在了解容器卷之前,咱们先来看看Docker的理念:
我们想象一下,Docker容器运行后,产生的数据,如果不通过docker commit生成新的镜像,使得数据做为镜像的一部分保存下来,那么当容器删除后,数据自然也就没有了。
所以,为了能保存数据,在docker中我们就要使用数据卷。
也可以这么理解:有点类似我们Redis里面的rdb和aof文件。
卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性:
卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数据卷
特点:
1:数据卷可在容器之间共享或重用数据
2:卷中的更改可以直接生效
3:数据卷中的更改不会包含在镜像的更新中
4:数据卷的生命周期一直持续到没有容器使用它为止。
容器的持久化
容器间继承+共享数据
容器内添加,主要有两种方式:
命令:
docker run -it -v /宿主机绝对路径目录:/容器内目录 镜像名
下面咱们进行直观的展示
具体要求,我想在宿主机根目录下创建一个hostDir目录,与容器的根目录下创建containerDir目录,进而让两者进行数据共享。
1、首先,咱们看一下,宿主机根目录下的文件目录,此时是没有hostDir目录的。

2、查看宿主机的镜像,咱们使用centos镜像
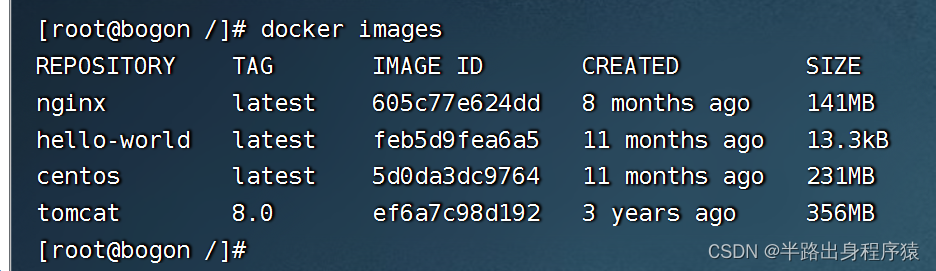
3、执行挂载数据卷的命令
docker run -it -v /hostDir:/containerDir centos /bin/bash
4、查看容器内部的目录变化

5、查看宿主机目录的变化

6、查看数据卷是否挂载成功
命令:docker inspect 容器ID

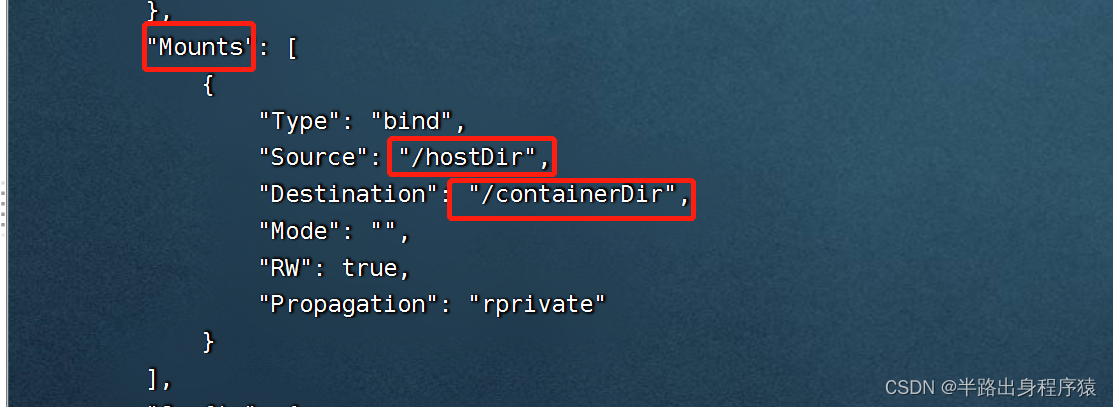
如何实现数据共享呢?
1、首先,咱们在容器的containerDir目录下,创建一个1.txt文件,并编辑内容
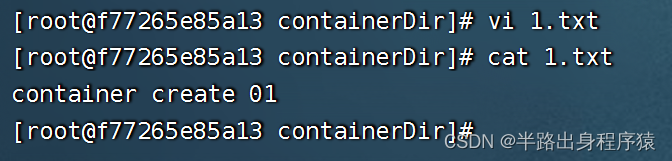
2、然后,咱们来到宿主机的hostDir下,查看是否也有1.txt文件,并查看里面的内容

