转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/a3a8d0c0.html
你好,我是测试蔡坨坨。
今天,我们来聊聊接口自动化测试是什么?如何开始?接口自动化测试框架怎么做?
自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发展的趋势。
特别是在敏捷模式下,产品迭代速度快,市场不断调整,客户需求不断变化,单纯的手工测试越来越无法适应整个变化过程(迭代快,加班多)。测试人员如何快速响应并保证产品在上线后的质量能够满足市场要求(如何在上线一个新功能的同时快速对旧功能快速进行回归,保证旧功能不被新功能影响而出现严重的Bug?)。
针对以上问题,采用自动化测试无疑是一个不错的选择,能够做到在保证产品质量的同时提升测试效率。
随着行业内卷越来越严重,对于测试岗位的要求也是水涨船高,岗位招聘要求都会出现自动化测试的字眼,因此也是我们跳槽面试、升职加薪必备利器。
自动化测试又可分为接口自动化、Web UI自动化、App自动化,今天我们就来聊聊接口自动化测试。
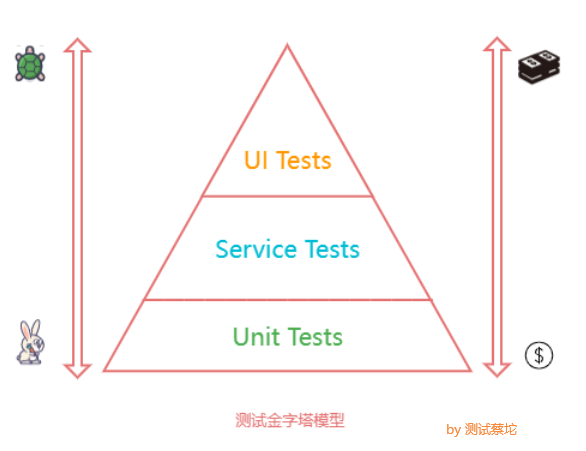
分层测试金字塔模型中,接口测试属于第二层服务集成测试,与UI自动化测试相比,接口自动化测试收益更大、更容易实现、维护成本更低,有更高的投入产出比,因此是公司开展自动化测试的首选。自动化测试工具有很多,每种工具都有各自的优缺点,选择适合自身实际情况的框架,落地实施才是重点,具体选择哪种工具放在其他文章再说。
这里使用 Python + Requests + Pytest + Allure
接口信息:
名称:全国高校信息查询接口
描述:用于查询全国高校信息
Host: www.iamwawa.cn
Request URL:/home/daxue/ajax
Request Method:POST
Content-Type: application/x-www-form-urlencoded
headers:user-agent:Chrome
参数:
| 名称 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
| type | String | 是 | name,根据名称查询 |
| keyword | String | 是 | 高校名称,如:四川轻化工大学 |
请求示例:
POST /home/daxue/ajax HTTP/1.1
Host: www.iamwawa.cn
user-agent: Chrome
Content-Type: application/x-www-form-urlencoded
Cookie: PHPSESSID=sjsrn0drje6ds5fq9kouoo2r23
Content-Length: 54
type=name&keyword=四川轻化工大学
响应示例:
{
"status": 1,
"info": "查询成功!",
"data": [
{
"id": "2181",
"name": "四川轻化工大学",
"code": "4151010622",
"department": "四川省",
"city": "自贡市",
"level": "本科",
"remark": ""
}
]
}
import requests
res = requests.post(url="https://www.iamwawa.cn/home/daxue/ajax",
headers={"user-agent": "Chrome"},
data={"type": "name", "keyword": "四川轻化工大学"})
assert res.status_code == 200
res_json = res.json()
print(res_json)
assert res_json["status"] == 1
使用以上代码,最基础最简单的接口测试就做起来了,好的开始就是成功的一半。
但是,问题也随之而来,线性脚本的缺点也暴露出来了:
所以,下一步就是如何优化线性脚本,也就是如何实现代码的高内聚低耦合,也是接口自动化测试框架要解决的问题。
GitHub开源代码:关注微信公众号 测试蔡坨坨,回复关键字 源码获取
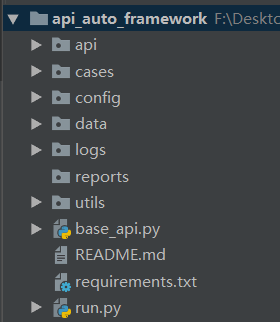
base_api.py:对Requests库进行二次封装,完成对api的驱动
api:继承base_api,将http请求接口封装成Python方法
utils:CommonUtil,公共模块,将一些公共函数、方法以及通用操作进行封装,如:日志模块、yaml操作模块、时间模块
config:配置文件模块,配置信息存放,如:URL、Port、Headers、Token、数据库信息等
data:测试数据模块,用于测试数据的管理,数据与脚本分离,降低维护成本,提高可移植性,如:yml文件数据
cases:测试用例模块,用于测试用例的管理,这里会用到单元测试框架,如:Pytest、Unittest
run.py:批量执行测试用例的主程序,根据不同需求不同场景进行组装,遵循框架的灵活性和扩展性
logs:日志模块,用于记录和管理日志,针对不同情况,设置不同的日志级别,方便定位问题
reports:测试报告模块,用于测试报告的生成和管理,如:基于Allure生成的定制化报告
最后,可以关注公众号 测试蔡坨坨,和坨坨一起学习软件测试,升职加薪 ~
关于软件测试相关问题,都可以添加我微信私信交流:caituotuo666
需要学习资料也可以私信!!!免费获取简历、面试题、自动化测试、测试开发、性能等30种学习资源……
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您