 这种现象一般表现为:
这种现象一般表现为:
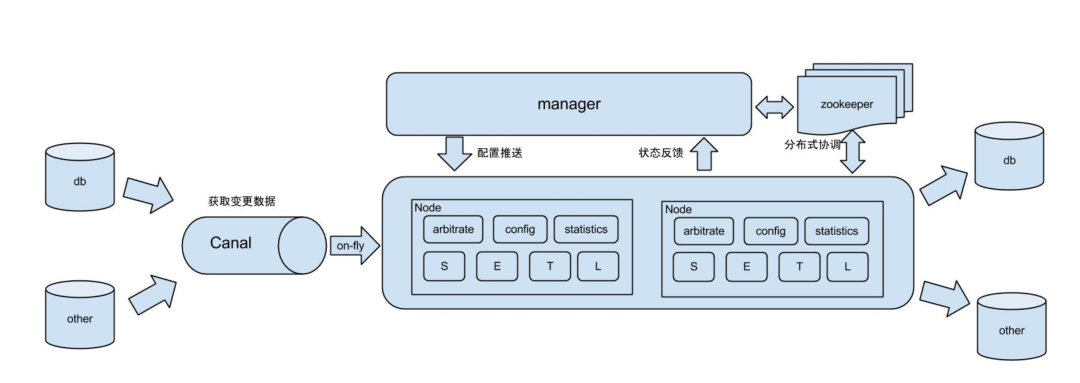 基于Canal开源产品,获取数据库增量日志数据并下发,下游消费增量数据直接生成大宽表,但是宽表还是写入mysql数据库,实现单表查询,单表查询速度显著提升,无olap数据库的常见做法,通过宽表减少join带来的性能消耗。但是存在以下几个问题:
基于Canal开源产品,获取数据库增量日志数据并下发,下游消费增量数据直接生成大宽表,但是宽表还是写入mysql数据库,实现单表查询,单表查询速度显著提升,无olap数据库的常见做法,通过宽表减少join带来的性能消耗。但是存在以下几个问题: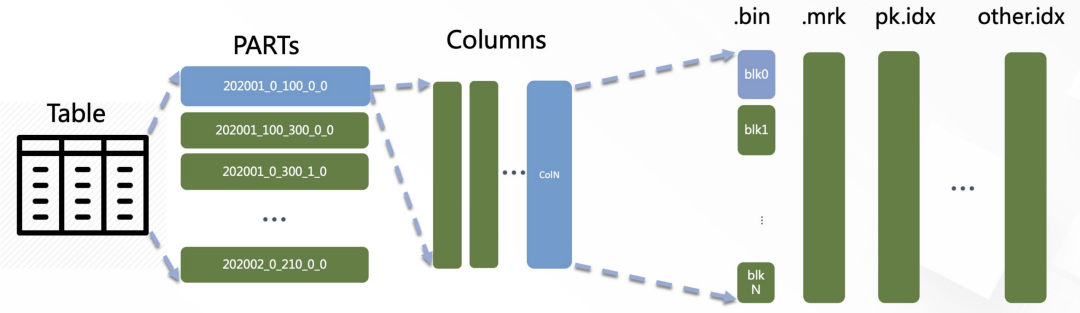
 附:clickhouse不支持标准的upsert模式,可以通过使用AggregatingMergeTree 引擎字段类型使用SimpleAggregateFunction(anyLast, Nullable(UInt64)) 合并规则取最后一条非null数据可以实现upsert相似的功能,但读时合并性能有影响。
附:clickhouse不支持标准的upsert模式,可以通过使用AggregatingMergeTree 引擎字段类型使用SimpleAggregateFunction(anyLast, Nullable(UInt64)) 合并规则取最后一条非null数据可以实现upsert相似的功能,但读时合并性能有影响。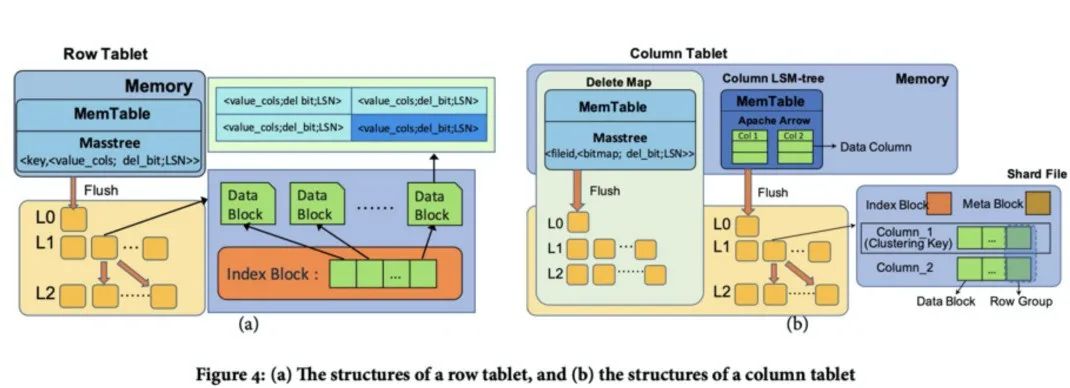 这样一个行列混合的olap数据库,支持upsert,支持存算分离,还是比较符合我们的预期。
这样一个行列混合的olap数据库,支持upsert,支持存算分离,还是比较符合我们的预期。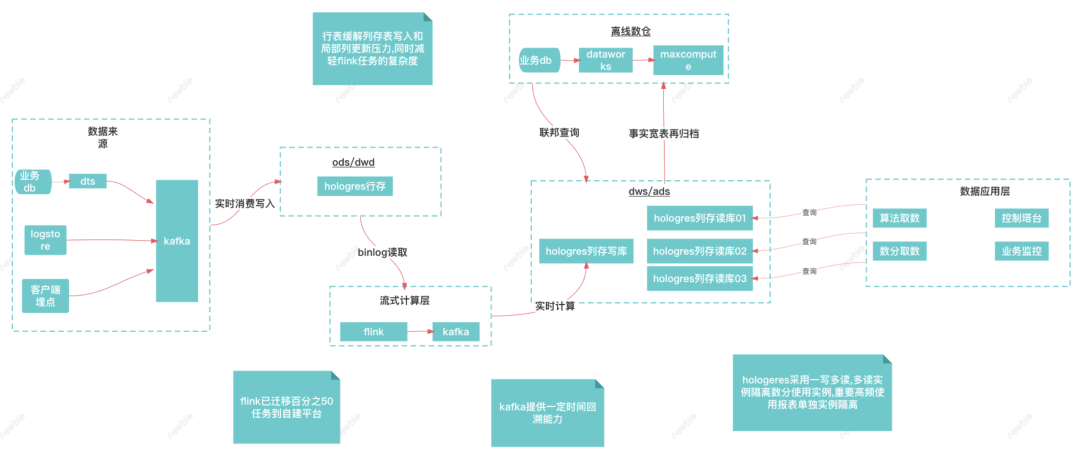 目前这样一套架构支持了供应链每天数千人的报表取数需求,以及每天10亿数据量的导出,访问量在得物所有to B系统中排名靠前。
目前这样一套架构支持了供应链每天数千人的报表取数需求,以及每天10亿数据量的导出,访问量在得物所有to B系统中排名靠前。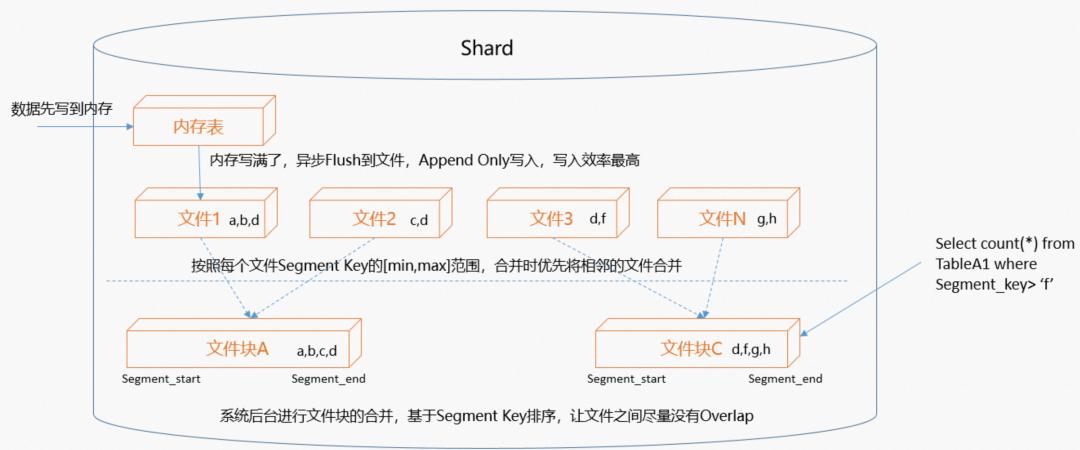 设置合理的segment_key如有序的时间字段,可以做到完全顺序写。每个segment文件都有个min,max值,所有的时间字段过来只需要去比较下在不在这个最小值最大值之间(这个动作开销很低),不在范围内直接跳过,在不带segment_key查询的条件下,也能极大的降低所需要过滤的文件数量。
设置合理的segment_key如有序的时间字段,可以做到完全顺序写。每个segment文件都有个min,max值,所有的时间字段过来只需要去比较下在不在这个最小值最大值之间(这个动作开销很低),不在范围内直接跳过,在不带segment_key查询的条件下,也能极大的降低所需要过滤的文件数量。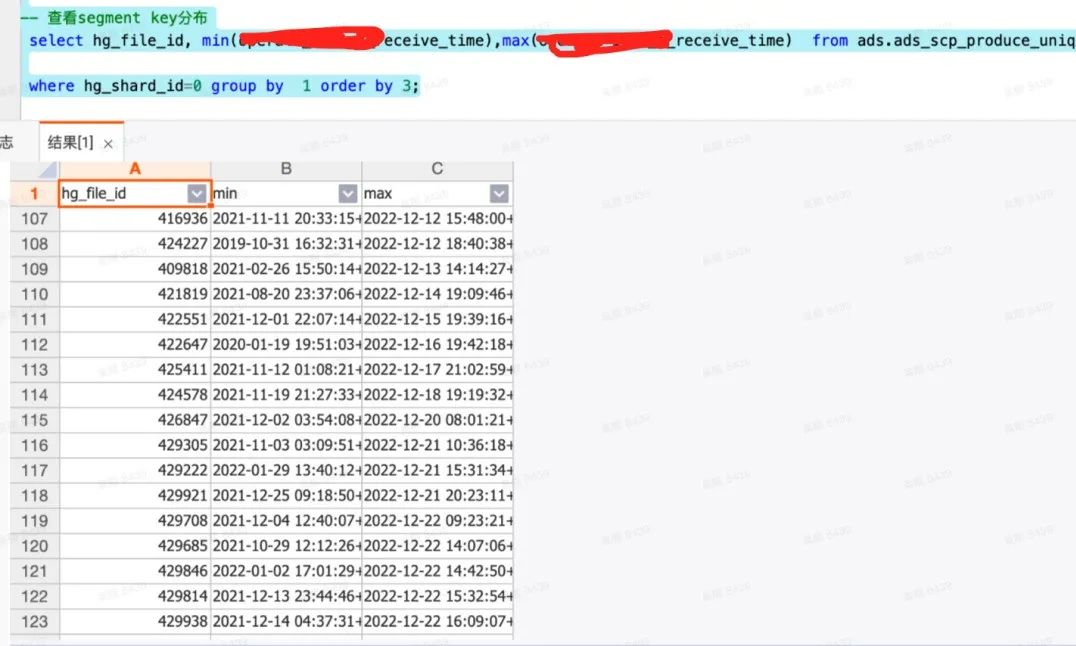
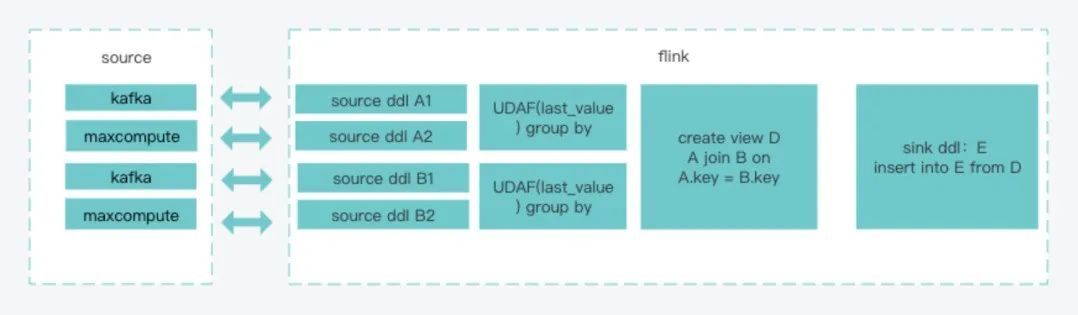 (1)离线按key去重,每个key只保留一条,减少消息量下发。(2)离线和实时数据合并,使用last_value取相同主键最新事件时间戳的一条数据。(3)使用union all + group by方式是可作为代替join的一个选择。(4)实时数据取当日数据,离线数据取历史数据,防止数据漂移,实时数据需前置一小时。
