有一定深度学习图像分割基础,至少阅读过部分语义分割或者医学图像分割文献
python 3.7.9
torch 1.9.1
torchstat 0.0.7
torchsummary 1.5.1
torchvision 0.4.0
cuda 10.0
cudatoolkit 10.1.243
numpy 1.19.2
文章目录
前面的一篇
医学图像分割多目标分割(多分类)实践文章记录了笔者在医学图像分割踩坑入门的实践,但当时的源码不够完整。通过博客的评论互动和私信发现有很多同学同样在做这个方向,最近空闲的时间也让我下定决心重新复现之前代码并进行一些注释和讲解,希望能对该方向入坑的同学提供一些帮助。
先上源码。
【完整源码地址】: pytorch-medical-image-segmentation
重新整理了之前的代码,利用其中一个数据集(前面文章提到的基于磁共振成像的膀胱内外壁分割与肿瘤检测,)作为案例,但由于没有官方的数据授权,我仅将该数据集的一小部分数据拿来做演示。
我将代码托管到了国内的Gitee上(主要觉得比Github速度快点),源码 pytorch-medical-image-segmentation可直接下载运行。
【代码目录结构】:
pytorch-medical-image-segmentation/
|-- checkpoint # 存放训练好的模型
|-- dataprepare # 数据预处理的一些方法
|-- datasets # 数据加载的一些方法
|-- log # 日志文件
|-- media
| |-- Datasets # 存放数据集
|-- networks # 存放模型
|-- test # 测试相关
|-- train # 训练相关
|-- utils # 一些工具函数
|-- validate # 验证相关
|-- README.md
来自ISICDM 2019 临床数据分析挑战赛的基于磁共振成像的膀胱内外壁分割与肿瘤检测数据集。
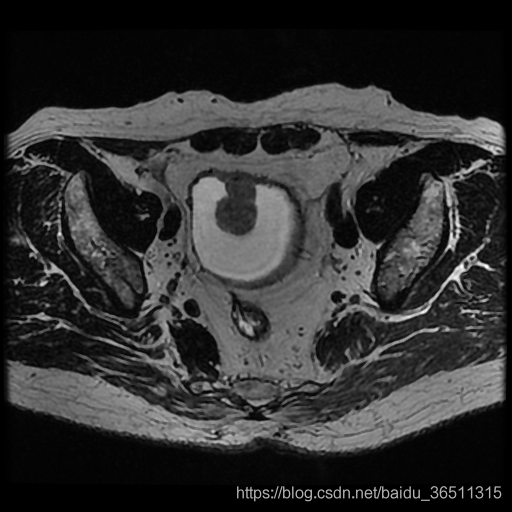

【说明】:笔者没有权限公开分享该数据集,需要完整数据集可通过官网获取。若官网数据集也不能获取,可利用其他数据集代替,本教程主要是提供分割的大体代码思路,不局限于某一个具体的数据集。
【灰度值】:灰色128为膀胱内外壁,白色255为肿瘤。
【分割任务】:同时分割出膀胱内外壁和肿瘤部分
【分析】:我们需要分割出膀胱内外壁和肿瘤,再加上黑色背景,相当于是一个三分类问题。
根据笔者做分割的一些经验,医学图像分割任务的步骤大体是以下几个步骤:
接下来我们通过代码一步步完成分割的过程。
此次的膀胱数据集本身是官方处理好的png图像,不像常规的MRI和CT图像是nii格式的,因此数据处理起来相对容易。
为了简单起见,笔者主要对原始数据做了数据集划分、对标签进行One-hot、裁剪等操作。由于不同的数据集做的数据增广操作(一般会有旋转、缩放、弹性形变等)不太一样,本案例中省略了数据增广的操作。
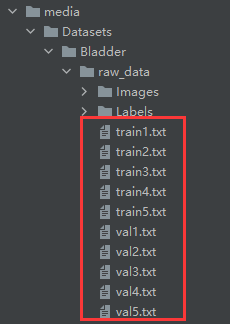
首先,我们对原始数据集进行重新数据划分,这里使用了五折交叉验证(5-fold validation)的方法对数据进行划分,不了解交叉验证的同学可以先去网上搜索了解一下。
这里是将数据集的名字划分到不同txt文件中,而不是真正的将原始数据划分到不同的文件夹中,后面读取的时候也是通过名字来读取,这样更加方便。
# /dataprepare/kfold.py
import os, shutil
from sklearn.model_selection import KFold
# 按K折交叉验证划分数据集
def dataset_kfold(dataset_dir, save_path):
data_list = os.listdir(dataset_dir)
kf = KFold(5, False, 12345) # 使用5折交叉验证
for i, (tr, val) in enumerate(kf.split(data_list), 1):
print(len(tr), len(val))
if os.path.exists(os.path.join(save_path, 'train{}.txt'.format(i))):
# 若该目录已存在,则先删除,用来清空数据
print('清空原始数据中...')
