Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
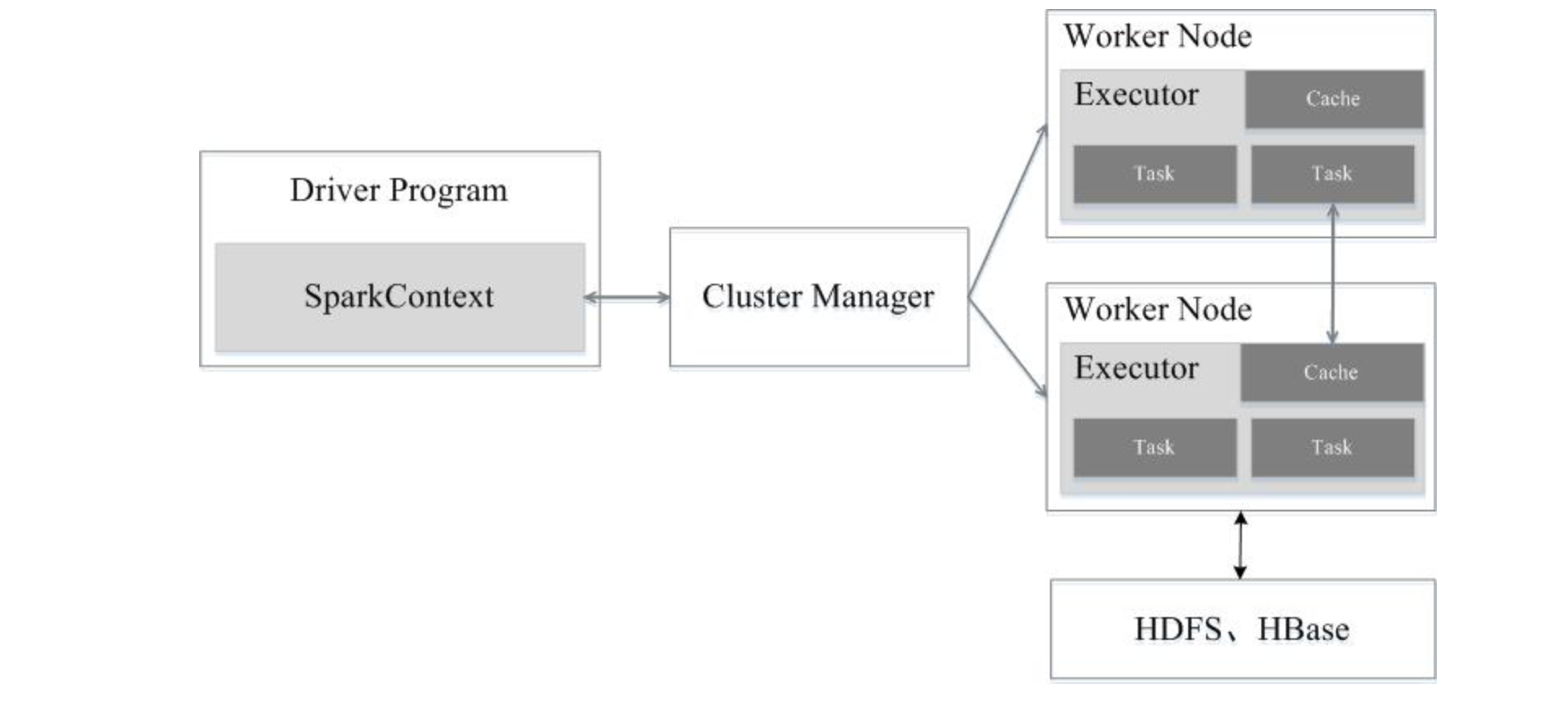
用户编写的Spark应用程序,包含了Driver Program以及在集群上运行的程序代码,物理机器上涉及了driver,master,worker三个节点。
Spark中的Driver即运行Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与Cluster Manager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
集群中任何一个可以运行spark应用代码的节点。Worker就是物理节点,可以在上面启动Executor进程。
在每个Worker上为某应用启动的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。Executor是一个执行Task的容器。它的主要职责是:
Executor是一个应用程序运行的监控和执行容器。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
有向无环图,反映RDD之间的依赖关系。
被发送到executor上的工作单元。每个Task负责计算一个分区的数据。
在Spark中有两类task:
输出是shuffle所需数据,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
输出是计算结果,比如:
rdd.parallize(1 to 10).foreach(println)
这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个。
rdd.map(x=>(x,1)).reduceByKey(_+_).foreach(println)
上面这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
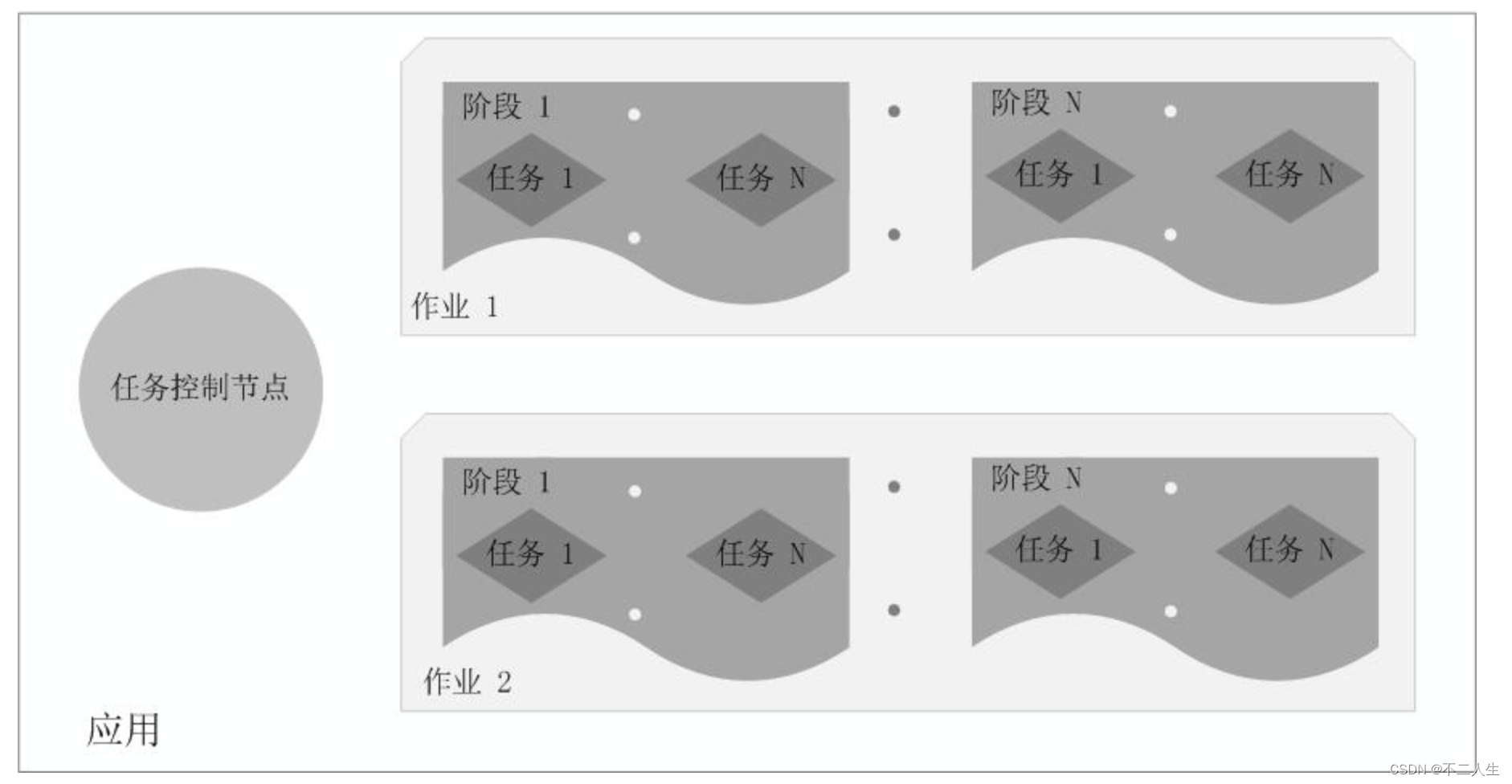
一个Job包含多个RDD及作用于相应RDD上的各种操作,它包含很多task的并行计算,可以认为是SparkRDD里面的action,每个action的触发会生成一个job。用户提交的Job会提交给DAGScheduler,Job会被分解成Stage,Stage会被细化成Task,Task简单的说就是在一个数据partition上的单个数据处理流程。
是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为一个Stage就像MapStage,ReduceStage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Partition类似hadoop的Split,计算是以partition为单位进行的,当然partition的划分依据有很多,这是可以自己定义的,像HDFS文件,划分的方式就和MapReduce一样,以文件的block来划分不同的partition。总而言之,Spark的partition在概念上与hadoop中的split是相似的,提供了一种划分数据的方式。
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件。假设block设置为128M,你的文件是250M,那么这份文件占3个block(128+128+2)。这样的设计虽然会有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容。
注意:考虑到hdfs冗余设计,默认三份拷贝,实际上3*3=9个block的物理空间。
spark中的partition是弹性分布式数据集RDD的最小单元,RDD是由分布在各个节点上的partition组成的。partition是指的spark在计算过程中,生成的数据在计算空间内最小单元,同一份数据(RDD)的partition大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定的,这也是为什么叫“弹性分布式”数据集的原因之一。
block位于存储空间、partition位于计算空间,block的大小是固定的、partition大小是不固定的,block是有冗余的、不会轻易丢失,partition(RDD)没有冗余设计、丢失之后重新计算得到。
指的是在集群上获取资源的外部服务。目前有三种类型:
在Yarn模式下,客户端程序会向Yarn申请计算我这个任务需要多少的memory,多少CPU等等。然后Cluster Manager会通过调度告诉客户端可以使用,客户端就可以把程序送到每个Worker上面去执行了。
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
Spark结构的特点可以总结成下面3个。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU