JAVA中简单的for循环竟有这么多坑,你踩过吗
☝☝☝☝☝☝☝☝☝☝☝☝☝☝☝☝
实际的业务项目开发中,大家应该对从给定的list中剔除不满足条件的元素这个操作不陌生吧?
很多同学可以立刻想出很多种实现的方式,但你想到的这些实现方式都是人畜无害的吗?很多看似正常的操作其实背后是个陷阱,很多新手可能稍不留神就会掉入其中。
倘若不幸踩中:

那么,到底有哪些实现方式呢?哪些实现方式可能会存在问题呢?这里我们一起探讨下。注意哦,这里讨论的可不是茴香豆的“茴”字有有种写法的问题,而是很严肃很现实也很容易被忽略的技术问题。
假设需求场景:
给定一个用户列表allUsers,需要从该列表中剔除隶属部门为dev的人员,将剩余的人员信息返回
很多新手的第一想法就是for循环逐个判断校验下然后符合条件的剔除掉就行了嘛~ so easy...
1分钟就把代码写完了:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
for (UserDetail user : allUsers) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(user.getDepartment())) {
allUsers.remove(user);
}
}
// 返回剩余的用户数据
return allUsers;
}
然后信心满满的点击了执行按钮:
java.util.ConcurrentModificationException: null
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at com.veezean.demo4.UserService.filterAllDevDeptUsers(UserService.java:13)
at com.veezean.demo4.Main.main(Main.java:26)
诶? what are you 弄啥嘞?咋抛异常了?

一不留神就踩坑里了,下面就一起分析下为啥会抛异常。
原因分析:
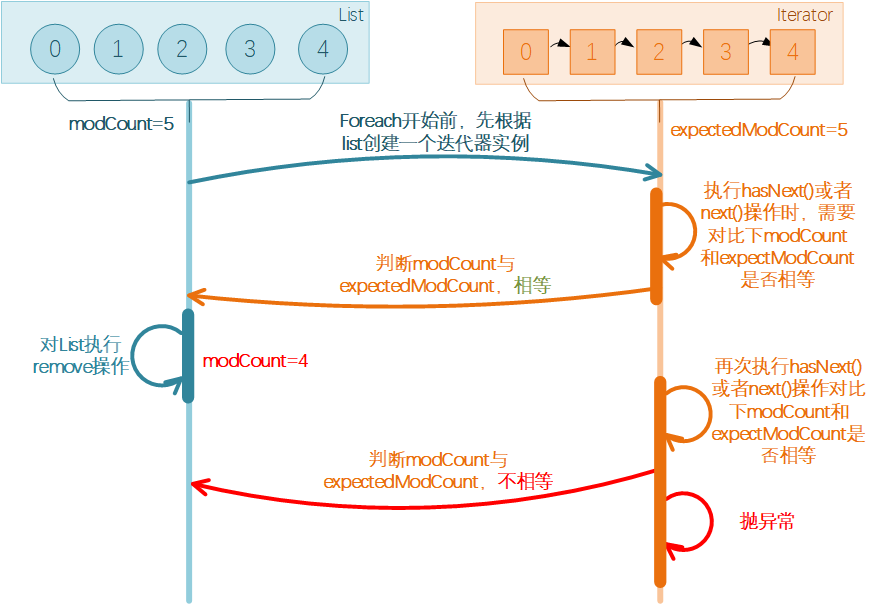
JAVA的foreach语法实际处理是基于迭代器Iterator进行实现的。
在循环开始时,会首先创建一个迭代实例,这个迭代实例的expectedModCount 赋值为集合的modCount。而每当迭代器使⽤ hashNext() / next() 遍历下⼀个元素之前,都会检测 modCount 变量与expectedModCount 值是否相等,相等的话就返回遍历;否则就抛出异常ConcurrentModificationException,终⽌遍历。
如果在循环中添加或删除元素,是直接调用集合的add(),remove()方法,导致了modCount增加或减少,但这些方法不会修改迭代实例中的expectedModCount,导致在迭代实例中expectedModCount与 modCount的值不相等,抛出ConcurrentModificationException异常。
嗯哼?既然foreach方式不行,那就用原始的下标循环的方式来搞,总不会报错了吧?依旧很easy ...
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
for (int i = 0; i < allUsers.size(); i++) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(allUsers.get(i).getDepartment())) {
allUsers.remove(i);
}
}
// 返回剩余的用户数据
return allUsers;
}
代码一气呵成,执行一下,看下处理后的输出:
{id=2, name='李四', department='dev'}
{id=3, name='王五', department='product'}
{id=4, name='铁柱', department='pm'}
果然,不报错了,结果也输出了,完美~
等等?这样真的OK了吗?我们的代码逻辑里面是判断如果"dev".equals(department),但是输出结果里面,为啥还是有department=dev这种本应被剔除掉的数据呢?
这里如果是在真实业务项目中,开发阶段不报错,又没有仔细去验证结果的情况下,流到生产线上,就可能造成业务逻辑的异常。

接下来看下出现这个现象的具体原因。
原因分析:
我们知道,list中的元素与下标之间,其实并没有强绑定关系,仅仅只是一个位置顺序的对应关系,list中元素变更之后,其每个元素对应的下标都可能会变更,如下示意:
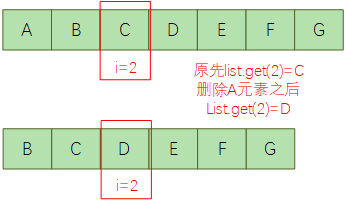
那么,从List中删除元素之后,List中被删元素后面的所有元素下标都发生前移,但是for循环的指针i是始终往后累加的,再处理下一个的时候,就可能会有部分元素被漏掉没有处理。
比如下图的示意,i=0时,判断A元素需要删除,则直接删除;再循环时i=1,此时因为list中元素位置前移,导致B元素变成了原来下标为0的位置,直接被漏掉了:
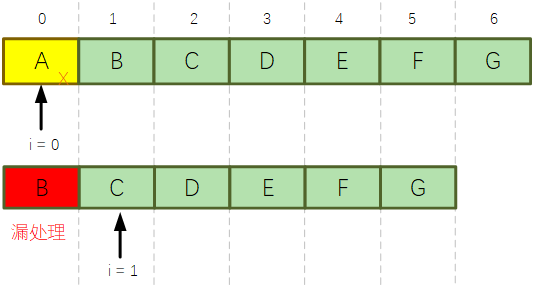
所以到这里呢,也就可以知道为啥上面的代码执行后会出现漏网之鱼啦~
见识了上面2个坑操作之后,那正确妥当的操作方式应该是怎么样的呢?
诶?没搞错吧?前面不是刚说过foreach方式也是使用的迭代器,但是其实是坑操作吗?这里怎么又说迭代器模式是正确方式呢?
虽然都是基于迭代器,但是使用逻辑是不一样的,看下代码:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
Iterator<UserDetail> iterator = allUsers.iterator();
while (iterator.hasNext()) {
// 判断部门如果属于dev,则直接剔除
if ("dev".equals(iterator.next().getDepartment())) {
// 这是重点,此处操作的是Iterator,而不是list
iterator.remove();
}
}
// 返回剩余的用户数据
return allUsers;
}
执行结果:
{id=3, name='王五', department='product'}
{id=4, name='铁柱', department='pm'}
这次竟然直接执行成功了,且结果也是正确的。为啥呢?

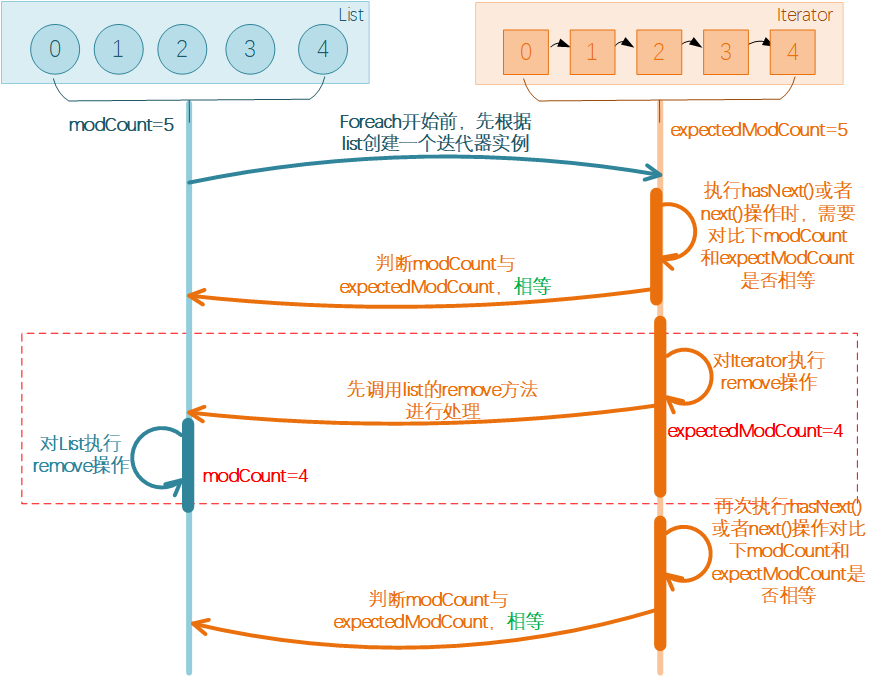
在前面foreach方式的时候,我们提过之所以会报错的原因,是由于直接修改了原始list数据而没有同步让Iterator感知到,所以导致Iterator操作前校验失败抛异常了。而此处的写法中,直接调用迭代器中的remove()方法,此操作会在调用集合的remove(),add()方法后,将expectedModCount重新赋值为modCount,所以在迭代器中增加、删除元素是可以正常运行的。,所以这样就不会出问题啦。
言简意赅,直接上代码:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
allUsers.removeIf(user -> "dev".equals(user.getDepartment()));
return allUsers;
}
作为JAVA8开始加入的Stream,使得这种场景实现起来更加的优雅与易懂:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
return allUsers.stream()
.filter(user -> !"dev".equals(user.getDepartment()))
.collect(Collectors.toList());
}
既然前面说了不能直接循环的时候执行移除操作,那就先搞个list对象将需要移除的元素暂存起来,最后一起剔除就行啦 ~
嗯,虽然有点挫,但是不得不承认,实际情况中,很多人都在用这个方法:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
List<UserDetail> needRemoveUsers = new ArrayList<>();
for (UserDetail user : allUsers) {
if ("dev".equals(user.getDepartment())) {
needRemoveUsers.add(user);
}
}
allUsers.removeAll(needRemoveUsers);
return allUsers;
}
或者:
public List<UserDetail> filterAllDevDeptUsers(List<UserDetail> allUsers) {
List<UserDetail> resultUsers = new ArrayList<>();
for (UserDetail user : allUsers) {
if (!"dev".equals(user.getDepartment())) {
resultUsers.add(user);
}
}
return resultUsers;
}

好啦,关于JAVA中循环场景中对列表操作的相关内容我们就聊这么多了~ 你有踩过上面的坑么?你还有什么更好的方式来实现吗?欢迎一起讨论交流~
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注,也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
似乎无法为此找到有效的答案。我正在阅读Rails教程的第10章第10.1.2节,但似乎无法使邮件程序预览正常工作。我发现处理错误的所有答案都与教程的不同部分相关,我假设我犯的错误正盯着我的脸。我已经完成并将教程中的代码复制/粘贴到相关文件中,但到目前为止,我还看不出我输入的内容与教程中的内容有什么区别。到目前为止,建议是在函数定义中添加或删除参数user,但这并没有解决问题。触发错误的url是http://localhost:3000/rails/mailers/user_mailer/account_activation.http://localhost:3000/rails/mai
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www