缓存是提升性能的通用方法,现在大多数的缓存实现都使用了经典的技术。当读多写少的情况时,通常会使用缓存来提升获取数据的性能。使用缓存的方式大概有Reids、MemoryCahce、Memcached、Dictionary等等方式来实现自己的缓存,使用缓存时可能考虑最多的时如何存储数据,而不是考虑如何淘汰数据,一般希望缓存可以命中所有的请求,在必要时候再请求底层数据,来提高性能。但是缓存数据也有存储成本,如果存储所有数据,需要在存储上付出很多成本。
在操作系统,数据库等领域中,我们会经常使用到驱逐策略算法(换出调度算法)来实现数据页面在主存与磁盘之间频繁的交换。CPU L1,L2......缓存中简述了缓存淘汰策略。本篇详细讨论一下各个驱逐策略。大概总结了如下几种驱逐策略:
Two-Queue/N-Queue概念的淘汰策略
简述:当缓存溢出时,优先淘汰先进入的数据
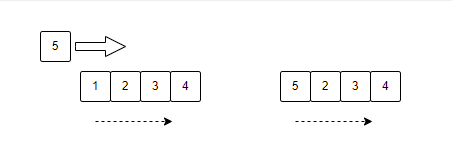
上述图例说明:
有一个容量为4的缓存,依次存入:1,2,3,4。当存入5时目前已经没有空间,在FIFO的策略下,优先淘汰1,然后将5存储到1的位置上。(一般使用环状数组实现FIFO)
集中一个数据访问时,可以通过缓存获取到数据,可以应对同一个数据出现高峰时返回缓存数据
当数据量大于内存容量一定比例之后,数据的访问不会命中缓存。
简述:最久未使用的数据优先淘汰。核心思想是最近访问的元素,很有可能是目前最想访问的元素,也有可能是未来一直会访问的元素

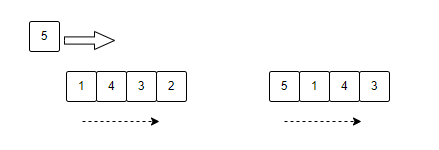
图列说明:
有一个容量为4的缓存,依次存入:1,2,3,4。图1为再次访问数据1的元素时,会将访问的元素重置为内存第一个元素,也就意味着最晚淘汰
图列说明:
将数据5存入内存时,缓存溢出,优先淘汰最久未使用的元素2。
存储热点数据,例如热搜等等
因为访问一次就会认为是“新鲜”的数据,在有偶发热点数据时会将历史热点数据淘汰掉,导致缓存一直在淘汰数据。
简述:最近使用频率高的数据很大概率将会再次被使用,而最近使用频率低的数据,很大概率不会再使用。
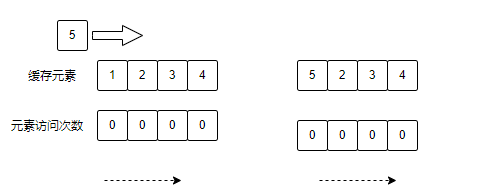
图列说明:
当元素5存入缓存时,当前缓存溢出,淘汰元素1,淘汰数据算法是:优点淘汰访问次数较低的元素,访问次数一致的,优先淘汰最久未访问过的。
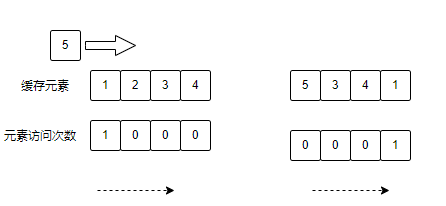
图列说明:
当元素5存入缓存时,当前缓存溢出,淘汰元素2,淘汰数据算法是:优点淘汰访问次数较低的元素,访问次数一致的,优先淘汰最久未访问过的。元素1访问次数为1,所以不能被淘汰
简述:当时访问的数据趋向于访问最近的内容,会更多地命中LRU list,这样会增大LRU的空间; 当系统趋向于访问最频繁的内容,会更多地命中LFU list,这样会增加LFU的空间。
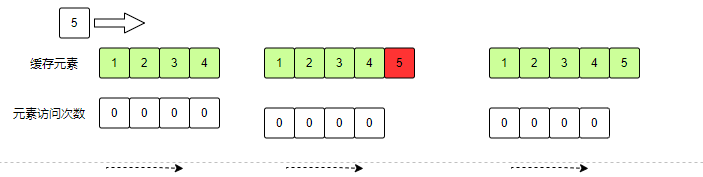
图列说明:首先进入缓存的数据存储在LRUList中,当缓存溢出时,优先将存入的数据放入到LRU ghost List,然后LURList扩容,将新数据放到LRU第一个元素,LRU List和LFU List 共用一个空间,只是内部进行了区分,LUR List扩容之后意味着LFU List会缩小。这就是所谓的动态调整。
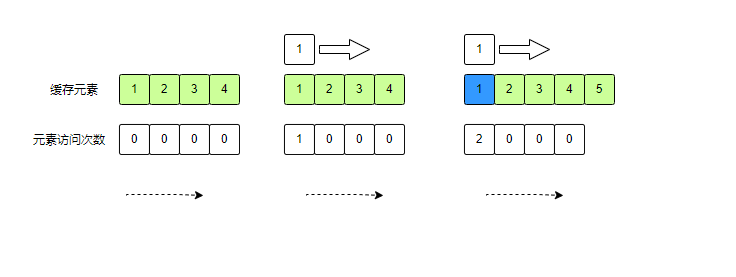
图列说明:第一次访问元素1,记录已存在元素的访问次数,第二次访问元素1,访问次数到达2,会进入LFU List。
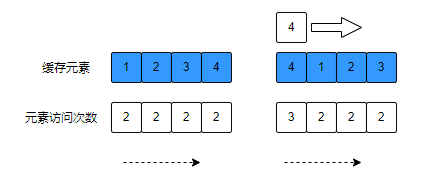
图例说明:所有元素都在LFU List中,再次访问LFU中的元素时,优先将访问的元素放到LFU List中,这样可以实现热点数据一直存在于缓存中。
支持各种突发和偶发的数据操作
使用Two Queue实现,实现难度比较高,IBM发明使用。
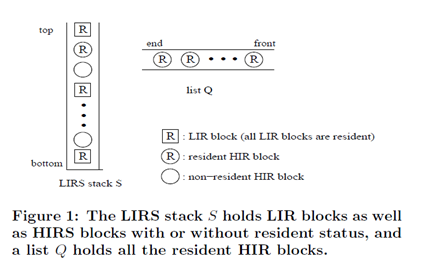
简述:LIRS 算法全称 Low Inter-reference Recency Set,LIRS 使用 IRR(Inter-Reference Recency)来表示记录数据块访问历史信息,IRR 表示最近连续访问同一个数据块之间访问其他不同数据块非重复个数
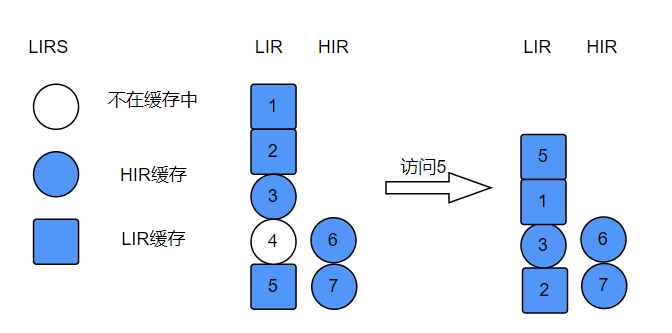
图例说明:
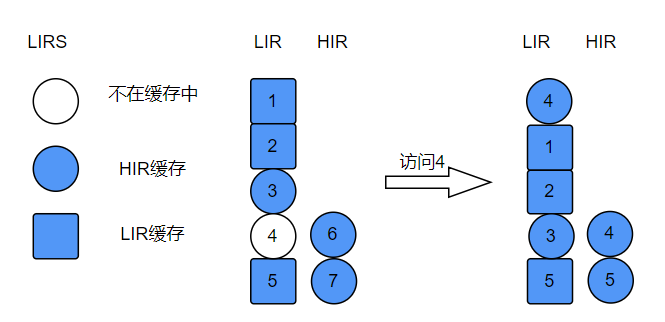
图例说明:访问存在于LIR中的失效缓存元素
总结:LIRS中使用IRR和R记录当前数据的访问次数和访问之间的间隔,判断是否为经常使用的元素,使用Stack和Queue结合缓存元素,几乎所有元素都在缓存中,只不过有失效元素,这是因为需要计算元素访问间隔。上述图例并未全面列出LIRS的数据操作,感兴趣的小伙伴可以一一推导。
在LRU的基础上考虑了支持突发冷数据的影响,设计理念为缓存中的数据一定存在
缺点
占用空间较大,实现算法复杂,需要考虑各种状态。
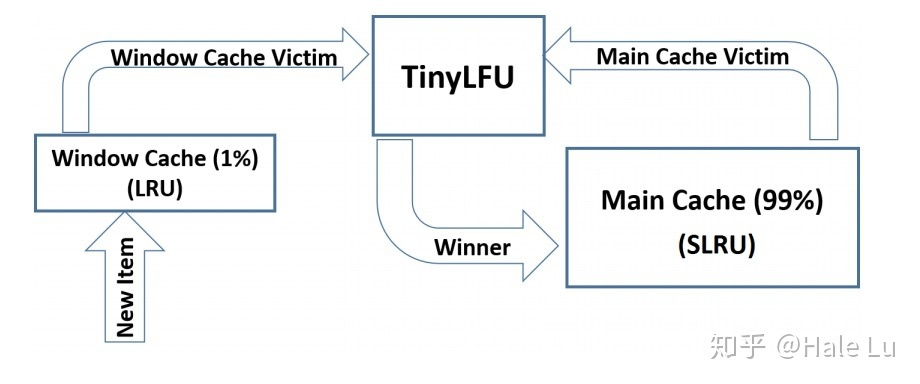
简介:内部分三个队列:windowLRU,probationLru,protectedLru,首先进入缓存的数据,进入windowLRU,当windowLRU溢出时选出首个元素叫做candidate,获取probationLru首个元素叫做victim,两个元素做比较,淘汰使用次数少的元素,两个元素使用次数一致时,随机将一个元素淘汰。当probationLru中的数据访问次数到达一定指标之后会晋升到protectedLru队列中。
三阶段,支持突发数据缓存和历史数据缓存,提高命中率
实现复杂度较高,对基础知识要求高。
BitFaster.Caching:https://github.com/bitfaster/BitFaster.Caching
简介:。NET 高性能,线程安全内存缓存,其中实现了LRU和LFU的缓存策略
int capacity = 666;
var lru = new ConcurrentLru<string, SomeItem>(capacity);
var value = lru.GetOrAdd("key", (key) => new SomeItem(key));int capacity = 666;
var lfu = new ConcurrentLfu<string, SomeItem>(capacity);
var value = lfu.GetOrAdd("key", (key) => new SomeItem(key));Caffeine (Java中拥有多种缓存策略的缓存项目)
github:https://github.com/ben-manes/caffeine
Caffeine是一个开源的Java缓存库,它能提供高命中率和出色的并发能力 ,内部使用W-TinyLFU 策略加上并发写入的实现,在基准测试中表现优异。目前被广泛应用与游戏和电商等等项目中。此项目只有Java版本的,没有适配所有版本。
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我想使用两种不同的protect_from_forgery策略构建一个Rails应用程序:一种用于Web应用程序,一种用于API。在我的应用程序Controller中,我有这行代码:protect_from_forgerywith::exception为了防止CSRF攻击,它工作得很好。在我的API命名空间中,我创建了一个继承self的应用程序Controller的api_controller,它是API命名空间中所有其他Controller的父类,我将上面的代码更改为:protect_from_forgery:null_session.遗憾的是,我在尝试发出POST请求时遇到错误:“
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
当我尝试进行bundle安装时,我的gem_path和gem_home指向/usr/local/rvm/gems/我没有写入权限,并且由于权限无效而失败。因此,我已将两个路径都更改为我具有写入权限的本地目录。这样做时,我进行了bundle安装,我得到:bruno@test6:~$bundleinstallFetchinggemmetadatafromhttps://rubygems.org/.........Fetchinggemmetadatafromhttps://rubygems.org/..Bundler::GemspecError:Couldnotreadgemat/afs/
我一直在Heroku上尝试不同的缓存策略,并添加了他们的memcached附加组件,目的是为我的应用程序添加Action缓存。但是,当我在我当前的应用程序上查看Rails.cache.stats时(安装了memcached并使用dalligem),在执行应该缓存的操作后,我得到current和total_items为0。在Controller的顶部,我想缓存我有的Action:caches_action:show此外,我修改了我的环境配置(对于在Heroku上运行的配置)config.cache_store=:dalli_store我是否可以查看其他一些统计数据,看看它是否有效或我做错
我有一个具有页面缓存的ControllerAction,我制作了一个清扫程序,它使用Controller和指定的Action调用expire_page...Controller操作呈现一个js.erb模板,所以我试图确保expire_page删除public/javascripts中的.js文件,但它没有这样做。classJavascriptsController"javascripts",:action=>"lol",:format=>'js')endend...所以,我访问javascripts/lol.js并呈现我的模板。我验证了public/javascripts/lol.js
我的Controller有这个:caches_action:render_ticker_for_channel,:expires_in=>30.seconds在我的路由文件中我有这个:match'/render_c_t/:channel_id'=>'render#render_ticker_for_channel',:as=>:render_channel_ticker在日志文件中我看到了这个:Writefragmentviews/mcr3.dev/render_c_t/63(11.6ms)我如何手动使它过期?我需要从与渲染Controller不同的Controller使它过期,但即使
我在开发和生产中都使用docker,真正困扰我的一件事是docker缓存的简单性。我的ruby应用程序需要bundleinstall来安装依赖项,因此我从以下Dockerfile开始:添加GemfileGemfile添加Gemfile.lockGemfile.lock运行bundleinstall--path/root/bundle所有依赖项都被缓存,并且在我添加新gem之前效果很好。即使我添加的gem只有0.5MB,从头开始安装所有应用程序gem仍然需要10-15分钟。由于依赖项文件夹的大小(大约300MB),然后再花10分钟来部署它。我在node_modules和npm上遇到了