作为一套面向开发和运维团队的解决方案,CI/CD 主要解决集成新代码和向用户频繁交付应用的问题。
更直接地说,就是可以解放开发人员的双手,将时间和精力专注于代码本身。
CI/CD(Continuous Intergration/Continuous Delpoy),持续集成/持续部署,或者持续集成/持续交付(Continuous Delivery),是一种在开发阶段引入自动化来频繁交付应用的方法。从前端的角度看,CICD的流程中涉及:
前后端分离的开发模式中,前端项目经常会使用框架进行开发,经由 Webpack(或者其他构建工具) 打包后的SPA应用(代码),本质上都是静态资源,只需要把它们都放到 Nginx的静态资源目录下,配好相关的路径,即可完成部署。
前端项目的构建、部署、上线流程,从 简陋疏散 到 完善严谨 ,大致经历了以下几个阶段:
yarn build构建项目手动部署操作起来很简单,但缺点也很明显,每次构建完都要人为地进行部署的动作,一方面减少了实际敲代码的时间,另一方面,人工操作免不了会有疏忽出错的时候。
随着工程化的发展和工具链的成熟,项目部署不再像以前简单粗暴。前端代码的健壮性、可靠性越来越被重视,项目发布前往往需要 代码约束 和 代码测试 ,校验通过后服务器拉取最新的代码,进行 build 和 nginx 配置后才算完成整个部署的过程。
yarn lint检查代码是否规范yarn unit进行单元测试git push提交更改到远端仓库git pull拉取最新代码yarn build构建项目这个阶段,我们借助一些工具,能够减少代码不规范或隐藏bug的问题。但所有的操作还是得一行一行命令去敲,项目真正的部署也还是需要手动去操作服务器。
其实完全可以将上面的操作细节都集成到一个 shell 脚本里,通知执行 shell 也能减少很多重复的工作。
上面提到,借助shell也能使得一部分操作自动化,但无论是代码扫描、单元测试还是项目的构建,都还是在本地的开发机上进行(或者说跟开发强耦合),有没有办法将这些附属的操作抽离出来,放到另外的专有环境下进行呢?
现在很流行的 DevOps 理念中,CI/CD的那一环就能很好地实现。
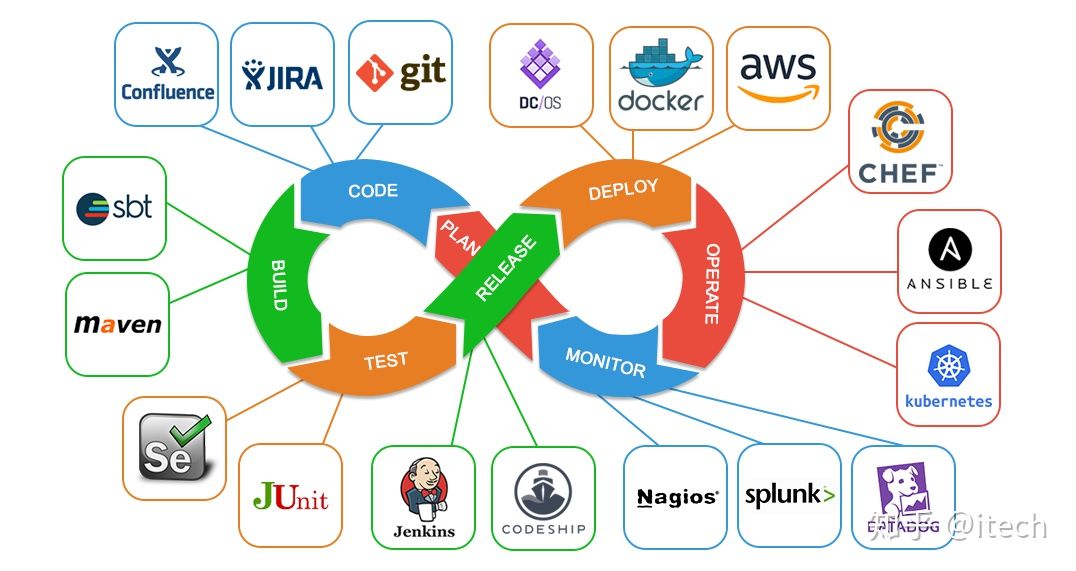
DevOps是一种思想理念,强调软件开发测试运维的一体化,目标是减少各个部门之间的沟通成本,从而实现软件的快速高质量的发布。CI/CD是一套实践方案,实现软件的构建测试部署的自动化。
远程主分支代码发生改变,拉取主分支代码进行构建,完成后通过 ssh 上传到测试/生产服务器。
安装 docker
# 安装 docker 的依赖库,-y 选项表示所有的 Is this OK[y/d/N],都会自动选择y
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加 docker cd 软件源信息
sudo yum-config-manager --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo
# 安装 docker ce
sudo yum install docker-ce
启动 docker
sudo systemctl enable docker # 设置开机自启
sudo systemctl start docker /# 启动docker
docker-compose 用于定义和运行多容器 docker 应用程序,使用 yml 文件配置应用所需的所有服务。
安装 docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
提升权限
sudo chmod +x /usr/local/bin/docker-compos
这里为了方便, nginx 通过容器的方式去启动(不会影响到我目前的 nginx ),jenkins 就还是放在根项目部署的服务器上(方便后续直接通过 shell 复制构建好的项目)
(拉取nginx镜像,编写目录数据卷映射)
拉取 nginx 镜像
docker pull nginx
docker images # 查看安装的镜像
创建数据卷目录,以便挂载到容器里
+ compose # docker-compose 配置目录
- docker-compose.yml
+ nginx
+ conf # nginx 配置
- nginx.conf
+ html # nginx 静态资源
- index.html
编写 docker-compose.yml
