一.、创建虚拟机
1. 创建虚拟机
2. 安装 CentOS
二、虚拟机网络设置
三、 安装JDK
四、 安装 Hadoop
1. 下载并解压
2. 修改配置
五、组成集群(本章)
1、虚拟机克隆与主机配置
2、配置每台主机
(1)主机配置:更改IP地址
(2) 修改主机名(重启后永久生效)
(3)设置ip和域名映射,四台主机都需要修改
3. 免密登录
4、Hadoop集群的配置
(1)修改文件#############workers
(2) 创建数据和临时文件夹
5.、格式化 HDFS
六、 启动集群(本章)
1、关闭防火墙
2、 宿主机上做节点映射
3、Hadoop环境变量配置 (对所有节点)
七、 关闭集群(本章)
在上几篇文章中我们已经完成了jdk 以及Hadoop的安装和配置,下面我们就开始Hadoop集群的配置。
虚拟机克隆与主机配置
(1)这里推荐采用完整克隆方式,克隆时需要虚拟机处于关机状态。
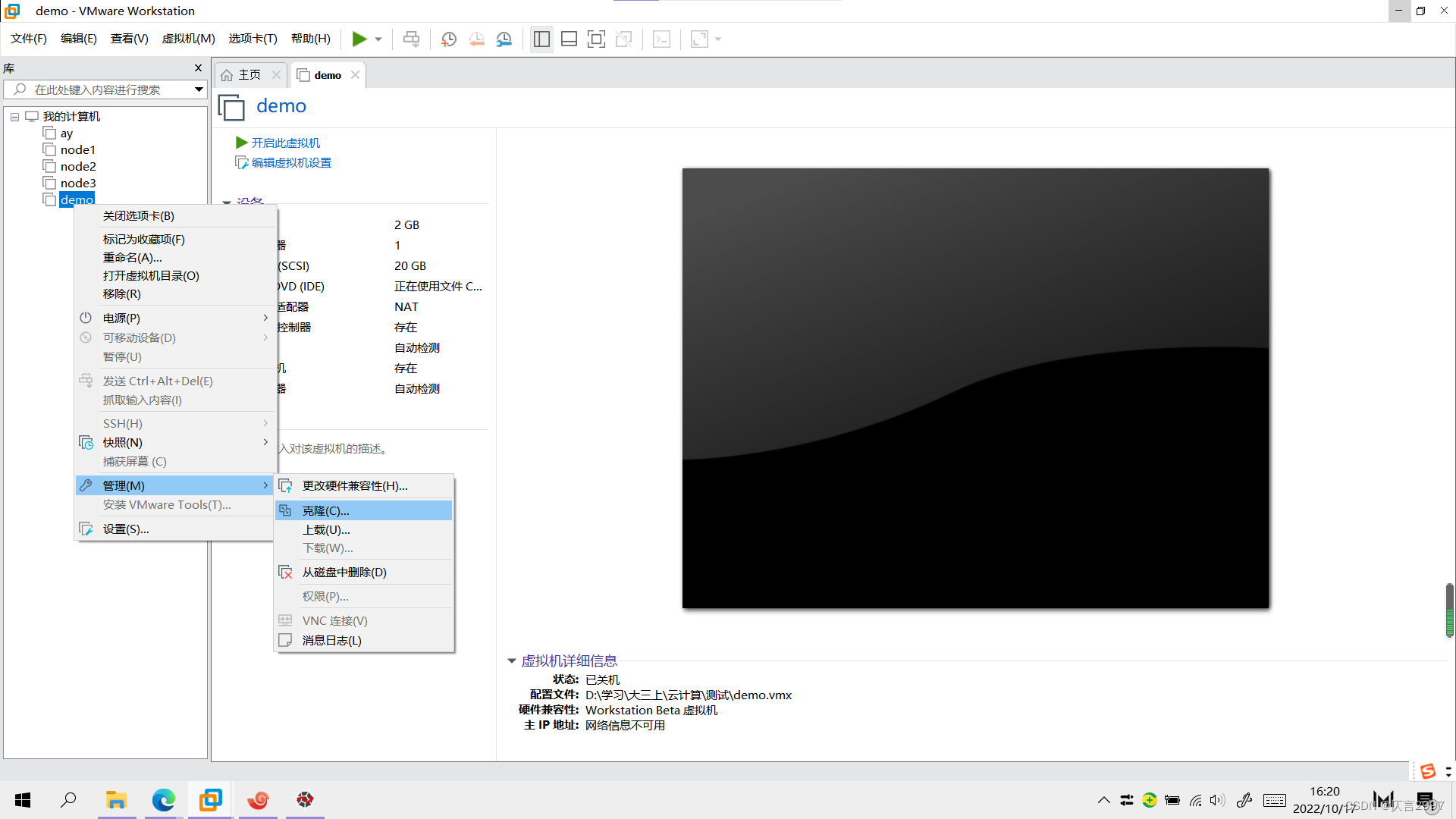
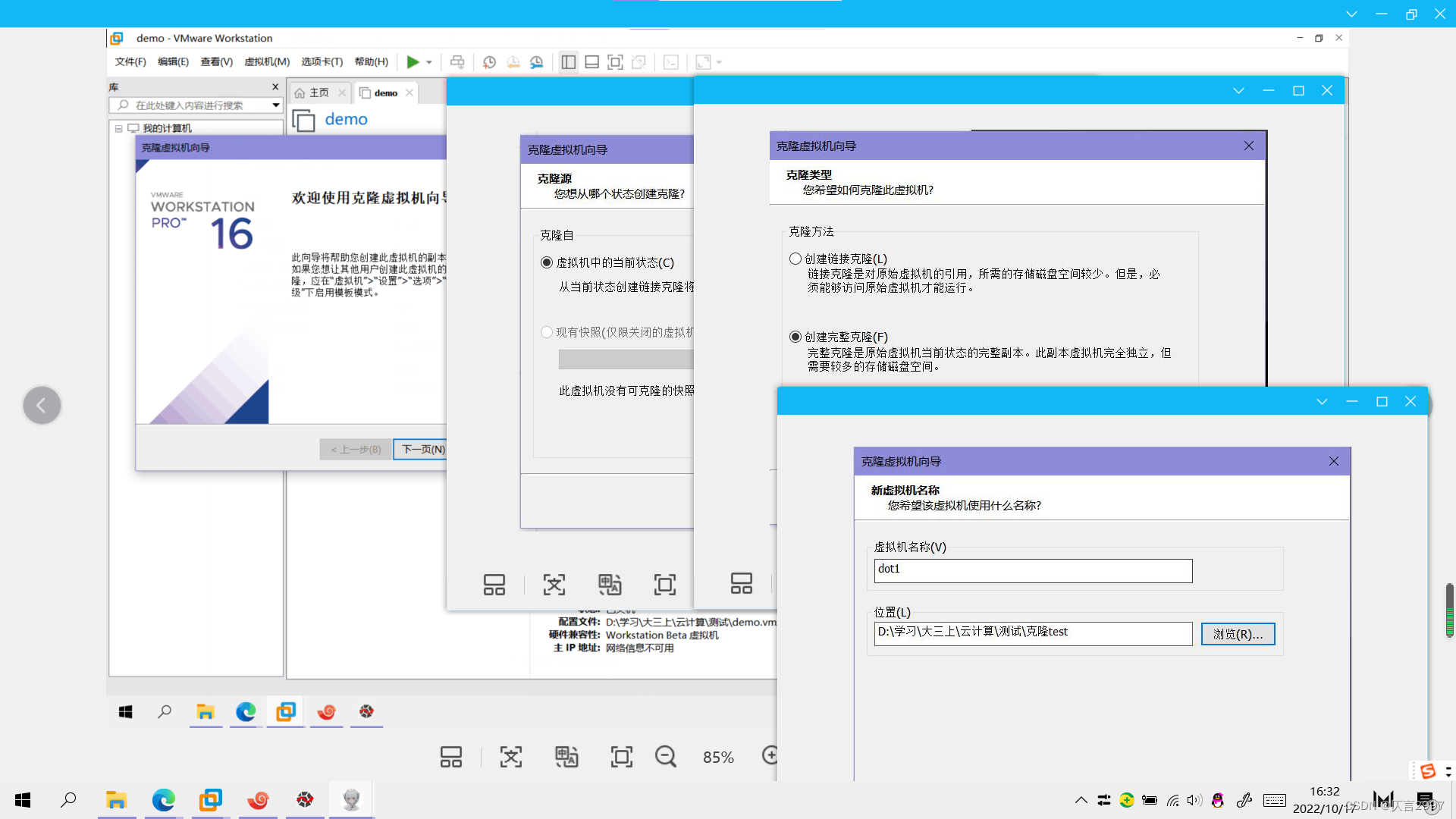
2. 配置每台主机
(1)主机配置:更改IP地址
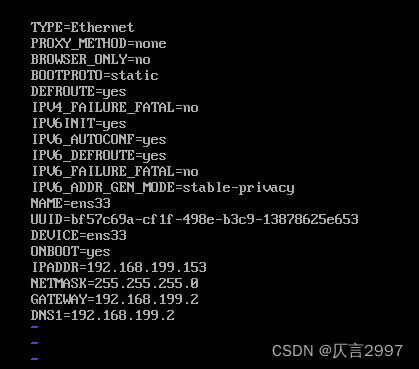
设置固定IP命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
dot1: 192.168.230.151
dot2: 192.168.230.152
dot3: 192.168.230.153
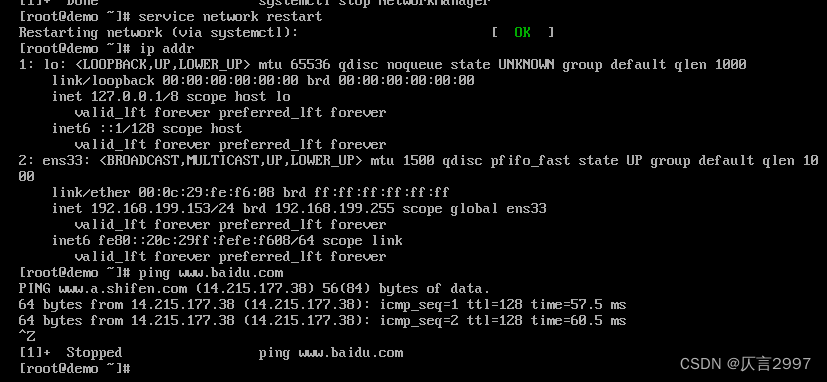
使用ip addr查看ip地址,ping www.baidu.com,ping通表示成功。
(2) 修改主机名(重启后永久生效)
命令:vi /etc/sysconfig/network
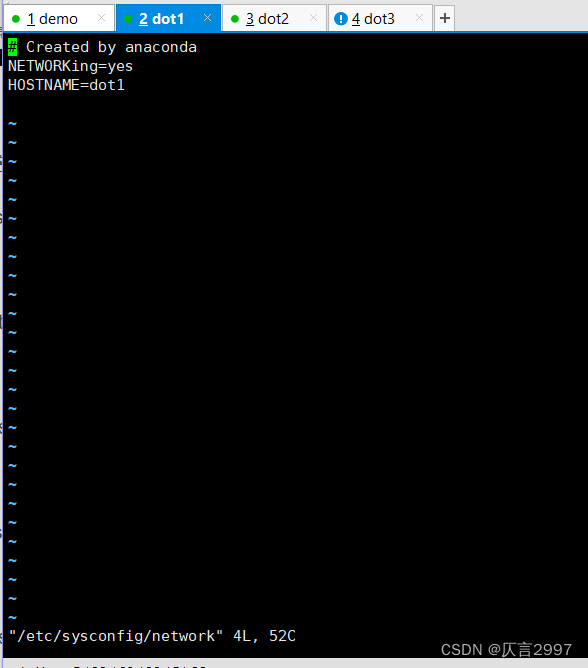
或者 命令:vi /etc/hostname
对于其他节点:
dot1 - vi /etc/hostname
dot1
dot2 - vi /etc/hostname
dot2
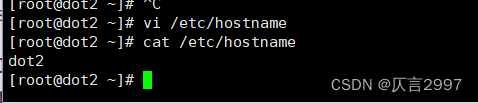
dot3 - vi /etc/hostname
dot3
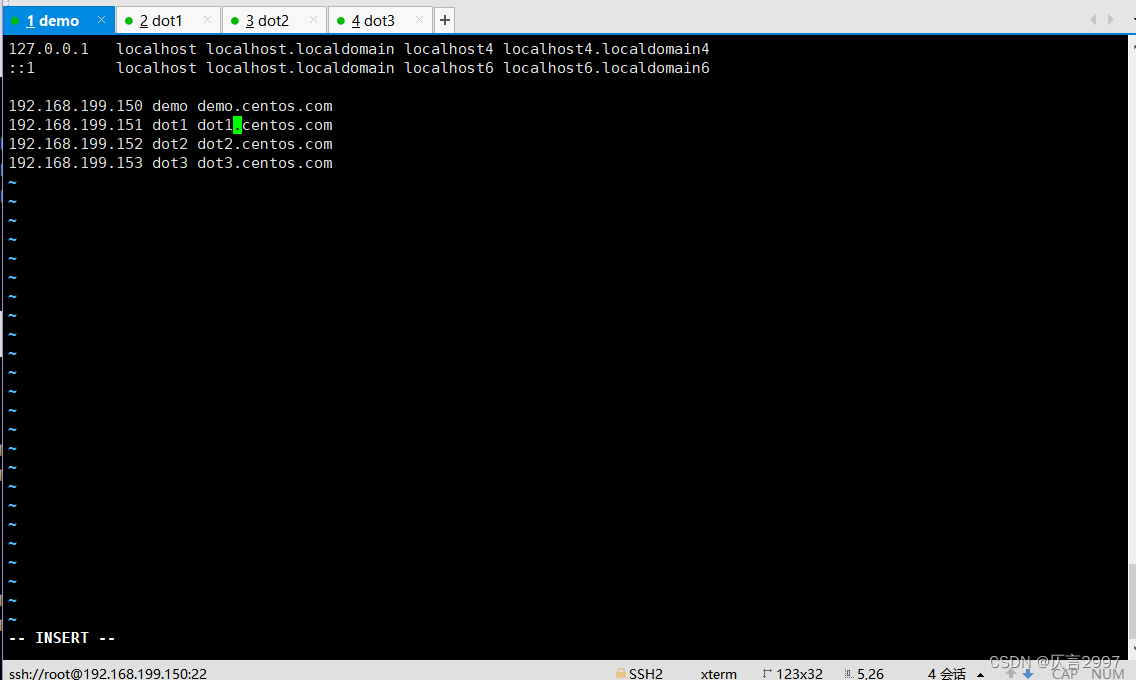
(3)设置ip和域名映射,四台主机都需要修改
命令:vi /etc/hosts
192.168.199.150 demo demo.centos.com
192.168.199.151 dot1 dot1.centos.com
