1、什么是DataSource数据源
javax.sql.DataSource是由JDBC2.0 提供的接口,它负责建立与数据库的连接,当在应用程序中访问数据库时不必编写连接数据库的代码,直接引用DataSource获取数据库的连接对象即可。用于获取操作数据Connection对象
2、数据库连接池
当我们使用数据源建立多个数据库连接,这些数据库连接会保存在数据库连接池中,当需要访问数据库时,只需要从数据库连接池中获取空闲的数据库连接,当程序访问数据库结束时,数据库连接会放回数据库连接池中
首先我们需要导入JDBC相关场景
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
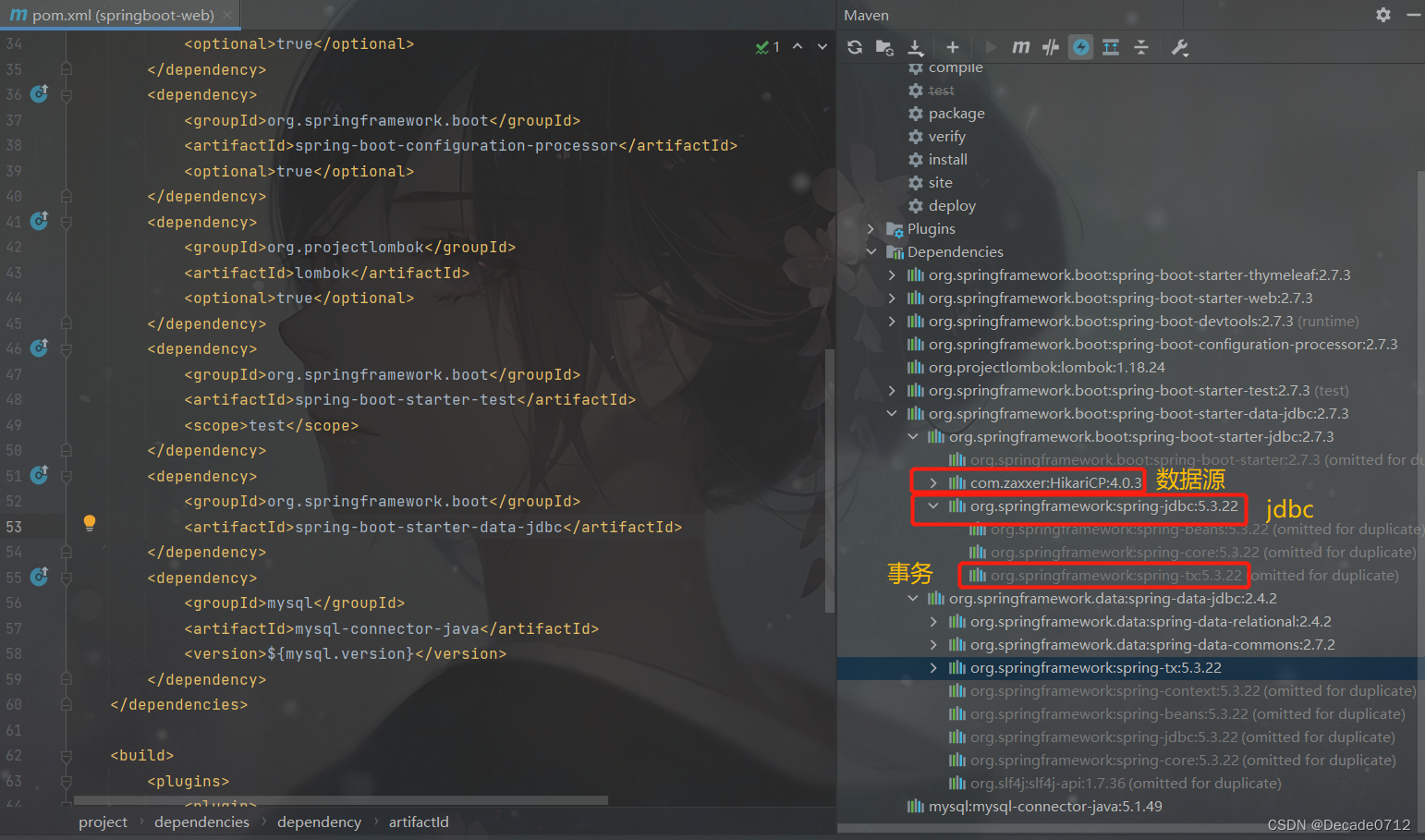
然后,我们还需要导入数据库的连接驱动
注意,我们要根据数据库的版本去导入对应版本的驱动
因为Spring Boot它有默认的版本仲裁,即使不声明version也会有默认版本
所以我们可以直接修改依赖引入的版本(maven的就近依赖原则)或者在properties属性中重新声明版本(maven的属性的就近优先原则,下面使用的就是这种方式)
<properties>
<mysql.version>5.1.49</mysql.version>
</properties>
...
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
从名字不难看出,这个类和数据源的自动配置有关
@AutoConfiguration(
before = {SqlInitializationAutoConfiguration.class}
)
@ConditionalOnClass({DataSource.class, EmbeddedDatabaseType.class})
@ConditionalOnMissingBean(
type = {"io.r2dbc.spi.ConnectionFactory"}
)
@EnableConfigurationProperties({DataSourceProperties.class})
@Import({DataSourcePoolMetadataProvidersConfiguration.class})
public class DataSourceAutoConfiguration {
public DataSourceAutoConfiguration() {
}
...
通过分析这个自动配置类,我们可以发现它绑定了一个DataSourceProperties.class配置类
@ConfigurationProperties(
prefix = "spring.datasource"
)
public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean {
private ClassLoader classLoader;
private boolean generateUniqueName = true;
private String name;
private Class<? extends DataSource> type;
private String driverClassName;
private String url;
private String username;
private String password;
private String jndiName;
private EmbeddedDatabaseConnection embeddedDatabaseConnection;
private DataSourceProperties.Xa xa = new DataSourceProperties.Xa();
private String uniqueName;
...
我们发现想要修改数据源相关的配置,只需要调整spring.datasource相关配置项即可
这里面有很多数据源的配置项,例如url、username等
在这个自动配置类中还有一个内嵌的配置类PooledDataSourceConfiguration
它在容器中没有DataSource.class和XADataSource.class这两种类型的bean时才会生效
它使用@Import导入了针对不同数据库类型数据源连接组件的数据源配置,这些配置仅在使用了相应的数据源连接组件时才生效,一般开发人员只使用其中一种,所以也就只会有一个生效
@Configuration(
proxyBeanMethods = false
)
@Conditional({DataSourceAutoConfiguration.PooledDataSourceCondition.class})
@ConditionalOnMissingBean({DataSource.class, XADataSource.class})
@Import({Hikari.class, Tomcat.class, Dbcp2.class, OracleUcp.class, Generic.class, DataSourceJmxConfiguration.class})
protected static class PooledDataSourceConfiguration {
protected PooledDataSourceConfiguration() {
}
}
我们随便点进一个它导入的数据源连接组件,跳转到DataSourceConfiguration类,可以看到我们前面自动导入的Hikari的相关配置如下,我们梳理一下这个类生效的条件
HikariDataSource.class类型的beanDataSource.class这个类型的beanspring.datasource.type的值为com.zaxxer.hikari.HikariDataSource或者空matchIfMissing:当配置为空时,matchIfMissing为true,配置生效@Configuration(
proxyBeanMethods = false
)
@ConditionalOnClass({HikariDataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(
name = {"spring.datasource.type"},
havingValue = "com.zaxxer.hikari.HikariDataSource",
matchIfMissing = true
)
static class Hikari {
Hikari() {
}
@Bean
@ConfigurationProperties(
prefix = "spring.datasource.hikari"
)
HikariDataSource dataSource(DataSourceProperties properties) {
HikariDataSource dataSource = (HikariDataSource)DataSourceConfiguration.createDataSource(properties, HikariDataSource.class);
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
上述条件满足,所以底层配置好的连接池是:HikariDataSource
事务管理器的自动配置
这个是JdbcTemplate的自动配置,JdbcTemplate可以来对数据库进行crud
@AutoConfiguration(
after = {DataSourceAutoConfiguration.class}
)
@ConditionalOnClass({DataSource.class, JdbcTemplate.class})
@ConditionalOnSingleCandidate(DataSource.class)
@EnableConfigurationProperties({JdbcProperties.class})
@Import({DatabaseInitializationDependencyConfigurer.class, JdbcTemplateConfiguration.class, NamedParameterJdbcTemplateConfiguration.class})
public class JdbcTemplateAutoConfiguration {
public JdbcTemplateAutoConfiguration() {
}
}
通过分析该自动配置类的配置绑定相关类代码可知,我们可以通过修改spring.jdbc开头的配置来对JdbcTemplate进行配置调整
@ConfigurationProperties(
prefix = "spring.jdbc"
)
public class JdbcProperties {
private final JdbcProperties.Template template = new JdbcProperties.Template();
public JdbcProperties() {
}
public JdbcProperties.Template getTemplate() {
return this.template;
}
然后这个自动配置类导入的配置类又会去操作我们前面配置好的数据源
也就是下方jdbcTemplate()方法中的dataSource参数
@Configuration(
proxyBeanMethods = false
)
@ConditionalOnMissingBean({JdbcOperations.class})
class JdbcTemplateConfiguration {
JdbcTemplateConfiguration() {
}
@Bean
@Primary
JdbcTemplate jdbcTemplate(DataSource dataSource, JdbcProperties properties) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
Template template = properties.getTemplate();
jdbcTemplate.setFetchSize(template.getFetchSize());
jdbcTemplate.setMaxRows(template.getMaxRows());
if (template.getQueryTimeout() != null) {
jdbcTemplate.setQueryTimeout((int)template.getQueryTimeout().getSeconds());
}
return jdbcTemplate;
}
}
Jndi自动配置
分布式事务的自动配置
结合上面的源码分析,我们可以写一个简单的demo来进行数据库查询
首先我们去系统配置文件中定义一些关于数据源的配置项
spring:
datasource:
url: jdbc:mysql://localhost:3306/decade_test?useUnicode=true&characterEncoding=UTF-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
下面就是测试代码
package com.decade;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.jdbc.core.JdbcTemplate;
@SpringBootTest
@Slf4j
class SpringbootWebApplicationTests {
@Autowired
private JdbcTemplate jdbcTemplate;
@Test
void contextLoads() {
final Long count = jdbcTemplate.queryForObject("select count(*) from t_decade_user", Long.class);
log.info("该表中数据总数为{}", count);
}
}
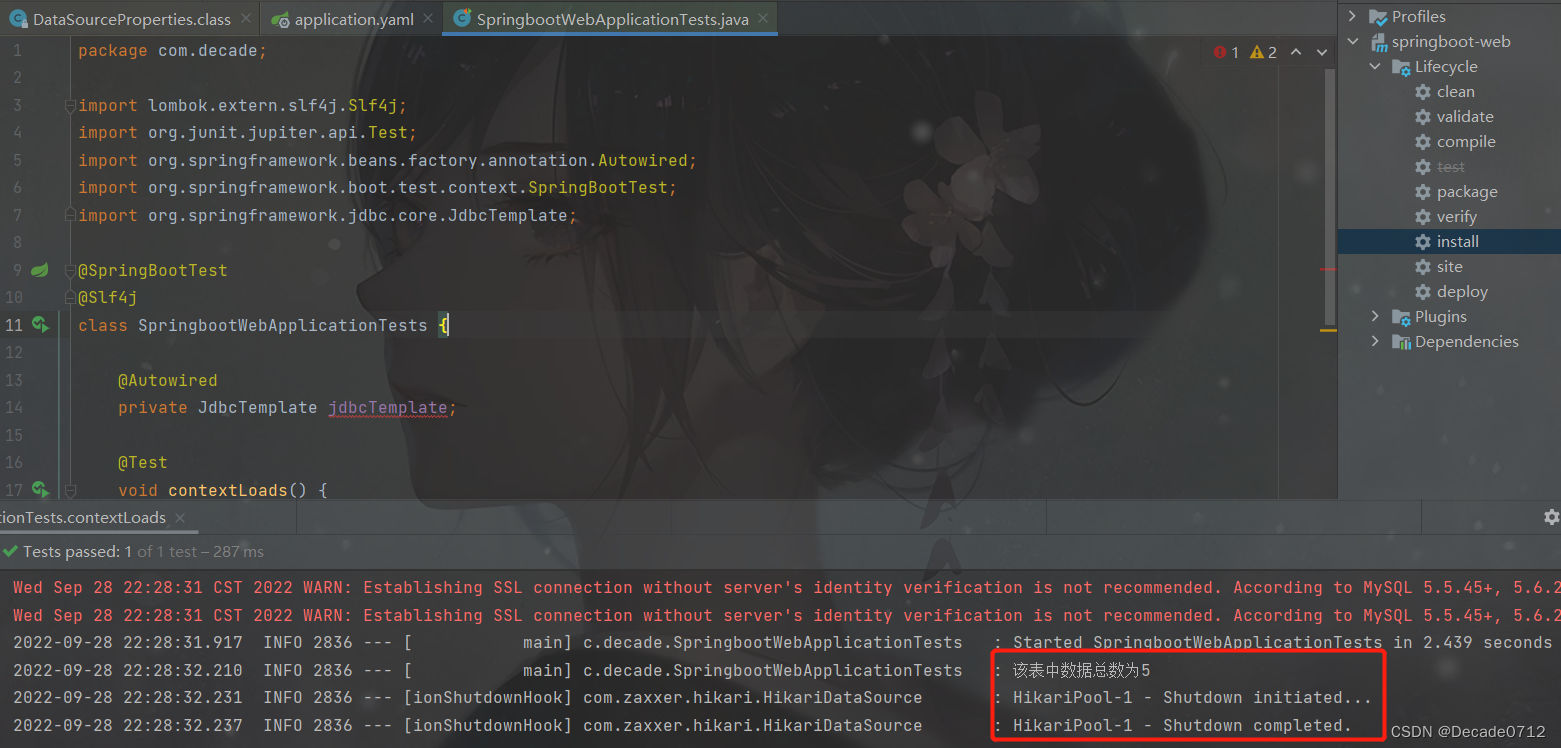
最后测试结果如图
如有错误,欢迎指正!!!
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_