废话不多说,不扯那些所谓的"提高贡献者荣誉感"、"让贡献被所有人看到",直接上图!
这就是"排场",这就是"面子",这就是"英雄榜"!
概要
主要分为两大部分,第一部分是 DevStream 英雄榜的简单介绍,第二部分是对 DevStream 的贡献者、证书管理体系及自动化的介绍。
适合的阅读群体
谁能上榜?
所有获得过证书的 DevStream 的贡献者们。
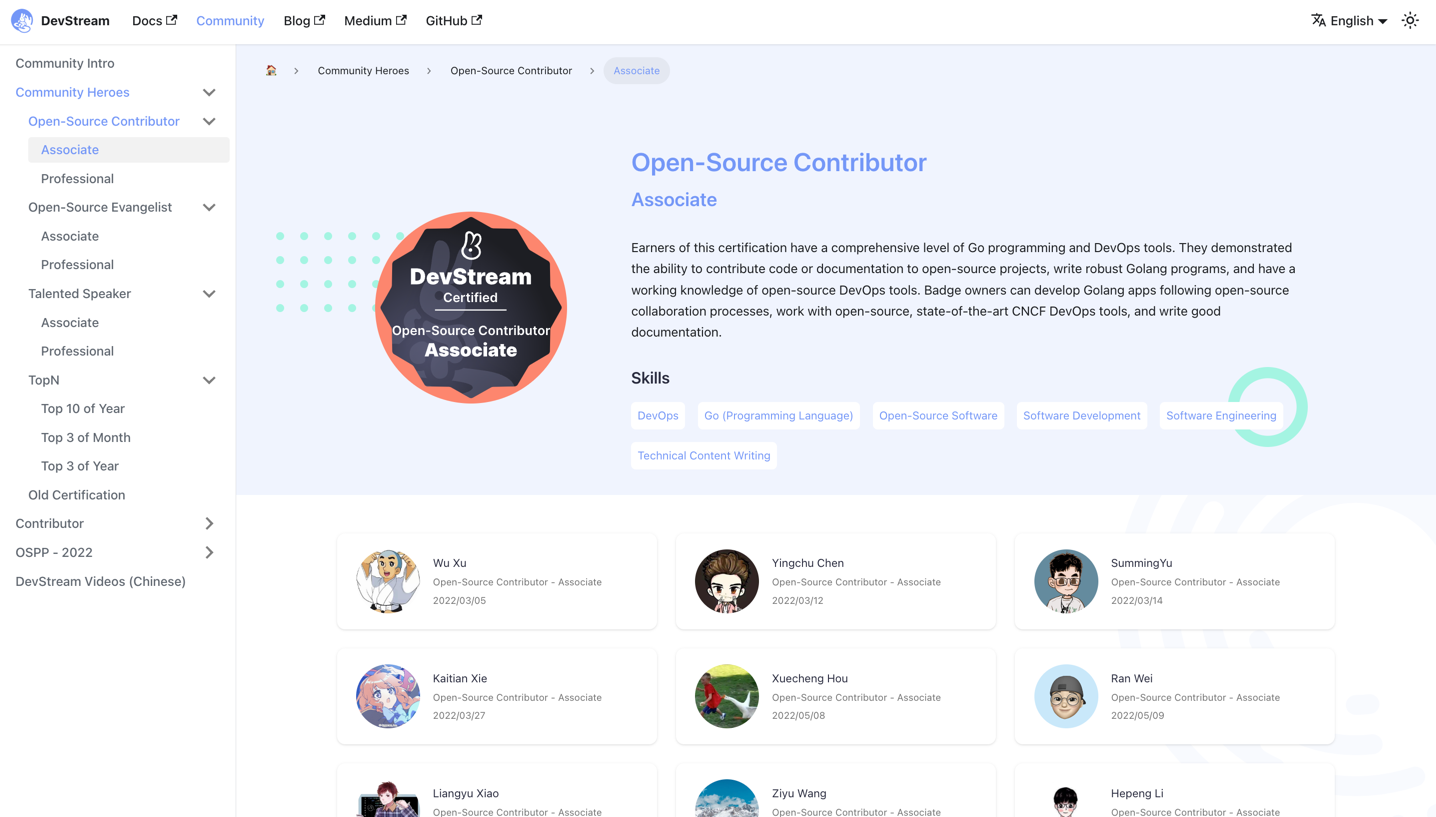
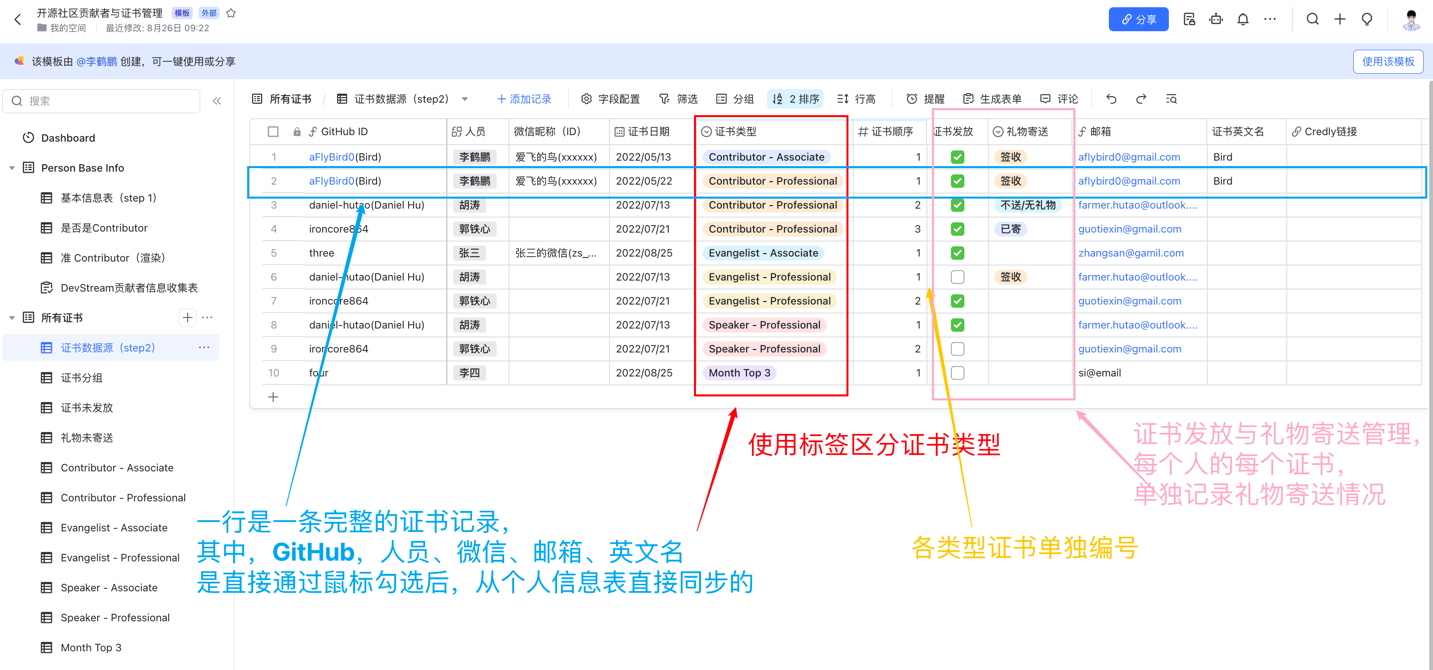
DevStream 目前共有开源贡献者、布道师、演说家、TopN几大类证书(徽章),每种证书的每个细分类型都使用一个单独的页面来展示贡献者们。
英雄榜的组成
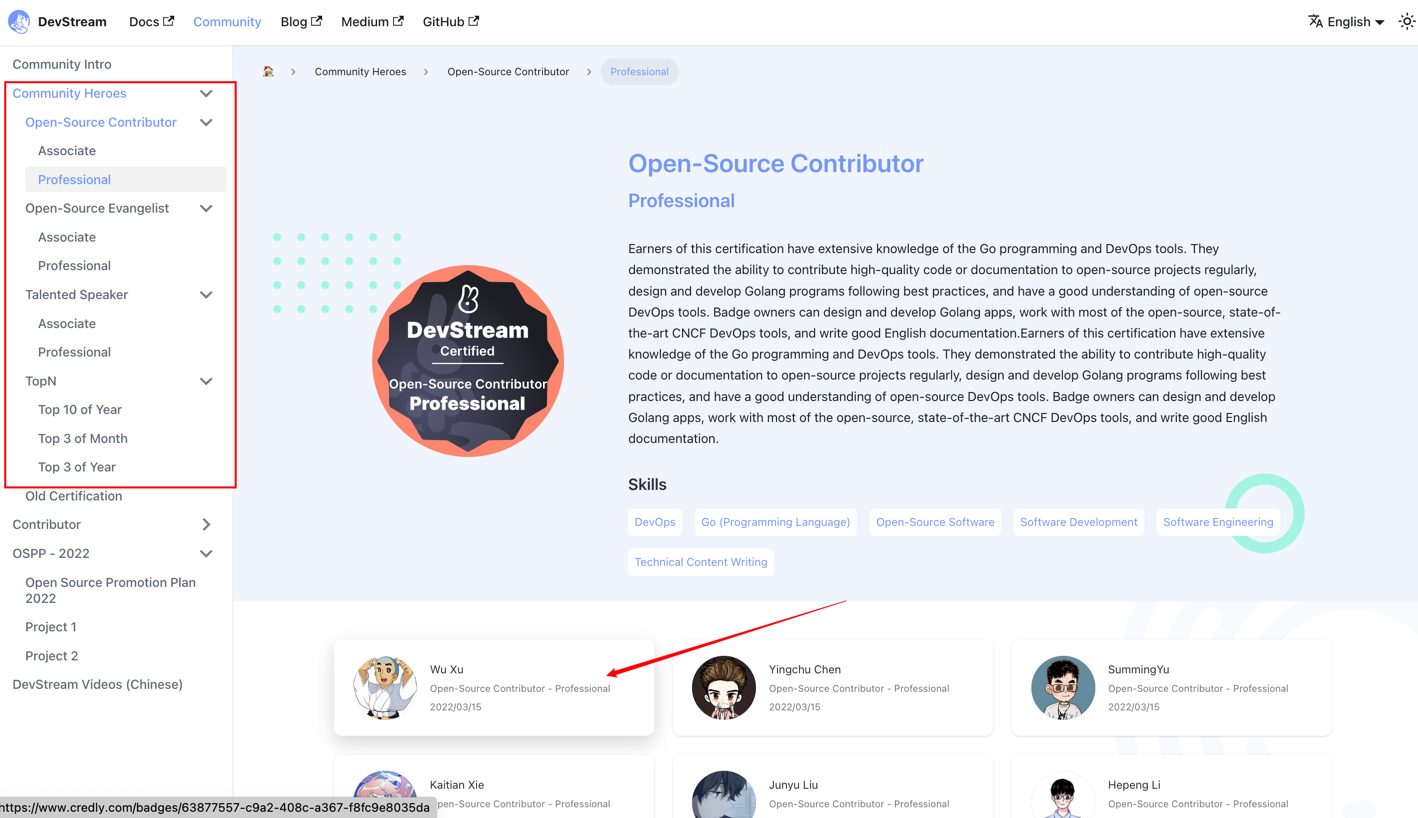
英雄榜主要由证书的图标、介绍、贡献者阵列组成。
实时展示每个"英雄"的 GitHub 头像,点击可以跳转到 Credly 证书页面以校验。
建议先看视频一睹为快,再看文章了解整个自动化体系的发展历程、设计思路、技术细节。
点击图片观看演示与讲解视频:
DevStream 的贡献者证书管理体系来源于一个很不起眼的需求。
五月份左右的时候,DevStream 处于新贡献者的爆发期,几乎天天有新贡献者加入。我们准备了很多 "good first issue", 往往一出现就被一抢而空。
随着贡献者越来越多,我们需要判断某 GitHub 用户是否已经成为了贡献者,以防止 "good first issue" 的重复申领。
这时候只需要一个简单的表格就能实现。
随着 DevStream 推出新的证书体系,我们有了十多种细分证书,而且一位贡献者可以被授予多个证书。
每个证书都有其编号、颁发日期、礼物发放细节,传统的单表格模式已无法满足新的需求。
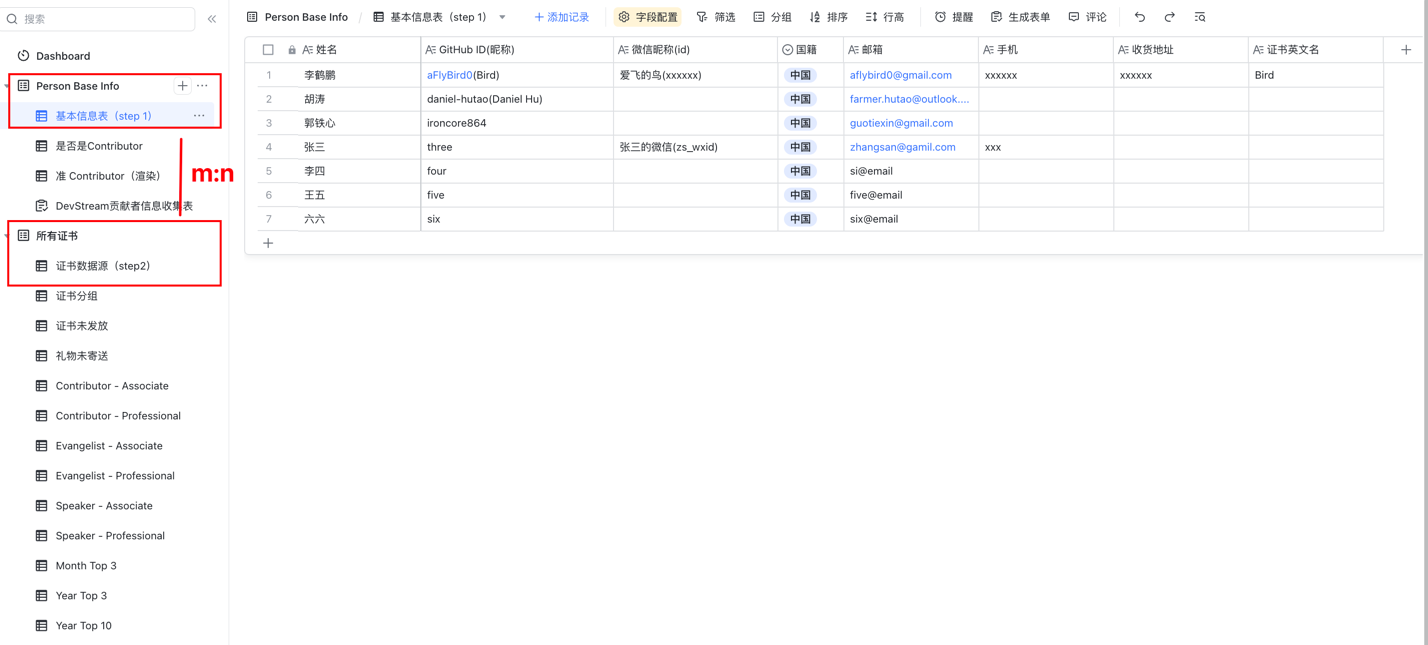
我们基于飞书多维表格来完成了复杂的需求实现,将个人信息与证书颁布信息拆分成两个表格,二者采用多对多的关联形式。
使用方式:
以下为操作演示,假设我们要给"张三"颁布"Talented-Speaker Professional"证书,可在10秒内完成:
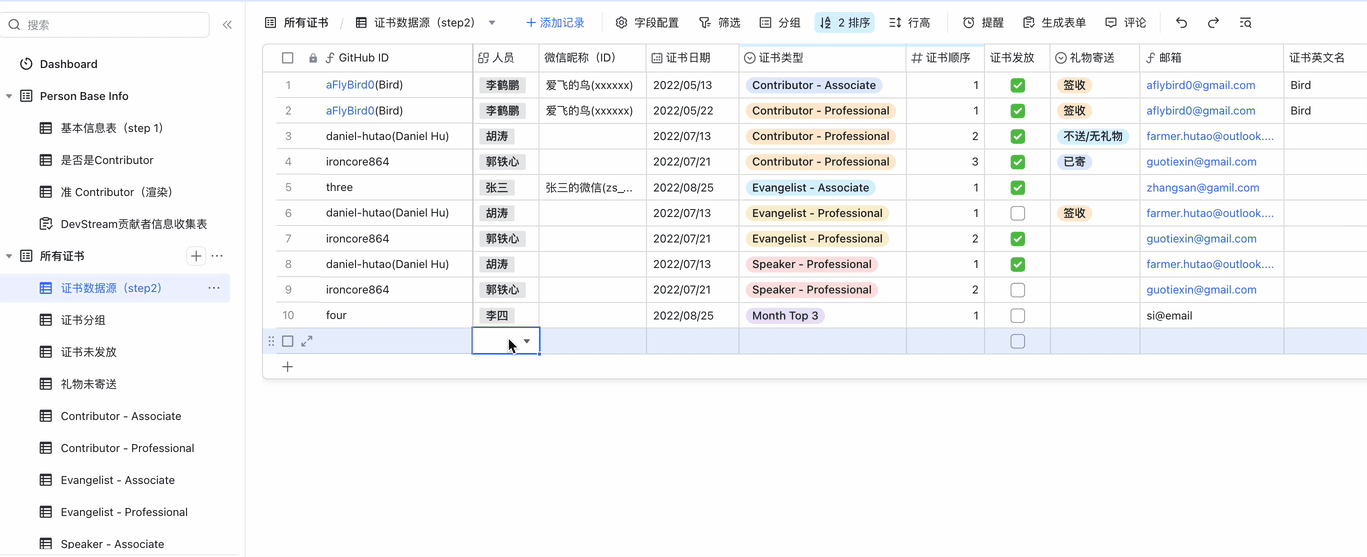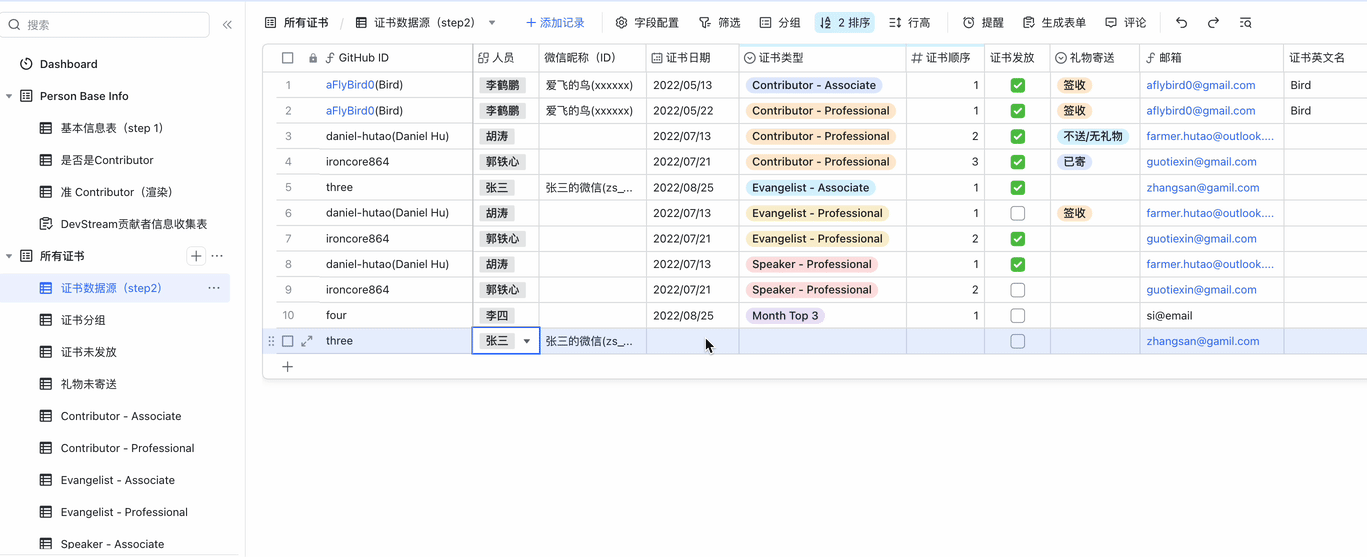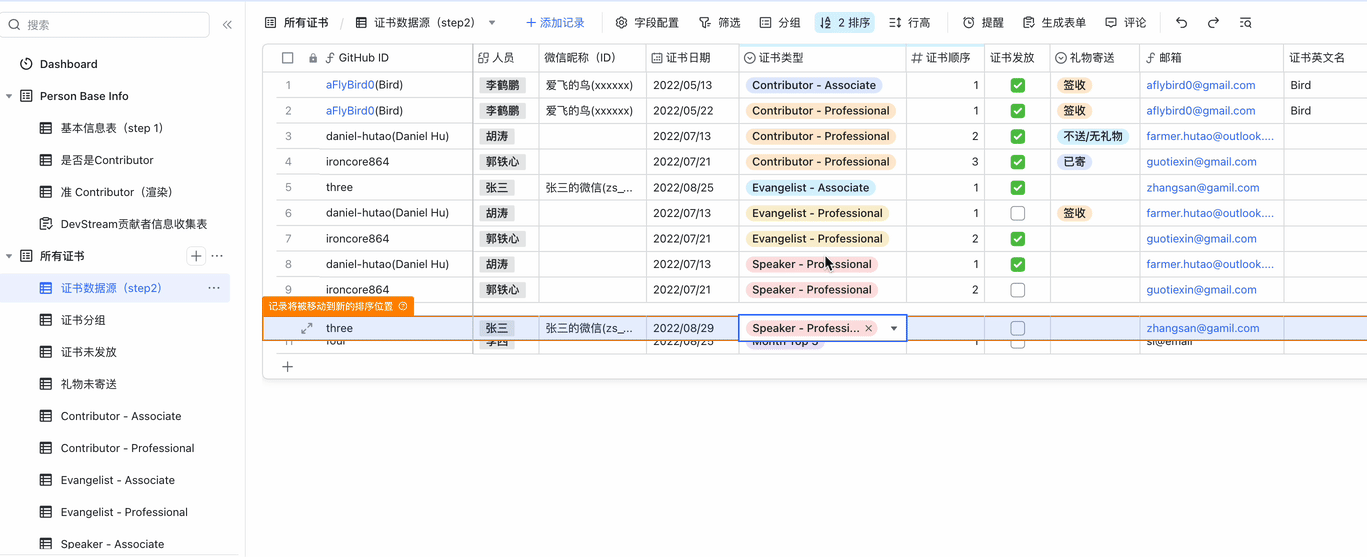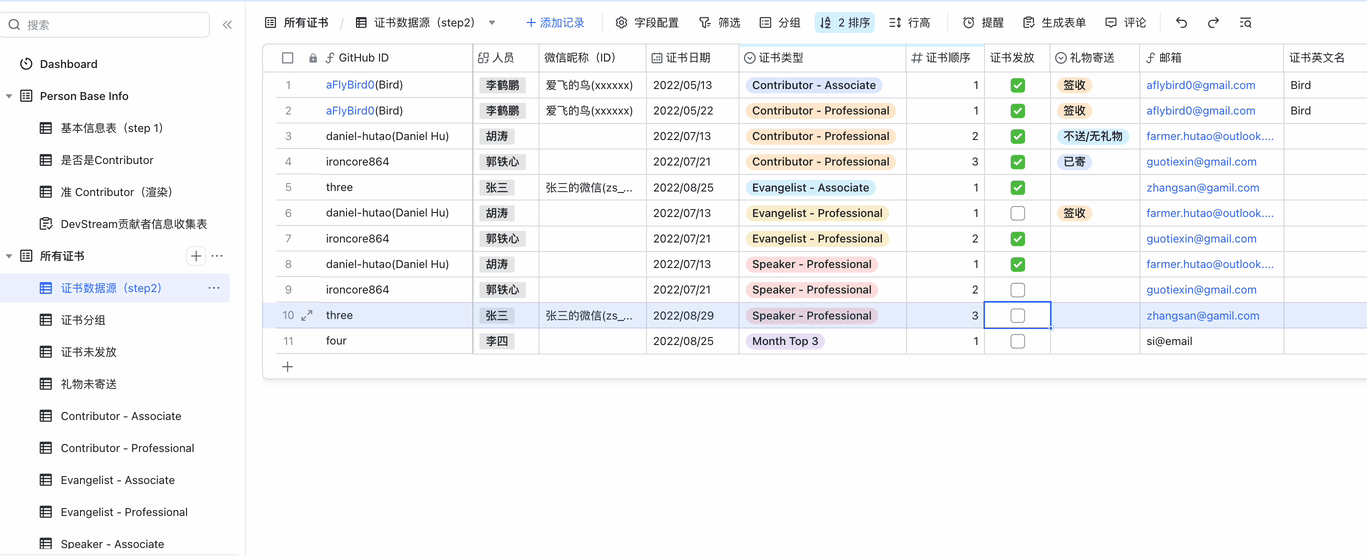
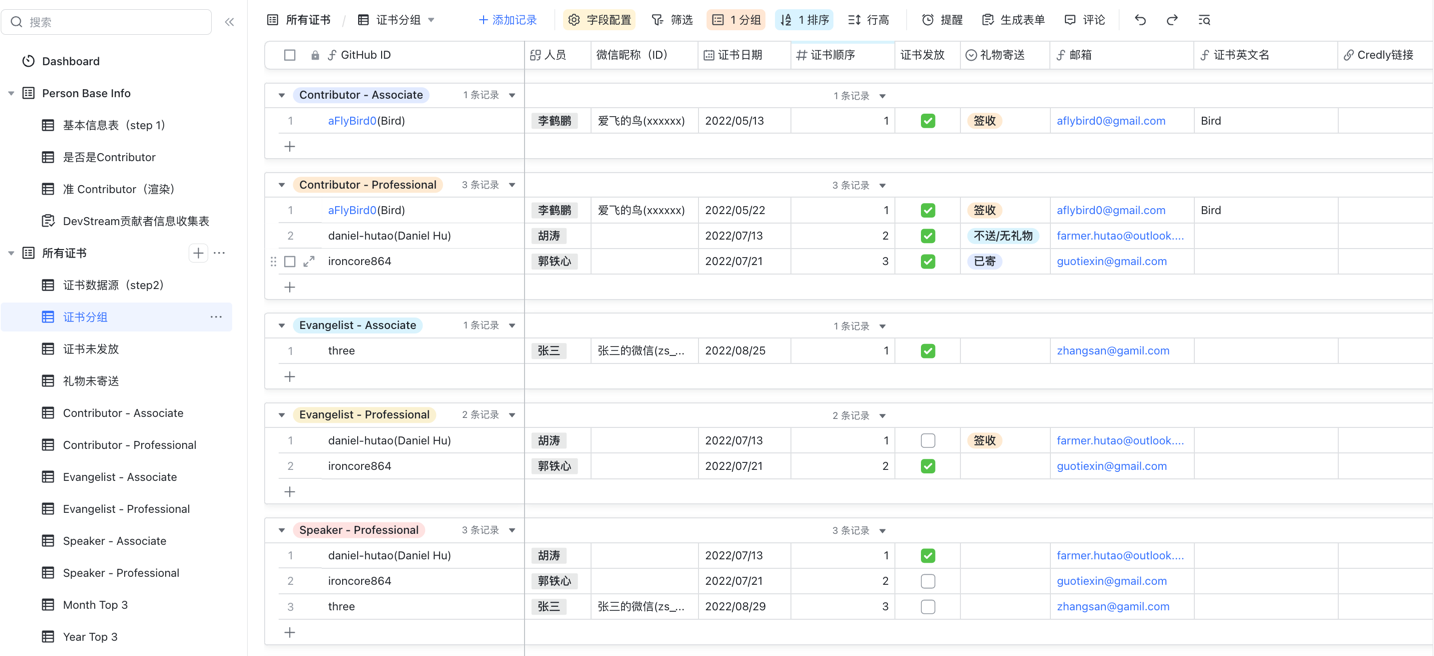
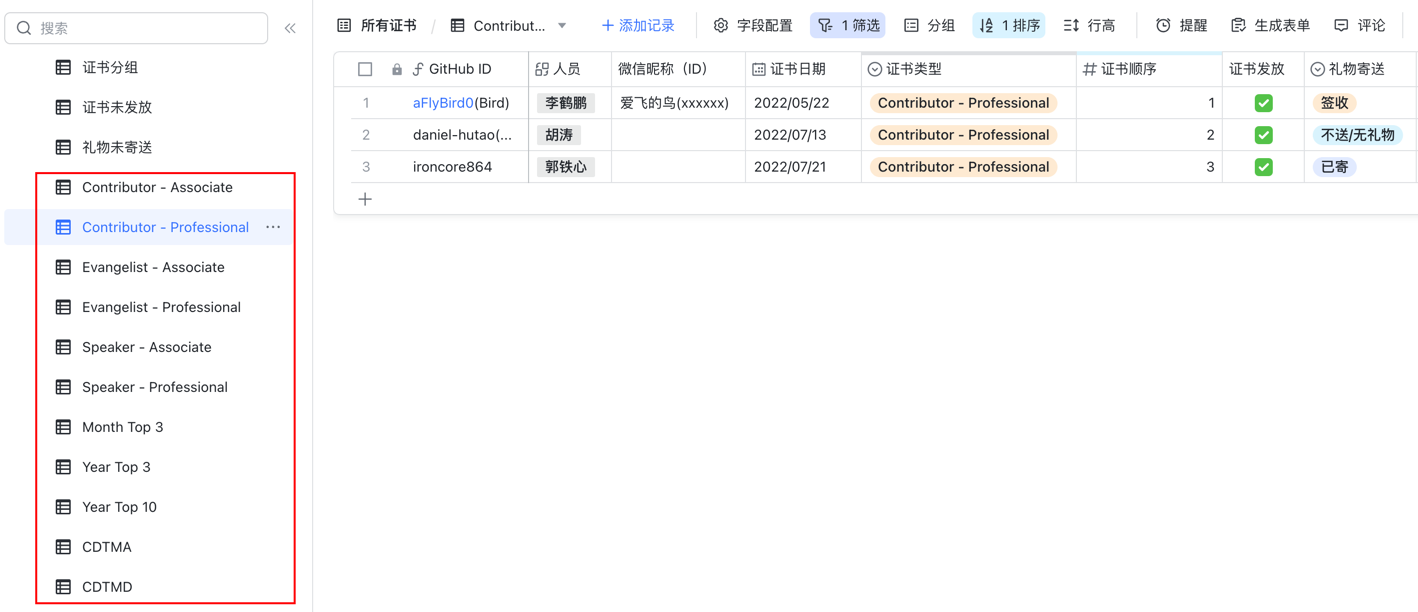
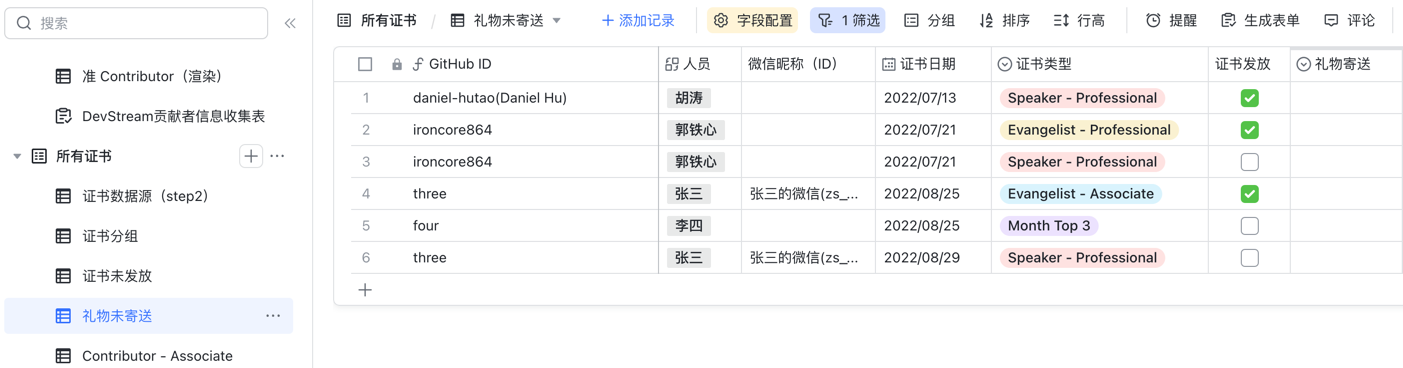
在观看演示的时候,你可能会发现,屏幕左侧有非常多的"表"。
其实那些都只是"视图",即设定不同的统计策略、筛选规则、排序方式,自动渲染,以不同的数据维度展示出来。
下面列举一些常用的视图:
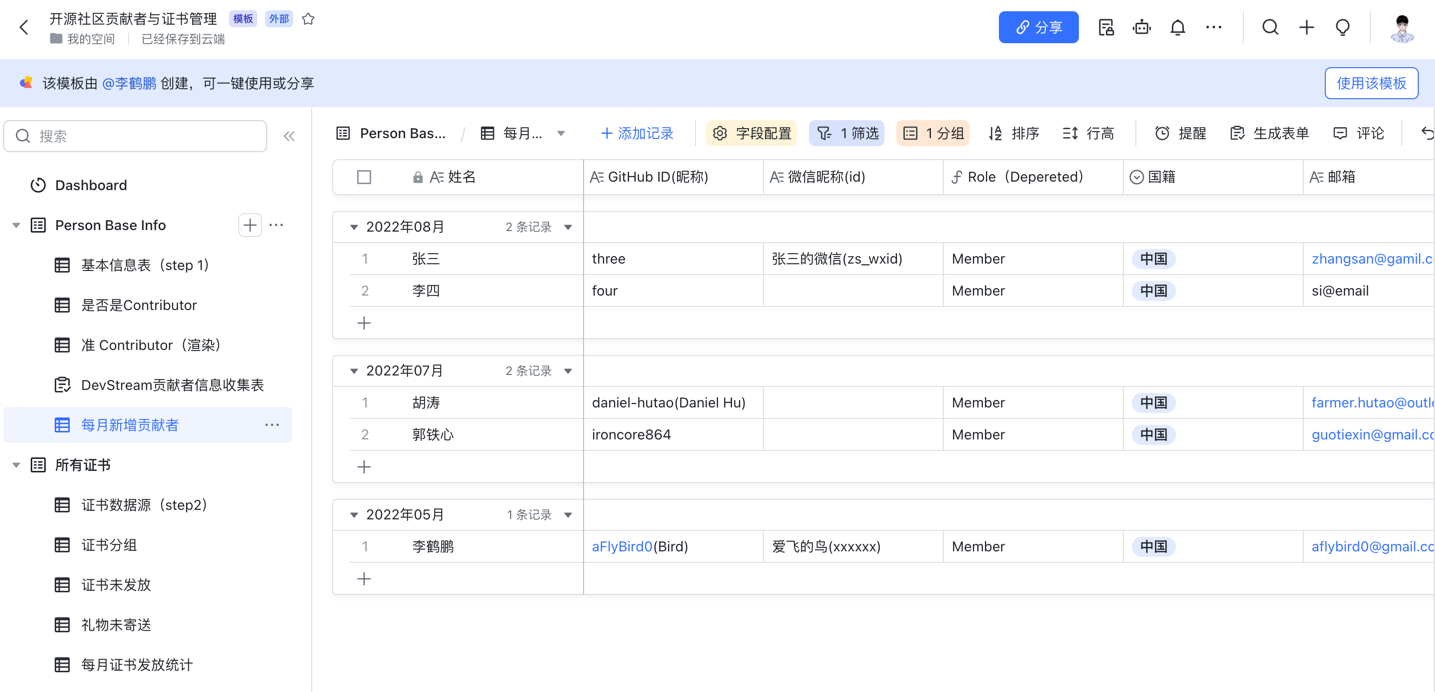

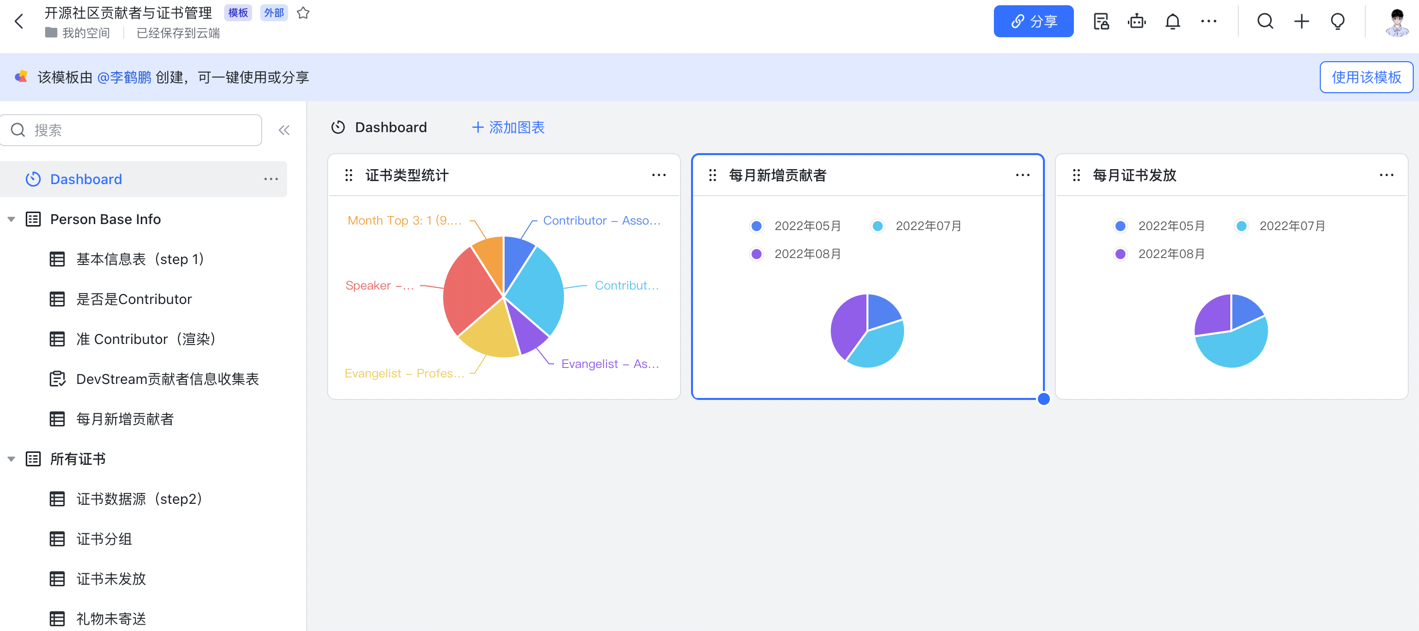
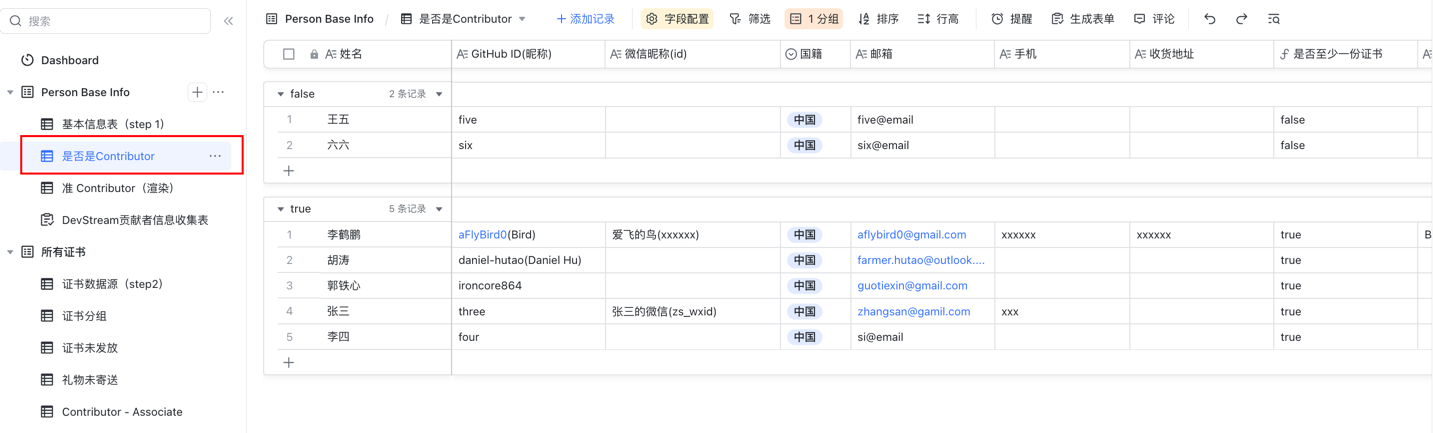
传统运营模式下,贡献者信息表格只能由内部人员编辑,需要使用社交媒体收集了贡献者的信息后,再将信息复制到表格中。沟通过程是"同步"的,成本很高。
DevStream 利用了多维表格的"表单视图",根据表格的字段自动生成表单。将表单发送给"准贡献者",填写完毕后信息自动保存到表格中。
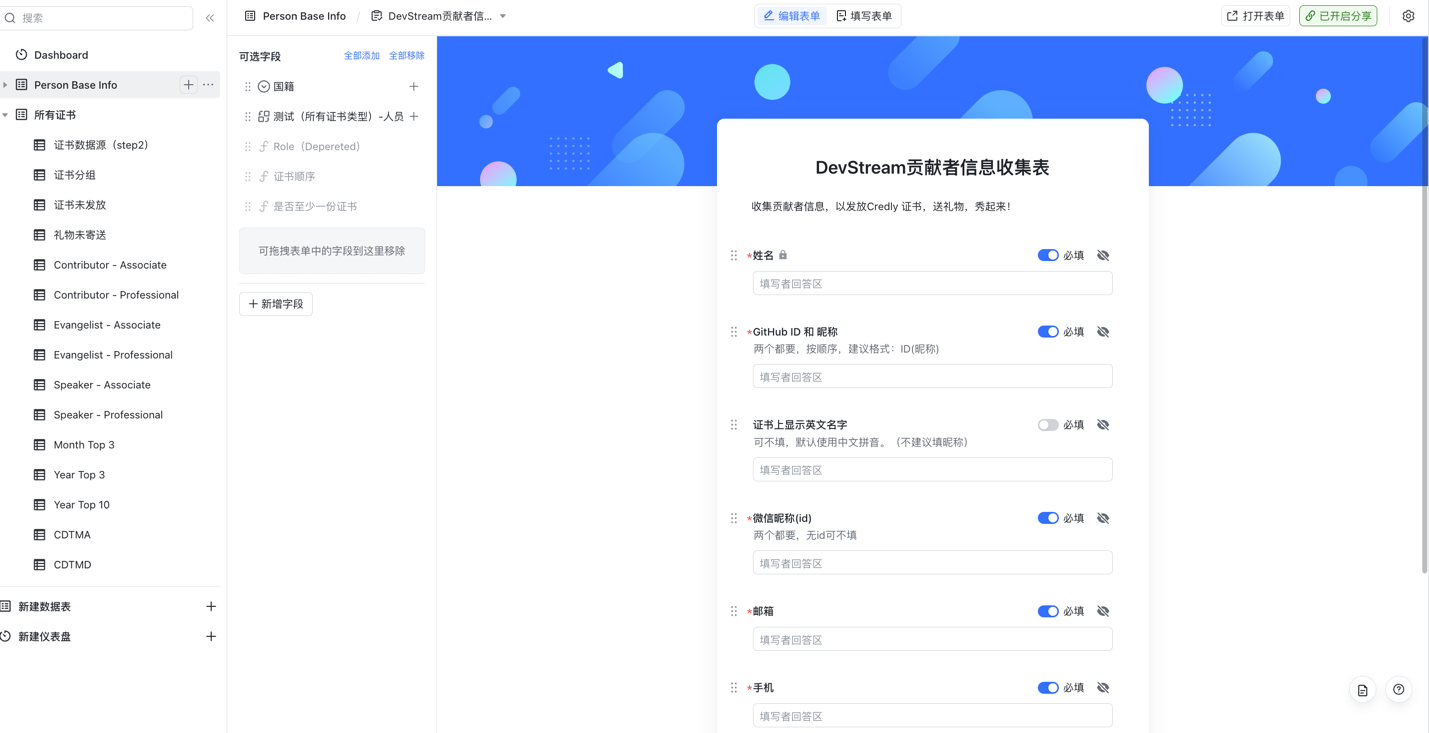
同时,我们还通过飞书的"自动化"功能,配置了消息提醒。每当有贡献者提交了表单,飞书会自动提醒运营人员,不需要再反复询问或确认是否完成了表单的填写,采用异步沟通的形式提高了效率。
接下来就是颁发 Credly 证书,这部分参照 Credly 官网教程即可。
以上的多维表格,已经整理成了模板,可以一键使用:开源社区贡献者与证书管理-模板。
原先我们只有内部的贡献者信息和证书信息管理表格,后面又有了 Credly 证书,现在又有了那么酷炫的英雄榜,以及需要能从英雄榜跳转到特定的 Credly 证书验证页。
加上之前的证书发布状态管理、礼物寄送状态管理,需要一个自动化且可信的数据处理、同步机制。
DevStream 借用了 Single Source of Truth 的理念,将证书表格作为唯一的、标准的信息来源。各种信息的管理和记录都在表格上进行,Credly 颁发完成后证书链接也先填回表格,再导出到官网英雄榜。
多维表格是"表格“形式,可以导出成 csv 格式; 而DevStream官网仓库渲染英雄榜贡献者使用的格式是 json。
还有很多细节,如:
DevStream 做了个数据格式转换仓库, 读入 csv 数据,转换成英雄榜需要的 json 数据,并处理中文转拼音等细节。
于是,我们的操作流程就变成了这样:
csv 格式下载至本地,并将其移动到数据转化代码的相应目录中;json 格式;json 文件覆盖官网仓库的对应文件;能不能再简化一些呢?尤其是每次手动提要点开 GitHub 网页提交 pr 好麻烦!
当然可以!—— 我认为绝大多数重复的、可被精确定义或描述的操作,都可以使用代码自动化。
我们可以使用 GitHub Actions 来完成部分自动化,每次提交最新的含有贡献者和证书信息的 csv 文件,由 Actions 完成"程序运行(数据处理)、复制 json 至官网仓库、提 pr 到官网仓库"的操作。
然后流程就变成了:
csv ,移动到相应目录;git add && git commit && git push (之后由 GitHub Actions 自动执行程序,复制 json、提 pr 到官网仓库);还能再简单点吗?我只想点点鼠标!
当然!可以!
第二步已经把执行的命令都写出来了,为什么不直接放到 shell 脚本里?
第一步呢?"下载表格成 csv"本就是个鼠标操作,"移动到代码目录" 不就是个 mv 吗?
(具体的 GitHub Actions 工作流定义和 shell 脚本,前面的数据格式转换仓库中均已给出)。
最终流程
当贡献者或证书信息更新后:
泡杯茶,等半分钟,通知 website 仓库管理员 review pr 并 merge。
自动化环节,很多地方可以做得更好,以及很多地方是多次权衡过的结果,简单分享一下:
Q1. 为什么最后还要人工 review?
其实理论上能做到直接合并不需要 review,但最后人工校验一下更安全。
Q2. 为什么最后要依靠脚本来在本地操作 Git,而不是建个 web 服务器?
虽然这样看起来很美好,而且所有人都能很简单地操作且没有任何环境依赖。
同时飞书的多维表格的自动化是支持在表格变动了之后发送 http 请求的,理论上完全可以做到在表格变动之后,通知后端服务,主动拉取表格数据、渲染、pr 。
但这样有以下几个问题:
其实建不建 web 服务器,很大程度取决于如何从飞书端获取导出的数据。DevStream 采用了"推"的方式主动将数据发送给程序,而不是使用"拉"的方式由程序来请求飞书,虽然后者理论上更安全可靠等,但是实际操作起来会更麻烦。
目前这套流程最终也只需要点两次鼠标就能完成,操作上已经几乎达到最简。
Q3. 文件的安全性如何保证?
目前贡献者敏感信息主要是手机号、微信、收货地址等。
我采取的方式是建个新视图 ——"下载专用(脱敏)",屏蔽所有敏感信息,只展示渲染英雄榜需要的关键信息。之后下载 csv 都从这个视图里下。
(这就是写博客输出的好处了,建立新视图来屏蔽敏感信息的方式是输出的过程中想到的)。
也可以采取以下方式,更保险:
csv 文件上传到可信的或自建的文件存储服务器,然后在 GitHub Actions 里面下载,同时将网络文件存储服务的密码存至仓库的 Secret 中。csv 到 json 的转换,GitHub Action 只完成 pr 操作。写着写着,想到了博客以外的一些内容,想分享一下。
为什么会有这篇博客,或者说,为什么会有这个自动化系统?
前段时间 DevStream 的全职运营离职,所以我们进行了一个非常大胆的创新:每个开发都分担一部分运营的任务。
原以为这会成为开发的一个负担,但运作到现在,事情变得有意思了起来:
搞技术的人天生受不了重复性的操作,如果让搞技术的来做运营,那么我们会想方设法地去简化整个流程,提高整体的效率。
所以,对于一个无技术背景的运营来说,管理这样一个复杂的贡献者信息——礼物发放——证书发放——英雄榜更新体系是一件非常耗时的工作:
需要一个个地去沟通、收集、复制、编辑、再复制...... 每有一个新的贡献者起码耗时20分钟,是非常折磨人的。
但这个运营工作落到了技术人员身上,流程就变成了:
愈发觉得 DevStream 这个模式是成功且高效、有一定推广意义的,无论是技术人员辅助做些运营工作并提高整个团队的工作效率,还是运营人员自身去学些技术或者利用工具提高效率。
如果开源社区的运营者们不用每天身陷于重复性的无聊的工作,而是能有更多的时间去做些创造性的工作、有趣的工作,那一定非常酷!
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
herokudb:pullpostgresql://root:@localhost/db_name执行此命令后显示此消息/usr/lib/ruby/gems/1.8/gems/rest-client-1.6.1/lib/restclient/abstract_response.rb:50:警告:future版本的括号参数加载水龙头v0.3.13警告:数据库“postgresql://root:@localhost/db_name”中的数据将被覆盖并且无法恢复。您确定要继续吗?(是/否)?是连接数据库失败:Sequel::AdapterNotFound->LoadError:没有要加载的
今天,我将尽可能地设置我的测试环境和工作流程。我正在向对Ruby测试充满热情和精通的你们寻求有关如何设置测试环境的实用建议。到一天结束时(太平洋标准时间早上6点?)我希望能够:键入一个1-command来为我在Github上找到的任何项目运行测试套件。为任何Github项目运行autotest,这样我就可以fork并做出可测试的贡献。使用Autotest和Shoulda从头开始构建gem。Foronereasonoranother,IhardlyeverruntestsforprojectsIclonefromGithub.Themajorreasonisbecauseunless
我收到以下错误消息:herokudb:pull--debugpostgres://USERNAME:PASSWORD@localhost/testLoadedTapsv0.3.23Warning:Datainthedatabase'postgres://USERNAME:PASSWORD@localhost/test'willbeoverwrittenandwillnotberecoverable.ReceivingschemaUnabletofetchtablesinformationfromhttp://heroku:foo9dsfsdfsdb465ar@taps19.heroku
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭7年前。Improvethisquestion我是一名RubyonRails开发人员,手头有一些时间。我想利用这段时间通过为开源项目做贡献来回馈和学习。我不是一流的程序员,想从小做起。在哪里可以找到Ruby或Rails中的小型开源项目?我该如何贡献?亚历克斯
在Java领域,主要使用JUnit,而在.NET中,我相信nUnit非常流行。社区是否就Ruby世界的单元测试框架达成一致?背景:我问是因为我是Ruby的新手,想在学习Ruby的同时练习TDD。到目前为止,我只玩过Test::Unit。 最佳答案 你可以坚持使用Test::Unit或者你可以使用Shoulda对其进行很好的扩展或使用Context的一些很酷的上下文.另一方面,如果您更喜欢BDD,那么您可以安全地坚持使用RSpec.至于验收测试用Cucumber. 关于ruby-什么是社区
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭8年前。ImprovethisquestionDavidKorn,Unix哲学的支持者,几年前在aSlashdotinterview中斥责Perl程序员用于编写单一的Perl脚本而不通过管道、重定向等使用Unix工具包。“Unix不仅仅是一个操作系统,”他说,“它是一种做事的方式,shell通过提供使它起作用的胶水。”似乎提醒同样适用于Ruby社区。Ruby具有通过popen、STDIN、STDOUT、STDERR、ARGF等与其他U
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭12年前。这是一个诚实的问题,我不是在挑衅。作为Rails的新手,我一直在寻找好的Rails资源。但是我注意到许多曾经很受欢迎的网站现在已经完全被废弃了。一些例子:http://www.softiesonrails.com/-最后更新于2010年2月http://www.therailsway.com/-最后更新于2009年8月http://nubyonrails
踏浪而行,逐浪而上,MEME全新版本2.0乘势而来,荣耀上线,2022年7月27日,全网最难爆仓平台MEME携全新2.0版正式上线!MEME2.0版本探索更多功能,全面升级重新定义合约,体验感更好,交易更流畅,相比于原来的1.0,MEME2.0版本上线后,全面支持独立钱包与邮箱登陆,全网最难爆仓平台!从追赶者到领航者数字资产和区块链的成长过程,如同观察一个生态系统,一个新兴事物从无到有的蓬勃发展,这带给我们的冲击是前所未有的。尽管生态系统已经拥有相当悠久的历史,但数字化技术的出现改变了一切。不同于传统的生态圈,数字生态系统实现了1+1>2的协同效应。MEME全网首家Web3交互交易平台,去中心
如今eBPF程序的编写,很多都是基于bcc或者bpftrace进行,也有开发者直接基于libbpf库进行,但是不管怎样,编写的xx.bpf.c程序,在加载到内核时,都必须经过内核的verifier校验器进行各种边界和内存检查,经常会碰到各种奇奇怪怪的verifier报错,导致eBPF程序加载失败。有些错误,开发者可能要花费大量的时间去分析并修改程序,并祈祷程序能够加载成功。特别是在低版本的内核运行低版本Clang编译器编译的eBPF程序,错误提示非常糟糕,经常找不到出错点,这就大大增加了开发难度。为此,本文梳理了一些常见的eBPFverifier报错,避免更多的人走弯路,写出能成功加载的eBP