 在本杂志 2022 年 3 月版发表的题为“用 Zeek 轻松实现网络安全监控”的文章中,我们研究了 Zeek 的功能,并学习了如何开始使用它。现在我们将把我们的学习经验再进一步,看看如何将其与 ELK(即 Elasticsearch、Kibana、Beats 和 Logstash)整合。为此,我们将使用一个叫做 Filebeat 的工具,它可以监控、收集并转发日志到 Elasticsearch。我们将把 Filebeat 和 Zeek 配置在一起,这样后者收集的数据将被转发并集中到我们的 Kibana 仪表盘上。
在本杂志 2022 年 3 月版发表的题为“用 Zeek 轻松实现网络安全监控”的文章中,我们研究了 Zeek 的功能,并学习了如何开始使用它。现在我们将把我们的学习经验再进一步,看看如何将其与 ELK(即 Elasticsearch、Kibana、Beats 和 Logstash)整合。为此,我们将使用一个叫做 Filebeat 的工具,它可以监控、收集并转发日志到 Elasticsearch。我们将把 Filebeat 和 Zeek 配置在一起,这样后者收集的数据将被转发并集中到我们的 Kibana 仪表盘上。apt 来安装 Filebeat,使用以下命令:sudo apt install filebeat.yml 文件,它位于 /etc/filebeat/ 文件夹中:sudo nano /etc/filebeat/filebeat.ymllog,并取消对 enabled:false 的注释,将其改为 true。我们还需要指定存储日志的路径,也就是说,我们需要指定 /opt/zeek/logs/current/*.log。完成这些后,设置的第一部分应该类似于图 1 所示的内容。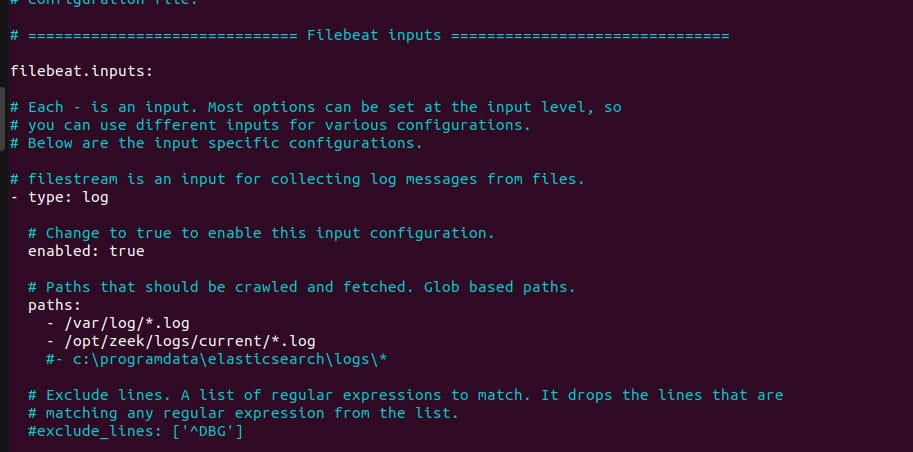 Figure 1: Filebeat config (a)第二件要修改的事情是在输出下的 Elasticsearch 输出部分,取消对
Figure 1: Filebeat config (a)第二件要修改的事情是在输出下的 Elasticsearch 输出部分,取消对 output.elasticsearch 和 hosts 的注释。确保主机的 URL 和端口号与你安装 ELK 时配置的相似。我们把它保持为 localhost,端口号为 9200。在同一部分中,取消底部的用户名和密码的注释,输入安装后配置 ELK 时生成的 Elasticsearch 用户的用户名和密码。完成这些后,参考图 2,检查设置。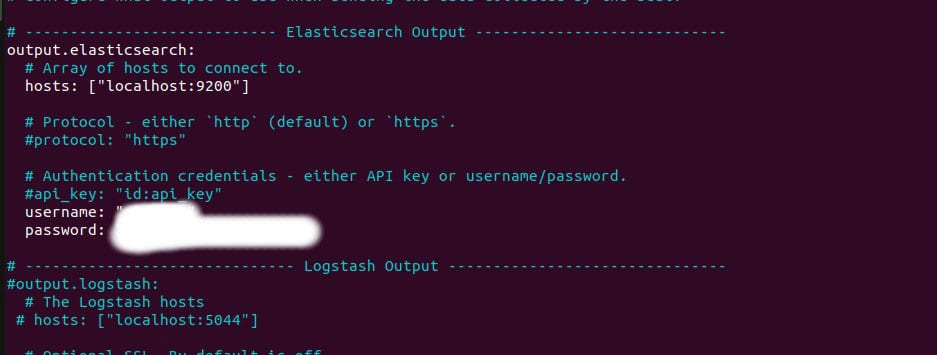 Figure 2: Filebeat config (b)现在我们已经完成了安装和配置,我们需要配置 Zeek,使其以 JSON 格式存储日志。为此,确保你的 Zeek 实例已经停止。如果没有,执行下面的命令来停止它:
Figure 2: Filebeat config (b)现在我们已经完成了安装和配置,我们需要配置 Zeek,使其以 JSON 格式存储日志。为此,确保你的 Zeek 实例已经停止。如果没有,执行下面的命令来停止它:cd /opt/zeek/bin
./zeekctl stoplocal.zeek 中添加一小行,它存在于 opt/zeek/share/zeek/site/ 目录中。以 root 身份打开该文件,添加以下行:@load policy/tuning/json-logs.zeek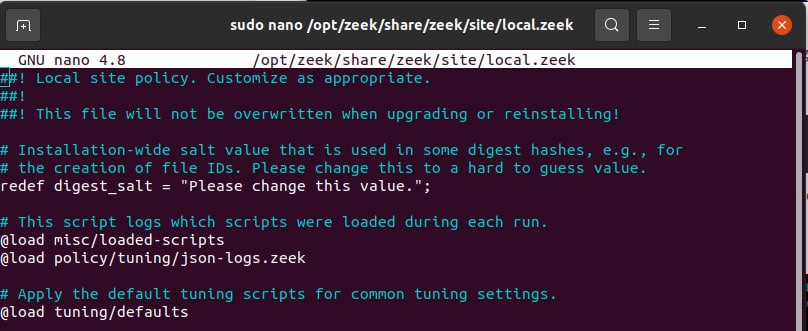 Figure 3: local.zeek file由于我们改变了 Zeek 的一些配置,我们需要重新部署它,这可以通过执行以下命令来完成:
Figure 3: local.zeek file由于我们改变了 Zeek 的一些配置,我们需要重新部署它,这可以通过执行以下命令来完成:cd /opt/zeek/bin
./zeekctl deploysudo filebeat modules enable zeekzeek.yml 文件要记录什么类型的数据。这可以通过修改 /etc/filebeat/modules.d/zeek.yml 文件完成。在这个 .yml 文件中,我们必须提到这些指定的日志存放在哪个目录下。我们知道,这些日志存储在当前文件夹中,其中有几个文件,如 dns.log、conn.log、dhcp.log 等等。我们需要在每个部分提到每个路径。如果而且只有在你不需要该文件/程序的日志时,你可以通过把启用值改为 false 来舍弃不需要的文件。例如,对于 dns,确保启用值为 true,并且路径被配置:var.paths: [ “/opt/zeek/logs/current/dns.log”, “/opt/zeek/logs/*.dns.json” ]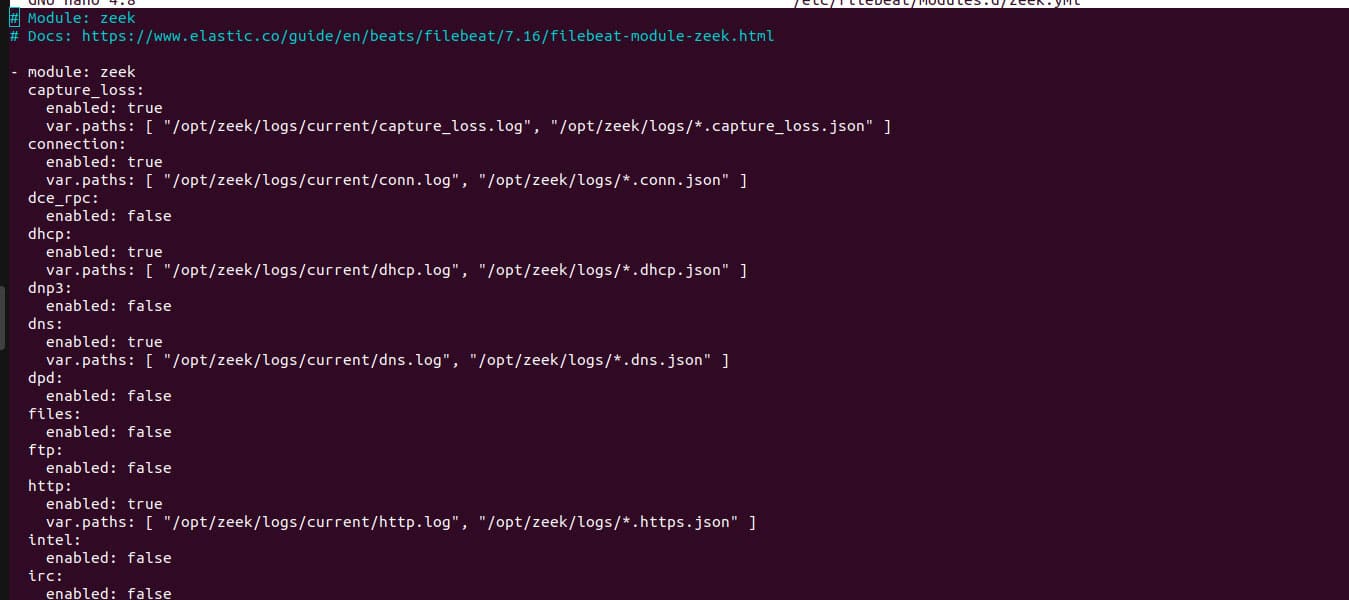 Figure 4: zeek.yml configuration现在是启动 Filebeat 的时候了。执行以下命令:
Figure 4: zeek.yml configuration现在是启动 Filebeat 的时候了。执行以下命令:sudo filebeat setup
sudo service filebeat start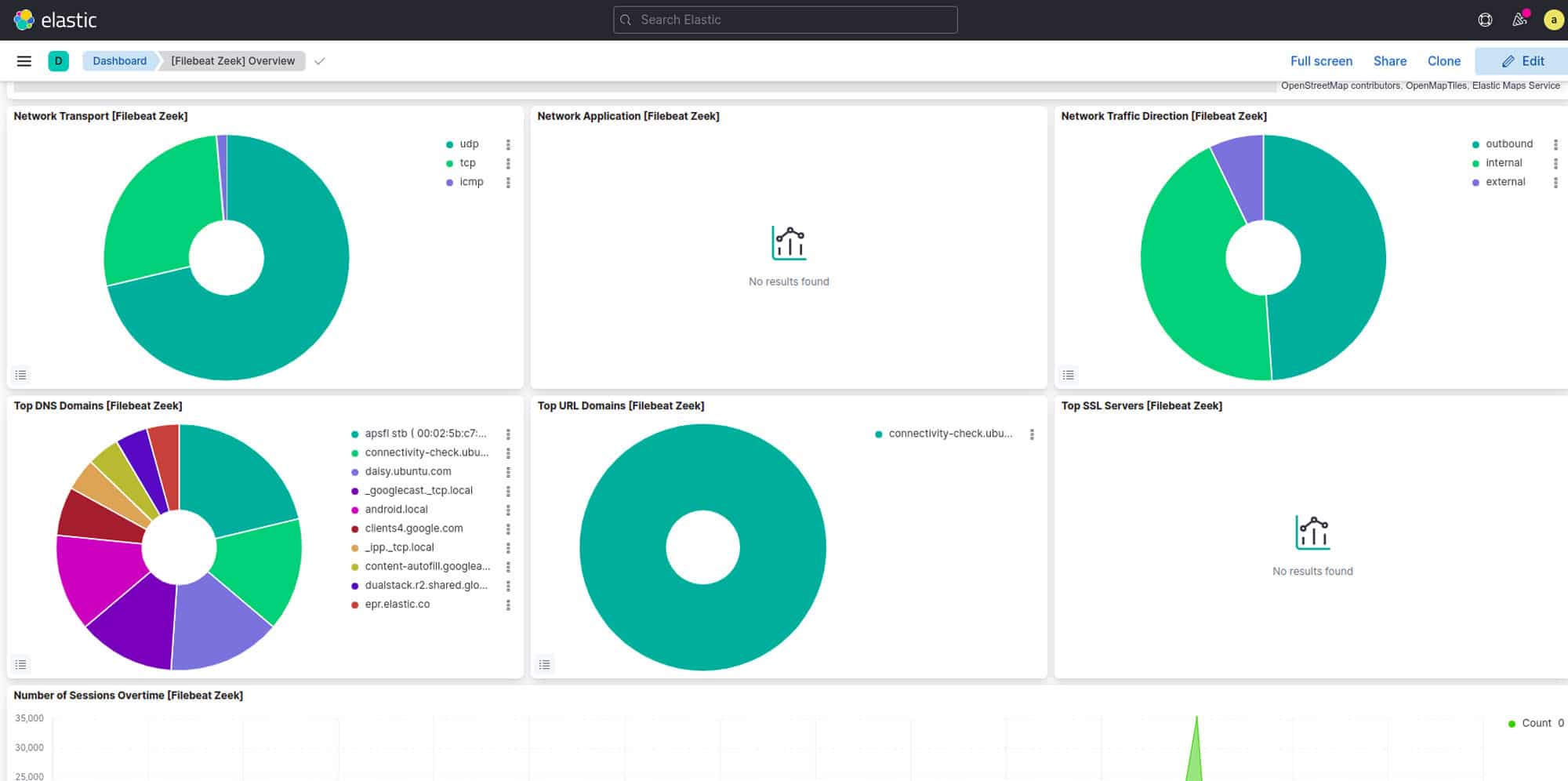 Figure 6: Dashboard of Kibana (Network)现在让我们进入发现选项卡,通过使用查询进行过滤来检查结果:这个查询将过滤它在一定时间内收到的所有数据,只向我们显示名为 Zeek 的模块的数据(图 7)。
Figure 6: Dashboard of Kibana (Network)现在让我们进入发现选项卡,通过使用查询进行过滤来检查结果:这个查询将过滤它在一定时间内收到的所有数据,只向我们显示名为 Zeek 的模块的数据(图 7)。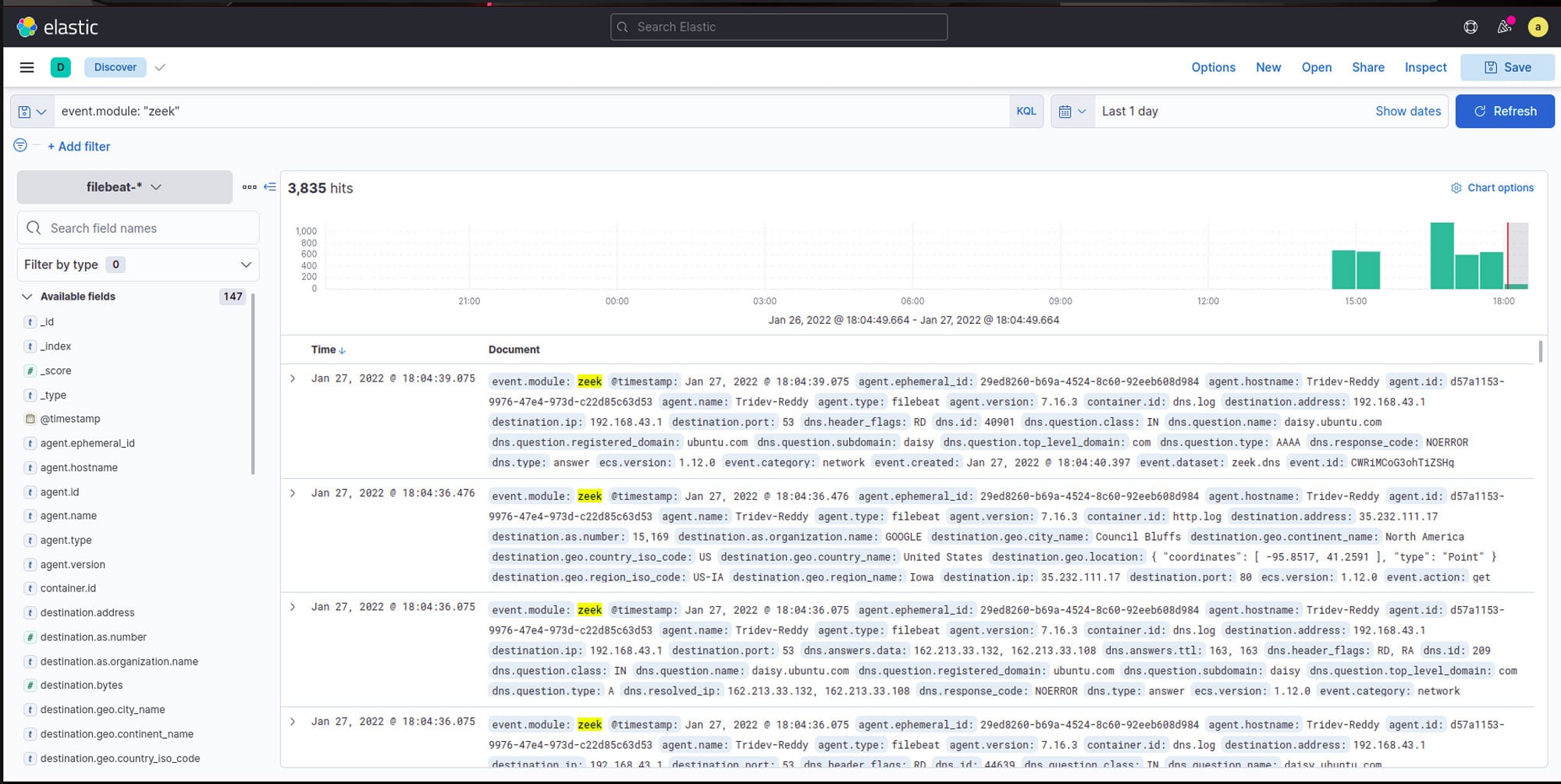 Figure 7: Filtered data by event.module query
Figure 7: Filtered data by event.module query我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
三分钟集成Tap防沉迷SDK(Unity版)一、SDK介绍基于国家对上线所有游戏必须增加防沉迷功能的政策下,TapTap推出防沉迷SDK,供游戏开发者进行接入;允许未成年用户在周五、六、日以及法定节假日晚上8:00-9:00进行游戏,防沉谜时间段进入游戏会弹窗进行提示!开发环境要求:Unity2019.4或更高版本iOS10或更高版本Android5.0(APIlevel21)或更高版本🔗Unity集成Demo参考链接🔗UnityTapSDK功能体验APK下载链接二、集成前准备1.创建应用进入开发者后台,按照提示开始创建应用;2.开通服务在使用TDS实名认证和防沉迷服务之前,需要在上面创建的应
我被这个难住了。到目前为止教程中的一切都进行得很顺利,但是当我将这段代码添加到我的/spec/requests/users_spec.rb文件中时,事情开始变得糟糕:describe"success"doit"shouldmakeanewuser"dolambdadovisitsignup_pathfill_in"Name",:with=>"ExampleUser"fill_in"Email",:with=>"ryan@example.com"fill_in"Password",:with=>"foobar"fill_in"Confirmation",:with=>"foobar"cl
我需要一些指导来了解如何将Angular整合到rails中。选择Rails的原因:我喜欢他们偏执的做事方式。还有迁移,gem真的很酷。使用angular的原因:我正在研究和寻找最适合SPA的框架。Backbone似乎太抽象了。我不得不在Angular和Ember之间做出选择。我首先开始阅读Angular,它对我来说很有意义。所以我从来没有去读过关于ember的文章。使用Angular和Rails的原因:我研究并尝试使用小型框架,例如grape、slim(是的,我也使用php)。但我觉得需要坚持项目的长期范围。我个人喜欢用Rails的方式做事。这就是我需要帮助的地方,我在Rails4中有
有没有人有在Maven中运行用Ruby编写的单元测试的经验。任何输入,如要使用的库/maven插件,将不胜感激!我们已经在使用Maven+hudson+Junit。但是我们正在引入Ruby单元测试,找不到任何同样好的组合。 最佳答案 我建议让Maven使用ExecMavenPlugin启动rake测试(exec:exec目标)并使用ci_reportergem生成单元测试结果的XML文件,Hudson、Bamboo等可以读取该文件,以与JUnit测试相同的格式显示测试结果。如果您不需要使用mvntest运行Ruby测试,您也可以只使
目前我有一小套针对我的网络服务器运行的集成测试,它发出请求并断言一些关于响应应该是什么的假设。这些是用Ruby编写的,生成http请求。我一直在看Gatling作为压力测试工具,但我想知道它是否也可以用于集成测试。这样,所有端点请求都可以在压力测试和集成测试中重复使用。我可能在这里失去了一些东西,因为没有RSpec的BDD,但不必两次创建相同的测试。有没有人有这样使用gatling的经验? 最佳答案 您可以使用AssertionAPI并设置验收标准。但是,Gatling不是浏览器,不会运行/测试您的Javascript,因此这种方法
文章目录前言一、Elasticsearch版本介绍二、客户端种类三、客户端与版本兼容性四、引入Elasticsearch依赖包五、客户端配置六、Elasticsearch使用前言ElasticSearch是Elastic公司出品的一款功能强大的搜索引擎,被广泛的应用于各大IT公司,它的代码位于https://github.com/elastic/elasticsearch,目前是一个开源项目。ElasticSearch公司的另外两个开源产品Logstash、Kibana与ElasticSearch构成了著名的ELK技术栈。。他们三个共同形成了一个强大的生态圈。简单地说,Logstash负责数据
集成背景我们当前集群使用的是ClouderaCDP,Flink版本为ClouderaVersion1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置FlinkHome,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。集成步骤版本匹配问题解决首先解决无法识别Cloudera中的FlinkHome问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。修改对象:修改源码:(解决无法匹配clouderajar