os.remove(os.path.join(save_path, 'train{}.txt'.format(i)))
os.remove(os.path.join(save_path, 'val{}.txt'.format(i)))
print('原始数据已清空。')
for item in tr:
file_name = data_list[item]
with open(os.path.join(save_path, 'train{}.txt'.format(i)), 'a') as f:
f.write(file_name)
f.write('\n')
for item in val:
file_name = data_list[item]
with open(os.path.join(save_path, 'val{}.txt'.format(i)), 'a') as f:
f.write(file_name)
f.write('\n')
if __name__ == '__main__':
# 膀胱数据集划分
# 首次划分数据集或者重新划分数据集时运行
dataset_kfold(os.path.join('..\media\Datasets\Bladder', 'raw_data\Labels'),
os.path.join('..\media\Datasets\Bladder', 'raw_data'))
运行后会生成以下文件,相当于是将数据集5份,每一份对应自己的训练集和验证集。
数据集划分好了,接下来就要写数据加载的类和方法,以便在训练的时候加载我们的数据。
# /datasets/bladder.py
import os
import cv2
import numpy as np
from PIL import Image
from torch.utils import data
from utils import helpers
'''
128 = bladder
255 = tumor
0 = background
'''
palette = [[0], [128], [255]] # one-hot的颜色表
num_classes = 3 # 分类数
def make_dataset(root, mode, fold):
assert mode in ['train', 'val', 'test']
items = []
if mode == 'train':
img_path = os.path.join(root, 'Images')
mask_path = os.path.join(root, 'Labels')
if 'Augdata' in root: # 当使用增广后的训练集
data_list = os.listdir(os.path.join(root, 'Labels'))
else:
data_list = [l.strip('\n') for l in open(os.path.join(root, 'train{}.txt'.format(fold))).readlines()]
for it in data_list:
item = (os.path.join(img_path, it), os.path.join(mask_path, it))
items.append(item)
elif mode == 'val':
img_path = os.path.join(root, 'Images')
mask_path = os.path.join(root, 'Labels')
data_list = [l.strip('\n') for l in open(os.path.join(
root, 'val{}.txt'.format(fold))).readlines()]
for it in data_list:
item = (os.path.join(img_path, it), os.path.join(mask_path, it))
items.append(item)
else:
img_path = os.path.join(root, 'Images')
data_list = [l.strip('\n') for l in open(os.path.join(
root, 'test.txt')).readlines()]
for it in data_list:
item = (os.path.join(img_path, 'c0', it))
items.append(item)
return items
class Dataset(data.Dataset):
def __init__(self, root, mode, fold, joint_transform=None, center_crop=None, transform=None, target_transform=None):
self.imgs = make_dataset(root, mode, fold)
self.palette = palette
self.mode = mode
if len(self.imgs) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.mode = mode
self.joint_transform = joint_transform
self.center_crop = center_crop
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
img_path, mask_path = self.imgs[index]
file_name = mask_path.split('\\')[-1]
img = Image.open(img_path)
mask = Image.open(mask_path)
if self.joint_transform is not None:
