第一次:es 读取速度快,ClickHouse 插入速度慢,导致ClickHouse CPU和内存压力缓慢上升,最终打爆,于是读与写分离,这里对 es 读取功能加了速度控制功能,在 scrollid 不到期的情况下,能够动态调整速度两边保持平衡。
第二次:ClickHouse 每次插入的数据少,然后插入次数比较频繁,会报错too many parts,这里推荐每批次插入20-50万条数据最佳,否则会导致ClickHouse 频繁的数据合并,我这边读 es 线程每次 scroll 65000 条记录,写 ClickHouse 线程开了 100 个,判断队列长度大于 20 万的时候,一次全部取出,然后插入 ClickHouse。
如果报错如下错误,问了腾讯云,也是加大每批次的插入数据条数,减少与 CK 的交互次数,因为小文件过多,后台就会生成很多的 merge 任务。
Table is in readonly mode的告警信息。
第三次:ClickHouse 插入无法部分成功,statement execute 失败之后,事务 context 会断开,会导致你 commit 的时候,整体失败,因为每次我都插入20-50万条记录,其中一两条数据异常会导致其他几十万数据也插入失败,最终导致插入10亿条数据的时候有几百万数据未插入,
这里我的方案是,statement execute 失败之后,不立即回滚,跑完所有语句,然后记录所有失败的语句,最后回滚事务,然后再重启一个事务,剔除异常的数据之后,再跑一次,那么就会只有少量失败记录插入失败,把这些失败数据写入 redis 集合,后续再处理。
第四次:es 按月分索引,读取数据 scroll 默认按 _doc 排序,这个查询效率是最高的,但是因为不是按照时间序排的,取出来的数据可能分布在不同的天,而 ClickHouse 是按照天来建立 partition,这样就导致了,每次插入的 50万数据,会分配到 N 个分区,由于 ClickHouse 的合并是按照分区来的,这样就导致每次插入需要合并 N 个分区,ck 压力暴增,最终拒绝服务,所以这里需要按照时间排序来 scroll es 数据,这样子,每次插入的数据,以及最近一段时间插入的数据,基本上都在同一天,提升了 ClickHouse 合并效率。
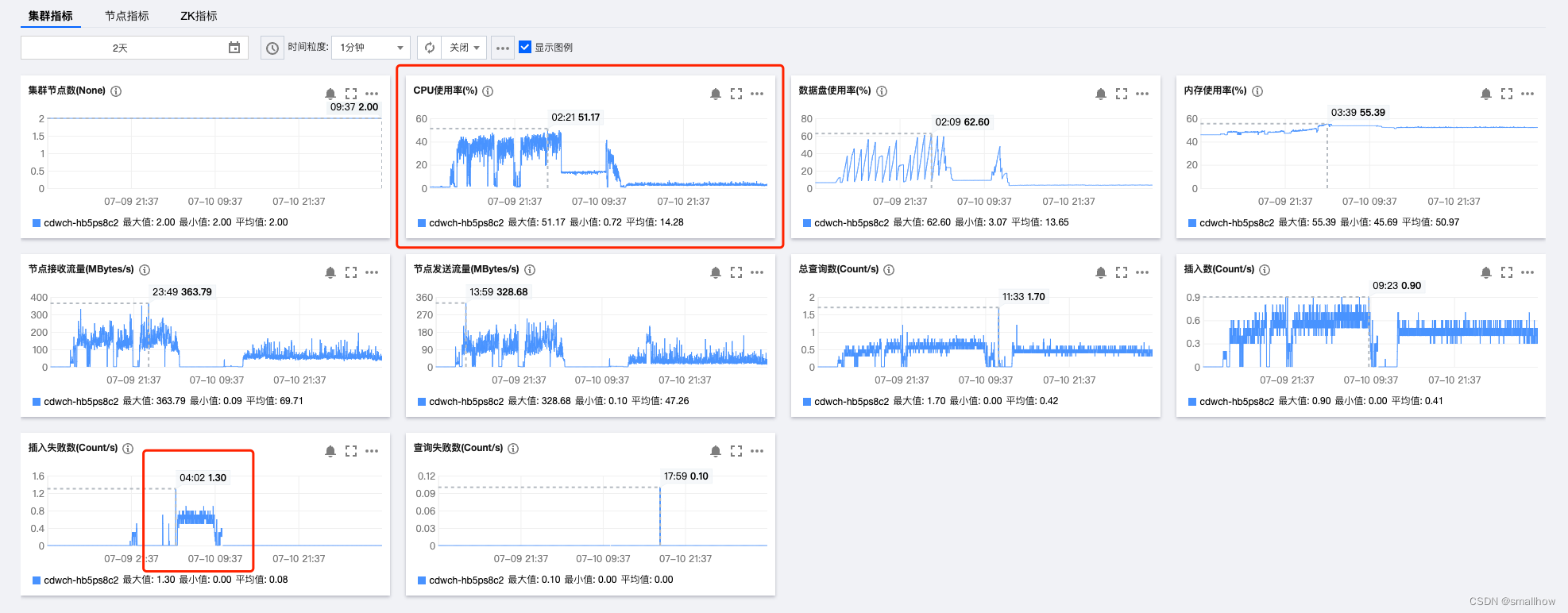
修改前每分钟 600万插入,CPU使用率在高位运行,说明一直在合并数据,修改后每分钟插入 400万数据,会慢一些,但是 CPU 一直在 10% 以下。
从上图还可以看出,之前的数据插入,会一直写到热盘,并且等合并完成之后,才会合并数据并迁移到冷盘,优化之后,会持续合并数据到冷盘,热盘的整体使用率一直稳定在低位。
迁移程序也因为数据处理速度快,避免了数据堆积,内存占用大的问题。
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_