虽然公司有运维,但也不能啥都靠他们,万一哪天环境出问题了,你不能一上来就找运维吧,丢脸脸~
今天分享一套从零开始搭建一套kafka集群的笔记,我几乎帮你踩了所有的坑,你只需按步骤来,有手就行

kafka依赖jdk和zookeeper环境
开始之前再啰嗦一句,同样的教程,有人失败有人成功,失败的小伙伴大部门都是路径问题,所以,仔细点,不要慌
检查下你服务器有没有jdk,如下图就是装了的

如果没装,出门右转,先把jdk搞完再回来接着看,linux安装jdk环境
虽然kafka 0.5.x 以上版本已经集成了zk,但我们最好还是单独部署一套,两个原因
1、kafka自带的zk是单机的,修改配置也能改成集群,但是有风险,搞不好把kafka改坏了
2、讲道理,虽然kafka依赖zk,但是这毕竟是两个组件,独立出来当然更好,我们应该降低耦合度
安装zookeeper其实也不复杂,只是会有很多坑,我下面的每一步都不要漏掉,最容易出问题的地方就是路径,建议路径保持和我一致,这样你基本直接复制我的命令就能用
1、来到你的服务器,到opt目录,创建一个zookeeper文件夹,然后进去
cd /opt
mkdir zookeeper
cd zookeeper
2、下载zk安装包
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
如果提示wget命令不存在 wget: command not found
yum -y install wget
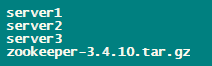
3、创建三个文件夹server1、server2、server3
因为我只有一台服务器,所以只能搭伪集群,所谓伪集群意思就是在一台机器上开三个端口来模拟三台服务器(真集群步骤也一样,一般来说区别在于伪集群ip相同端口不同,真集群ip不通端口相同)
mkdir server1
mkdir server2
mkdir server3
至此,你的zookeeper目录应该长这样
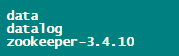
分别在三个server目录中创建data、datalog两个文件夹
并且将zk安装包分别解压到三个server目录中
mkdir server1/data
mkdir server1/datalog
tar -zxvf zookeeper-3.4.10.tar.gz -C server1
mkdir server2/data
mkdir server2/datalog
tar -zxvf zookeeper-3.4.10.tar.gz -C server2
mkdir server3/data
mkdir server3/datalog
tar -zxvf zookeeper-3.4.10.tar.gz -C server3
至此,每个server目录里都应该是这样
现在开始配置zk集群,关键步骤来了
分别 在三个server目录的data文件夹下建一个 myid 文件,文件内容就一个数字,server1对应1,server2对应2,server3对应3
新建文件
vi /opt/zookeeper/server1/data/myid
按i进入编辑模式,输入数字1,esc,冒号,wq保存退出
vi /opt/zookeeper/server2/data/myid
按i进入编辑模式,输入数字2,esc,冒号,wq保存退出
vi /opt/zookeeper/server3/data/myid
按i进入编辑模式,输入数字3,esc,冒号,wq保存退出
然后 分别 进到zookeeper的conf目录
里面有个文件叫 zoo_sample.cfg ,不要动它,它没啥用
我们复制一份到当前目录取名叫 zoo.cfg,名字其实不重要,但大家都这么取的
cp -i zoo_sample.cfg zoo.cfg
当前目录列表
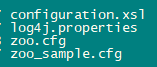
接着修改zoo.cfg文件
主要修改下民红框中几个地方,其它默认或者根据你自己的情况来修改
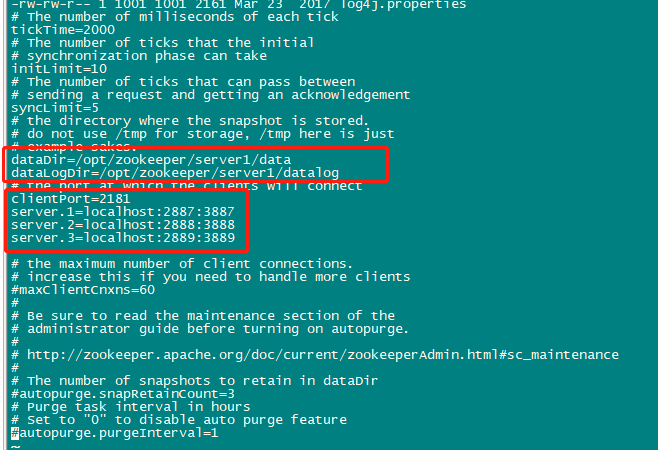
如果你全程都是跟着我的目录来的,直接像下面这样配置即可
#/opt/zookeeper/server1/zookeeper-3.4.10/conf/zoo.cfg
dataDir=/opt/zookeeper/server1/data
dataLogDir=/opt/zookeeper/server1/datalog
clientPort=2181
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
#/opt/zookeeper/server2/zookeeper-3.4.10/conf/zoo.cfg
dataDir=/opt/zookeeper/server2/data
dataLogDir=/opt/zookeeper/server2/datalog
clientPort=2182
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
#/opt/zookeeper/server3/zookeeper-3.4.10/conf/zoo.cfg
dataDir=/opt/zookeeper/server3/data
dataLogDir=/opt/zookeeper/server3/datalog
clientPort=2183
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
配置完成,进入zookeeper的bin目录启动zk服务
cd /opt/zookeeper/server1/zookeeper-3.4.10/bin
./zkServer.sh start
cd /opt/zookeeper/server2/zookeeper-3.4.10/bin
./zkServer.sh start
cd /opt/zookeeper/server3/zookeeper-3.4.10/bin
./zkServer.sh start
启动信息

三个zk都启动完了后,jps确认下启动成功没,如果都成功,会有这三个服务

至此,zookeeper集群搭建完成
1、进入/opt目录,创建kafka文件夹
mkdir /opt/kafka
cd /opt/kafka
2、进去下载kafka安装包
wget https://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
3、创建kafkalogs1、kafkalogs2、kafkalogs3三个文件夹
mkdir kafkalogs1
mkdir kafkalogs2
mkdir kafkalogs3
4、解压kafka安装包
tar -zxvf zookeeper-3.4.10.tar.gz
至此,你的kafka目录应该长这样
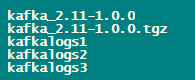
开始配置kafka
进入kafka的config目录
cd /opt/kafka/kafka_2.11-1.0.0/config/
里面有个 server.properties 文件
把这个文件重命名并且复制两份,得到这三个文件(不重命名也行,反正要有三份server配置文件,重命名了看着舒服)
mv server.properties server1.properties
cp -i server1.properties server2.properties
cp -i server1.properties server3.properties
最终得到三个server配置文件
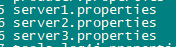
我们需要 分别 修改三个server配置文件的四个属性:
修改的时候注意,这个文件很大,你忍一下
//server1
broker.id=1
listeners=PLAINTEXT://ip:9092
log.dirs=/opt/kafka/kafkalogs1
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
//server2
broker.id=2
listeners=PLAINTEXT://ip:9093
log.dirs=/opt/kafka/kafkalogs2
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
//server3
broker.id=3
listeners=PLAINTEXT://ip:9094
log.dirs=/opt/kafka/kafkalogs3
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
配置完成,启动
来到解压好的kafka目录,启动三个kafka服务
cd /opt/kafka/kafka_2.11-1.0.0
./bin/kafka-server-start.sh -daemon config/server1.properties
./bin/kafka-server-start.sh -daemon config/server2.properties
./bin/kafka-server-start.sh -daemon config/server3.properties
jps看下启动成功没

如果没有kafka进程,说明启动失败了,具体原因可以在logs目录下的kafkaServer.out文件看日志
来到kafka安装目录
cd /opt/kafka/kafka_2.11-1.0.0
创建个topic先
./bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic test-topic --partitions 3 --replication-factor 3
命令解释:在127.0.0.1:2181这台zk上,创建一个名为test-topic的topic,将消息切分成3分,每份3个副本
–zookeeper:指定zk服务
–topic:指定topic名称
–partitions:分区数量
–replication-factor:数据副本数量

启动生产者
./bin/kafka-console-producer.sh --broker-list 私有地址:9092 --topic test-topic
随便发几条消息

启动消费者
./bin/kafka-console-consumer.sh --bootstrap-server 私有地址:9092 --topic test-topic

失败的很大可能性都是配置文件里面的路径没配好,好好检查下
确定上面步骤和配置文件都没错的话,可能是机器内存不足,kafka默认最小启动内存1g
看下启动日志
tail -111f /opt/kafka/kafka_2.11-1.0.0/logs/kafkaServer.out
如果显示如下信息,则就是你机器内存不足

简单,执行下面命令设置kafka启动参数
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
再次启动,如果还提示内存不足
清下机器缓存
sync
echo 3 > /proc/sys/vm/drop_caches
如果不是以上原因,就只能根据启动日志来灵活解决了
查看topic列表
./bin/kafka-topics.sh --zookeeper localhost:2181 --list

查看某个topic详情
./bin/kafka-topics.sh --zookeeper localhost:2181 -describe --topic test-topic

ok我话说完
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
我有一个问题。我想从另一个ruby脚本运行一个ruby脚本并捕获它的输出信息,同时让它也输出到屏幕。亚军#!/usr/bin/envrubyprint"Enteryourpassword:"password=gets.chompputs"Hereisyourpassword:#{password}"我运行的脚本文件:开始.rboutput=`runner`putsoutput.match(/Hereisyour(password:.*)/).captures[0].to_s正如您在此处看到的那样,存在问题。在start.rb的第一行,屏幕是空的。我在运行程序中看不到“输入您的密
有这样的事吗?我想在Ruby程序中使用它。 最佳答案 试试这个http://csl.sublevel3.org/jp2a/此外,Imagemagick可能还有一些东西 关于ruby-是否有将图像文件转换为ASCII艺术的命令行程序或库?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6510445/
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最
在几个项目中,我希望有一个类似rakeserver的rake任务,它将通过任何需要的方式开始为该应用程序提供服务。这是一个示例:task:serverdo%x{bundleexecrackup-p1234}end这行得通,但是当我准备停止它时,按Ctrl+c并没有正常关闭;它中断了Rake任务本身,它说rakeaborted!并给出堆栈跟踪。在某些情况下,我必须执行Ctrl+c两次。我可能可以用Signal.trap写一些东西来更优雅地中断它。有没有更简单的方法? 最佳答案 trap('SIGINT'){puts"Yourmessa
关于SSHkit-Github它说:Allbackendssupporttheexecute(*args),test(*args)&capture(*args)来自SSHkit-Rubydoc,我明白execute实际上是test的别名?test之间有什么区别?,execute,capture在Capistrano/SSHKit中我应该什么时候使用? 最佳答案 执行只是执行命令。使用非0退出引发错误。测试方法的行为与execute完全相同,但是它返回bool值(true如果命令以0退出,而false否则)。它通常用于控制任务中的流程