version: '3'
services:
cicd_nginx:
restart: always
image: nginx
container_name: nginx
ports:
- 3300:80
- 3301:433
volumes:
- ../nginx/html:/usr/share/nginx/html
- ../nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- ../nginx/log:/var/log/nginx
- ../nginx/localtime:/etc/localtime:ro
启动
docker-compose up -d
docker-compose stop //停止nginx和jenkins
公网查看 nginx
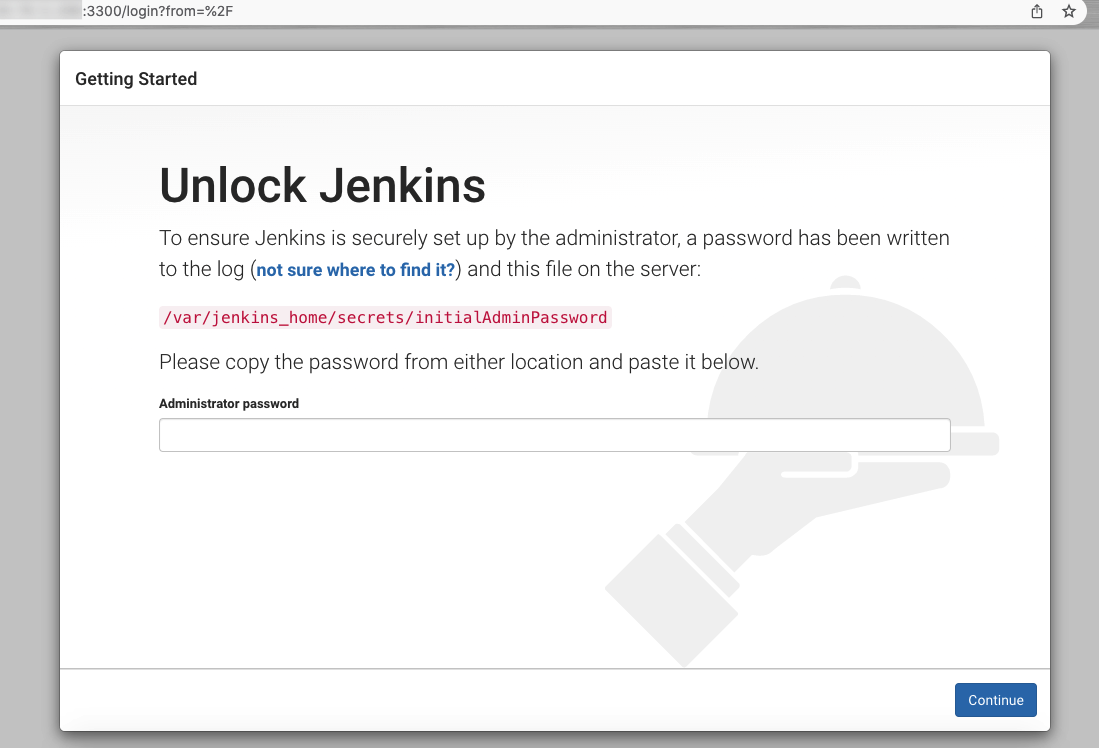
前往 jenkins 容器挂载的数据卷中获得初始密码
cat /home/cicd_demo/jenkins/jenkins_home/secrets/initialAdminPassword
这个密码只会显示一次,之后如果忘记密码需要重置
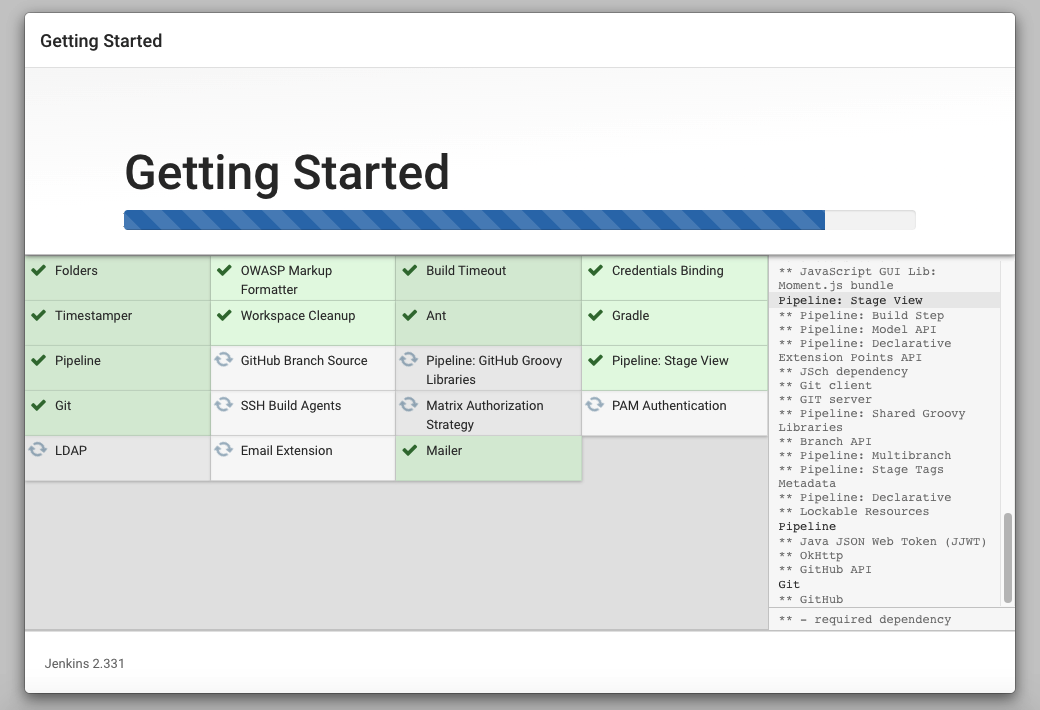
输入密码进入页面之后,选择推荐安装
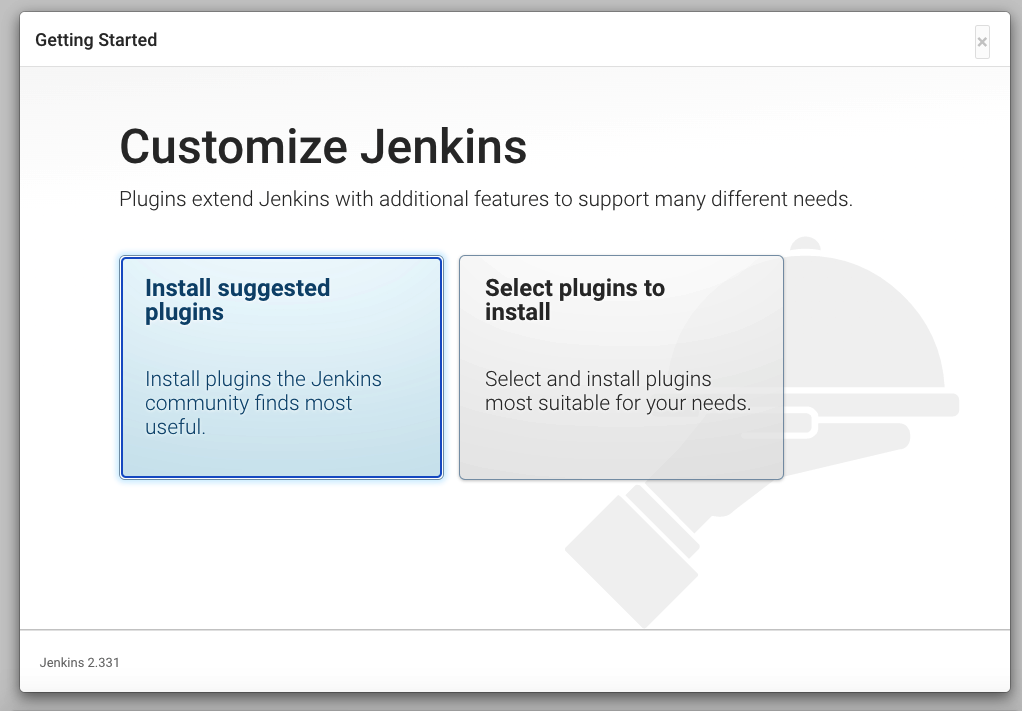
可以看到,jenkins 会自动帮我们安装很多插件,比如最常用的 git
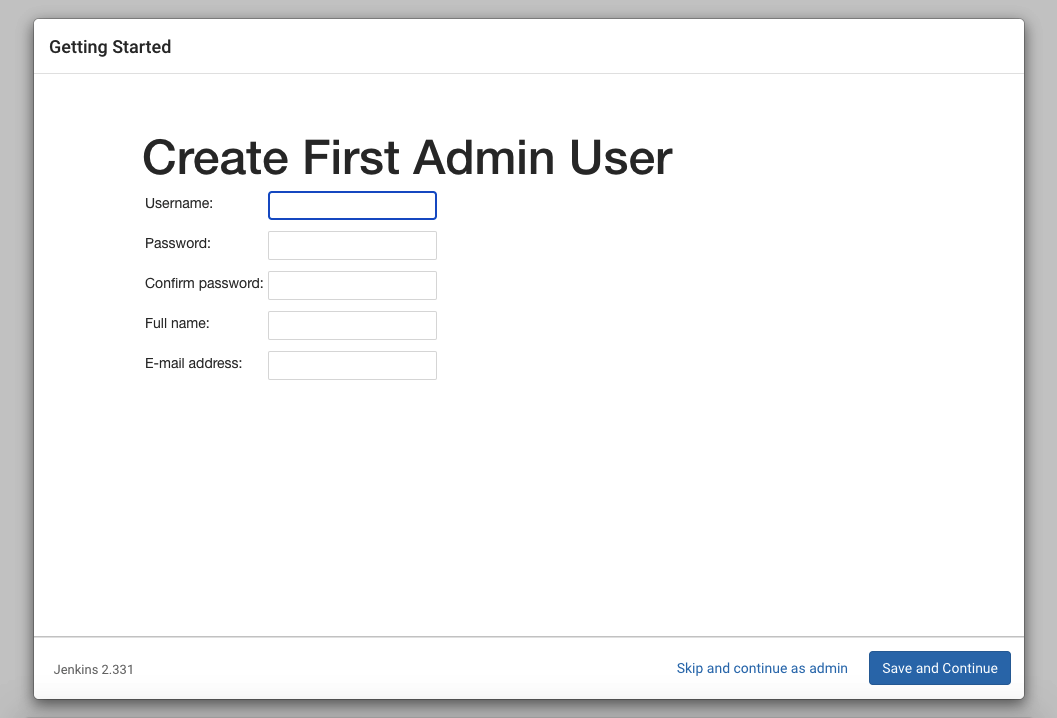
新建账户
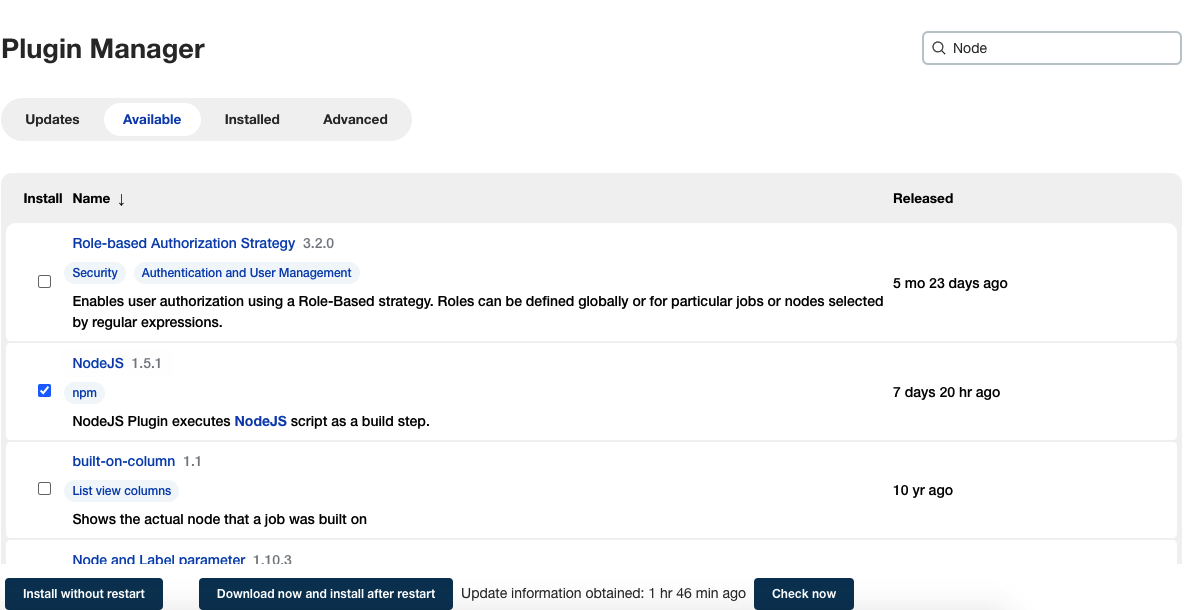
进入到主页后,先前往 Manage Jenkins - Manage Plugins 安装需要用到的插件,目前就只需要安装 NodeJS
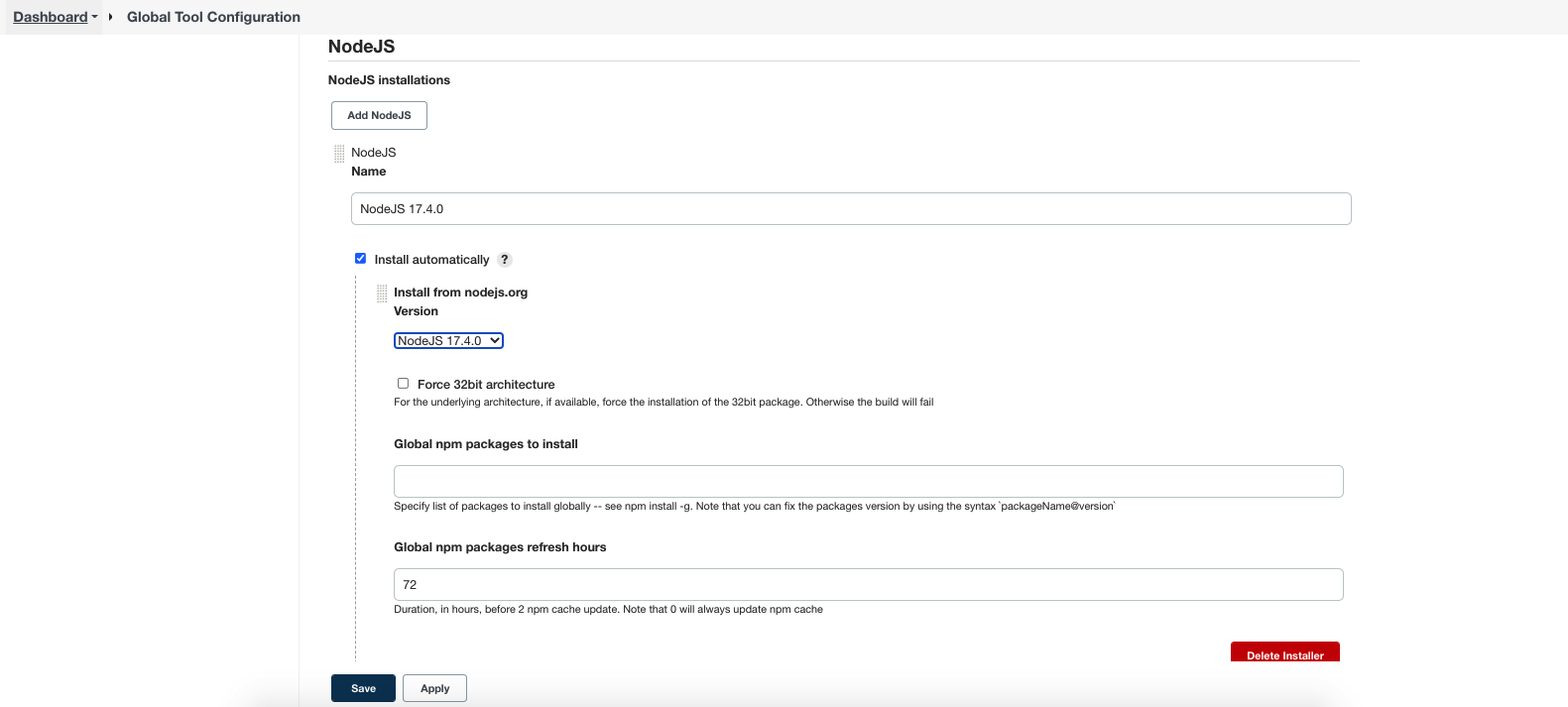
前往全局工具配置,安装需要的不同版本的 node 环境
配置 github
在配置之前,我们先要到 GitHub 生成 Personal access token。
头像 - Settings - Developer settings - Personal access tokens - Generate new token,按下图勾选需要的权限
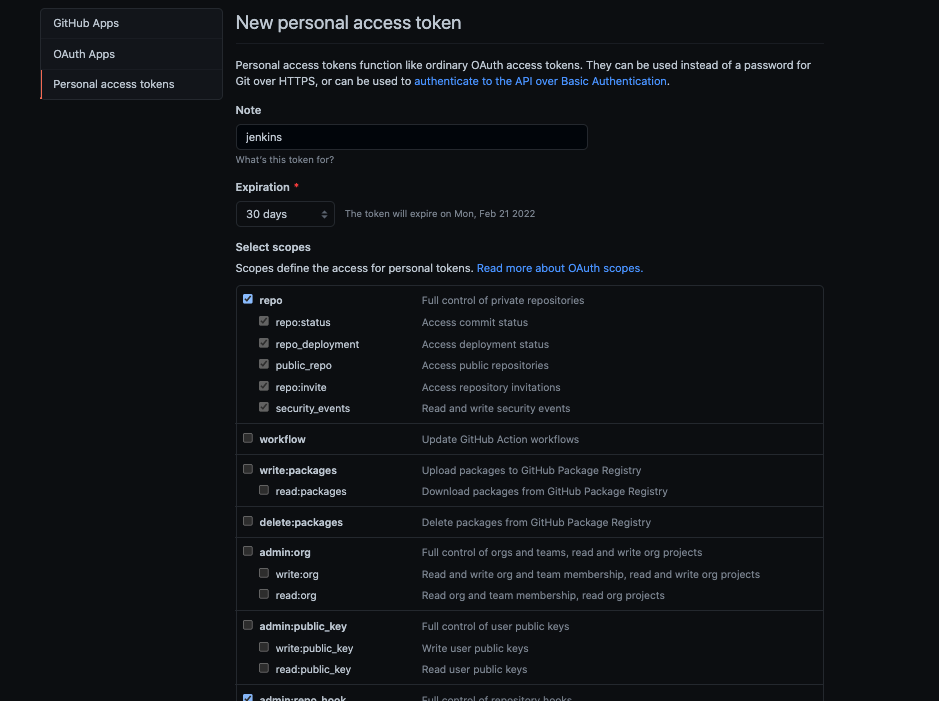
还记得我们要实现的效果吗?当主分支有新的代码提交,就要通知 jenkins 去拉取代码并进行构建。既然是通知,那么肯定就需要用到 Webhook。这里并不需要手动创建 Webhock,jenkins提供的插件会帮我们创建。
接下来继续配置插件,**Manage Jenkisn - Config System - **,找到 Github 配置的部分
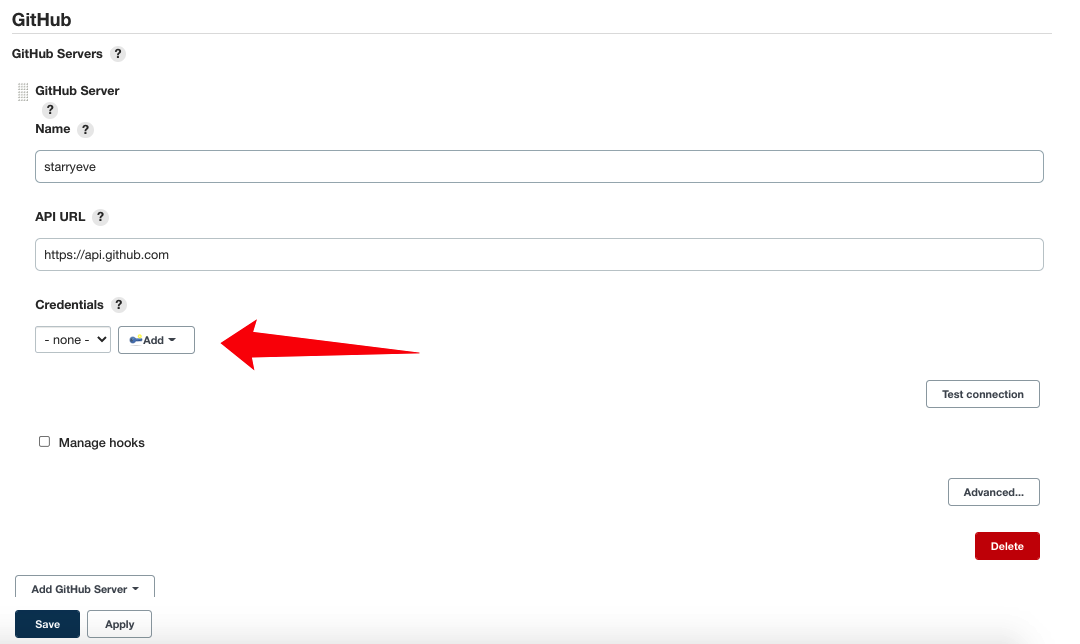
点击添加凭证,选择 Jenkins,点击后会弹出一个添加凭据的窗口,Type 选择为 Secret text,将我们刚才生成的 Personal access token 复制到 Secret 一栏中,点击添加
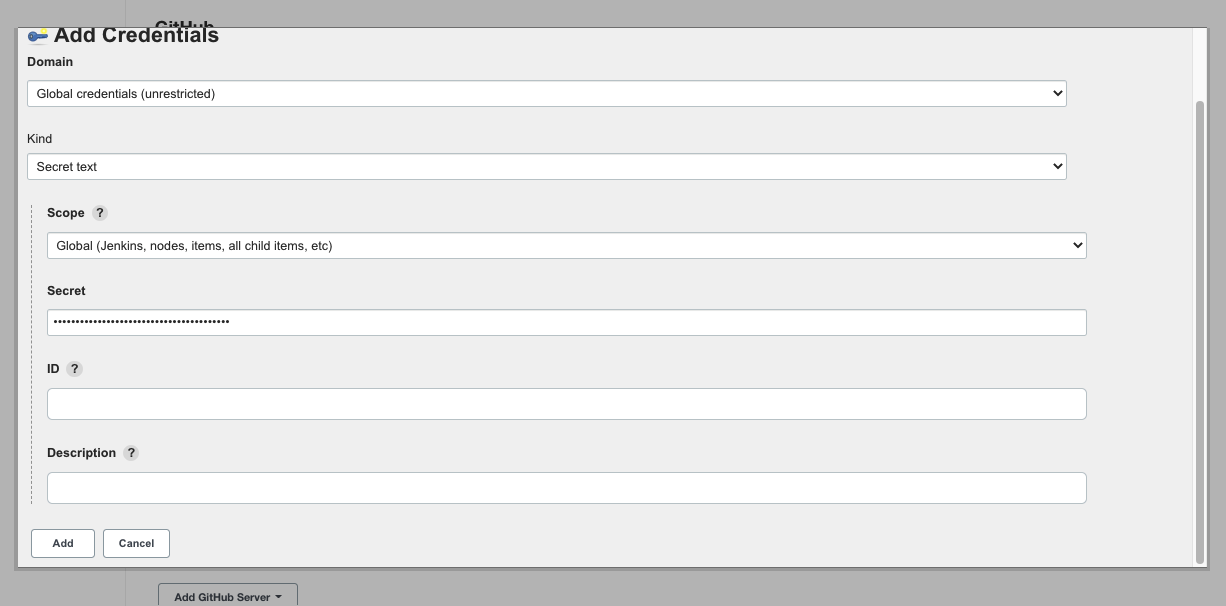
添加后在 Credentials 一栏选中 Secret text,勾选 Manage Hook,点击 Test connection,如果正确显示了GitHub 用户名,就说明配置成功了。
经过上面几步后,就完成了两件事情,Node 环境的配置和 Github Webhock 的添加,下面就可以开始新建任务了。
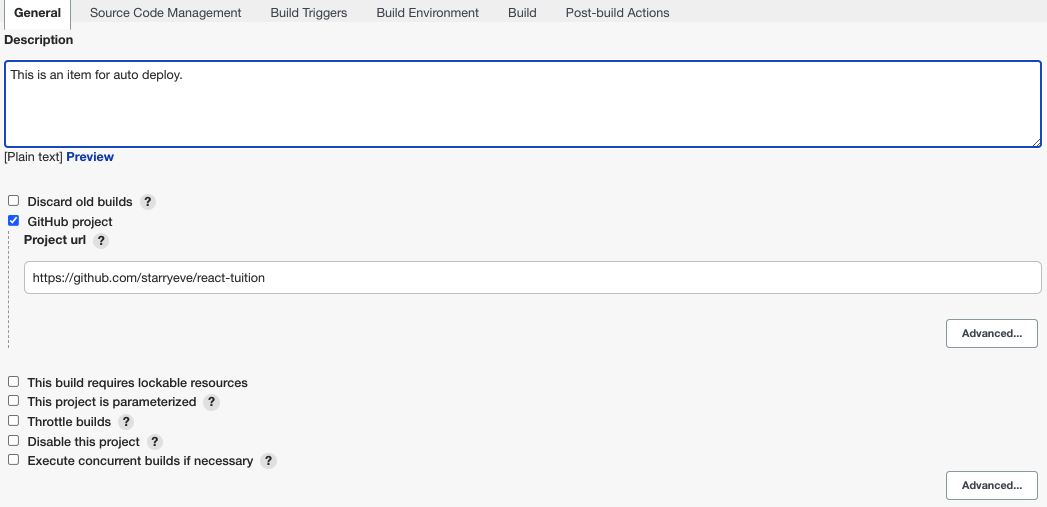
回到首页,新建一个自由风格的任务
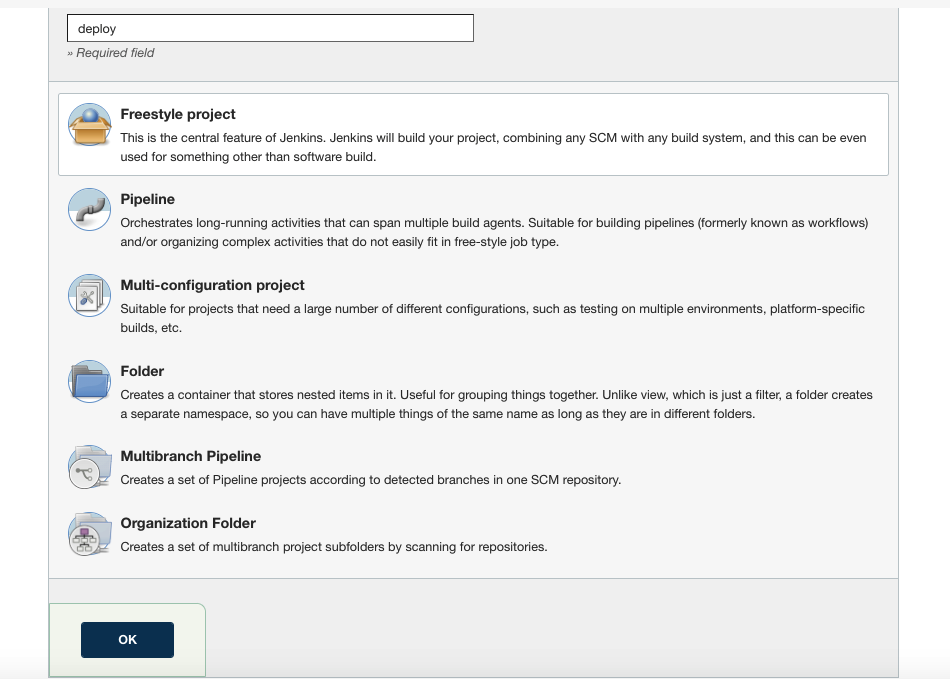
勾选 GitHub project,输入项目地址。将下面的 Source Code Management 选中为 Git,将你要构建部署的项目的 clone 地址填到 Repository URL 一栏中。
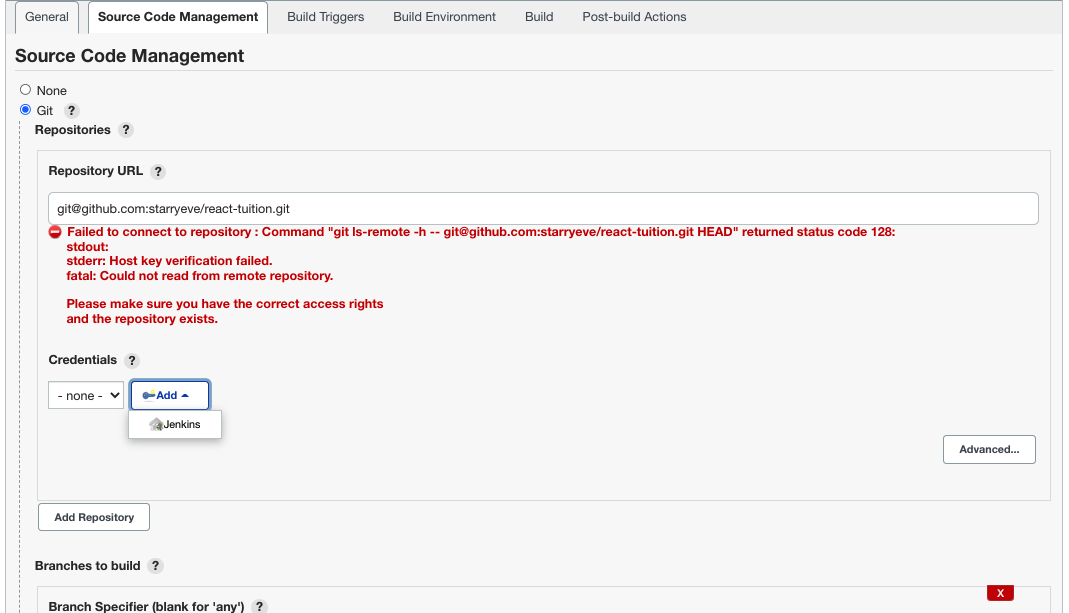
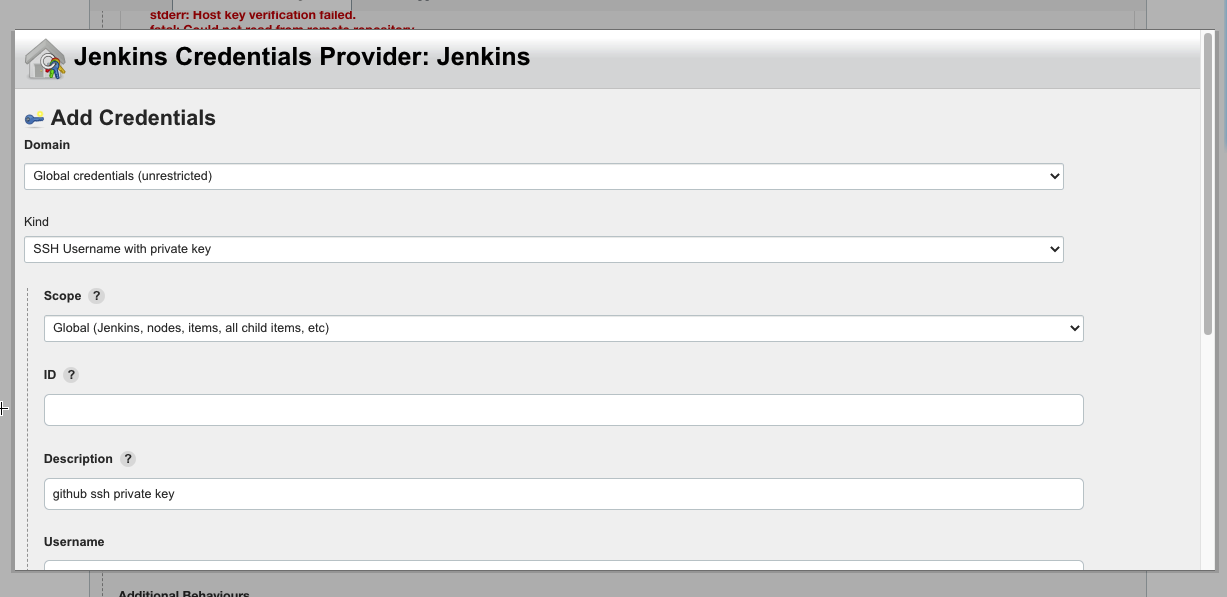
如果是公开的仓库,Credentials可以选择无。这里我准备的是一个私有的仓库,还需要添加一个可以访问访问 Github账户 的凭证,添加方法类似上面配置 Github Webhock 。这里选择 ssh private key的方式