img, mask = self.joint_transform(img, mask)
if self.center_crop is not None:
img, mask = self.center_crop(img, mask)
img = np.array(img)
mask = np.array(mask)
# Image.open读取灰度图像时shape=(H, W) 而非(H, W, 1)
# 因此先扩展出通道维度,以便在通道维度上进行one-hot映射
img = np.expand_dims(img, axis=2)
mask = np.expand_dims(mask, axis=2)
mask = helpers.mask_to_onehot(mask, self.palette)
# shape from (H, W, C) to (C, H, W)
img = img.transpose([2, 0, 1])
mask = mask.transpose([2, 0, 1])
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
mask = self.target_transform(mask)
return (img, mask), file_name
def __len__(self):
return len(self.imgs)
if __name__ == '__main__':
np.set_printoptions(threshold=9999999)
from torch.utils.data import DataLoader
import utils.image_transforms as joint_transforms
import utils.transforms as extended_transforms
def demo():
train_path = r'../media/Datasets/Bladder/raw_data'
val_path = r'../media/Datasets/Bladder/raw_data'
test_path = r'../media/Datasets/Bladder/test'
center_crop = joint_transforms.CenterCrop(256)
test_center_crop = joint_transforms.SingleCenterCrop(256)
train_input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
train_set = Dataset(train_path, 'train', 1,
joint_transform=None, center_crop=center_crop,
transform=train_input_transform, target_transform=target_transform)
train_loader = DataLoader(train_set, batch_size=1, shuffle=False)
for (input, mask), file_name in train_loader:
print(input.shape)
print(mask.shape)
img = helpers.array_to_img(np.expand_dims(input.squeeze(), 2))
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose(1, 2, 0), palette)
gt = helpers.array_to_img(gt)
cv2.imshow('img GT', np.uint8(np.hstack([img, gt])))
cv2.waitKey(1000)
demo()
通常我会在数据预处理和加载类已写好后,运行代码测试数据的加载过程,看加载的数据是否有问题。通过可视化的结果可以看到加载的数据是正常的。
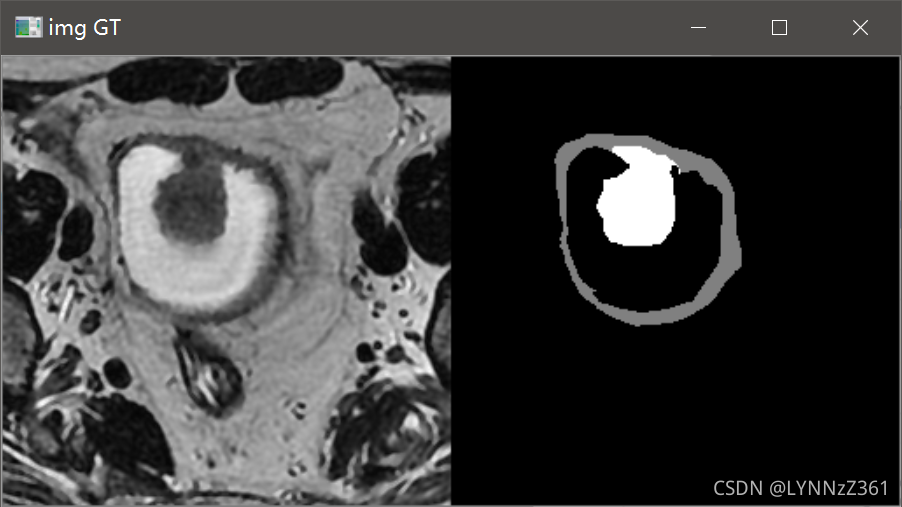
我们在对ground truth反one-hot进行可视化时,改变颜色表palette中的颜色值,就可以将ground truth重新映射成我们想要的颜色,例如:
我们修改上面的部分代码,将颜色表palette修改成三色值([x, x, x]里边有三个数字,单色[x]就对应灰色图像)将gt映射成彩色图像。
for (input, mask), file_name in train_loader:
print(input.shape)
print(mask.shape)
img = helpers.array_to_img(np.expand_dims(input.squeeze(), 2))
# 将gt反one-hot回去以便进行可视化
palette = [[0, 0, 0], [246, 16, 16], [16, 136, 246]]
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose(1, 2, 0), palette)
gt = helpers.array_to_img(gt)
# cv2.imshow('img GT', np.uint8(np.hstack([img, gt])))
cv2.imshow('img GT', np.uint8(gt))
cv2.waitKey(1000)
可视化的结果如下

直接用经典的U-Net作为演示模型。注意输入的图像是1个通道,输出是3个通道。
# /networks/u_net.py
from networks.custom_modules.basic_modules import *
from utils.misc import initialize_weights
class Baseline(nn.Module):
def __init__(self, img_ch=1, num_classes=3, depth=2):
super(Baseline, self).__init__()
chs = [64, 128, 256, 512, 512]
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc1 = EncoderBlock(img_ch, chs[0], depth=depth)
self.enc2 = EncoderBlock(chs[0], chs[1], depth=depth)
self.enc3 = EncoderBlock(chs[1], chs[2], depth=depth)
self.enc4 = EncoderBlock(chs[2], chs[3], depth=depth)
self.enc5 = EncoderBlock(chs[3], chs[4], depth=depth)
self.dec4 = DecoderBlock(chs[4], chs[3])
self.decconv4 = EncoderBlock(chs[3] * 2, chs[3])
self.dec3 = DecoderBlock(chs[3], chs[2])
self.decconv3 = EncoderBlock(chs[2] * 2, chs[2])
self.dec2 = DecoderBlock(chs[2], chs[1])
self.decconv2 = EncoderBlock(chs[1] * 2, chs[1])
self.dec1 = DecoderBlock(chs[1], chs[0])
self.decconv1 = EncoderBlock(chs[0] * 2, chs[0])
self.conv_1x1 = nn.Conv2d(chs[0], num_classes, 1, bias=False)
initialize_weights(self)
def forward(self, x):
# encoding path
x1 = self.enc1(x)
x2 = self.maxpool(x1)
x2 = self.enc2(x2)
x3 = self.maxpool(x2)
x3 = self.enc3(x3)
x4 = self.maxpool(x3)
x4 = self.enc4(x4)
x5 = self.maxpool(x4)
x5 = self.enc5(x5)
# decoding + concat path
d4 = self.dec4(x5)
d4 = torch.cat((x4, d4), dim=1)
d4 = self.decconv4(d4)
d3 = self.dec3(d4)
d3 = torch.cat((x3, d3), dim=1)
d3 = self.decconv3(d3)
d2 = self.dec2(d3)
d2 = torch.cat((x2, d2), dim=1)
d2 = self.decconv2(d2)
d1 = self.dec1(d2)
d1 = torch.cat((x1, d1), dim=1)
d1 = self.decconv1(d1)
d1 = self.conv_1x1(d1)
return d1
if __name__ == '__main__':
# from torchstat import stat
import torch
from torchsummary import summary
x = torch.randn([2, 1, 64, 64]).cuda()
# # 参数计算
model = Baseline(num_classes=3).cuda()
total = sum([param.nelement() for param in model.parameters()])
print("Number of parameter: %.3fM" % (total / 1e6))
# # 参数计算
# # stat(model, (1, 224, 224))
# # 每层输出大小
print(model(x).shape)
可以直接运行该文件,测试模型的输入和输出是否符合预期。
这里选择医学图像分割中最常用的指标Dice和Dice loss。关于实现的讨论可参考【Pytorch】 Dice系数与Dice Loss损失函数实现。
Dice系数的实现核心代码:
# /utils/metrics.py
def diceCoeffv2(pred, gt, eps=1e-5):
r""" computational formula:
dice = (2 * tp) / (2 * tp + fp + fn)
"""
N = gt.size(0)
pred_flat = pred.view(N, -1)
gt_flat = gt.view(N, -1)
tp = torch.sum(gt_flat * pred_flat, dim=1)
fp = torch.sum(pred_flat, dim=1) - tp
fn = torch.sum(gt_flat, dim=1) - tp
score = (2 * tp + eps) / (2 * tp + fp + fn + eps)
return score.sum() / N
多分类Dice loss实现的核心代码:
# /utils/loss.py
class SoftDiceLoss(_Loss):
def __init__(self, num_classes):
super(SoftDiceLoss, self).__init__()
self.num_classes = num_classes
def forward(self, y_pred, y_true):
class_dice = []
# 从1开始排除背景,前提是颜色表palette中背景放在第一个位置 [[0], ..., ...]
for i in range(1, self.num_classes):
class_dice.append(diceCoeffv2(y_pred[:, i:i + 1, :], y_true[:, i:i + 1, :]))
mean_dice = sum(class_dice) / len(class_dice)
return 1 - mean_dice
如果只是二分类,用下面的损失函数:
class BinarySoftDiceLoss(_Loss):
def __init__(self):
super(BinarySoftDiceLoss, self).__init__()
def forward(self, y_pred, y_true):
mean_dice = diceCoeffv2(y_pred, y_true)
return 1 - mean_dice
训练的整体思路就是,训练完一个epoch进行验证(注意验证的loss不反向传播,只验证不影响模型权重),在训练的过程中使用了早停机制(Early stopping)。只要在15个epoch内,验证集上的评价Dice指标增长不超过0.1%则停止训练,并保存之前在验证集上最好的模型。
代码中Early Stopping提供两个版本,其中EarlyStopping传指标进去即可,EarlyStoppingV2传验证集的loss值,表示在15个epoch内,loss下降不超过0.001则停止训练。
# /train/train_bladder.py
import time
import os
import torch
import random
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
from torch.optim import lr_scheduler
from tqdm import tqdm
import sys
from datasets import bladder
import utils.image_transforms as joint_transforms
import utils.transforms as extended_transforms
from utils.loss import *
from utils.metrics import diceCoeffv2
from utils import misc
from utils.pytorchtools import EarlyStopping
from utils.LRScheduler import PolyLR
# 超参设置
crop_size = 256 # 输入裁剪大小
batch_size = 2 # batch size
n_epoch = 300 # 训练的最大epoch
early_stop__eps = 1e-3 # 早停的指标阈值
early_stop_patience = 15 # 早停的epoch阈值
initial_lr = 1e-4 # 初始学习率
threshold_lr = 1e-6 # 早停的学习率阈值
weight_decay = 1e-5 # 学习率衰减率
optimizer_type = 'adam' # adam, sgd
scheduler_type = 'no' # ReduceLR, StepLR, poly
label_smoothing = 0.01
aux_loss = False
gamma = 0.5
alpha = 0.85
model_number = random.randint(1, 1e6)
model_type = "unet"
if model_type == "unet":
from networks.u_net import Baseline
root_path = '../'
fold = 1 # 训练集k-fold, 可设置1, 2, 3, 4, 5
depth = 2 # unet编码器的卷积层数
loss_name = 'dice' # dice, bce, wbce, dual, wdual
reduction = '' # aug
model_name = '{}_depth={}_fold_{}_{}_{}{}'.format(model_type, depth, fold, loss_name, reduction, model_number)
# 训练日志
writer = SummaryWriter(os.path.join(root_path, 'log/bladder/train', model_name + '_{}fold'.format(fold) + str(int(time.time()))))
val_writer = SummaryWriter(os.path.join(os.path.join(root_path, 'log/bladder/val', model_name) + '_{}fold'.format(fold) + str(int(time.time()))))
# 训练集路径
# train_path = os.path.join(root_path, 'media/Datasets/bladder/Augdata_5folds', 'train{}'.format(fold), 'npy')
train_path = os.path.join(root_path, 'media/Datasets/Bladder/raw_data')
val_path = os.path.join(root_path, 'media/Datasets/Bladder/raw_data')
def main():
# 定义网络
net = Baseline(num_classes=bladder.num_classes, depth=depth).cuda()
# 数据预处理
center_crop = joint_transforms.CenterCrop(crop_size)
input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
# 训练集加载
train_set = bladder.Dataset(train_path, 'train', fold, joint_transform=None, center_crop=center_crop,
transform=input_transform, target_transform=target_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=6)
# 验证集加载
val_set = bladder.Dataset(val_path, 'val', fold,
joint_transform=None, transform=input_transform, center_crop=center_crop,
target_transform=target_transform)
val_loader = DataLoader(val_set, batch_size=1, shuffle=False)
# 定义损失函数
if loss_name == 'dice':
criterion = SoftDiceLoss(bladder.num_classes).cuda()
# 定义早停机制
early_stopping = EarlyStopping(early_stop_patience, verbose=True, delta=early_stop__eps,
path=os.path.join(root_path, 'checkpoint', '{}.pth'.format(model_name)))
# 定义优化器
if optimizer_type == 'adam':
optimizer = torch.optim.Adam(net.parameters(), lr=initial_lr, weight_decay=weight_decay)
else:
optimizer = torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
# 定义学习率衰减策略
if scheduler_type == 'StepLR':
scheduler = lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
elif scheduler_type == 'ReduceLR':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5)
elif scheduler_type == 'poly':
scheduler = PolyLR(optimizer, max_iter=n_epoch, power=0.9)
else:
scheduler = None
train(train_loader, val_loader, net, criterion, optimizer, scheduler, None, early_stopping, n_epoch, 0)
def train(train_loader, val_loader, net, criterion, optimizer, scheduler, warm_scheduler, early_stopping, num_epoches,
iters):
for epoch in range(1, num_epoches + 1):
st = time.time()
train_class_dices = np.array([0] * (bladder.num_classes - 1), dtype=np.float)
val_class_dices = np.array([0] * (bladder.num_classes - 1), dtype=np.float)
val_dice_arr = []
train_losses = []
val_losses = []
# 训练模型
net.train()
for batch, ((input, mask), file_name) in enumerate(train_loader, 1):
X = input.cuda()
y = mask.cuda()
optimizer.zero_grad()
output = net(X)
output = torch.sigmoid(output)
loss = criterion(output, y)
loss.backward()
optimizer.step()
iters += 1
train_losses.append(loss.item())
class_dice = []
for i in range(1, bladder.num_classes):
cur_dice = diceCoeffv2(output[:, i:i + 1, :], y[:, i:i + 1, :]).cpu().item()
class_dice.append(cur_dice)
mean_dice = sum(class_dice) / len(class_dice)
train_class_dices += np.array(class_dice)
string_print = 'epoch: {} - iters: {} - loss: {:.4} - mean: {:.4} - bladder: {:.4}- tumor: {:.4} - time: {:.2}' \
