
K 哥之前写过一篇关于百度翻译逆向的文章,也在 bilibili 上出过相应的视频,最近在 K 哥爬虫交流群中有群友提出,百度翻译新增了一个请求头参数 Acs-Token,如果不携带该参数,直接按照以前的方法进行处理,会出现 1022 报错,并且如果直接将 Acs-Token 写成定值,前几次可能能成功,多查询几次也会报同样的错误,现对其进行逆向分析,对往期代码进行重构。与此同时,K哥发现百度指数的某些接口有个 Cipher-Text 参数,与百度翻译的 Acs-Token 加密方式差不多,所以就一起分析一波。
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
先以百度翻译为例,随便输入文字,可以看到没有刷新页面,翻译结果就出来了,由此可以推断是 Ajax 加载的,打开开发者工具,选择 XHR 过滤 Ajax 请求,找到接口位置,详细分析推荐阅读 K 哥往期百度翻译逆向的文章,如下图可以看到在请求头中新增了一个 Acs-Token 参数,前面两串数字看起来像时间戳,具体加密方式需要我们来进一步分析:
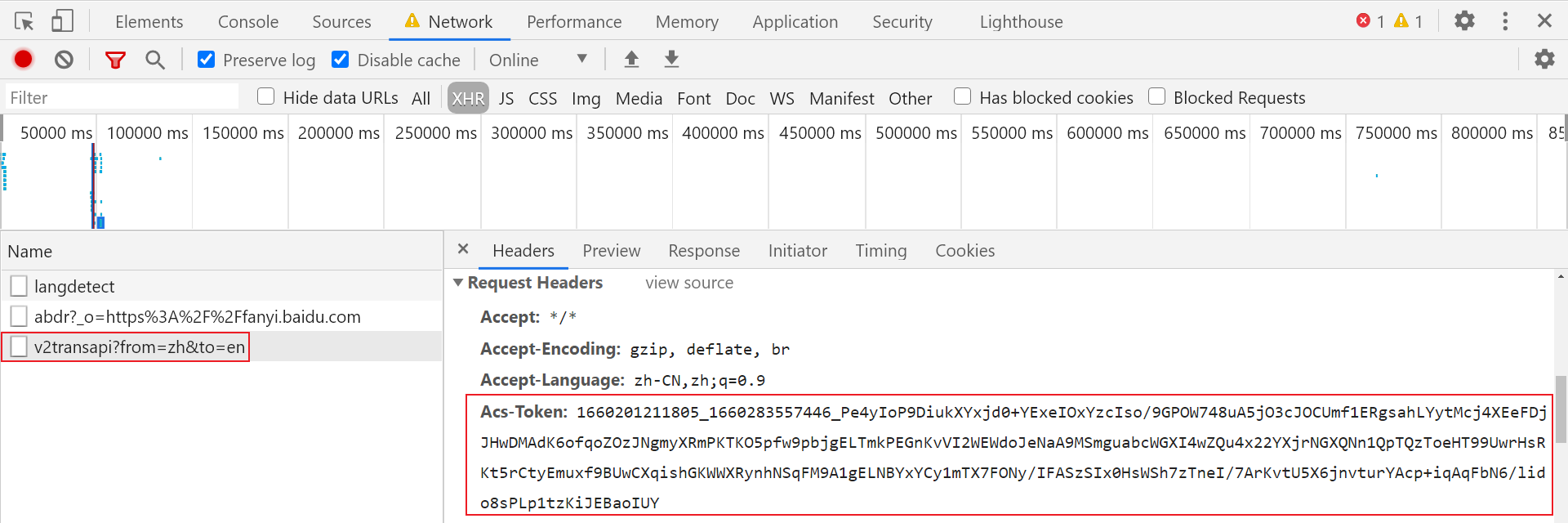
