今年写了一个数据中心的项目,其中有相当一部分的数据查询,用的是ES来做的,涉及到dsl的查询语句,从最开始的简单查询,到后面的复杂的查询,逐步掌握了ES的常用写法,现在总结一下。
文章内的称呼,没有按照ES的官方称呼,例如sql那边的表叫type,sql那边的行叫documents,sql那边的列或者字段叫fields。为了方便起见,统一按照sql的叫法。
示例一:
{
"size": 0,
"query": {
"bool": {
"must": [
{
"bool": {
"must": [
{
"term": {
"depot_id": 1
}
},
{
"range": {
"order_time": {
"gte": "2022-01-01 00:00:00",
"lte": "2099-01-01 00:00:00"
}
}
}
]
}
},
{
"bool": {
"must_not": [
{
"match_phrase": {
"user_remark": {
"query": "换货单"
}
}
}
]
}
}
]
}
},
"aggregations": {
"total_user_count": {
"cardinality": {
"field": "user_id",
"precision_threshold": 50000000
}
},
"total_order_money": {
"sum": {
"field": "pay_money"
}
}
}
}
在这个查询中,使用了条件过滤,以及查询之后,对结果进行聚合。
代码解释:
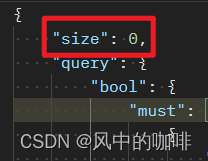
加上size:0之后,则不会返回查询到条件,对应的ES内存的原始数据。
用sql解释就是,没有size:0,则相当于“select * from 某个表”。这个和后面查询的聚合结果没有关系,就只是 是否返回原始数据,以及返回多少条原始数据。加不加size,都不会影响返回后面的聚合后的值。
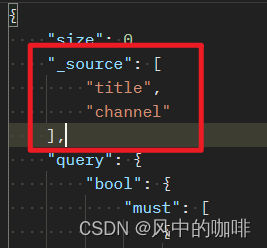
_source后面加上字段名,是用于返回原始数据的指定字段的。
例如sql中会写:
select id ,name,sex
from stu_info
limit 100
在ES里面就会写
{
"size": 100,
"_source": [
"id",
"name",
"sex"
],
"query": {
"match_all": { }
}
}
如果只是排除个别的字段,可以写exclude
例如:
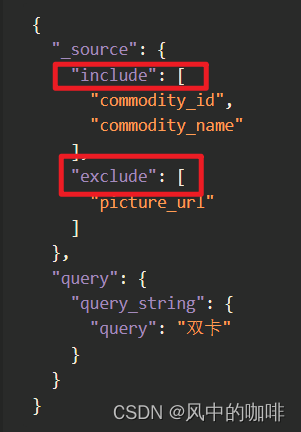
这里面的意思就是,只需要显示 commodity_id、commodity_name, 排除掉 picture_url。
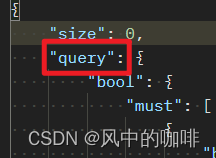
在query后面,会加上查询数据的条件,例如上面查询,我们用了
"query": {
"match_all": { }
}
它的意思就是,匹配所有的数据
而这个
"query": {
"query_string": {
"query": "双卡"
}
}
它的意思是,查询包含“双卡”的数据。
must 理解起来就是sql里面的 =,in ()
例如
select *
from stu_info
where id = 3
or name in ('张三','李四')
那么此处的这两个条件,都可以用must来写。
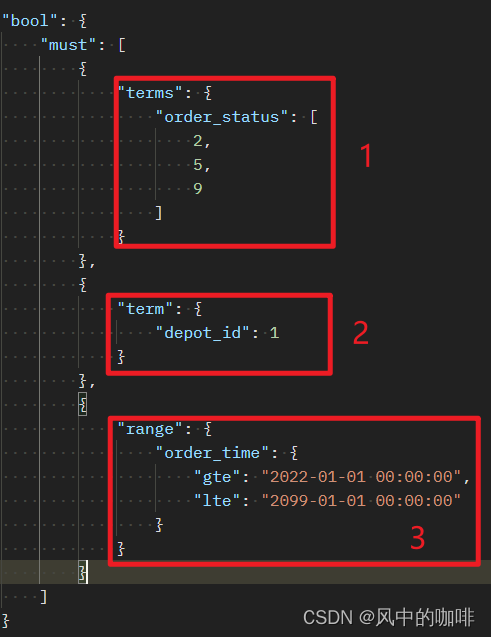
这个图中,must下面包含了三个条件,并且这三个条件的关系是and,必须同时满足,此处不做过多解释,下面是对应的sql写法
1.order_status in (2,5,9)
2.depot_id = 1
3.order_time between '2022-01-01 00:00:00' and '2099-01-01 00:00:00'
must_not 对应的就是 !=,<>, not in ()
should 对应的则是or, should中的两个条件至少满足一个就可以。
至于must,must_not,should的组合以及嵌套,可以参考:
解决es中must,must_not,should不能同时生效的问题
这个是用于查询结果聚合的,类似于groupby,注意只是类似于
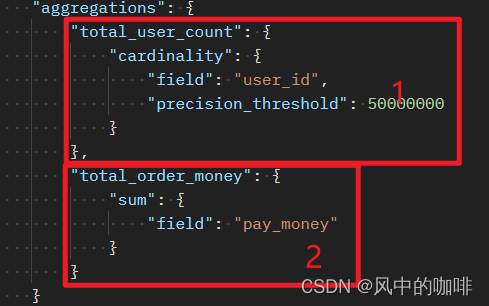
在这个代码里,实现了两个功能,
1.对user_id 进行去重数个数,相当于
count(distinct user_id)
这里的precision_threshold是修改精度,因为在数据量较大时,计数会产生稍微的误差
2.对pay_money进行求和,相当于
sum(order_money)
同样的,这这里可以进行求平均值,最大值等操作
这一部分就先写到这里,这只是我对于ES的自己的总结,难免会有不完整以及错误的地方,欢迎指正。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时