.format(epoch, iters, loss.data.cpu(), mean_dice, class_dice[0], class_dice[1], time.time() - st)
misc.log(string_print)
st = time.time()
train_loss = np.average(train_losses)
train_class_dices = train_class_dices / batch
train_mean_dice = train_class_dices.sum() / train_class_dices.size
writer.add_scalar('main_loss', train_loss, epoch)
writer.add_scalar('main_dice', train_mean_dice, epoch)
print('epoch {}/{} - train_loss: {:.4} - train_mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'.format(
epoch, num_epoches, train_loss, train_mean_dice, train_class_dices[0], train_class_dices[1]))
# 验证模型
net.eval()
for val_batch, ((input, mask), file_name) in tqdm(enumerate(val_loader, 1)):
val_X = input.cuda()
val_y = mask.cuda()
pred = net(val_X)
pred = torch.sigmoid(pred)
val_loss = criterion(pred, val_y)
val_losses.append(val_loss.item())
pred = pred.cpu().detach()
val_class_dice = []
for i in range(1, bladder.num_classes):
val_class_dice.append(diceCoeffv2(pred[:, i:i + 1, :], mask[:, i:i + 1, :]))
val_dice_arr.append(val_class_dice)
val_class_dices += np.array(val_class_dice)
val_loss = np.average(val_losses)
val_dice_arr = np.array(val_dice_arr)
val_class_dices = val_class_dices / val_batch
val_mean_dice = val_class_dices.sum() / val_class_dices.size
val_writer.add_scalar('lr', optimizer.param_groups[0]['lr'], epoch)
val_writer.add_scalar('main_loss', val_loss, epoch)
val_writer.add_scalar('main_dice', val_mean_dice, epoch)
print('val_loss: {:.4} - val_mean_dice: {:.4} - bladder: {:.4}- tumor: {:.4}'
.format(val_loss, val_mean_dice, val_class_dices[0], val_class_dices[1]))
print('lr: {}'.format(optimizer.param_groups[0]['lr']))
early_stopping(val_mean_dice, net, epoch)
if early_stopping.early_stop or optimizer.param_groups[0]['lr'] < threshold_lr:
print("Early stopping")
# 结束模型训练
break
print('----------------------------------------------------------')
print('save epoch {}'.format(early_stopping.save_epoch))
print('stoped epoch {}'.format(epoch))
print('----------------------------------------------------------')
if __name__ == '__main__':
main()
按照加载训练集类似的方法,我们加载验证集或者测试集进行模型验证。
# /validate/validate_bladder.py
import os
import cv2
import torch
import shutil
import utils.image_transforms as joint_transforms
from torch.utils.data import DataLoader
import utils.transforms as extended_transforms
from datasets import bladder
from utils.loss import *
from networks.u_net import Baseline
from tqdm import tqdm
crop_size = 256
val_path = r'..\media/Datasets/Bladder/raw_data'
center_crop = joint_transforms.CenterCrop(crop_size)
val_input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
val_set = bladder.Dataset(val_path, 'val', 1,
joint_transform=None, transform=val_input_transform, center_crop=center_crop,
target_transform=target_transform)
val_loader = DataLoader(val_set, batch_size=1, shuffle=False)
palette = bladder.palette
num_classes = bladder.num_classes
net = Baseline(img_ch=1, num_classes=num_classes, depth=2).cuda()
net.load_state_dict(torch.load("../checkpoint/unet_depth=2_fold_1_dice_348055.pth"))
net.eval()
def auto_val(net):
# 效果展示图片数
dices = 0
class_dices = np.array([0] * (num_classes - 1), dtype=np.float)
save_path = './results'
if os.path.exists(save_path):
# 若该目录已存在,则先删除,用来清空数据
shutil.rmtree(os.path.join(save_path))
img_path = os.path.join(save_path, 'images')
pred_path = os.path.join(save_path, 'pred')
gt_path = os.path.join(save_path, 'gt')
os.makedirs(img_path)
os.makedirs(pred_path)
os.makedirs(gt_path)
val_dice_arr = []
for (input, mask), file_name in tqdm(val_loader):
file_name = file_name[0].split('.')[0]
X = input.cuda()
pred = net(X)
pred = torch.sigmoid(pred)
pred = pred.cpu().detach()
# pred[pred < 0.5] = 0
# pred[np.logical_and(pred > 0.5, pred == 0.5)] = 1
# 原图
m1 = np.array(input.squeeze())
m1 = helpers.array_to_img(np.expand_dims(m1, 2))
# gt
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose([1, 2, 0]), palette)
gt = helpers.array_to_img(gt)
# pred
save_pred = helpers.onehot_to_mask(np.array(pred.squeeze()).transpose([1, 2, 0]), palette)
save_pred_png = helpers.array_to_img(save_pred)
# png格式
m1.save(os.path.join(img_path, file_name + '.png'))
gt.save(os.path.join(gt_path, file_name + '.png'))
save_pred_png.save(os.path.join(pred_path, file_name + '.png'))
class_dice = []
for i in range(1, num_classes):
class_dice.append(diceCoeffv2(pred[:, i:i + 1, :], mask[:, i:i + 1, :]))
mean_dice = sum(class_dice) / len(class_dice)
val_dice_arr.append(class_dice)
dices += mean_dice
class_dices += np.array(class_dice)
print('mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'
.format(mean_dice, class_dice[0], class_dice[1]))
val_mean_dice = dices / (len(val_loader) / 1)
val_class_dice = class_dices / (len(val_loader) / 1)
print('Val mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'.format(val_mean_dice, val_class_dice[0], val_class_dice[1]))
if __name__ == '__main__':
np.set_printoptions(threshold=9999999)
auto_val(net)
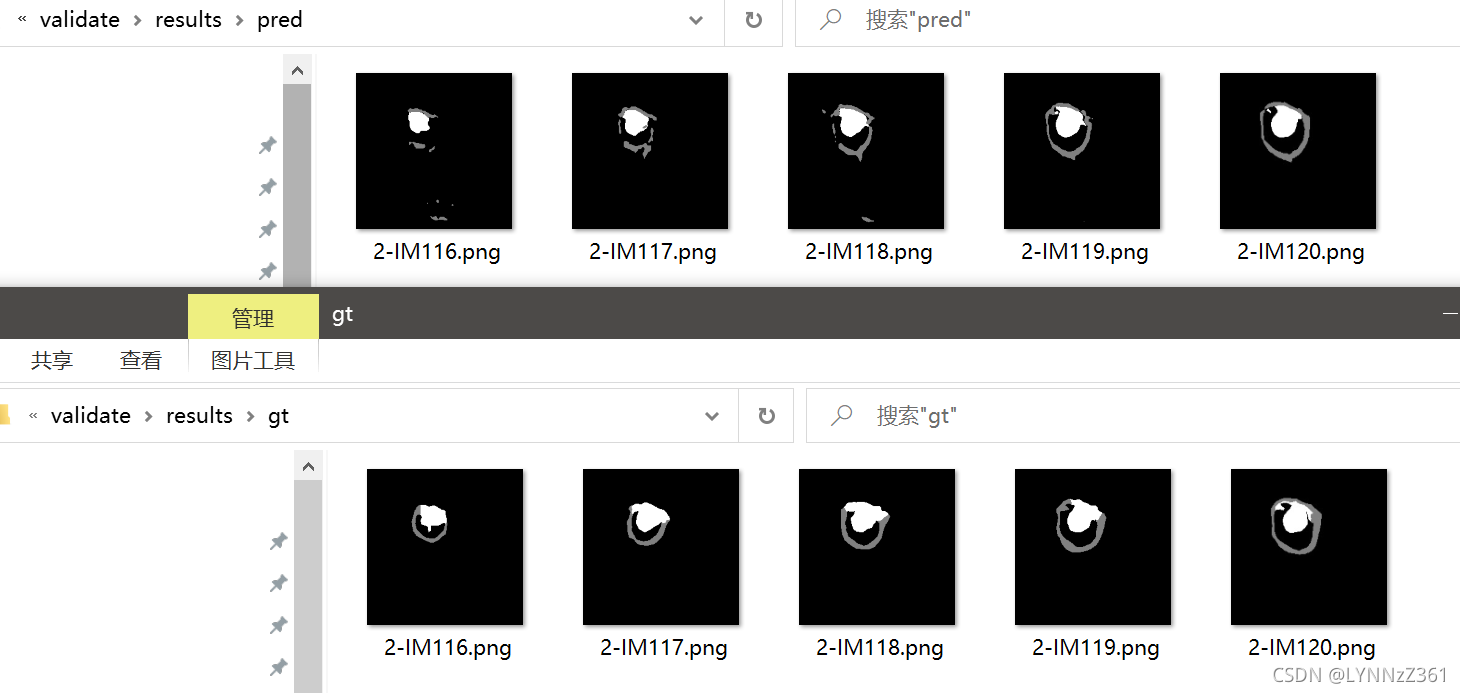
直接运行该文件可生成我们的预测结果。
虽然我们的U-Net只用了24张图进行训练,但从结果可以看到,模型也能大致分割出目标。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear