二分搜索树遍历分为两大类,深度优先遍历和层序遍历。
深度优先遍历分为三种:先序遍历(preorder tree walk)、中序遍历(inorder tree walk)、后序遍历(postorder tree walk),分别为:
前序遍历结果图示:
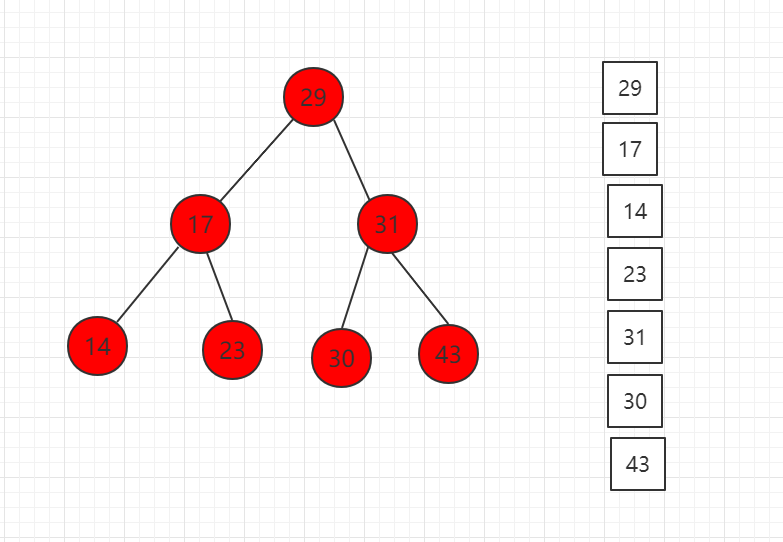
对应代码示例:
中序遍历结果图示:
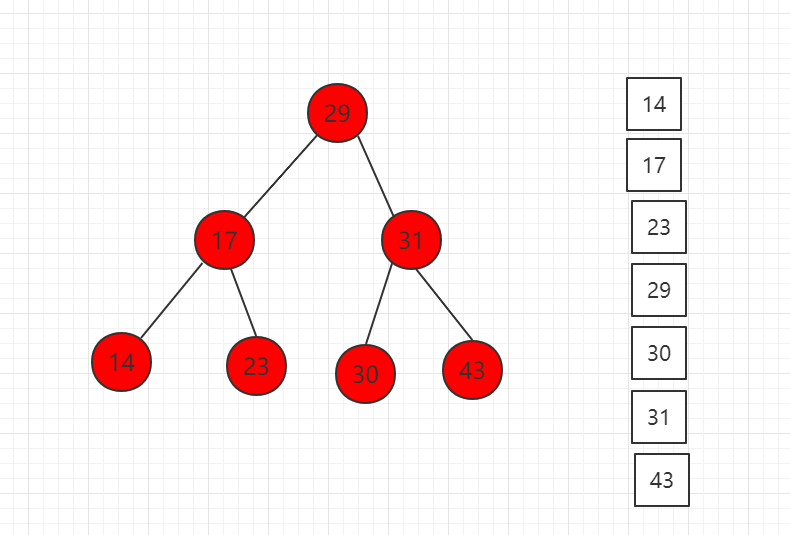
对应代码示例:
后序遍历结果图示:
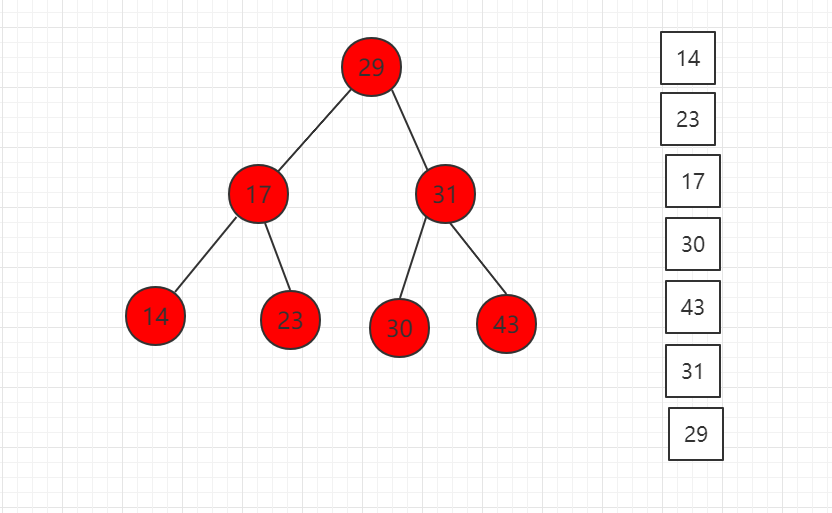
对应代码示例:
源码包下载:Download
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题: