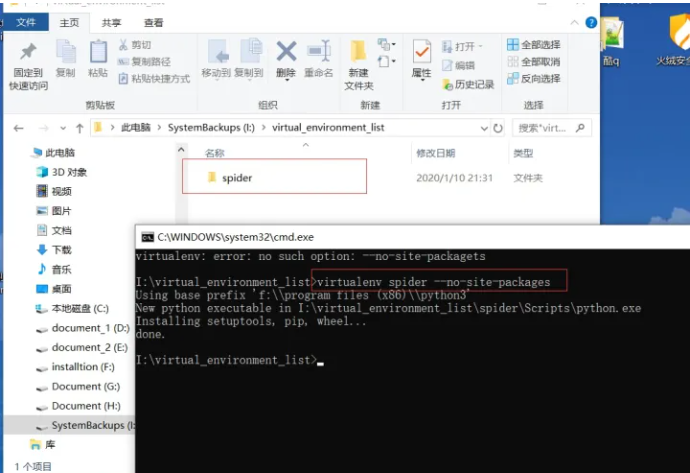
3、之后执行命令 virtualenv spider --no-site-packages,其中参数–no-site-packages表示我们就创建一个干净的、没有第三方包的干净的环境,如下图所示。
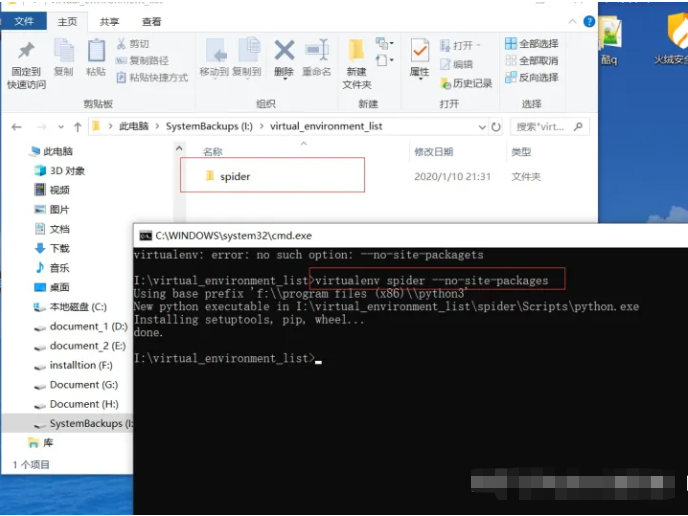
这样我们就创建了一个虚拟环境,但是此时我们并没有使用,我们在执行pip install package时,依然还是安装那个真实的环境上。
4、接下来我们需要进入并且激活spider虚拟环境。
cd spider
cd Scripts
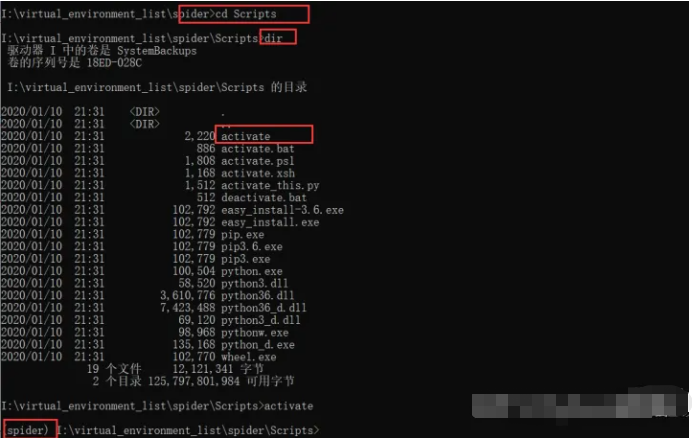
activate
当前面有显示(spider)时,表示我们已经进入了虚拟环境。这时候我们再执行pip install package时,就可以讲库安装在该新建的虚拟环境里了,如下图所示。
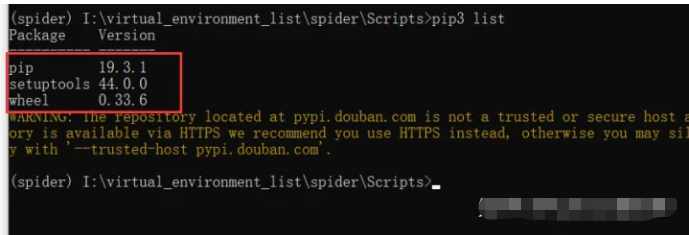
5、下图这个是我的虚拟环境。
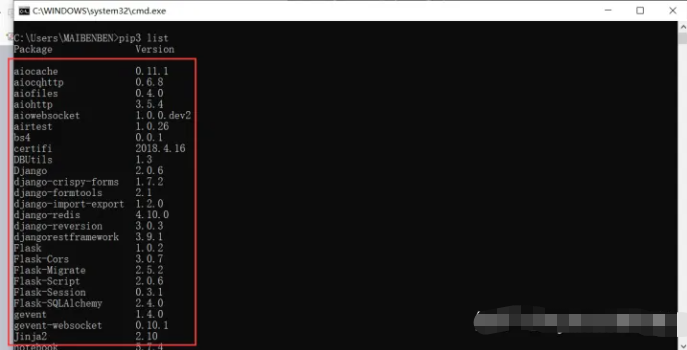
6、下图这个是我的真实环境。
7、在虚拟环境中安装第三方包,以安装requests库为例,如下图所示。在虚拟环境中输入安装指令:pip install requests,可以看到库的具体下载进度条。
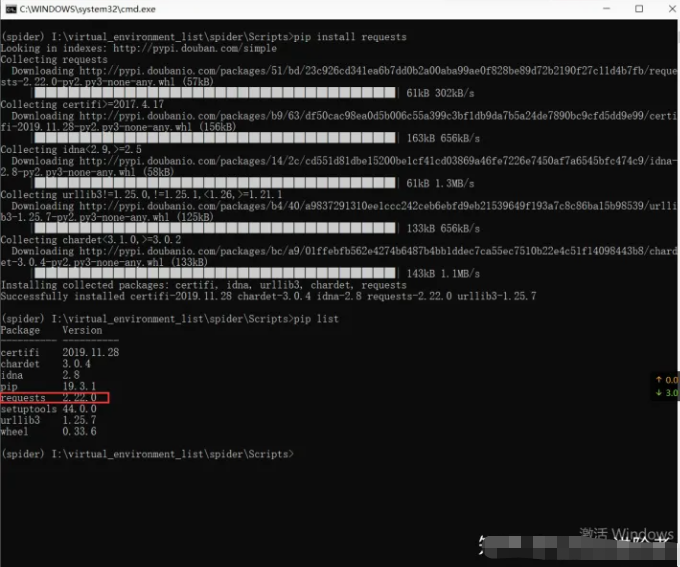
8、Ok,我们创建完了虚拟环境,但是应该怎么退出呢?
直接在虚拟环境中执行deactivate命令,就可以退出虚拟环境了,有的可能需要.bat,有的不需要,如下图所示。

退出之后,我们可以看到左边的(spider)已经没有了,进入到了我们的真实环境。如果我们需要再创建虚拟环境,如法炮制就好了。
这篇文章主要介绍了一下Python的虚拟环境,阐述了虚拟环境的重要以及虚拟环境创建、使用和退出的具体操作步骤,希望对大家入门Python虚拟环境有帮助,后面我会写一篇关于Pycharm下如何使用虚拟环境的教程,教大家在Pycharm中导入虚拟环境,让你的环境不再乱糟糟。
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。


观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

检查学习结果。

我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub