| IP地址 | 主机名称 | 角色 |
|---|---|---|
| 10.0.0.5 | node1 | JournalNode、NameNode、ResourceManager |
| 10.0.0.6 | node2 | JournalNode、NameNode、ResourceManager |
| 10.0.0.7 | node3 | JournalNode、DataNode、NodeManager |
| 10.0.0.8 | node4 | DataNode、NodeManager |
| 10.0.0.9 | node5 | DataNode、NodeManager |
sudo apt-get update
sudo apt-get install -y openjdk-8-jdk
vi ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
source ~/.bashrc
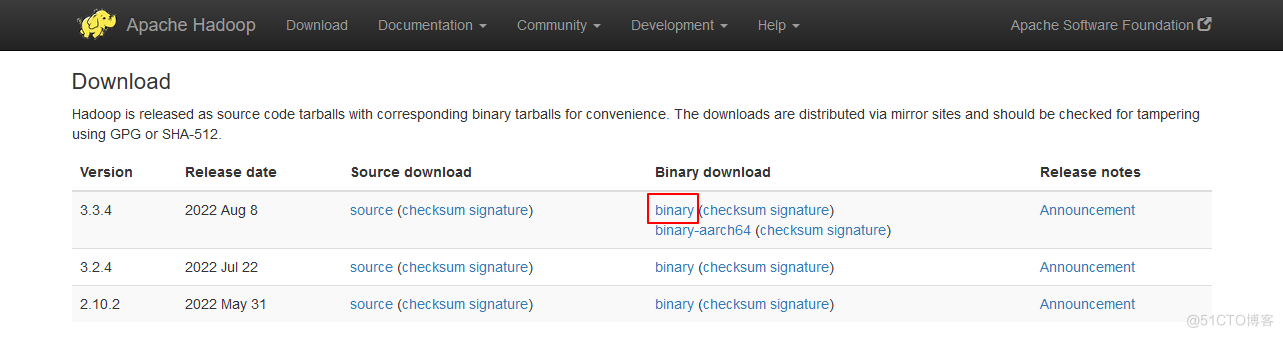 或者直接通过命令下载。
或者直接通过命令下载。
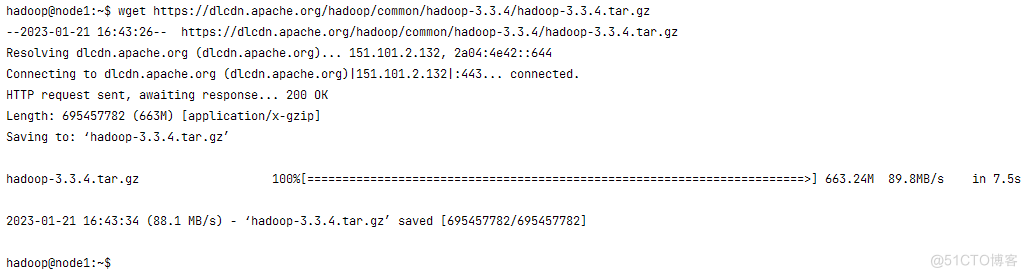
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
/etc/hosts。
由于该配置文件的修改需要root权限,所以在每个节点上都手动配置。
10.0.0.5 node1
10.0.0.6 node2
10.0.0.7 node3
10.0.0.8 node4
10.0.0.8 node5
以下配置过程在node1上完成,并且配置完成后将配置文件复制到其他节点。
hadoop@node1:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:pp2AC1bQAQ5J6CJJCij1QA7bgKOsVxpoPVNi+cxhcyg hadoop@node1
The key's randomart image is:
+---[RSA 3072]----+
|O=*oo.. |
|OX E.* . |
|X+* @ + |
|B+.=.= |
|= o++ . S |
|..o. . = . |
| . . . o |
| |
| |
+----[SHA256]-----+
hadoop@node1:~$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
hadoop@node1:~$ scp -r .ssh node1:~/
id_rsa.pub 100% 566 1.7MB/s 00:00
authorized_keys 100% 566 2.0MB/s 00:00
known_hosts 100% 1332 4.5MB/s 00:00
id_rsa 100% 2602 10.1MB/s 00:00
hadoop@node1:~$ scp -r .ssh node2:~/
hadoop@node2's password:
id_rsa.pub 100% 566 934.6KB/s 00:00
authorized_keys 100% 566 107.3KB/s 00:00
known_hosts 100% 1332 2.5MB/s 00:00
id_rsa 100% 2602 4.8MB/s 00:00
hadoop@node1:~$ scp -r .ssh node3:~/
hadoop@node3's password:
id_rsa.pub 100% 566 1.0MB/s 00:00
authorized_keys 100% 566 1.3MB/s 00:00
known_hosts 100% 1332 2.8MB/s 00:00
id_rsa 100% 2602 5.2MB/s 00:00