这里使用 Fiddler 插件 hook 定位 Acs-Token 参数,相关 hook 操作方式可阅读 K 哥往期文章,本文不再赘述:

(function () {
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function (key, value) {
console.log(key, ':', value)
if (key == 'Acs-Token') {
debugger;
}
return org.apply(this, arguments);
};
})();
清除缓存,点击翻译,可以看到成功 hook 到 Acs-Token 参数,往下跟栈即可找到其值生成的位置:
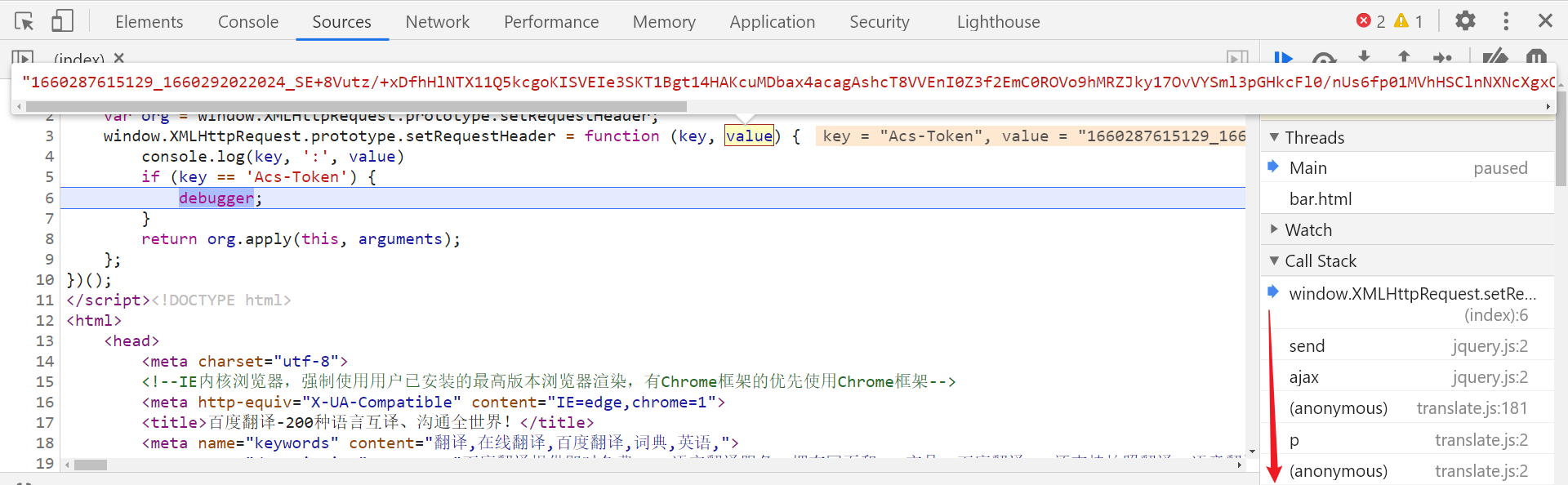
向下跟栈分析,Acs-Token 参数的值在 translate.js 文件的第 187 行生成,由 sign 参数传递,sign 参数定义在第 180 行,在第 195 行打下断点调试,点击翻译后成功在断点处断下:
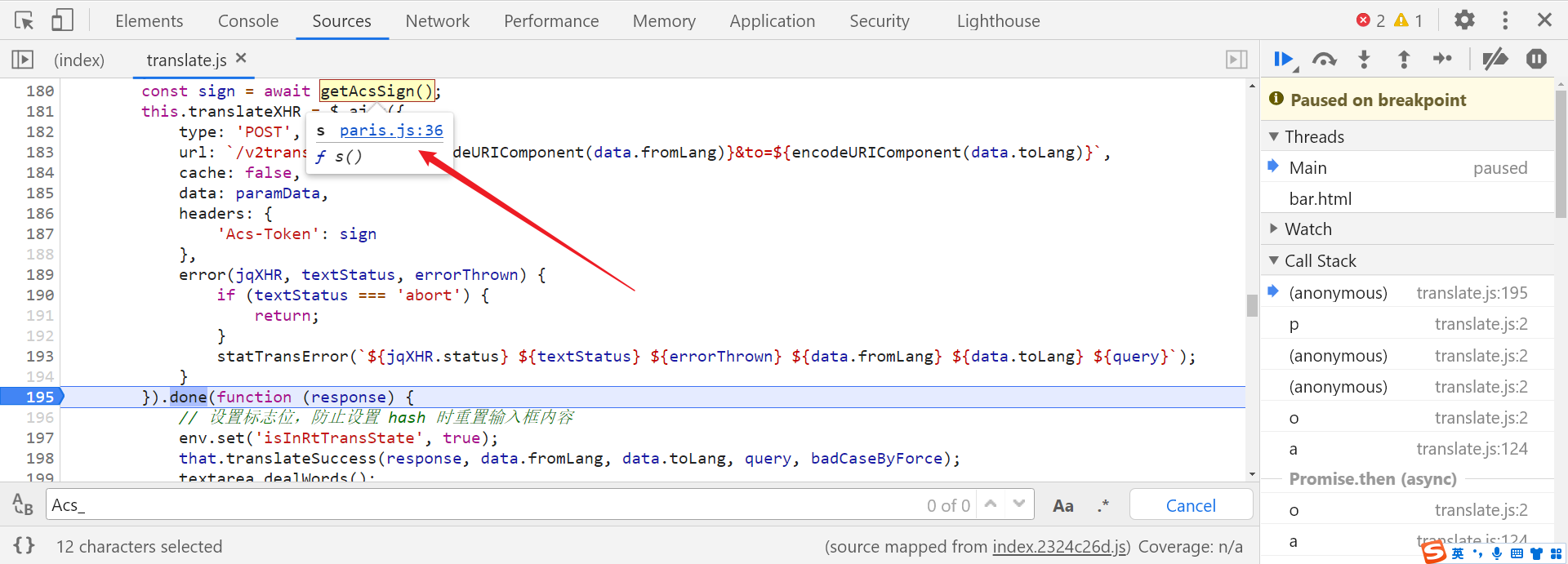
跟进 getAcsSign() 函数,整体选中,点击进入到 paris.js 文件中,可以看到函数体中创建了一个异步 Promise 对象进行异步操作:
Promise 的构造函数接收一个函数参数,并且这个函数需要传入两个参数:
resolve:异步操作执行成功后的回调函数;reject:异步操作执行失败后的回调函数。所以异步操作执行成功即返回 sign 参数的值:
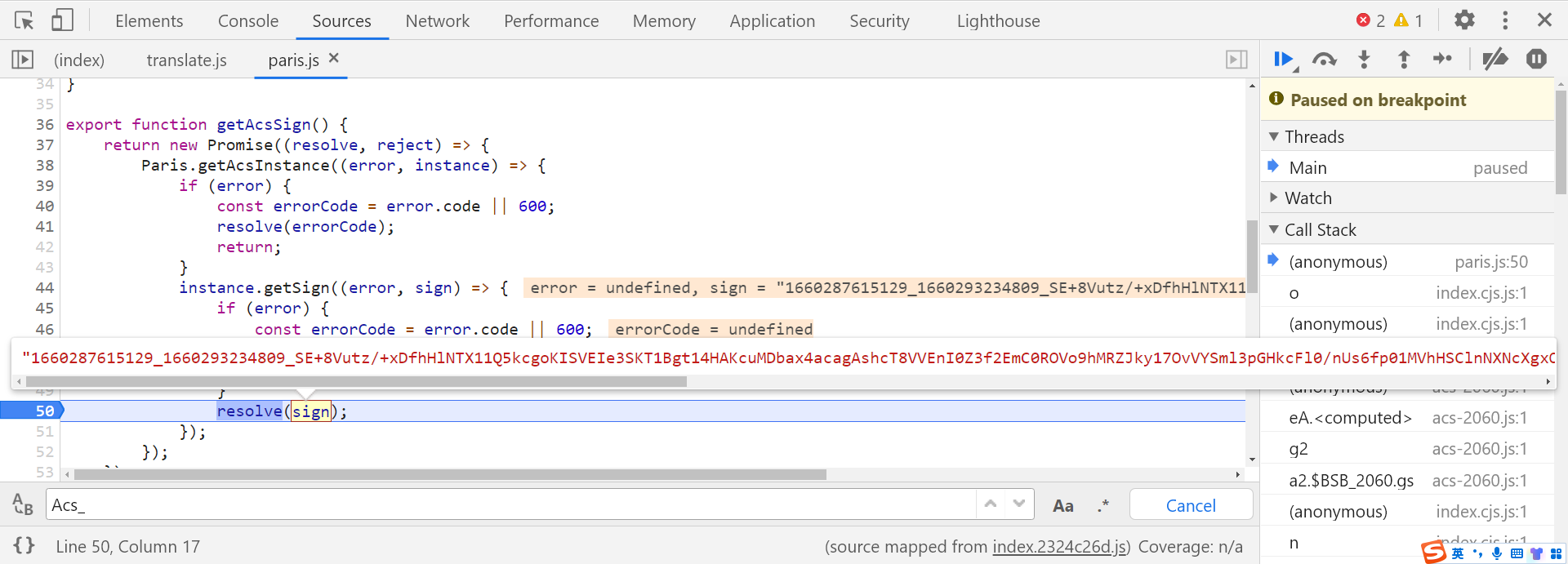
到这里已经拿到 sign 了,我们再向上跟栈,可以发现 Acs-Token 参数的值在 acs-2060.js 文件的第 805 行生成,很明显是拼接而成的:
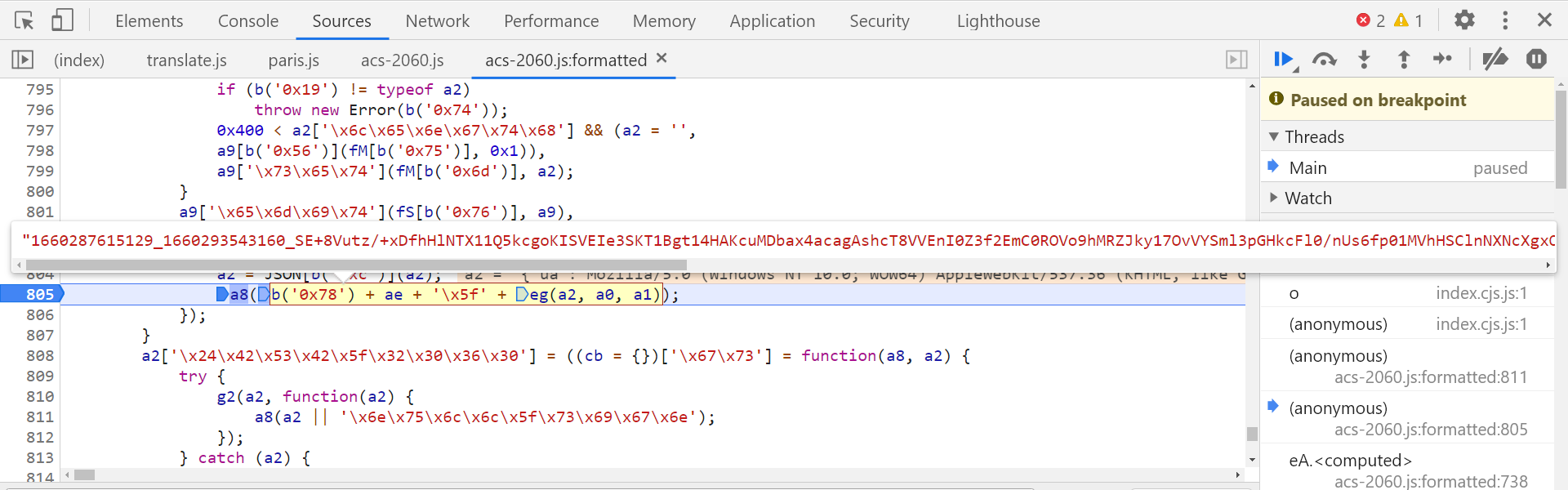
上图是几天前分析的时候断下的情况,今天再次分析的时候发现结构变了,如下图所示:
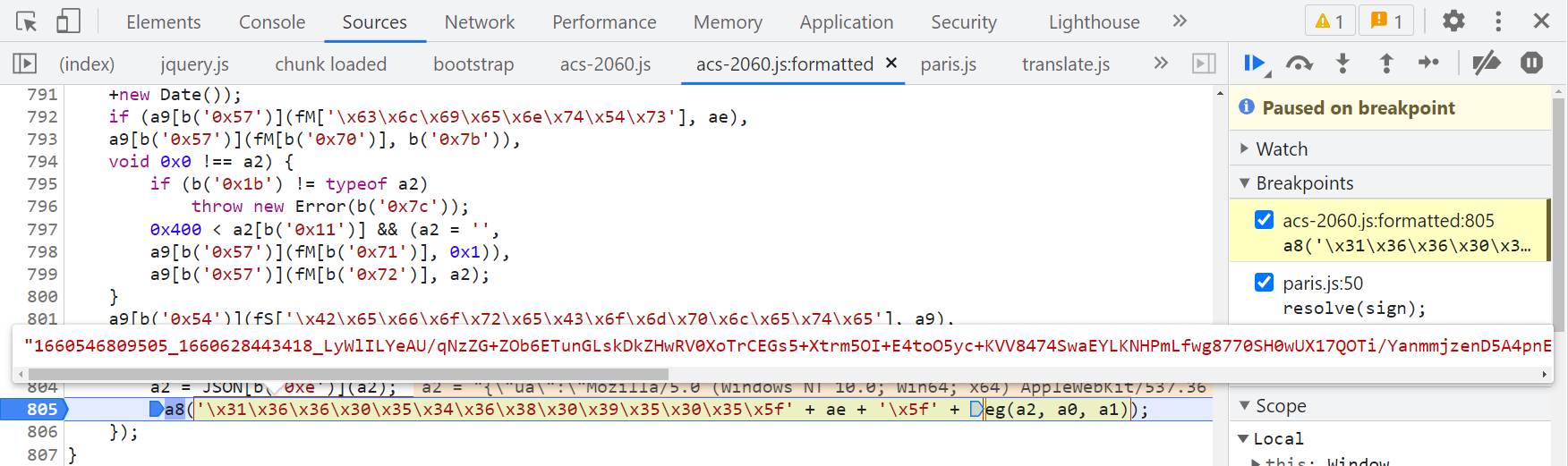
这个 acs-2060.js 是咋来的呢?在 paris.js 里其实可以看到 init 初始化了了一些配置文件,其中的 acsUrl 就是 acs-2060.js 的地址,2060 是渠道号,由管理员分配,根据注释可以看到这个东西叫做“玉门关”。
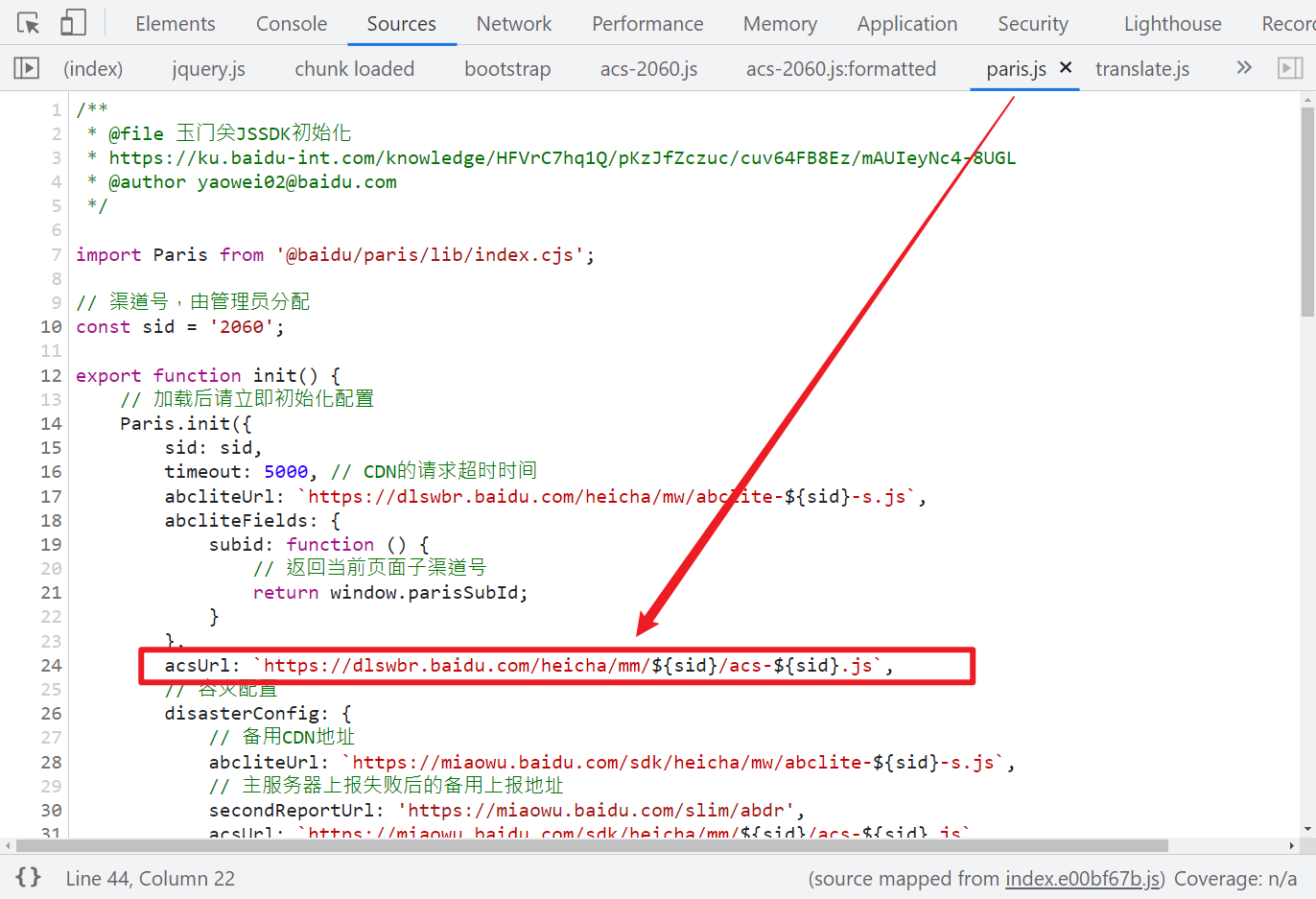
继续前面的步骤,分析一下 acs-2060.js,在第 805 行打断点调试,分析 a8() 中各拼接部分含义,可得到如下结果:
b('0x78') 或者 '\x31\x36\x36\x30\x35\x34\x36\x38\x30\x39\x35\x30\x35\x5f':固定字符串 1660287615129_ 或者 1660546809505_,这里每隔一段时间都会变化。具体的变化周期得需要持续观察一下才知道。ae:当前时间戳'\x5f':下划线 _eg(a2, a0, a1):一大串加密字符串,在控制台输出可以知道 a2, a0, a1 各自的含义
a0,a1 为定值,分析 a2 字典中各参数值含义:
ua:浏览器类型url:翻译链接,例如输如 spider,url 即为 https://fanyi.baidu.com/#zh/en/spiderplatform:平台操作系统版本clientTs:当前时间戳version:版本号选中 eg,跟进到 eg 函数定义的位置,在 acs-2060.js 文件的第 537 行:
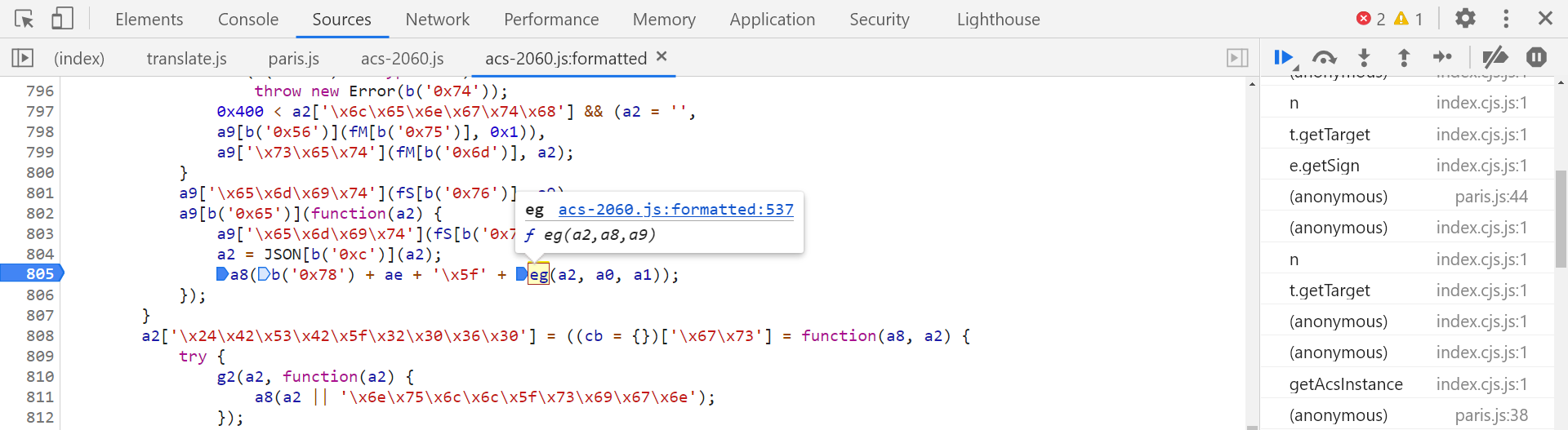
具体内容如下:
function eg(a2, a8, a9) {
return a2 = b('0x4d') == typeof a2 ? JSON[b('0xc')](a2) : void 0x0 === a2 ? '' : '' + a2,
dD[b('0x37')](a2, ad[b('0x29')](a8), {
'\x69\x76': ad[b('0x29')](a9),
'\x6d\x6f\x64\x65': cc,
'\x70\x61\x64\x64\x69\x6e\x67': cz
})[b('0x27')][b('0xa')](ag);
}
可以在第 538 行打断点进行调试,亦可从控制台直接打印混淆部分内容,会发现三个经典加密参数:
'\x69\x76':iv,偏移量'\x6d\x6f\x64\x65':mode,加密方式'\x70\x61\x64\x64\x69\x6e\x67':padding,填充方式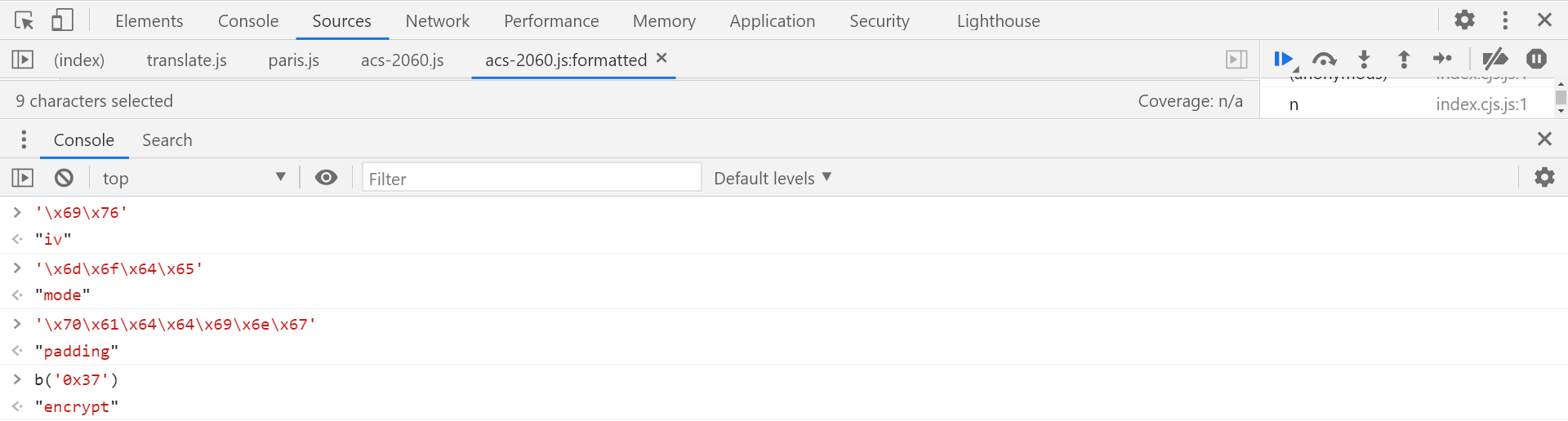
并且在第 548 行将 eg 赋值给了 window.aes_encrypt,很明显 AES 加密了,可以选择直接引库,也可以直接扣代码,这里不做继续研究:
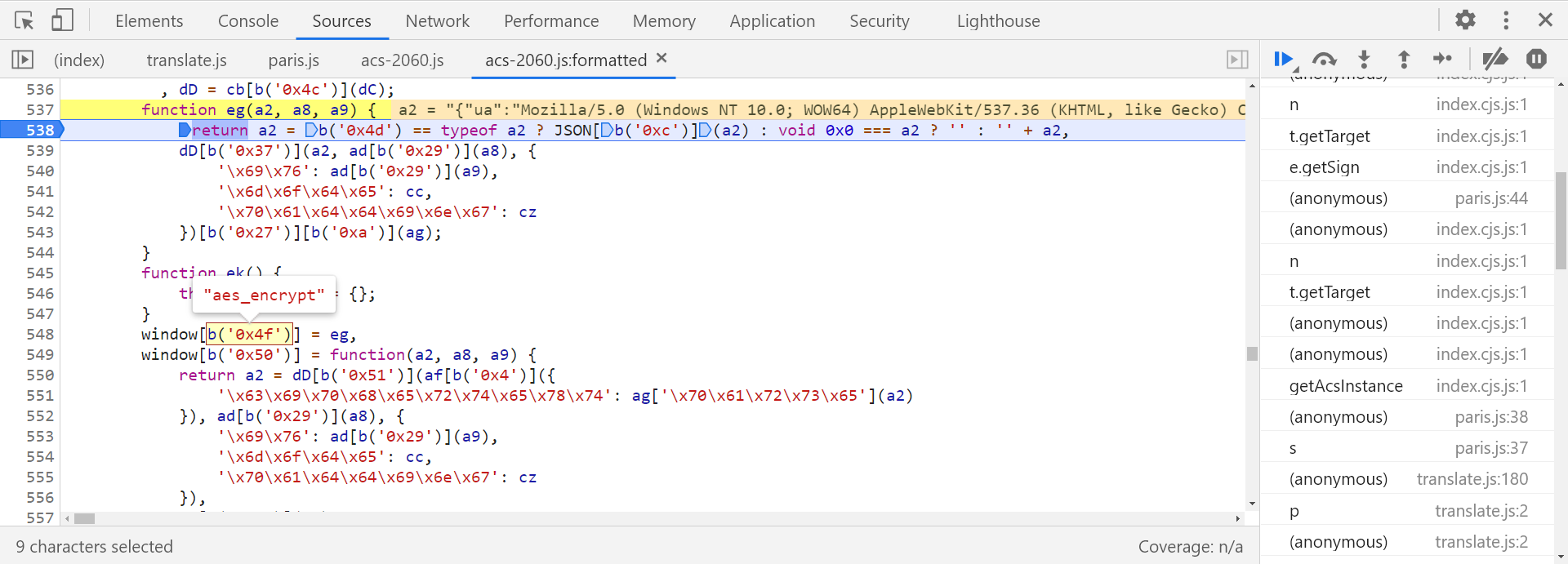
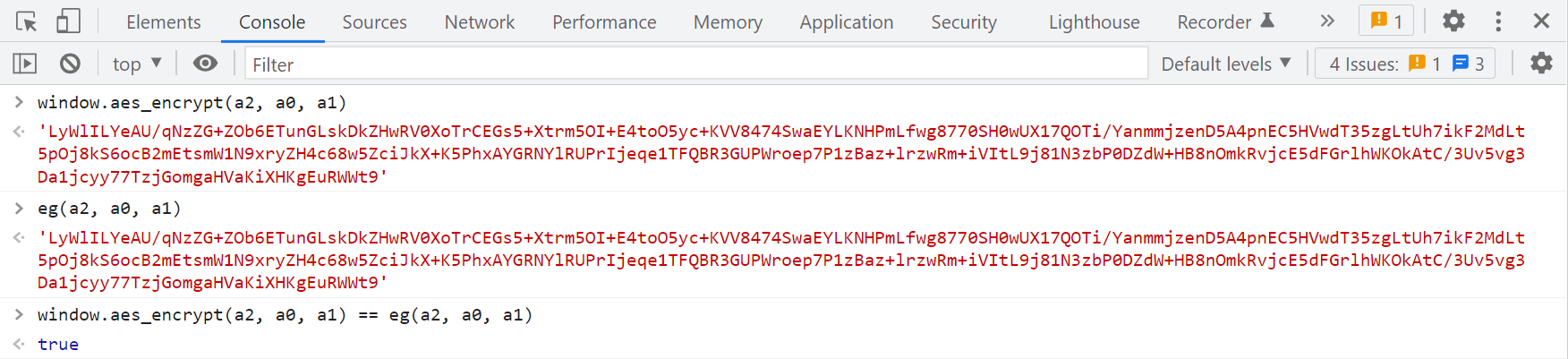
百度指数的 Cipher-Text 和百度翻译的 Acs-Token 在结构上是一样的,根据百度翻译的经验,我们知道核心加密代码应该在“玉门关”里面,不同的站分配的渠道号不一样,我们直接全局搜索 acsUrl,或者直接找 acs 开头的 JS,会发现有一个 acs-2057.js:
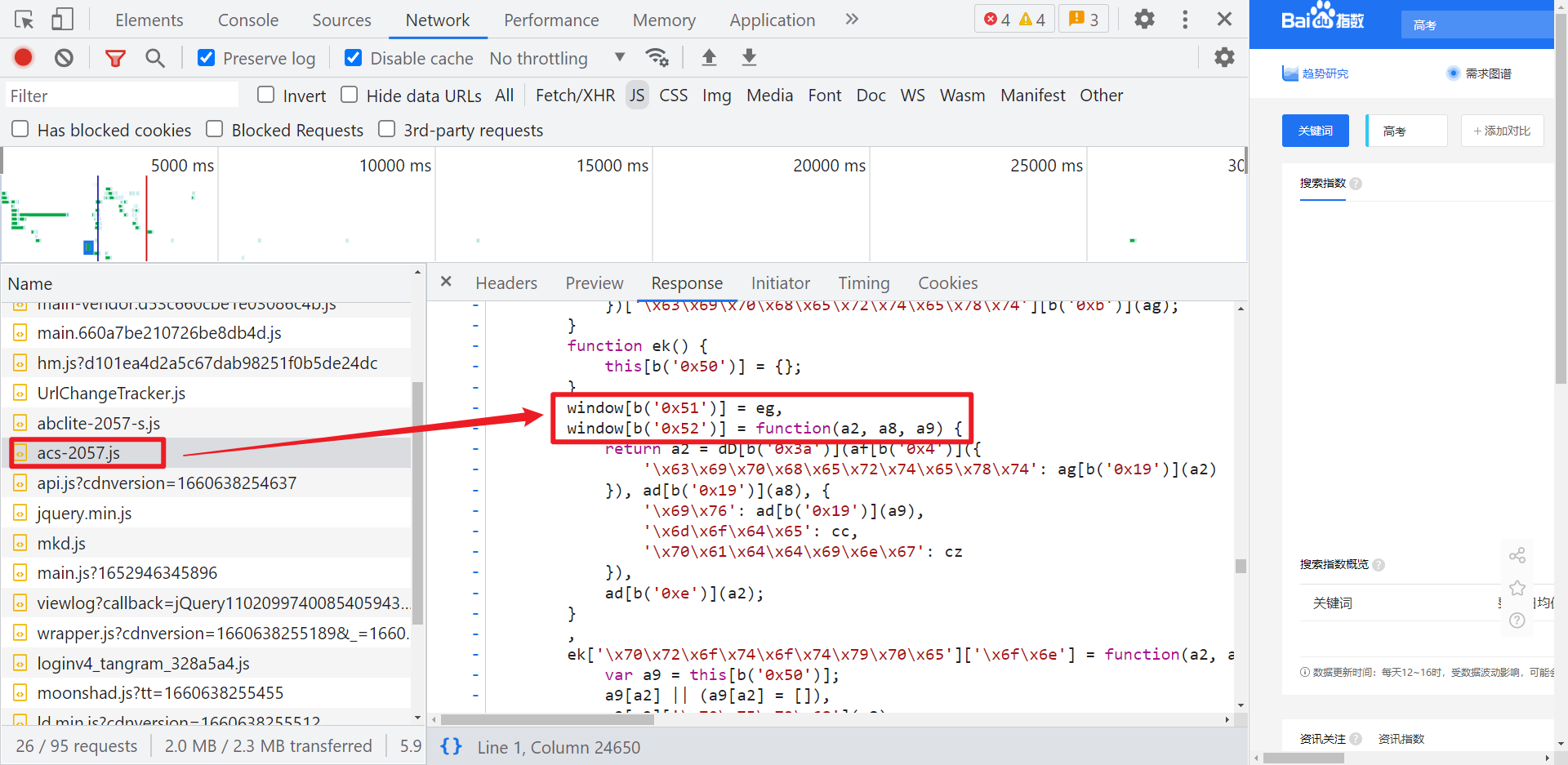
老样子,在 a8() 处下断,刷新接口,即可断下:

百度指数与百度翻译不一样的地方在于开头的那个时间戳不一样,变量 a0 不一样,其他的逻辑都是一样的,我们注意到开头的时间戳隔一段时间就会改变,如果在项目代码中应用,人工定时去改肯定是不合理的,这里的处理思路可以是先在本地固定一套算法,然后每次请求先去拿 acs 开头的那个 JS,拿到内容后,通过正则匹配去拿到那个时间戳,再传到本地的算法里生成最终值,灵活处理即可。
至此,Cipher-Text 和 Acs-Token 就分析结束了,本次逆向的加密算法其实并不难,但是想要找到加密位置需要一定的技巧,另外在写这篇文章时,发现百度翻译不加 Acs-Token 请求又可以了,目前的状况是有时候不加可以请求,有时候不加又不能请求,如果你请求发现报错 {"errno":1022,"errmsg":"访问出现异常,请刷新后重试!","error":1022,"errShowMsg":"访问出现异常,请刷新后重试!"},那就可以尝试加上这个参数。
bilibili 关注 K 哥爬虫,小助理手把手视频教学:https://space.bilibili.com/1622879192
GitHub 关注 K 哥爬虫,持续分享爬虫相关代码!欢迎 star !https://github.com/kgepachong/
以下只演示部分关键代码,不能直接运行!
var window = global;
// 以下部分内容过长,此处省略
// 完整代码关注 GitHub:https://github.com/kgepachong/crawler
(function(){...
})()
function ascToken(translate_url){
// 部分参数直接写死了,不同网站参数值不同,如果在项目中使用,请灵活处理
var a0 = 'uyaqcsmsseqyosiy';
var a1 = '1234567887654321';
var ae = (new Date).getTime();
var a2 = '{"ua":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36","url":' + translate_url + '","platform":"Win32","clientTs":' + ae + ',"version":"2.2.0"}';
// 这里开头的时间戳写死了,如果请求失败请更新这个值
return '1660546809505_' + ae + '_' + window.aes_encrypt(a2, a0, a1);
}
// console.log(ascToken("https://fanyi.baidu.com/#zh/en/%E6%B5%8B%E8%AF%95"))
# ==================================
# --*-- coding: utf-8 --*--
# @Time : 2021-08-12
# @Author : 微信公众号:K哥爬虫
# @FileName: baidufanyi.py
# @Software: PyCharm
# ==================================
import re
import execjs
import requests
from urllib import parse
session = requests.session()
index_url = 'https://fanyi.baidu.com/'
lang_url = 'https://fanyi.baidu.com/langdetect'
translate_api = 'https://fanyi.baidu.com/v2transapi'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
# cookies = {
# "BAIDUID": "624363427DBD2BFCDF0C3D6E129F5C65:FG=1"
# }
def get_params(query):
# 获取 token 和 gtk
session.get(url=index_url, headers=headers)
# print(session.cookies.get_dict())
response_index = session.get(url=index_url, headers=headers)
token = re.findall(r"token: '([0-9a-z]+)'", response_index.text)[0]
gtk = re.findall(r'gtk = "(.*?)"', response_index.text)[0]
# 自动检测语言
response_lang = session.post(url=lang_url, headers=headers, data={'query': query})
lang = response_lang.json()['lan']
return token, gtk, lang
def get_sign_and_token(query, gtk, lang):
with open('baidufanyi_encrypt.js', 'r', encoding='utf-8') as f:
baidu_js = f.read()
sign = execjs.compile(baidu_js).call('e', query, gtk)
translate_url = 'https://fanyi.baidu.com/#%s/en/%s' % (lang, parse.quote(query))
acs_token = execjs.compile(baidu_js).call('ascToken', translate_url)
return sign, acs_token
def get_result(query, lang, sign, token, acs_token):
data = {
'from': lang,
'to': 'en',
'query': query,
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': sign,
'token': token,
}
headers["Acs-Token"] = acs_token
response = session.post(url=translate_api, headers=headers, data=data)
result = response.json()['trans_result']['data'][0]['dst']
return result
def main():
query = input('请输入要翻译的文字:')
token, gtk, lang = get_params(query)
sign, acs_token = get_sign_and_token(query, gtk, lang)
result = get_result(query, lang, sign, token, acs_token)
print('翻译成英文的结果为:', result)
if __name__ == '__main__':
main()


我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
似乎无法为此找到有效的答案。我正在阅读Rails教程的第10章第10.1.2节,但似乎无法使邮件程序预览正常工作。我发现处理错误的所有答案都与教程的不同部分相关,我假设我犯的错误正盯着我的脸。我已经完成并将教程中的代码复制/粘贴到相关文件中,但到目前为止,我还看不出我输入的内容与教程中的内容有什么区别。到目前为止,建议是在函数定义中添加或删除参数user,但这并没有解决问题。触发错误的url是http://localhost:3000/rails/mailers/user_mailer/account_activation.http://localhost:3000/rails/mai
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"
我正在尝试创建密码规则来设计可恢复的密码更改。我通过passwords_controller.rb做了一个父类(superclass),但我需要在应用规则之前检查用户角色,但我所拥有的只是reset_password_token。 最佳答案 假设您的模型是用户:User.with_reset_password_token(your_token_here)Source 关于ruby-on-rails-设计通过reset_password_token获取用户,我们在StackOverflow
简单代码require'net/http'url=URI.parse('getjson/otherdatahere[link]')req=Net::HTTP::Get.new(url.to_s)res=Net::HTTP.start(url.host,url.port){|http|http.request(req)}putsres.body只是想知道如何在phpcURL中放置身份验证token,我是这样做的 curl_setopt($ch,CURLOPT_HTTPHEADER,array('Authorization:Bearerxxx'));//Bearertokenfora
所以...SublimeText具有折叠方法的内置功能,但是一旦方法声明跨越多行,它就会失去这种能力。有谁知道插件或使它工作的方法吗?具体来说,我在使用ruby时遇到了这个问题(我的团队遵守关于行长度的严格风格指南),但语言应该无关紧要。 最佳答案 无需单击出现在函数定义第一行旁边的装订线中的向下箭头,您需要做的就是将光标放在函数的一个缩进行上(不是缩进的函数参数,而是在函数定义本身)并使用CtrlShift[键绑定(bind)(在OSX上使用⌘Alt[)折叠函数及其参数。使用CtrlShift](⌘Alt]在OSX上)展开,或