文章目录
及早集合 与 惰性集合 :
在 惰性集合 中 集合元素的 初始化 是 惰性初始化 ;
Kotlin 中提供了一个 惰性集合 , 称为 序列 Sequence ;
在 序列 中 , 不记录元素个数 , 也 不对其内容进行排序 , 在该 <font color=bluegreen序列中 元素可能有无限多个 ;
序列中的元素 是由 数据源 产生的 , 其元素个数 可能有无限多个 ;
“generateSequence” 函数 是 Kotlin 标准库 中的一个函数,属于 Kotlin 的 序列生成器。
“generateSequence” 函数 可以生成一个 惰性序列,并且支持从指定的序列中生成元素。
生成的序列是惰性的,意味着 请求元素时,才会 生成相应的元素。这使得开发者可以在 不需要处理整个序列的情况下,处理序列中的元素。
Kotlin 提供的 " generateSequence " 标准库函数 , 原型如下 :
/**
* 返回由起始值[seed]和函数[nextFunction]定义的序列,每次迭代时,该函数被调用以根据前一个值计算下一个值
*
* 序列产生值,直到遇到第一个null值。
* 如果[seed]是null,则生成一个空序列。
*
* 该序列可以多次迭代,每次都从[seed]开始。
*
* @see kotlin.sequences.sequence
*
* @sample samples.collections.Sequences.Building.generateSequenceWithSeed
*/
@kotlin.internal.LowPriorityInOverloadResolution
public fun <T : Any> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction)
Kotlin 的 generateSequence 函数是一种 生成序列 的方法,它可以生成 可迭代的、有限或无限的序列。
generateSequence 函数 接收两个参数:
每次迭代时,nextFunction 都会被调用以生成下一个值,并且该序列会不断生成值,直到遇到第一个 null 值。如果起始值为 null,那么将会生成一个空序列。
该序列可以 多次迭代,每次都从起始值开始。这是因为 generateSequence 返回一个实现了 Sequence 接口的对象,这意味着你可以 在多次迭代之间重用该序列。
通过使用 generateSequence,你可以简化代码,提高可读性和可维护性,并且可以 生成更复杂的序列,如斐波那契数列、自然数序列等。
使用方法 : 使用 “generateSequence” 函数 并 传递一个函数作为参数 ; 函数必须返回 “Nullable” 类型的值,当序列不再生成元素时返回 “null”。
“generateSequence” 函数 是一种高效且灵活的 生成序列 的方法,它可以用于许多应用程序,如 生成指定数量的元素、生成无限循环的序列等。
示例 : 以下代码生成一个从 1 开始的整数序列:
val sequence = generateSequence(1) { it + 1 }
println(sequence.take(10).toList()) // prints [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
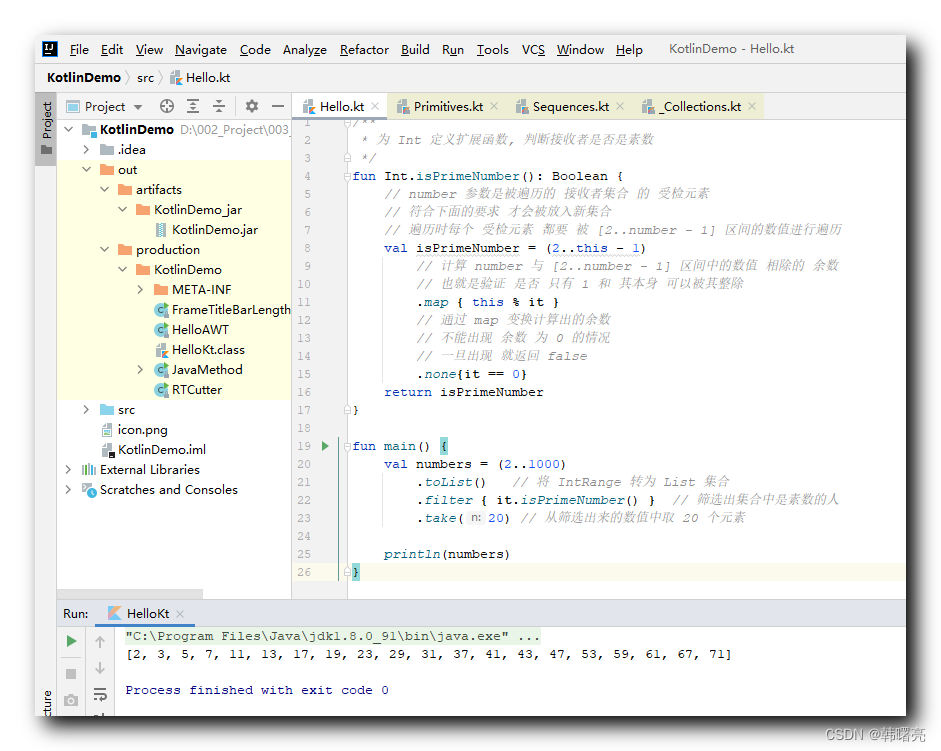
取 从 2 开始的 前 20 个 素数 ;
代码示例 : 下面的代码中 , 从 1 ~ 1000 的区间内查找素数 , 必须将 1000 个元素的集合生成出来 , 然后逐个遍历 ;
/**
* 为 Int 定义扩展函数, 判断接收者是否是素数
*/
fun Int.isPrimeNumber(): Boolean {
// number 参数是被遍历的 接收者集合 的 受检元素
// 符合下面的要求 才会被放入新集合
// 遍历时每个 受检元素 都要 被 [2..number - 1] 区间的数值进行遍历
val isPrimeNumber = (2..this - 1)
// 计算 number 与 [2..number - 1] 区间中的数值 相除的 余数
// 也就是验证 是否 只有 1 和 其本身 可以被其整除
.map { this % it }
// 通过 map 变换计算出的余数
// 不能出现 余数 为 0 的情况
// 一旦出现 就返回 false
.none{it == 0}
return isPrimeNumber
}
fun main() {
val numbers = (2..1000)
.toList() // 将 IntRange 转为 List 集合
.filter { it.isPrimeNumber() } // 筛选出集合中是素数的人
.take(20) // 从筛选出来的数值中取 20 个元素
println(numbers)
}
执行结果 :
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71]
使用传统方式实现素数查找 , 如 : 从 1 ~ 1000 的区间内查找素数 , 必须将 1000 个元素的集合生成出来 , 然后逐个遍历 ;
如果使用 序列 Sequence 实现 , 则 只需要实现需要的部分 , 没有遍历的元素不会生成 ;
代码示例 :
/**
* 为 Int 定义扩展函数, 判断接收者是否是素数
*/
fun Int.isPrimeNumber(): Boolean {
// number 参数是被遍历的 接收者集合 的 受检元素
// 符合下面的要求 才会被放入新集合
// 遍历时每个 受检元素 都要 被 [2..number - 1] 区间的数值进行遍历
val isPrimeNumber = (2..this - 1)
// 计算 number 与 [2..number - 1] 区间中的数值 相除的 余数
// 也就是验证 是否 只有 1 和 其本身 可以被其整除
.map { this % it }
// 通过 map 变换计算出的余数
// 不能出现 余数 为 0 的情况
// 一旦出现 就返回 false
.none{it == 0}
return isPrimeNumber
}
fun main() {
val numbers = generateSequence(2) { it + 1 } // 设置初始值为 2 , 然后每次值自增 1
.filter { it.isPrimeNumber() } // 遍历序列元素 , 查询是否是素数
.take(20) // 取前 20 个素数
println(numbers)
}
执行结果 :
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71]

下面是 普通集合 调用的 take 扩展函数 原型 和 序列 Sequence 调用的 take 扩展函数 的对比 , 两个 函数 是不同的 , take 函数决定了 取值的个数 ;
序列 Sequence 调用 take 函数时 , take 函数调用了序列的部分内容 , 决定了 序列 Sequence 的执行次数 , 生成多少元素 , 如 : 上述代码示例中 take 函数取够了 20 个素数 , 之后 Sequence 就不再继续生成后续元素了 ;
普通集合 调用的 take 扩展函数 原型 和 序列 Sequence 调用的 take 扩展函数 的对比 :
/**
* Returns a list containing first [n] elements.
*
* @throws IllegalArgumentException if [n] is negative.
*
* @sample samples.collections.Collections.Transformations.take
*/
public fun <T> Iterable<T>.take(n: Int): List<T> {
require(n >= 0) { "Requested element count $n is less than zero." }
if (n == 0) return emptyList()
if (this is Collection<T>) {
if (n >= size) return toList()
if (n == 1) return listOf(first())
}
var count = 0
val list = ArrayList<T>(n)
for (item in this) {
list.add(item)
if (++count == n)
break
}
return list.optimizeReadOnlyList()
}
/**
* Returns a sequence containing first [n] elements.
*
* The operation is _intermediate_ and _stateless_.
*
* @throws IllegalArgumentException if [n] is negative.
*
* @sample samples.collections.Collections.Transformations.take
*/
public fun <T> Sequence<T>.take(n: Int): Sequence<T> {
require(n >= 0) { "Requested element count $n is less than zero." }
return when {
n == 0 -> emptySequence()
this is DropTakeSequence -> this.take(n)
else -> TakeSequence(this, n)
}
}
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最