文章目录
IO流的概述:
I 表示intput,是数据从硬盘文件读入到内存的过程,称之输入,负责读。
O 表示output,是内存程序的数据从内存到写出到硬盘文件的过程,称之输出,负责写。

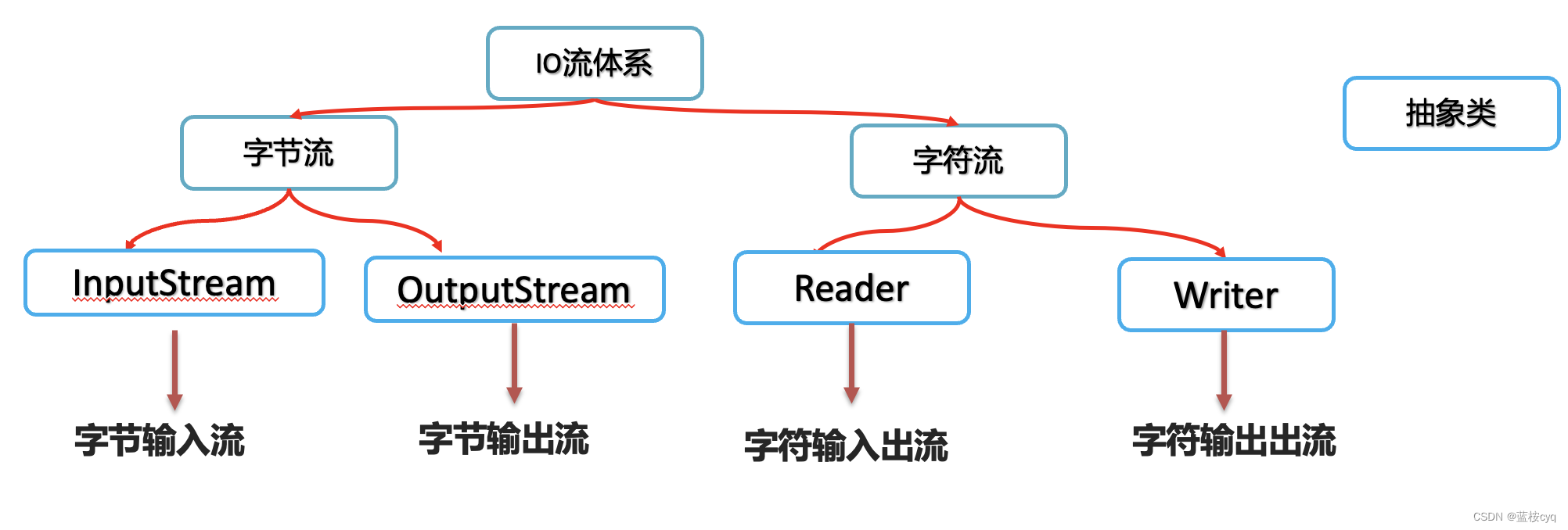
IO流的分类:
按方向分类:
- 输入流
- 输出流
按流中的数据最小单位分为:
- 字节流: 可以操作所有类型的文件(包括音视屏图片等)
- 字符流: 只能操作纯文本的文件(包括java文件, txt文件等)
总结流的四大类:
字节输入流:以内存为基准,来自磁盘文件/网络中的数据以字节的形式读入到内存中去的流称为字节输入流。
字节输出流:以内存为基准,把内存中的数据以字节写出到磁盘文件或者网络中去的流称为字节输出流。
字符输入流:以内存为基准,来自磁盘文件/网络中的数据以字符的形式读入到内存中去的流称为字符输入流。
字符输出流:以内存为基准,把内存中的数据以字符写出到磁盘文件或者网络介质中去的流称为字符输出流。

文件字节输入流: 实现类FileInputStream
作用:以内存为基准,把磁盘文件中的数据以字节的形式读取到内存中去。
构造器如下:
| 构造器 | 说明 |
|---|---|
| public FileInputStream(File file) | 创建字节输入流管道与源文件对象接通 |
| public FileInputStream(String pathname) | 创建字节输入流管道与源文件路径接通 |
示例代码:
public static void main(String[] args) throws FileNotFoundException {
// 写法一: 创建字节输入流与源文件对象接通
InputStream inp = new FileInputStream(new File("/file-io-app/src/test.txt"));
}
public static void main(String[] args) throws FileNotFoundException {
// 写法二: 创建字节输入流管道与源文件路径接通
InputStream inp = new FileInputStream("/file-io-app/src/test.txt");
}
| 方法名称 | 说明 |
|---|---|
| read() | 每次读取一个字节返回,如果字节已经没有可读的返回-1 |
例如我们读取的记事本文件中内容是: abcd123
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
int a = inp.read();
System.out.println(a); // 97
System.out.println((char) a); // a
// 一次输入一个字节
System.out.println(inp.read()); // 98
System.out.println(inp.read()); // 99
System.out.println(inp.read()); // 100
System.out.println(inp.read()); // 49
System.out.println(inp.read()); // 50
System.out.println(inp.read()); // 51
// 无字节可读返回-1
System.out.println(inp.read()); // -1
}
我们可以通过循环遍历出文件中的字节
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
int b;
while ((b = inp.read()) != -1) {
System.out.print((char) b); // abcd123
}
}
每次读取一个字节存在以下问题
性能较慢
读取中文字符输出无法避免乱码问题。
| 方法名称 | 说明 |
|---|---|
| read(byte[] buffer) | 每次读取一个字节数组, 返回读取了几个字节,如果字节已经没有可读的返回-1 |
定义一个字节数组, 用于接收读取的字节数
例如下面代码中, 文件中的内容是: abcd123, 每次读取三个字节, 每一次读取都会覆盖上一次数组中的内容, 但是第三次读取只读取了一个字符, 所以只覆盖了上一次读取的字符数组的第一个元素, 结果是: 312
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个长度为3的字节数组
byte[] arr = new byte[3];
// 第一次读取一个字节数组
int len1 = inp.read(arr);
System.out.println("读取字节数: " + len1); // 读取字节数: 3
// 对字节数组进行解码
String res1 = new String(arr);
System.out.println(res1); // abc
// 第二次读取一个字节数组
int len2 = inp.read(arr);
System.out.println("读取字节数: " + len2); // 读取字节数: 3
// 对字节数组进行解码
String res2 = new String(arr);
System.out.println(res2); // d12
// 第三次读取一个字节数组
int len3 = inp.read(arr);
System.out.println("读取字节数: " + len3); // 读取字节数: 1
// 对字节数组进行解码
String res3 = new String(arr);
System.out.println(res3); // 312
// 无字节可读返回-1
System.out.println(inp.read()); // -1
}
String第二个参数可以指定开始位置, 第三个参数可以指定结束位置, 可以用这两个参数解决第三次读取的弊端
并且循环改进优化代码
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
byte[] arr = new byte[3];
int len;
while ((len = inp.read(arr)) != -1) {
String res = new String(arr, 0, len);
System.out.print(res); // abcd123
}
}
每次读取一个数组存在的弊端:
读取的性能得到了提升
读取中文字符输出无法避免乱码问题。
为解决中文乱码问题我们可以定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。
弊端: 如果文件过大,字节数组可能引起内存溢出。
例如读取如下图这样一个文件

方式一:
自己定义一个字节数组与文件的大小一样大,然后使用读取字节数组的方法,一次性读取完成。
public static void main(String[] args) throws Exception {
File file = new File("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
InputStream inp = new FileInputStream(file);
// 创建一个与文件大小一样的字节数组
byte[] arr = new byte[(int) file.length()];
// 读取文件, 获取读取的字节长度
int len = inp.read(arr);
System.out.println(len); // 252
// 对字节数组进行解码
String res = new String(arr);
System.out.println(res);
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
}
方式二:
官方为字节输入流InputStream提供了如下API可以直接把文件的全部数据读取到一个字节数组中
| 方法名称 | 说明 |
|---|---|
| readAllBytes() | 直接读取当前字节输入流对应的文件对象的全部字节数据, 然后装到一个字节数组返回 |
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 获取文件的全部字节, 并返回一个字节数组
byte[] arr = inp.readAllBytes();
// 对字节数组进行解码
String res = new String(arr);
System.out.println(res);
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
}
文件字节输出流: 实现类FileOutputStream
作用:以内存为基准,把内存中的数据以字节的形式写出到磁盘文件中去的流。
构造器如下:
| 构造器 | 说明 |
|---|---|
| FileOutputStream(File file) | 创建字节输出流管道与源文件对象接通 |
| FileOutputStream(String filepath) | 创建字节输出流管道与源文件路径接通 |
public static void main(String[] args) throws Exception {
// 写法一: 创建输出流与源文件对象接通
OutputStream oup = new FileOutputStream(new File("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt"));
}
public static void main(String[] args) throws Exception {
// 写法二: 创建输出与源文件路径接通(常用)
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
}
文件字节输出流写数据出去的API:
| 方法名称 | 说明 |
|---|---|
| write(int a) | 写一个字节出去 |
| write(byte[] buffer) | 写一个字节数组出去 |
| write(byte[] buffer , int pos , int len) | 写一个字节数组的一部分出去。 |
流的刷新与关闭API:
| 方法 | 说明 |
|---|---|
| flush() | 刷新流,还可以继续写数据 |
| close() | 关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据 |
注意: 写入数据必须刷新数据, 流使用完成后需要关闭
写一个字节出去
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
oup.write('a');
// 支持写入编码
oup.write(97);
// 汉字占三个字节, 所以该方法不可以写入汉字
// oup.write('我');
// 写数据必须刷新数据
oup.flush();
// 刷新流后可以继续写入数据
oup.write('b');
// 使用完后需要关闭流, 关闭后不能再写入数据
oup.close();
}
写一个字节数组出去
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {'a', 98, 'b', 'c'};
// 写入中文, 需要将中文编码成字节数组
byte[] chinese = "中国".getBytes();
// 写入英文字节数组
oup.write(arr);
// 写入中文字节数组
oup.write(chinese);
// 关闭流(关闭之前会刷新)
oup.close();
}
写入一个字节数组的一部分
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {'a', 98, 'b', 'c'};
// 写入数组的第二个和第三个元素
oup.write(arr, 1, 2);
// 关闭流(关闭之前会刷新)
oup.close();
}
补充知识:
补充一: 写入内容时, 如果需要换行可将
\r\n(window支持输入\n但是有些系统不支持, 为了具备通用性使用\r\n)转为字节数组写入, 实现换行效果
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {'a', 98, 'b', 'c'};
oup.write(arr);
// 写入换行
oup.write("\r\n".getBytes());
// 写入数组的第二个和第三个元素
oup.write(arr, 1, 2);
// 关闭流(关闭之前会刷新)
oup.close();
}
补充二: 当写入文件时, 会先将原来文件清空, 再写入新的数据, 如果我们想在原来文件数据的基础上追加新的数据, 这时候就需要将构造器的第二个参数设置为true
| 构造器 | 说明 |
|---|---|
| FileOutputStream(File file,boolean append) | 创建字节输出流管道与源文件对象接通,可追加数据 |
| FileOutputStream(String filepath,boolean append) | 创建字节输出流管道与源文件路径接通,可追加数据 |
public static void main(String[] args) throws Exception {
// 设置为true即可
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt", true);
}
需求:
把test.pdf文件复制到其他目录下的newtest.pdf文件中
思路分析:
根据数据源创建字节输入流对象
根据目的地创建字节输出流对象
读写数据,复制视频
释放资源
示例代码:
public static void main(String[] args) {
try {
// 创建要复制文件的字节输入流
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.pdf");
// 创建目标路径的字节输出流
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/newtest.pdf");
// 使用文件输入流获取要复制文件的全部数据的字节数组
byte[] arr = inp.readAllBytes();
// 使用文件输出流将字节数组写入目标文件
oup.write(arr);
System.out.println("复制成功!");
// 释放资源
inp.close();
oup.close();
} catch (IOException e) {
e.printStackTrace();
}
}
疑问: 字节流可以拷贝什么类型的文件?
任何文件的底层都是字节,拷贝是一字不漏的转移字节,只要前后文件格式、编码一致没有任何问题。
总结: 字节流适合拷贝文件, 但是不适合进行中文的输出输出
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po