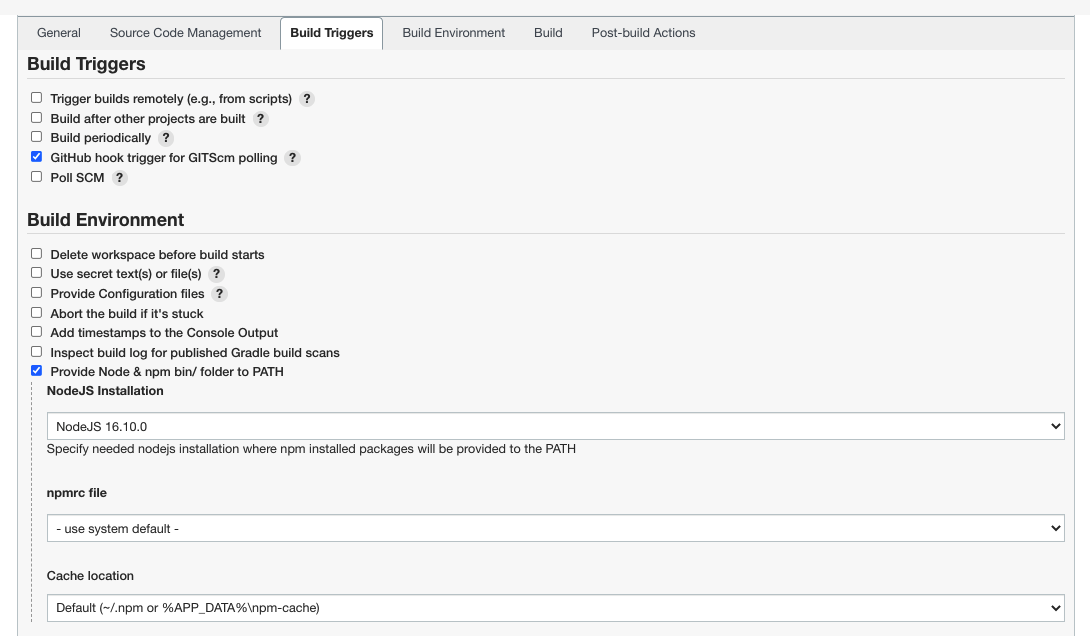
设置构建触发器和构建环境
编写构建shell
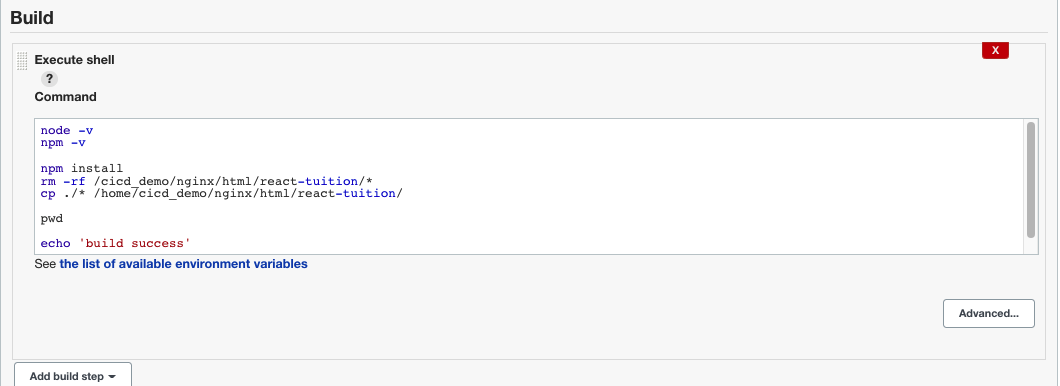
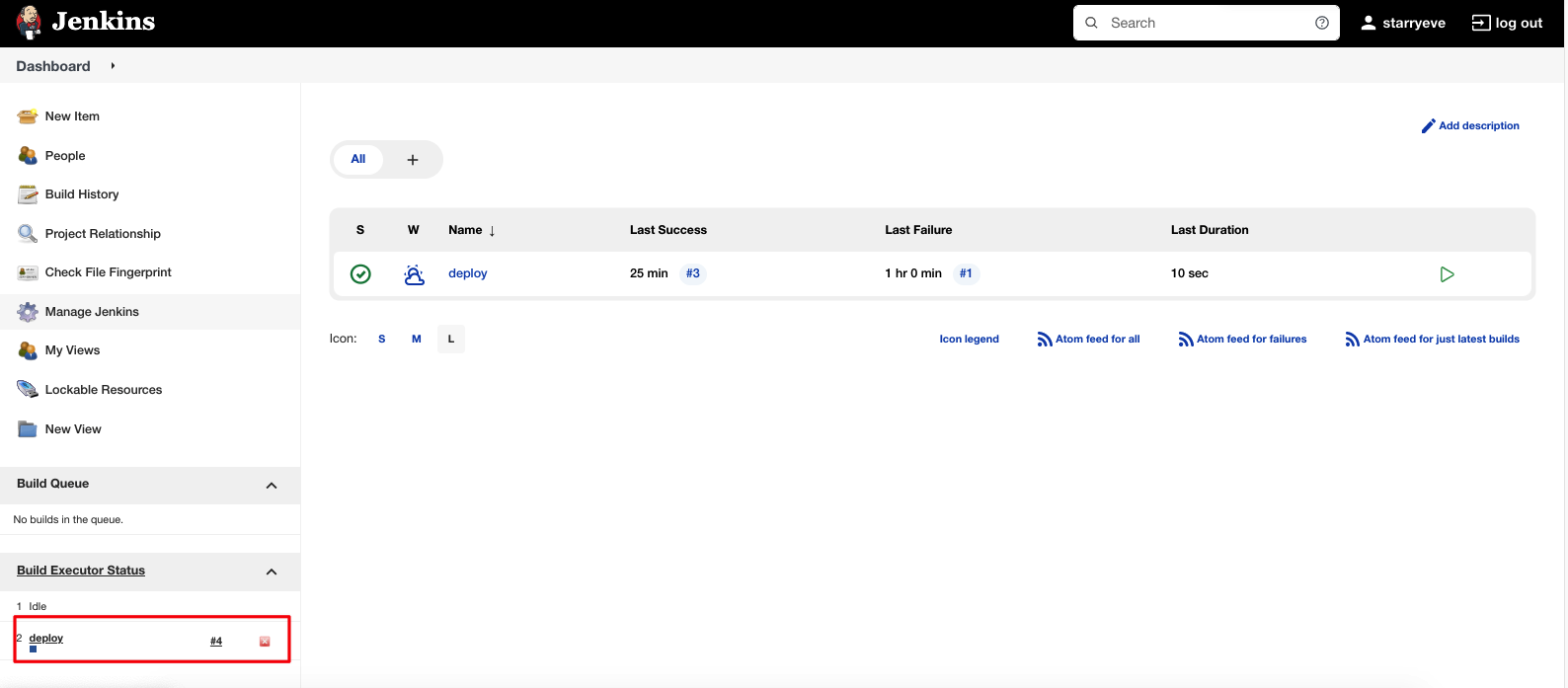
经过上面的步骤,就算完成一个 Item了,当 Github主分支有新的代码提交,就会触发构建:
Github Actions 是 Github 提供的持续集成服务,可以使我们的 repo 获得一些自动化的能力。
举例来说:
每次 repo 有新的提交或 pr 就自动执行 build
在 repo 中定时执行自定义的脚本
将代码打成镜像,自动提交到镜像仓库中
workflow:一次执行过程,每个 workflow 使用一个配置文件维护job:workflow 的分解,可串行存在依赖,也可并行执行step:job 的分解,即具体执行的步骤action:执行过程的封装,可以自定义,也可以使用 Github 社区定义好的 actionartifact:workflow 运行时产生的中间文件,包括日志、测试结果等event:触发 workflow 的事件,也可以理解为生命周期钩子配置 CI/CD 任务的过程本质上是向 runner 描述如下内容:
这里的 workflow 配置文件就是用来做这个工作的
每个 workflow 的配置文件都需要定于 on 字段,用以描述在何种情况下(event)下触发 job 的执行
event 可以分为 3 类:
在这里,我们只会用到最后一种,来描述 git 操作触发的 CI/CD 行为
下面是我在项目中经常使用的部署模板,我给它们加上了详细的注释
name: build and deploy # workflow 名称
on:
push: # push 事件触发
branches: [ dev ] # 只在 dev 分支有新的 push 情况下触发
jobs:
build: # job 名称
runs-on: ubuntu-latest # 执行 workflow 所需的操作系统环境
steps:
- name: checkout
uses: actions/checkout@v2 # 使用切换分支的 action 操作
- name: build
run: yarn && yarn build # 构建命令
- name: deploy
uses: easingthemes/ssh-deploy@main # 使用 ssh 上传文件的 action 操作
env:
SSH_PRIVATE_KEY: ${{ secrets.SERVER_SSH_KEY }} # ssh 密钥对中的私钥
ARGS: "-rltgoDzvO"
SOURCE: "dist" # 要进行上传的文件目录
REMOTE_HOST: ${{ secrets.REMOTE_HOST }} # 服务器主机 ip
REMOTE_USER: ${{ secrets.REMOTE_USER }} # 服务器用户名
TARGET: ${{ secrets.REMOTE_TARGET }} # 要进行部署的生产环境目录
- name: print env
run: printenv # 打印环境变量
- name: build success
if: ${{ success() }} # ${{ }} 可以使用上下文参数,success() 表示当上一步执行成功时返回 true
uses: chf007/action-wechat-work@master # 使用发送企业微信消息的 action
env:
WECHAT_WORK_BOT_WEBHOOK: ${{secrets.WX_WEBHOOK}} # github token,需要自己在 repo 的 settings 中生成
with:
msgtype: news
articles: '[{"title":"💯👨💻 Success Deploy ! 🎉🎉🎉","description":"click here to visit the test site ~","url":"http://xxxx:8080/","picurl":"https://xxxx.com/xxxx/figure-bed/raw/master/images/202203101823814.jpeg"}]'
mentioned_list: '[@all"]'
- name: build failure
if: ${{ failure() }}
uses: chf007/action-wechat-work@master
env:
WECHAT_WORK_BOT_WEBHOOK: ${{secrets.WX_WEBHOOK}}
with:
msgtype: markdown
content: |
# 💤🤷♀️ Deploy Failure 🙅♂️💣
> (⋟﹏⋞) from github action message
mentioned_list: '[@all"]'
注:上面 ssh 部署的方式使用了 rsa 秘钥对中的私钥,不知道怎么生成的话请参考服务器上的-Git-生成-SSH-公钥
name: pull request
on:
pull_request:
branches: [ master, dev ]
jobs:
pr:
runs-on: ubuntu-latest
steps:
- name: checkout
uses: actions/checkout@v2
# 获取 pr 信息,添加到环境变量
- name: set pr info
run: |
echo PR_NUMBER=$(echo $GITHUB_REF | awk 'BEGIN { FS = "/" } ; { print $3 }') >> $GITHUB_ENV
echo PR_FROM=$(echo $GITHUB_HEAD_REF ) >> $GITHUB_ENV
echo PR_TO=$(echo $GITHUB_B_REF ) >> $GITHUB_ENV
echo PR_TITLE=$(jq --raw-output .pull_request.title "$GITHUB_EVENT_PATH") >> $GITHUB_ENV
echo PR_URL=$(jq --raw-output .pull_request.html_url "$GITHUB_EVENT_PATH") >> $GITHUB_ENV
echo PR_USER=$(jq --raw-output .pull_request.user.login "$GITHUB_EVENT_PATH") >> $GITHUB_ENV