(1)离线按key去重,每个key只保留一条,减少消息量下发。(2)离线和实时数据合并,使用last_value取相同主键最新事件时间戳的一条数据。(3)使用union all + group by方式是可作为代替join的一个选择。(4)实时数据取当日数据,离线数据取历史数据,防止数据漂移,实时数据需前置一小时。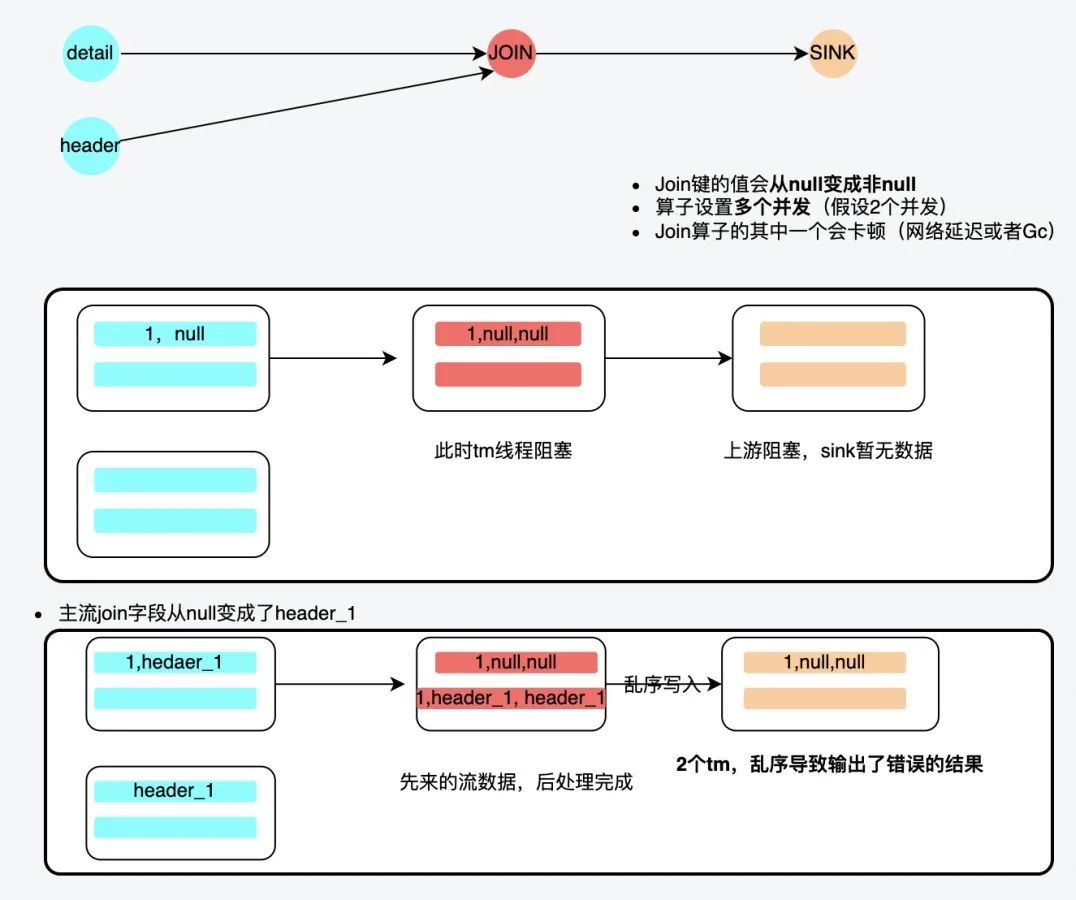
insert into sink
Select detail.id,detail.header_id,header.id
from detail
left join (
Select detail.id AS detail_id,detail.header_id,header.id
from header
inner join detail
on detail.header_id = header.id
) headerNew
on detail.id = headerNew.detail_id

 动态配置报表:
动态配置报表: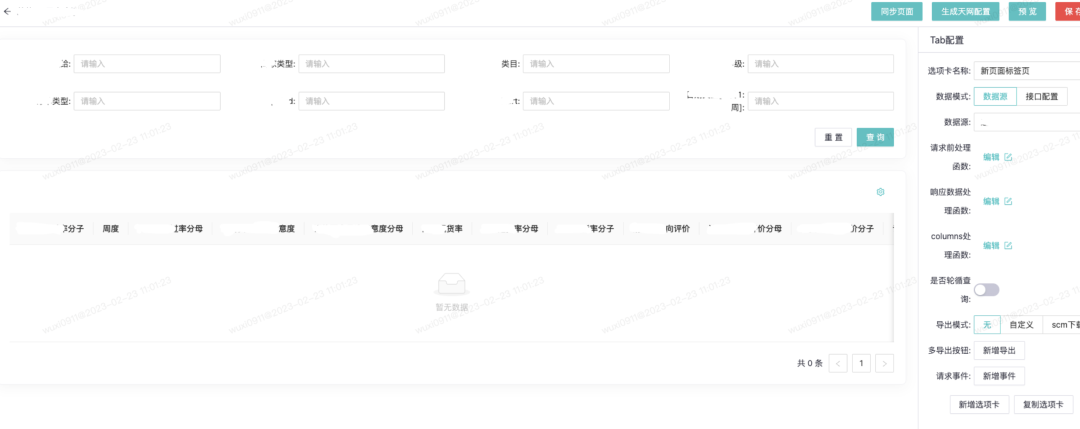
 (1)利用写在holo,计算在mc避免holo这种内存数据库,在极端查询内存被打爆的问题,利用mc的计算能力可以搞定一些事实表join的问题提升一些灵活度。
(1)利用写在holo,计算在mc避免holo这种内存数据库,在极端查询内存被打爆的问题,利用mc的计算能力可以搞定一些事实表join的问题提升一些灵活度。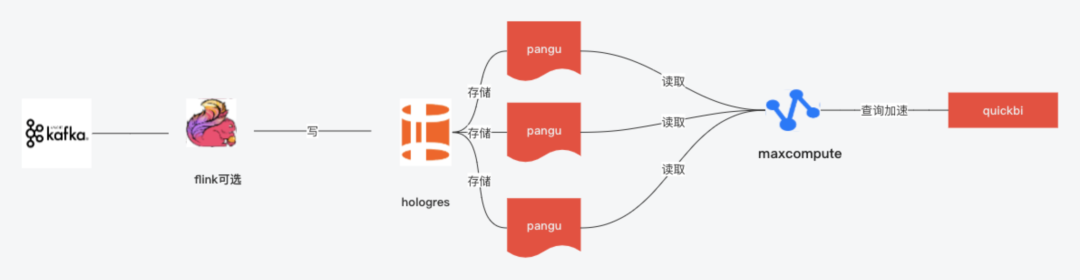 (2) 借助apache hudi推进湖仓一体,hudi做批流存储统一,flink做批流计算统一,一套代码,提供5-10分钟级的准实时架构,缓解部分场景只需要准时降低实时计算成本。
(2) 借助apache hudi推进湖仓一体,hudi做批流存储统一,flink做批流计算统一,一套代码,提供5-10分钟级的准实时架构,缓解部分场景只需要准时降低实时计算成本。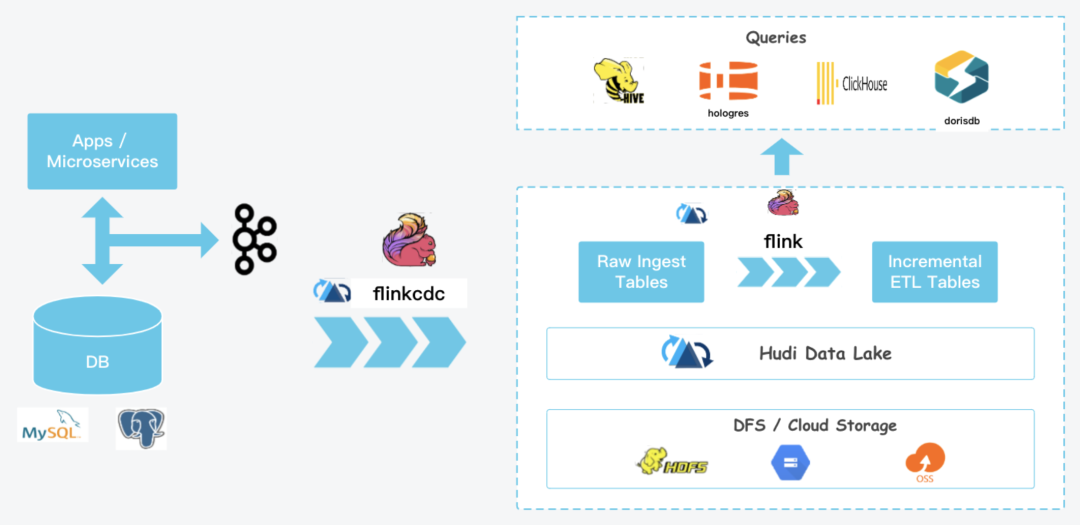
我在加密来self正在使用的第三方供应商的值时遇到问题。他们的指令如下:1)Converttheencryptionpasswordtoabytearray.2)Convertthevaluetobeencryptedtoabytearray.3)Theentirelengthofthearrayisinsertedasthefirstfourbytesontothefrontofthefirstblockoftheresultantbytearraybeforeencryption.4)EncryptthevalueusingAESwith:1.256-bitkeysize,2.25
我正在开发西洋跳棋实现,其中有许多易于测试的方法,但我不确定如何测试我的主要#play_game方法。我的大多数方法都可以很容易地确定输入和输出,因此也很容易测试,但这种方法是多方面的,实际上并没有容易辨别的输出。这是代码:defplay_gameputs@gui.introwhile(game_over?==false)message=nil@gui.render_board(@board)@gui.move_requestplayer_input=getscoordinates=UserInput.translate_move_request_to_coordinates(play