192.168.199.152 dot2 dot2.centos.com
192.168.199.153 dot3 dot3.centos.com
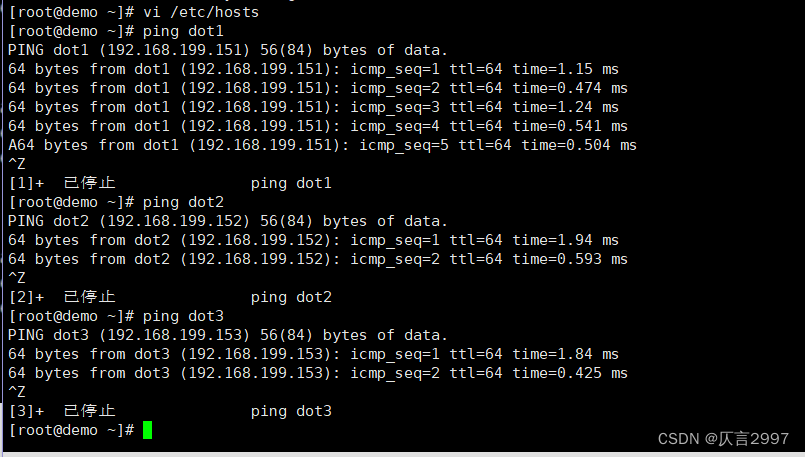
3. 免密登录
免密登录设置步骤
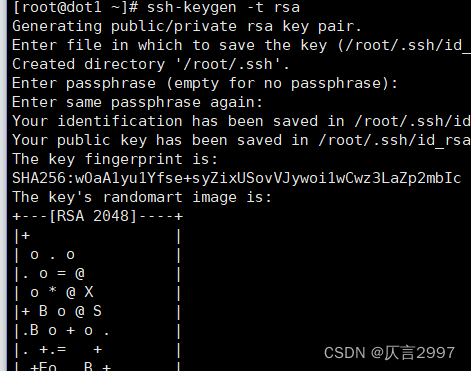
**第一步:四台机器生成公钥与私钥**
在四台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可
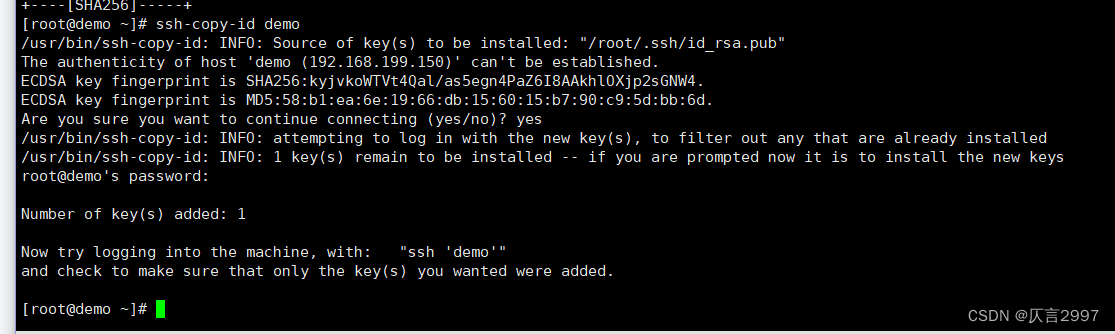
**第二步:拷贝公钥到同一台机器**
四台机器将拷贝公钥到demo机器
四台机器执行命令:
ssh-copy-id demo
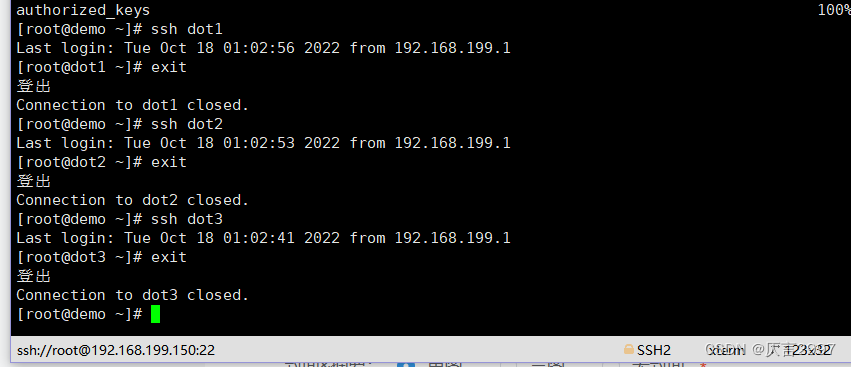
**第三步:复制第一台机器的认证到其他机器**
将demo机器的公钥拷贝到其他机器上
在demo机器上面指向以下命令
scp /root/.ssh/authorized_keys dot1:/root/.ssh
scp /root/.ssh/authorized_keys dot2:/root/.ssh
scp /root/.ssh/authorized_keys dot3:/root/.ssh

各机器之间实现免密登录
ssh master
ssh node1
ssh node2
ssh node3
exit
4. 格式化 HDFS
2、Hadoop集群的配置
(1)修改文件#############workers
dot1
dot2
dot3
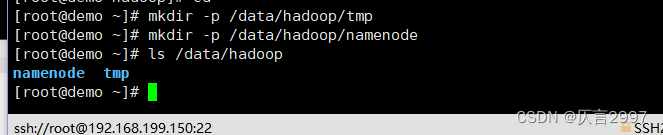
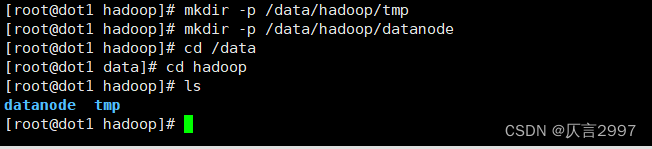
 (2) 创建数据和临时文件夹
(2) 创建数据和临时文件夹
(3) 创建数据和临时文件夹
demo 主节点:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
Other dots:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/datanode
或者在dot节点shell :
ssh dot1“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
ssh dot2“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
ssh dot3“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
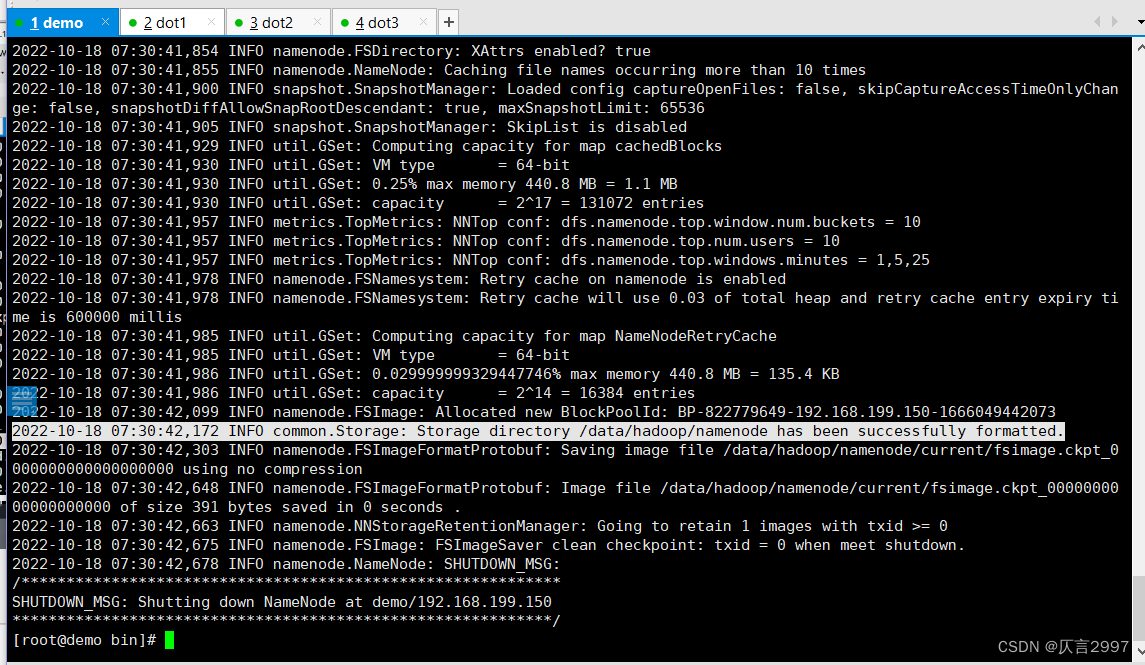
格式化 HDFS
在demo上面:
cd /opt/hadoop-3.1.4
cd bin
./hdfs namenode -format demo
5. 启动集群
启动集群
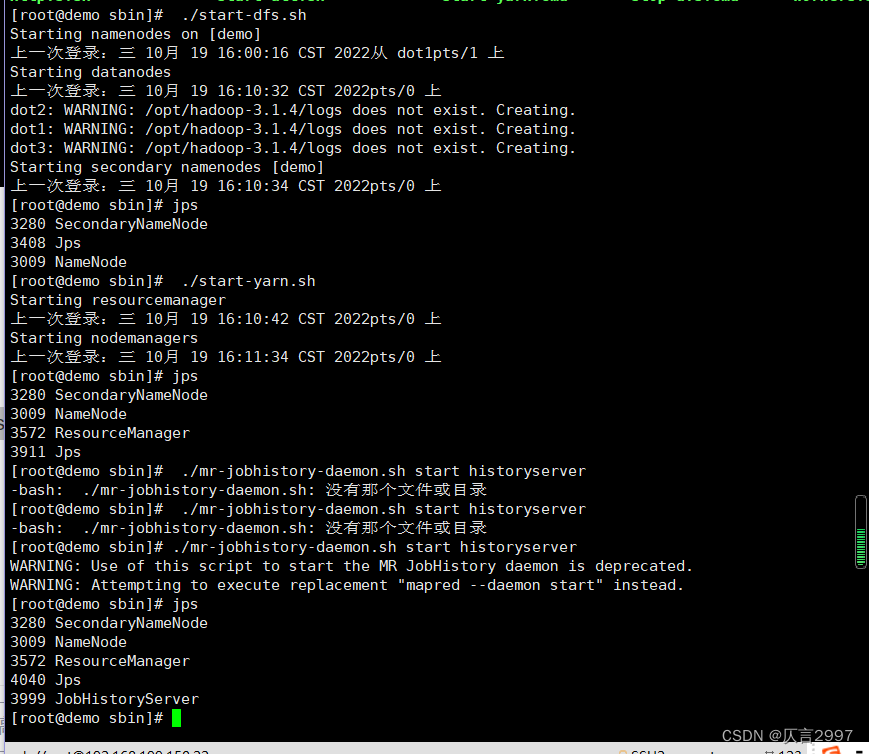
在demo上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver 或者 mapred --daemon start historyserver
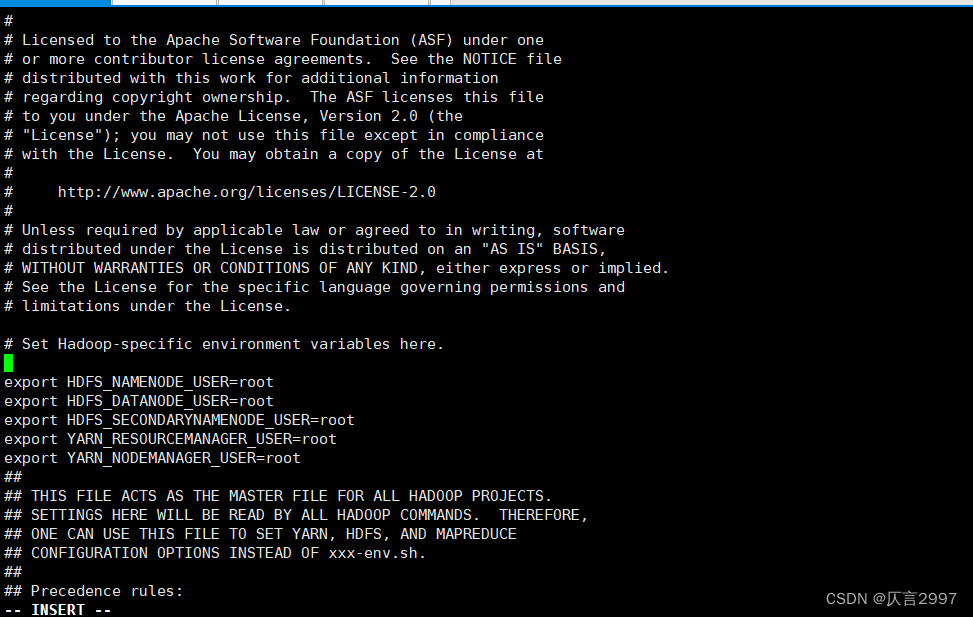
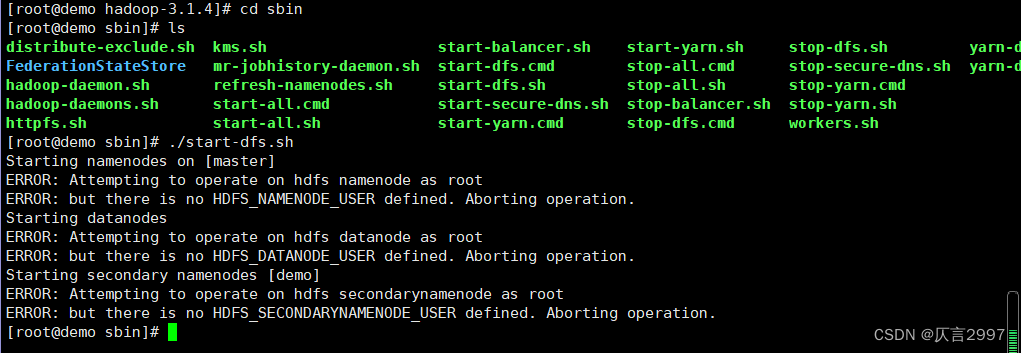 !!!报错:设置hadoop-env.sh
!!!报错:设置hadoop-env.sh
/opt/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
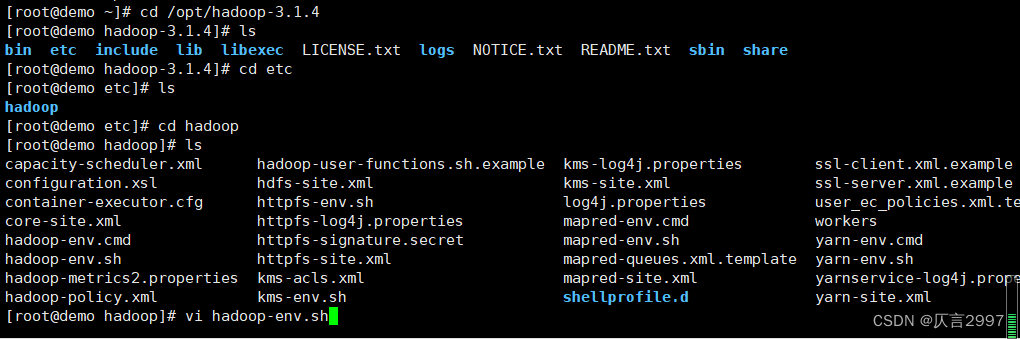 在demo上设置,添加授权:
在demo上设置,添加授权:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
 拷贝文件到其他节点:
拷贝文件到其他节点:
scp hadoop-env.sh dot1:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh dot2:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh dot3:/opt/hadoop-3.1.4/etc/hadoop/
[root@demo hadoop]# scp hadoop-env.sh dot1:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.8MB/s 00:00
[root@demo hadoop]# scp hadoop-env.sh dot2:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.4MB/s 00:00
[root@demo hadoop]# scp hadoop-env.sh dot3:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.7MB/s 00:00
[root@demo hadoop]#
 -> 再重复2步骤,通过jps查看进程
-> 再重复2步骤,通过jps查看进程
在demo上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver 或者 mapred --daemon start historyserver
6. 关闭防火墙
(对所有节点,可以考虑在克隆之前完成)
systemctl status firewalld.service
systemctl stop firewalld.service & systemctl disable firewalld.service

点击链接:
http://192.168.199.150:50070/dfshealth.html#tab-overview
http://192.168.199.150:8088/cluster
http://192.168.199.150:19888/jobhistory
7. 宿主机上做节点映射
宿主机上修改,host文件
/C:/Windows/System32/drivers/etc/hosts
192.168.199.150 demo demo.centos.com
192.168.199.151 dot1 dot1.centos.com
192.168.199.152 dot2 dot2.centos.com
192.168.199.153 dot3 dot3.centos.com
编辑文件

8. Hadoop环境变量配置
(对所有节点)
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin
[root@demo ~]# vi /etc/profile
[root@demo ~]# source /etc/profile
[root@demo ~]# echo $HADOOP_HOME
/opt/hadoop-3.1.4
[root@demo ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/hadoop-3.1.4/bin6. 关闭集群
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意关闭顺序:
[root@master sbin]# ./stop-dfs.sh
[root@master sbin]# ./stop-yarn.sh
[root@master sbin]#./mr-jobhistory-daemon.sh stop historyserver 或者 mapred --daemon stop historyserver
poweroff

Hadoop集群就配置成功啦!
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化