echo PR_COMMITS_NUM=$(jq --raw-output .pull_request.commits "$GITHUB_EVENT_PATH") >> $GITHUB_ENV
- name: print env
run: printenv
- name: pull request
uses: chf007/action-wechat-work@master
env:
WECHAT_WORK_BOT_WEBHOOK: ${{secrets.WX_WEBHOOK}}
with:
msgtype: markdown
content: |
# 😍 Pull Request 🤤 ! (^-^)V
> [${{ env.PR_TITLE }} #${{ env.PR_NUMBER }}](${{ env.PR_URL }})
> ${{ env.PR_USER }} wants to merge ${{ env.PR_COMMITS_NUM }} commits
> into <font color=#2F8CDB>${{ env.PR_TO }}</font> from <font color=#008000>${{ env.PR_FROM }}</font>
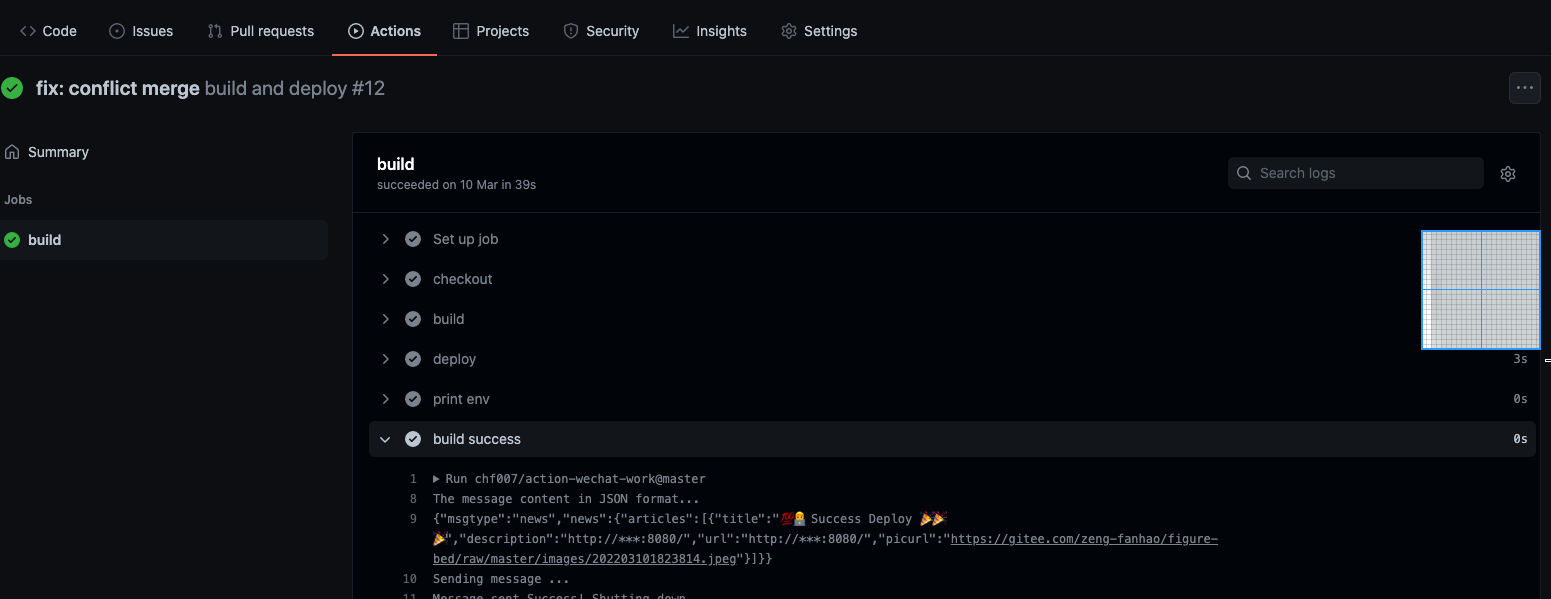
尝试将本地的代码推送到远端,可以看到确实触发了部署的操作
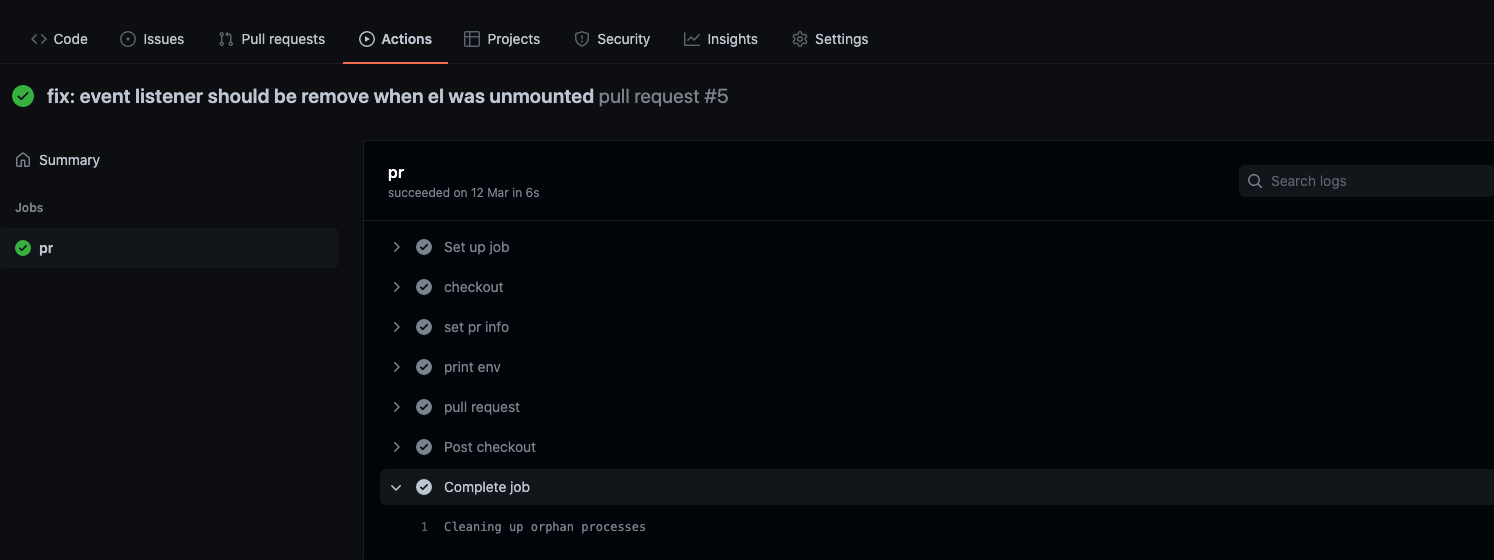
发起一个从开发分支到主分支的合并,同样的,也能触发对应的 workflow
经过以上的步骤,也就实现了一个最小化自动化部署的实践,但这仅仅只是 CI/CD 庞杂管道流程中的一环,很多时候还会结合 docker、k8s、sentry、gitlab等实现多平台协同。上面用到的 Jenkins、Github Actions ,也只是工具中的两种,类似的还有国人开发的 Gitea、Onedev等各类集成了 CI/CD 的代码自建托管平台;企业中,也很有可能会自建一套完整的系统去满足内部的要求。
上面两种方案虽然使用起来很方便,但其内部的实现,想必还是十分复杂的,后面有时间也会继续学习的。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