hadoop@node1:~$ scp -r .ssh node4:~/
hadoop@node3's password:
id_rsa.pub 100% 566 1.0MB/s 00:00
authorized_keys 100% 566 1.3MB/s 00:00
known_hosts 100% 1332 2.8MB/s 00:00
id_rsa 100% 2602 5.2MB/s 00:00
hadoop@node1:~$ scp -r .ssh node5:~/
hadoop@node3's password:
id_rsa.pub 100% 566 1.0MB/s 00:00
authorized_keys 100% 566 1.3MB/s 00:00
known_hosts 100% 1332 2.8MB/s 00:00
id_rsa 100% 2602 5.2MB/s 00:00
hadoop@node1:~$ ssh node1
hadoop@node1:~$ ssh node2
hadoop@node1:~$ ssh node3
hadoop@node1:~$ ssh node4
hadoop@node1:~$ ssh node5
hadoop@node1:~$ mkdir -p apps
hadoop@node1:~$ tar -xzf hadoop-3.3.4.tar.gz -C apps
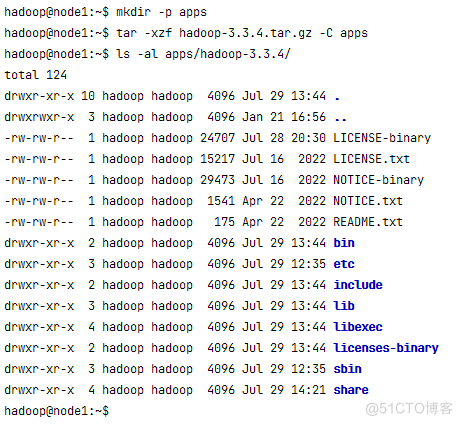 bin目录下存放的是Hadoop相关的常用命令,比如操作HDFS的hdfs命令,以及hadoop、yarn等命令。
etc目录下存放的是Hadoop的配置文件,对HDFS、MapReduce、YARN以及集群节点列表的配置都在这个里面。
sbin目录下存放的是管理集群相关的命令,比如启动集群、启动HDFS、启动YARN、停止集群等的命令。
share目录下存放了一些Hadoop的相关资源,比如文档以及各个模块的Jar包。
bin目录下存放的是Hadoop相关的常用命令,比如操作HDFS的hdfs命令,以及hadoop、yarn等命令。
etc目录下存放的是Hadoop的配置文件,对HDFS、MapReduce、YARN以及集群节点列表的配置都在这个里面。
sbin目录下存放的是管理集群相关的命令,比如启动集群、启动HDFS、启动YARN、停止集群等的命令。
share目录下存放了一些Hadoop的相关资源,比如文档以及各个模块的Jar包。
hadoop@node1:~$ vi ~/.bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.4
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
hadoop@node1:~$ source ~/.bashrc
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.4
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export HADOOP_LOG_DIR=/home/hadoop/logs/hadoop
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://wuxlabs</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop/temp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
<final>false</final>
</property>
</configuration>
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>wuxlabs</value>
<final>false</final>
</property>
<property>
<name>dfs.ha.namenodes.wuxlabs</name>
<value>nn1,nn2</value>
<final>false</final>
</property>
<property>
<name>dfs.namenode.rpc-address.wuxlabs.nn1</name>
<value>node1:8020</value>
<final>false</final>
</property>
<property>
<name>dfs.namenode.rpc-address.wuxlabs.nn2</name>
<value>node2:8020</value>
<final>false</final>
</property>
<property>
<name>dfs.namenode.http-address.wuxlabs.nn1</name>
<value>node1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.wuxlabs.nn2</name>
<value>node2:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/wuxlabs</value>
<final>false</final>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.wuxlabs</name>
<value>true</value>
<final>false</final>
</property>
<property>
<name>dfs.client.failover.proxy.provider.wuxlabs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<final>false</final>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/hadoop/journal</value>
<final>false</final>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<final>false</final>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>wuxlabs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/workers
node3
node4
node5
hadoop@node1:~$ scp -r .bashrc apps node2:~/
hadoop@node1:~$ scp -r .bashrc apps node3:~/
hadoop@node1:~$ scp -r .bashrc apps node4:~/
hadoop@node1:~$ scp -r .bashrc apps node5:~/
hadoop@node1:~$ hdfs --daemon start journalnode
hadoop@node1:~$ hdfs namenode -format
hadoop@node1:~$ hdfs --daemon start namenode

hadoop@node1:~$ hdfs zkfc -formatZK
hadoop@node2:~$ hdfs namenode -bootstrapStandby
hadoop@node2:~$ hdfs --daemon start namenode

hadoop@node1:~$ stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [node1 node2]
Stopping datanodes
Stopping journal nodes [node2 node3 node1]
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Stopping nodemanagers
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node4: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node3: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node5: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Stopping resourcemanagers on [ node1 node2]
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node1: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node2: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
hadoop@node1:~$ jps
275701 Jps
214989 QuorumPeerMain
hadoop@node1:~$ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [node1 node2]
Starting datanodes
Starting journal nodes [node2 node3 node1]
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Starting resourcemanagers on [ node1 node2]
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node1: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node2: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Starting nodemanagers
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node4: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node5: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node3: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
hadoop@node1:~$ jps
278677 NameNode
280787 Jps
279688 ResourceManager
214989 QuorumPeerMain
279115 JournalNode
hadoop@node1:~$ jps
278677 NameNode
280787 Jps
279688 ResourceManager
214989 QuorumPeerMain
279115 JournalNode
hadoop@node2:~$ jps
208369 QuorumPeerMain
264902 JournalNode
265264 ResourceManager
267858 Jps
264569 NameNode
hadoop@node3:~$ jps
215379 QuorumPeerMain
281221 Jps
278194 NodeManager
277487 DataNode
277754 JournalNode
hadoop@node4:~$ jps
183811 DataNode
187559 Jps
184343 NodeManager
hadoop@node5:~$ jps
186215 NodeManager
189848 Jps
185704 DataNode
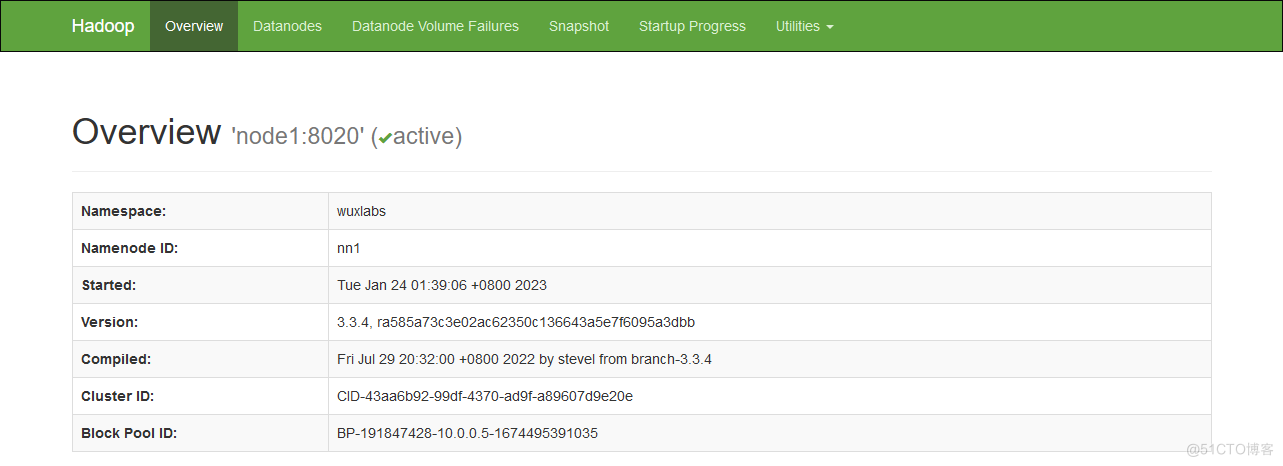
hadoop@node1:~$ hdfs --daemon start zkfc
hadoop@node2:~$ hdfs --daemon start zkfc
hadoop@node1:~$ hdfs dfs -put .bashrc /
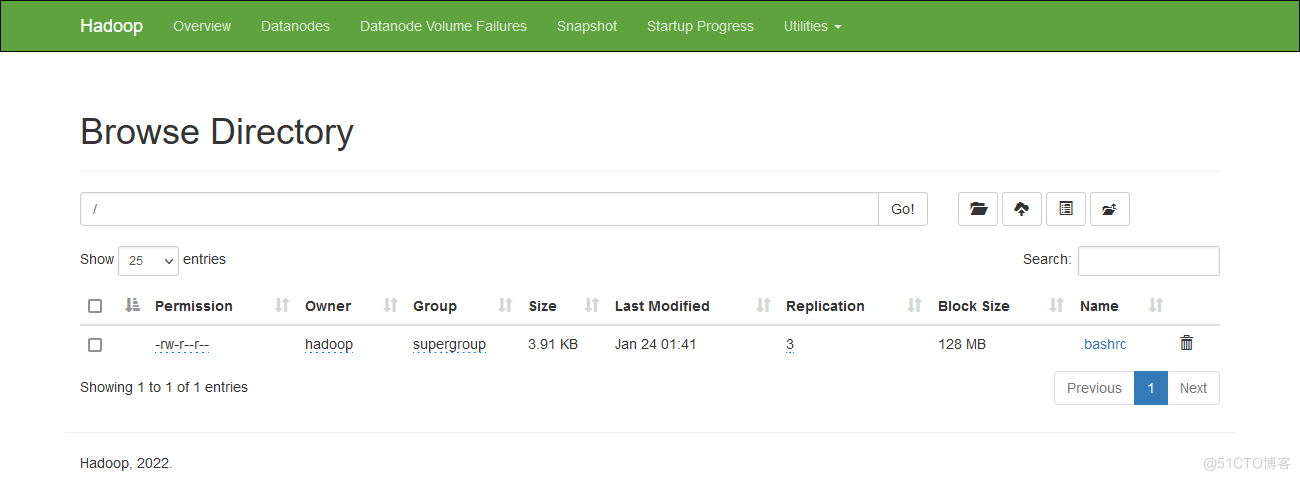 打开node2的HDFS Web UI查看相关信息,默认端口9870,由于状态是standby的,所以不能操作。
打开node2的HDFS Web UI查看相关信息,默认端口9870,由于状态是standby的,所以不能操作。
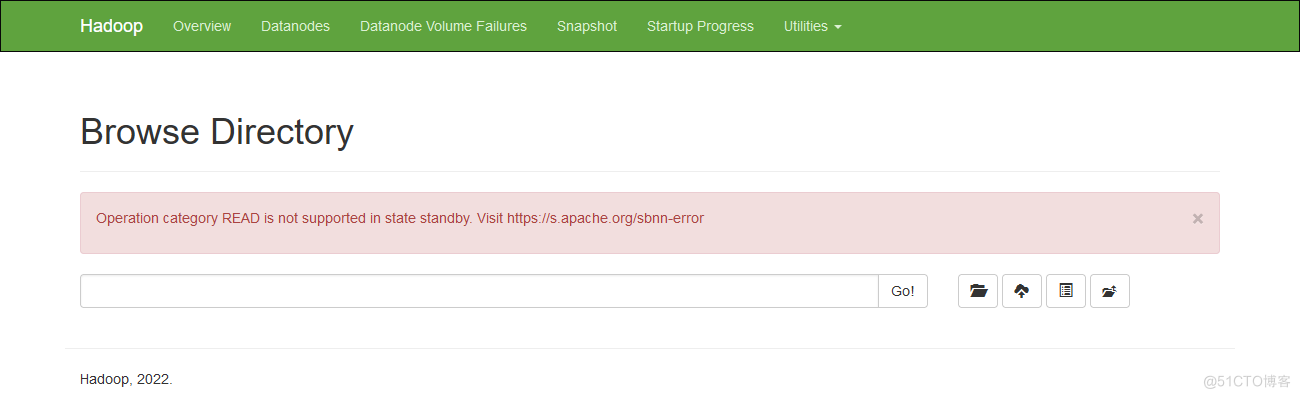
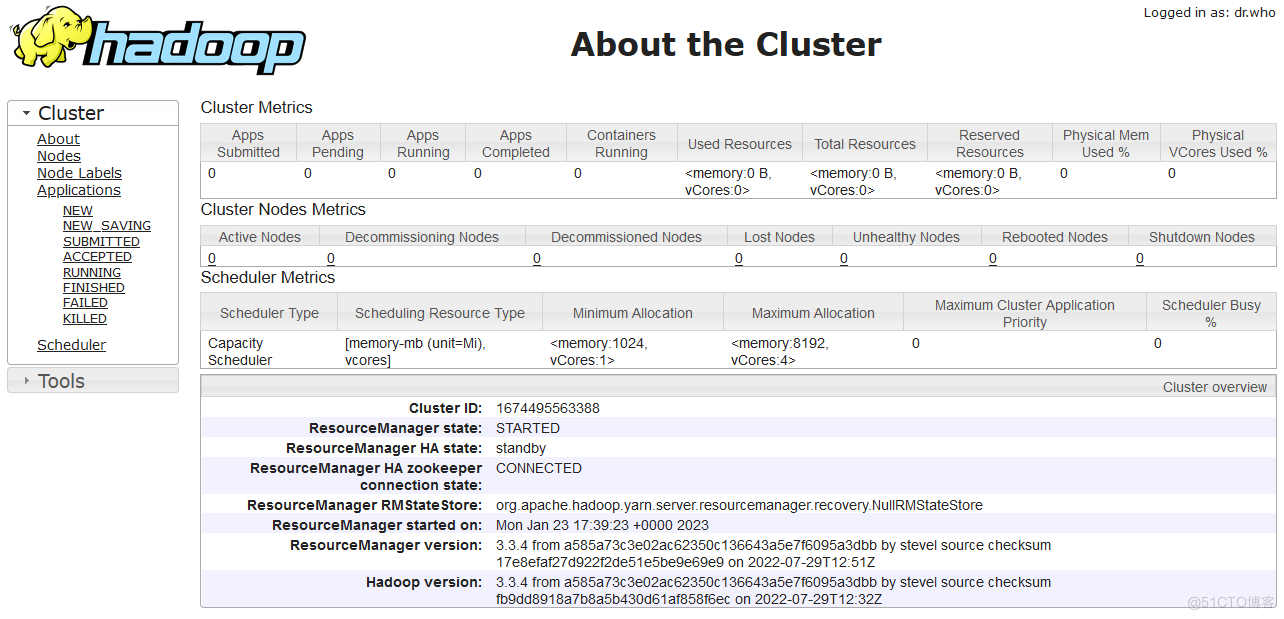 打开node2的YARN Web UI查看相关信息,默认端口8088,状态是active的。
打开node2的YARN Web UI查看相关信息,默认端口8088,状态是active的。
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
Client Commands:
classpath prints the class path needed to get the hadoop jar and the required libraries
dfs run a filesystem command on the file system
envvars display computed Hadoop environment variables
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
lsSnapshottableDir list all snapshottable dirs owned by the current user
snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot
version print the version
hdfs haadmin -transitionToActive --forcemanual nn1
hdfs haadmin -transitionToStandby --forcemanual nn2
Usage: yarn [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or yarn [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
Client Commands:
applicationattempt prints applicationattempt(s) report
app|application prints application(s) report/kill application/manage long running application
classpath prints the class path needed to get the hadoop jar and the required libraries
cluster prints cluster information
container prints container(s) report
envvars display computed Hadoop environment variables
fs2cs converts Fair Scheduler configuration to Capacity Scheduler (EXPERIMENTAL)
jar <jar> run a jar file
logs dump container logs
nodeattributes node attributes cli client
queue prints queue information
schedulerconf Updates scheduler configuration
timelinereader run the timeline reader server
top view cluster information
version print the version
hadoop@node1:~$ hdfs dfs -mkdir /input
hadoop@node1:~$ hdfs dfs -put apps/hadoop-3.3.4/etc/hadoop/*.xml /input/
hadoop@node1:~$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep /input /output 'dfs[a-z.]+'
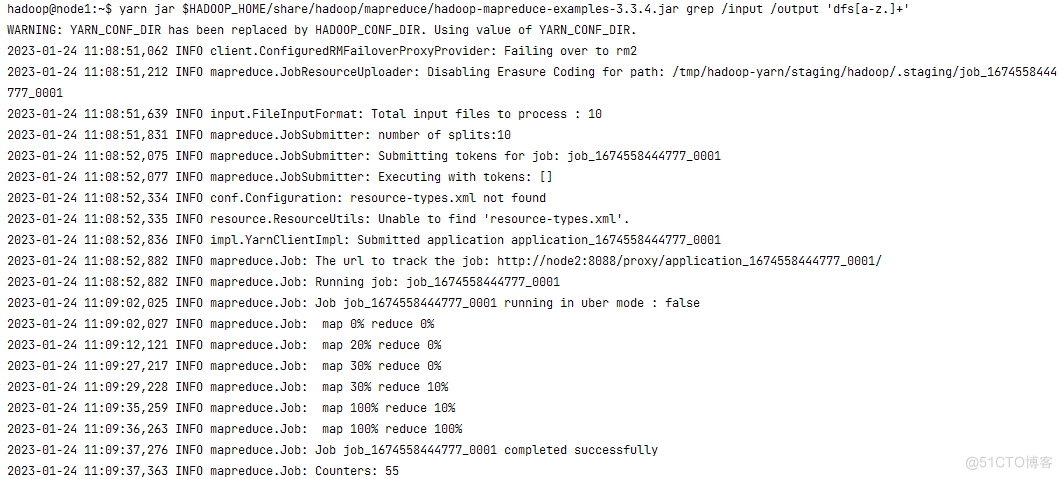 在YARN上可以看到提交的Job。
在YARN上可以看到提交的Job。
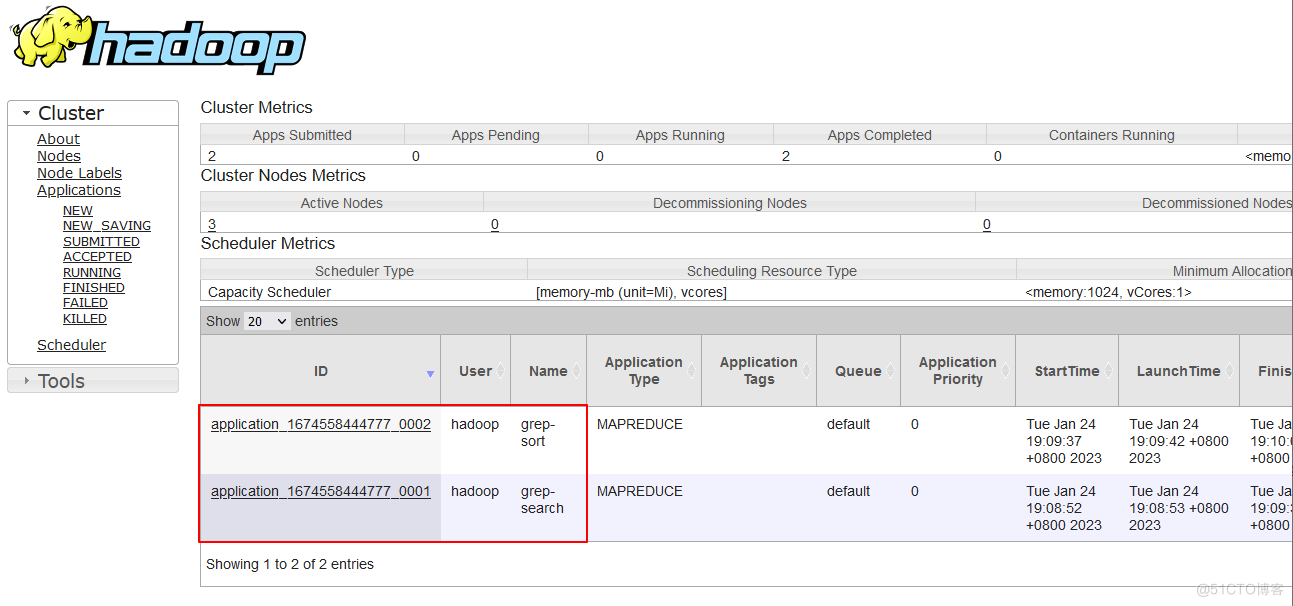 执行结果为:
执行结果为:
hadoop@node1:~$ hdfs dfs -cat /output/*
2 dfs.namenode.http
2 dfs.namenode.rpc
1 dfsadmin
1 dfs.server.namenode.ha.
1 dfs.replication
1 dfs.permissions
1 dfs.nameservices
1 dfs.namenode.shared.edits.dir
1 dfs.namenode.name.dir
1 dfs.journalnode.edits.dir
1 dfs.ha.namenodes.wuxlabs
1 dfs.ha.fencing.ssh.private
1 dfs.ha.fencing.methods
1 dfs.ha.automatic
1 dfs.datanode.data.dir
1 dfs.client.failover.proxy.provider.wuxlabs
hadoop@node1:~$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 10 10
hadoop@node1:~$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 10 10
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
... ...
Job Finished in 35.017 seconds
Estimated value of Pi is 3.20000000000000000000
hadoop@node1:~$ kill -9 278677
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel