JavaWeb系列教程
JavaWeb—Servlet
模拟Servlet本质
使用IDEA开发Servlet程序
Servlet对象的生命周期
适配器(GenericServlet)改造Servlet
ServletConfig
Servlet–ServletContext
web站点欢迎页
一篇学会HttpServletRequest
如果大家觉得有帮助的话,不妨动动小手,点赞收藏一波,也方便后面的复习哈
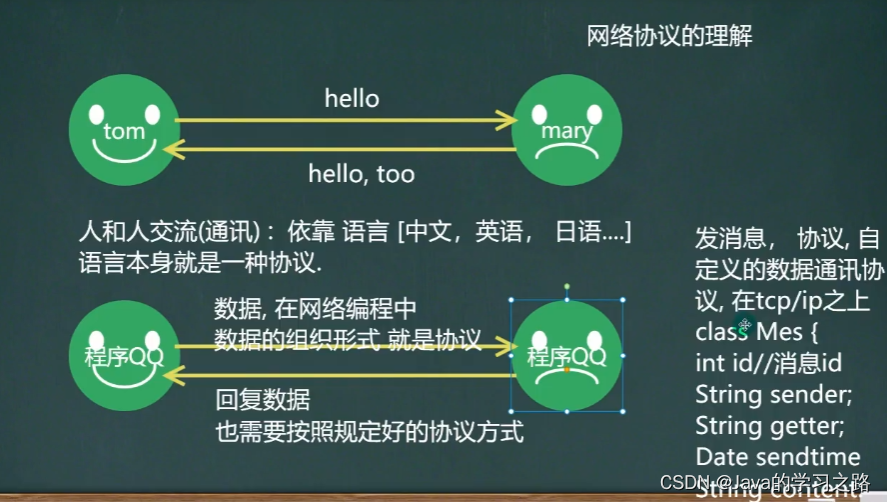
协议实际上是某些人,或者某些组织提前制定好的一套规范,大家都按照这个规范来,这样可以做到沟通无障碍。
协议就是一套规范,就是一套标准。由其他人或其他组织来负责制定的。
我说的话你能听懂,你说的话,我也能听懂,这说明我们之间是有一套规范的,一套协议的,这套协议就是:中国普通话协议。我们都遵守这套协议,我们之间就可以沟通无障碍。
HTTP协议:是W3C制定的一种超文本传输协议。(通信协议:发送消息的模板提前被制定好。)
W3C:
什么是超文本?
这种协议游走在B和S之间。B向S发数据要遵循HTTP协议。S向B发数据同样需要遵循HTTP协议。这样B和S才能解耦合。
什么是解耦合?
B/S表示:B/S结构的系统(浏览器访问WEB服务器的系统)
浏览器 向 WEB服务器发送数据,叫做:请求(request)
WEB服务器 向 浏览器发送数据,叫做:响应(response)
HTTP协议包括:
HTTP协议就是提前制定好的一种消息模板。
HTTP的请求协议(B --> S)
HTTP的请求协议包括:4部分
- 请求行
- 请求头
- 空白行
- 请求体

HTTP请求协议的具体报文:GET请求
GET /servlet05/getServlet?username=lucy&userpwd=1111 HTTP/1.1 请求行
Host: localhost:8080 请求头
Connection: keep-alive
sec-ch-ua: “Google Chrome”;v=“95”, “Chromium”;v=“95”, “;Not A Brand”;v=“99”
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: “Windows”
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54
Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: http://localhost:8080/servlet05/index.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
空白行
请求体
HTTP请求协议的具体报文:POST请求
POST /servlet05/postServlet HTTP/1.1 请求行
Host: localhost:8080 请求头
Connection: keep-alive
Content-Length: 25
Cache-Control: max-age=0
sec-ch-ua: “Google Chrome”;v=“95”, “Chromium”;v=“95”, “;Not A Brand”;v=“99”
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: “Windows”
Upgrade-Insecure-Requests: 1
Origin: http://localhost:8080
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: http://localhost:8080/servlet05/index.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
空白行
username=lisi&userpwd=123 请求体
请求行
请求头
空白行
请求体
HTTP的响应协议(S --> B)
HTTP的响应协议包括:4部分
HTTP响应协议的具体报文:
HTTP/1.1 200 ok 状态行
Content-Type: text/html;charset=UTF-8 响应头
Content-Length: 160
Date: Mon, 08 Nov 2021 13:19:32 GMT
Keep-Alive: timeout=20
Connection: keep-alive
空白行
<!doctype html> 响应体
<html>
<head>
<title>from get servlet</title>
</head>
<body>
<h1>from get servlet</h1>
</body>
</html>
状态行
响应头:
空白行:
响应体:
怎么查看的协议内容?
怎么向服务器发送GET请求,怎么向服务器发送POST请求?
1.简单快速:客户向服务器请求服务的时候,只需要传送请求方法和路径,请求方法一般是get和post,因为HTTP协议简单,所以HTTP服务器的程序规模小,通信速度快。
2.灵活:HTTP协议运行传输任意类型的数据对象,传输的类型由Content-Type标记
3.无连接:客户端向服务端发送一次请求,服务端接收后,连接就断开了,无连接表示每一次连接都只处理一个请求,这种方式可以节省传输时间.
举个例子:你打电话给朋友说让他帮忙买一瓶水,然后就把电话挂掉了,这个时候,想到说还要麻烦朋友做什么事情,就再打电话过去。
HTTP1.1版本以后,支持可连续连接,通过这种连接就有可能在建立一个TCP连接后,发送请求并得到回应,然后接着发送请求并得到回应。通过建立和释放TCP连接的开销分摊到多个请求,对每一个请求来说,因为TCO造成的相对开销被大大降低了,而且还可以发送流水线请求,就是说在发送请求1之后,在回应到来之前就可以发送请求2.
4.无状态。HTTP协议是无状态协议,无状态指的是对事务处理没有记忆能力,如果后面想要处理之前的信息的话,就必须重传,这样会导致每一次连接传送的数据量增大
get请求发送数据的时候,数据会挂在URI的后面,并且在URI后面添加一个“?”,"?"后面是数据。这样会导致发送的数据回显在浏览器的地址栏上。(get请求在“请求行”上发送数据)
post请求发送数据的时候,在请求体当中发送。不会回显到浏览器的地址栏上。也就是说post发送的数据,在浏览器地址栏上看不到。(post在“请求体”当中发送数据)
get请求只能发送普通的字符串。并且发送的字符串长度有限制,不同的浏览器限制不同。这个没有明确的规范。
get请求无法发送大数据量。
post请求可以发送任何类型的数据,包括普通字符串,流媒体等信息:视频、声音、图片。
post请求可以发送大数据量,理论上没有长度限制。
get请求在W3C中是这样说的:get请求比较适合从服务器端获取数据。
post请求在W3C中是这样说的:post请求比较适合向服务器端传送数据。
可能好多人,一看到说get请求会把内容显示在地址栏上,就是不安全的

get请求是安全的。get请求是绝对安全的。为什么?因为get请求只是为了从服务器上获取数据。不会对服务器造成威胁。(get本身是安全的,你不要用错了。用错了之后又冤枉人家get不安全,你这样不好(太坏了),那是你自己的问题,不是get请求的问题。)
post请求是危险的。为什么?因为post请求是向服务器提交数据,如果这些数据通过后门的方式进入到服务器当中,服务器是很危险的。另外post是为了提交数据,所以一般情况下拦截请求的时候,大部分会选择拦截(监听)post请求。
注意:我这里说的安全是相对而言,事实上它们都不安全,比如get请求,会把数据显示在url上,但是我们要正确使用就不会出现这种问题。post请求则比较危险。
get请求支持缓存。
post请求不支持缓存。(POST是用来修改服务器端的资源的。)
GET请求和POST请求如何选择,什么时候使用GET请求,什么时候使用POST请求?
怎么选择GET请求和POST请求呢?衡量标准是什么呢?你这个请求是想获取服务器端的数据,还是想向服务器发送数据。如果你是想从服务器上获取资源,建议使用GET请求,如果你这个请求是为了向服务器提交数据,建议使用POST请求。
大部分的form表单提交,都是post方式,因为form表单中要填写大量的数据,这些数据是收集用户的信息,一般是需要传给服务器,服务器将这些数据保存/修改等。
如果表单中有敏感信息,还是建议适用post请求,因为get请求会回显敏感信息到浏览器地址栏上。(例如:密码信息)
做文件上传,一定是post请求。要传的数据不是普通文本。
其他情况都可以使用get请求。
不管你是get请求还是post请求,发送的请求数据格式是完全相同的,只不过位置不同,格式都是统一的:
啰嗦一句,不要主观臆断。大家可能都会有这样的主观错误,认为get请求会把信息显示在地址栏,所以就是不安全,post就是安全的。我觉得这是一种常见的误区。其实这种安全只是相对的

这个表格是从w3cschool截取的

更加详细的介绍,具体的可以看这篇文章 get和post的区别
希望得到大家的支持
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我知道您通常应该在Rails中使用新建/创建和编辑/更新之间的链接,但我有一个情况需要其他东西。无论如何我可以实现同样的连接吗?我有一个模型表单,我希望它发布数据(类似于新View如何发布到创建操作)。这是我的表格prohibitedthisjobfrombeingsaved: 最佳答案 使用:url选项。=form_for@job,:url=>company_path,:html=>{:method=>:post/:put} 关于ruby-on-rails-rails:Howtomak
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_