方法应返回-1,0或1分别表示“小于”、“等于”和“大于”。对于某些类型的可排序对象,通常将排序顺序基于多个属性。以下是可行的,但我认为它看起来很笨拙:classLeagueStatsattr_accessor:points,:goal_diffdefinitializepts,gd@points=pts@goal_diff=gdenddefothercompare_pts=pointsother.pointsreturncompare_ptsunlesscompare_pts==0goal_diffother.goal_diffendend尝试一下:[LeagueStats.new(
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和
假设我有一个函数defodd_or_evennifn%2==0return:evenelsereturn:oddendend我有一个简单的可枚举数组simple=[1,2,3,4,5]然后我用我的函数在map中运行它,使用一个do-endblock:simple.mapdo|n|odd_or_even(n)end#=>[:odd,:even,:odd,:even,:odd]如果不首先定义函数,我怎么能做到这一点?例如,#doesnotworksimple.mapdo|n|ifn%2==0return:evenelsereturn:oddendend#Desiredresult:#=>[
这行ruby代码检测素数(太棒了!)。("1"*n)!~/^1?$|^(11+?)\1+$/#wherenisapositiveinteger详细信息在这篇博文中解释http://www.noulakaz.net/weblog/2007/03/18/a-regular-expression-to-check-for-prime-numbers/我很好奇它在BIG-O表示法中的表现。有人帮忙吗? 最佳答案 根据经验数据,它似乎是O(n2)。我对前10000个质数中的每100个运行Ruby代码。以下是结果:蓝点是记录的时间,橙色线是
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
我在供应商css文件引用的供应商文件夹下有很多供应商图像。我正在使用Heroku和S3进行生产,像background-image:url("../images/sprite.png");之类的东西正在开发中,但不在生产中,因为图像url指向S3url。它也没有被预编译,所以不确定我是否应该将它作为Assets预编译的一部分,但我想远离它,因为我需要手动将所有图像文件复制到assets/images文件夹并更改css文件中的引用,方法是将其更改为scss和asset_url(这似乎工作正常)有没有办法只从供应商css文件中引用S3url我还使用asset_syncgem上传到S3
我正在使用searchkick库作为产品搜索的elasticsearch客户端。https://github.com/ankane/searchkick可以创建'OR'条件和'AND'条件;AND运算Product.search其中:{price:{lte:200},in_stock:true}或运算Product.search其中:{或:[[{in_stock:true},{backordered:true}]]}但我坚持使用searchkick创建多个“AND”“OR”条件。我需要类似的东西A或B或(C和D)或者我需要这样,A与B与(C或D)请指导我,如何实现这一目标谢谢