看到这里,说明容器和宿主机的数据已经实现了同步和共享
3、现在呢,咱们反过来,在宿主机上,先创建一个2.txt,同时呢修改一下1.txt
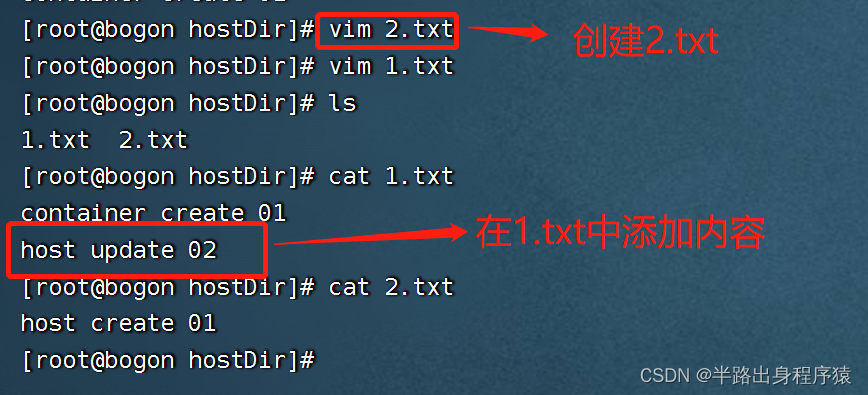
4、最后,咱们进入容器中进行查看,是否也有2.txt,同时呢1.txt是否也被修改

再加深一下,如果容器停止退出后,咱们在宿主机修改后数据后,再次启动容器,数据是可以同步的。这就类似我们Redis里面的rdb和aof文件。
可在Dockerfile中使用VOLUME指令来给镜像添加一个或多个数据卷
VOLUME["/dataVolumeContainer","/dataVolumeContainer2","/dataVolumeContainer3"]
说明:
出于可移植和分享的考虑,用-v 主机目录:容器目录这种方法不能够直接在Dockerfile中实现。
由于宿主机目录是依赖于特定宿主机的,并不能够保证在所有的宿主机上都存在这样的特定目录。
来来,咱们继续进行演示
1、在宿主机根目录下,创建一个mydocker文件夹并进入
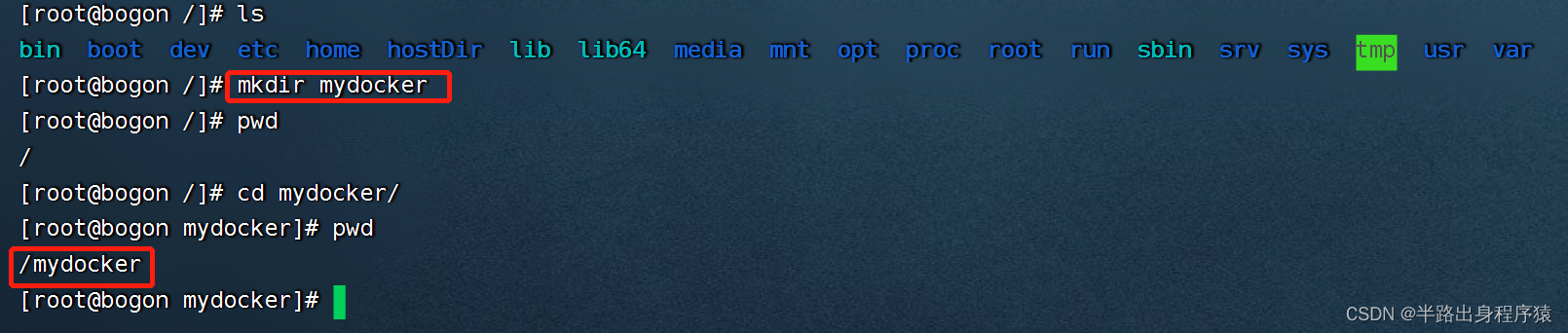
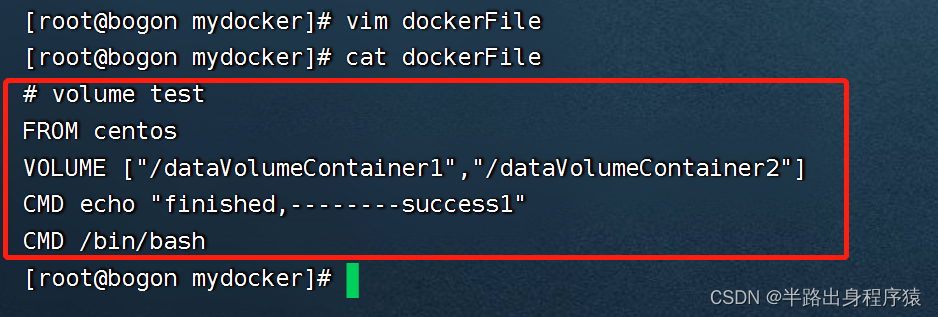
2、创建一个dockerFile文件,并编辑内容
# volume test
FROM centos
VOLUME ["/dataVolumeContainer1","/dataVolumeContainer2"]
CMD echo "finished,--------success1"
CMD /bin/bash
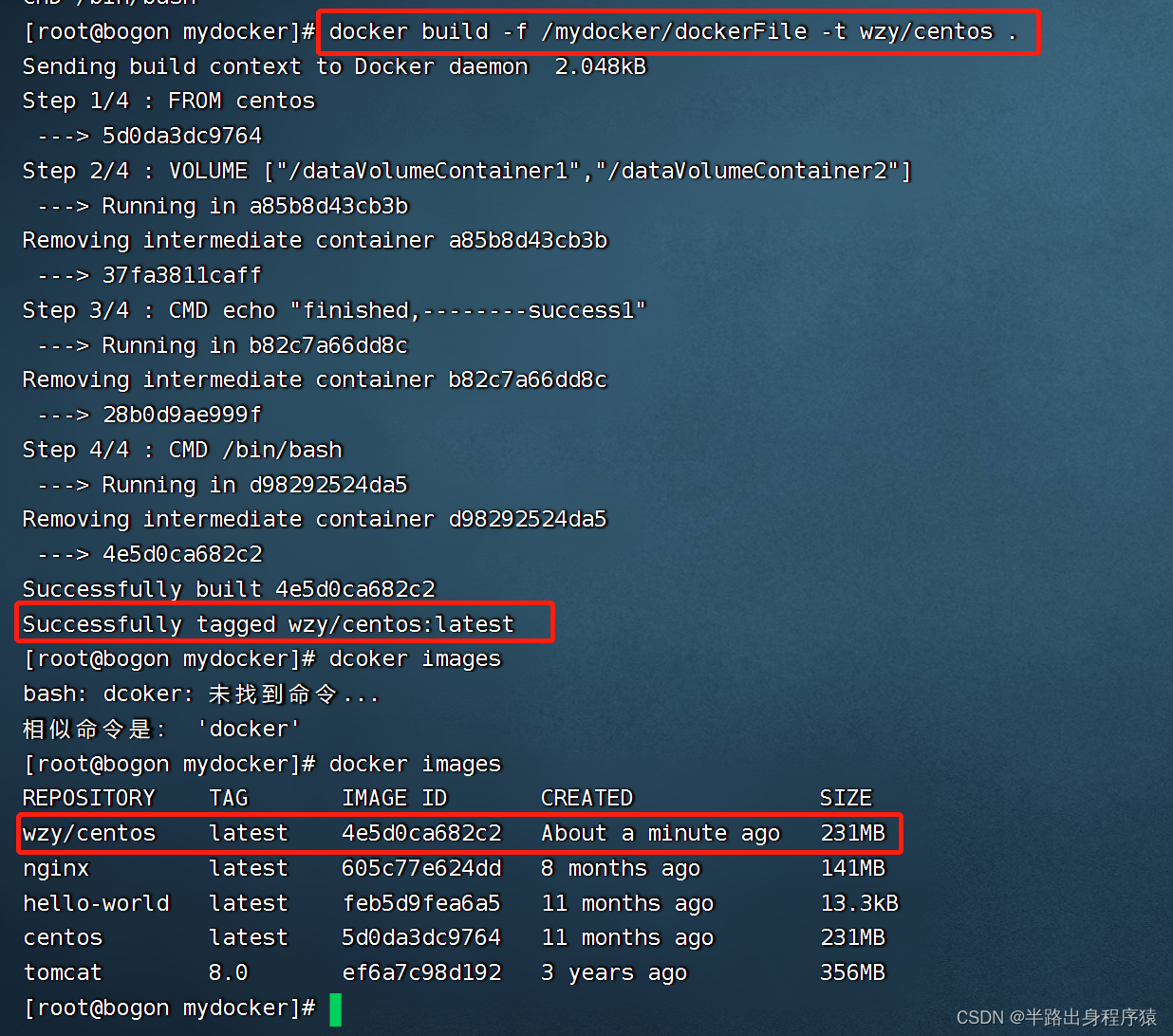
3、build后生成镜像,获得一个新镜像wzy/centos
docker build -f /mydocker/dockerFile -t wzy/centos .
4、运行这个新的容器,然后查看容器内部目录变化
docker run -it 4e5d0ca682c2 /bin/bash

此时可以看到,容器根目录下,已经创建出了两个文件夹。
5、通过上述步骤,容器内的卷目录地址已经知道,对应的主机目录地址哪???
咱们可以通过一个命令进行查看得到
docker inspect 容器id
docker inspect c3803db06963
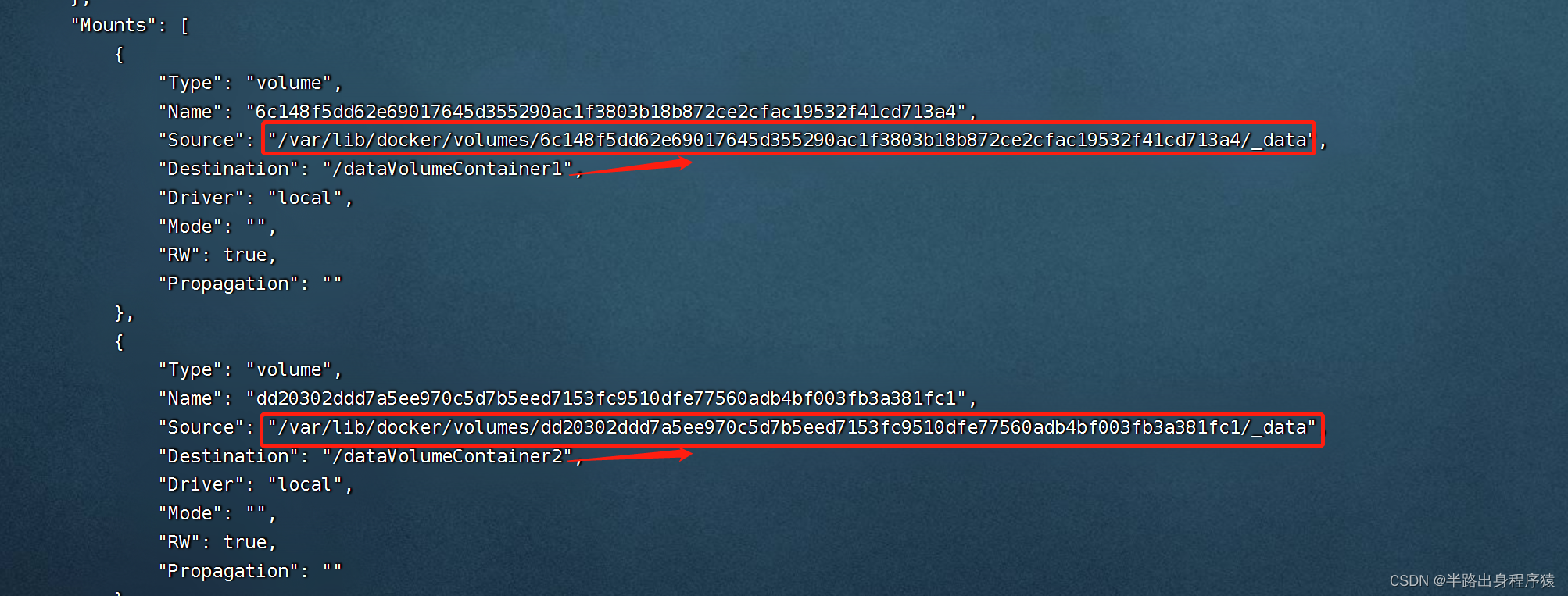
这俩就是相互对应的绑定关系
6、验证一下,宿主机的目录

这个目录确实是在宿主机存在的,下一步就可以做数据共享了。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit