在任意python文件下运行这几行命令
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称输出、报错如下:
是否可用: True
...
RuntimeError: The NVIDIA driver on your system is too old (found version 10020).然后在尝试降版本后出现第二个报错:
同样的命令
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称输出结果:
是否可用: False
...
AssertionError: Torch not compiled with CUDA enabled
首先命令行输入nvidia-smi,查看CUDA版本:
nvidia-smi查看得到结果:

得到服务器的CUDA版本为10.2.
然后去torch官网中查看老版本CUDA适配的torch版本:
https://pytorch.org/get-started/previous-versions/
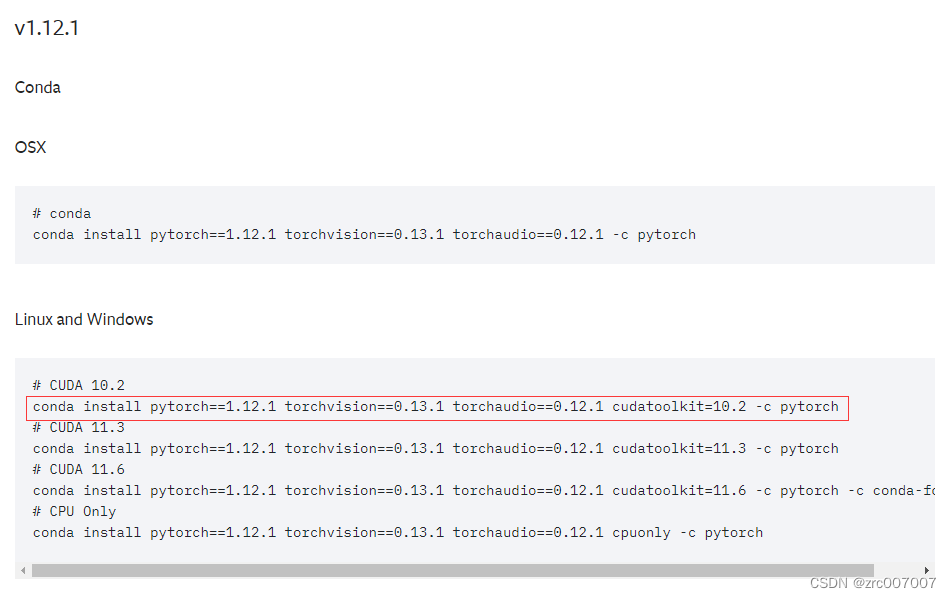
下面就要在镜像源中找到这样的torch版本:1.12.1以及适配gpu
比如我们在北外的torch镜像源中找:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
我们是linux版本,就选linux:
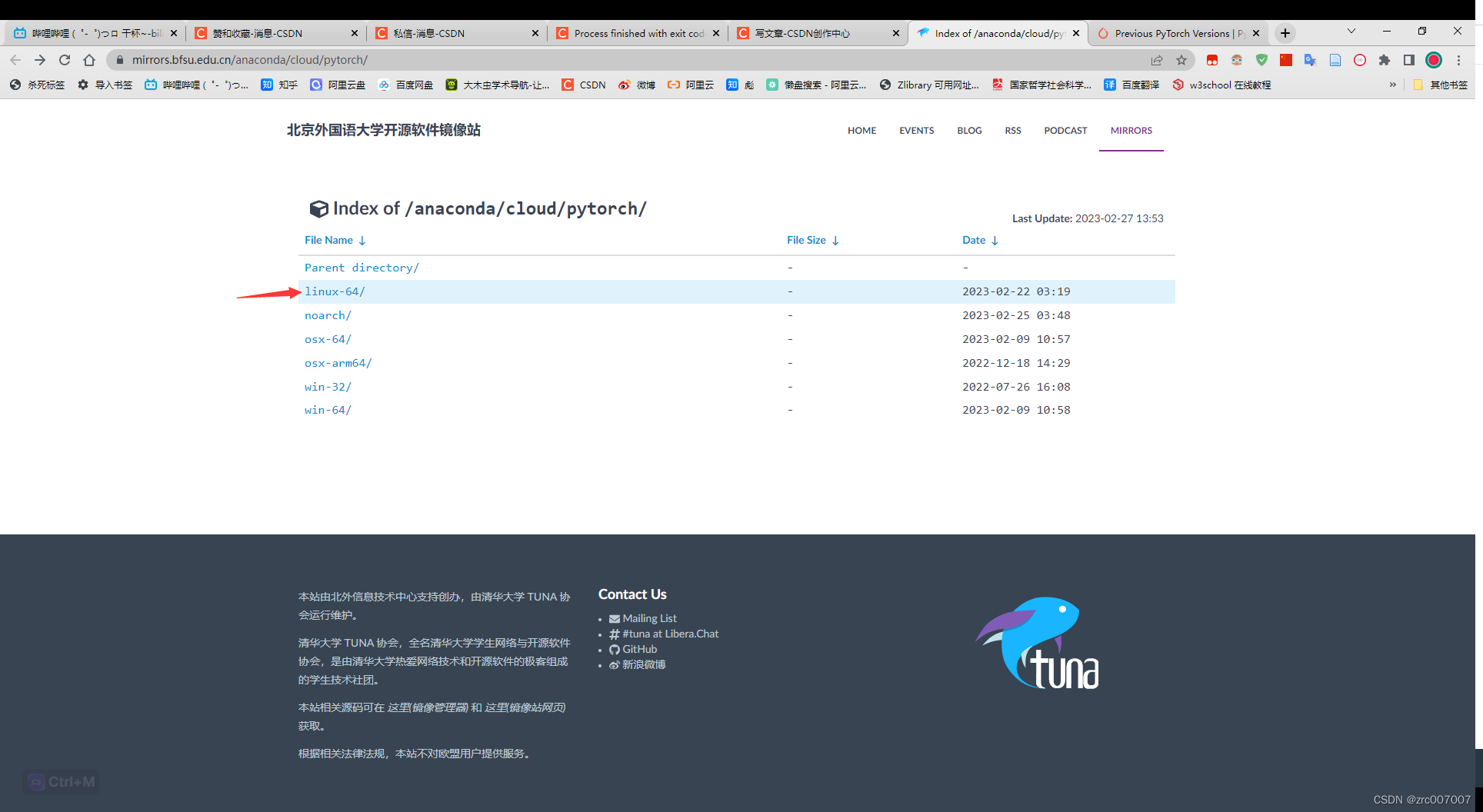
看到了如下的:
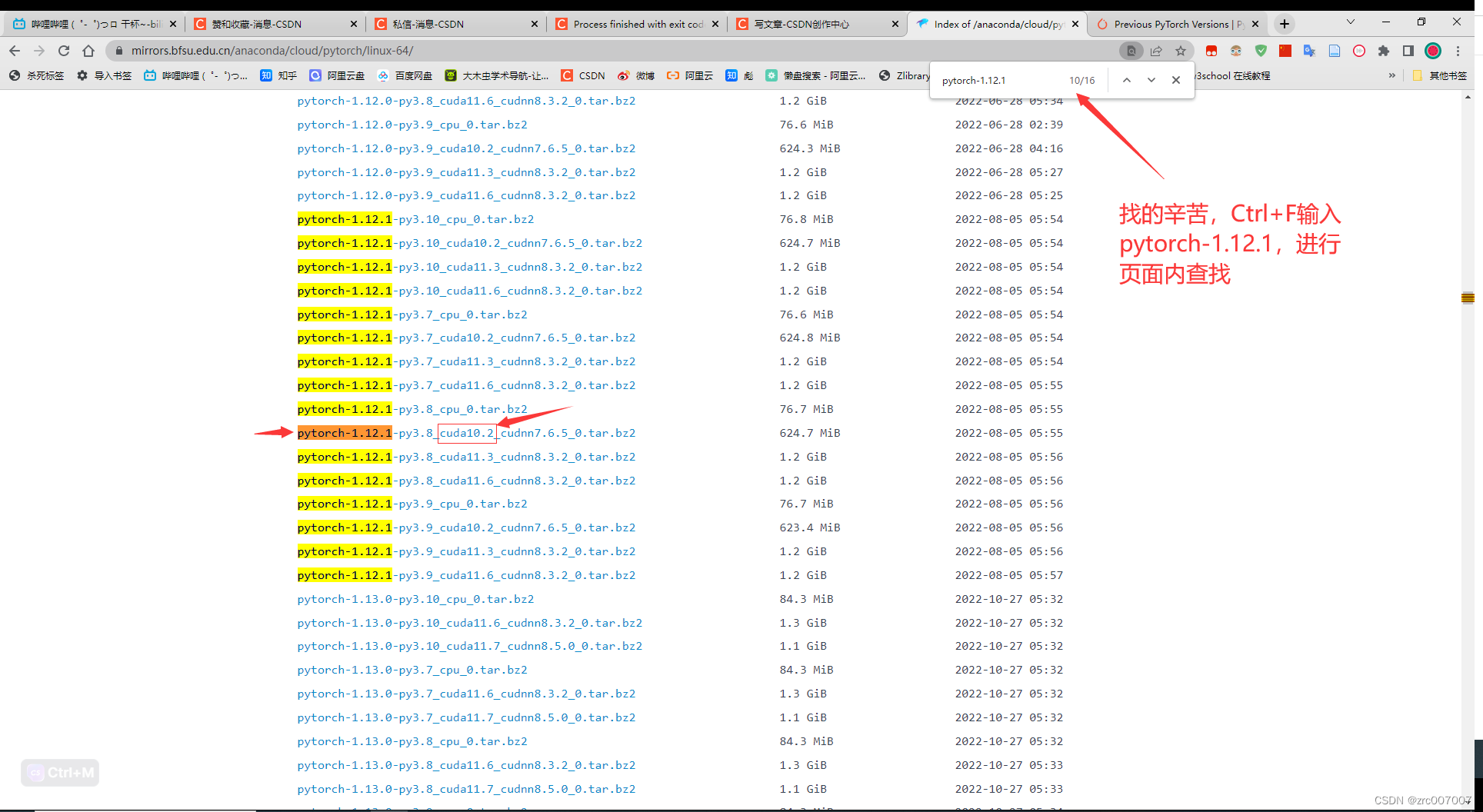
这就是我们要找的。右键点击蓝字,'右键'-'复制链接地址',得到下载链接,直接用这个包安装pytorch:
conda install https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/linux-64/pytorch-1.12.1-py3.8_cuda10.2_cudnn7.6.5_0.tar.bz2然后用以下命令,自动安装适配的依赖包:
conda install pytorch这样就安装成功了,再次调用以上python命令测试CUDA:
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称得到结果:
True
2
10.2
0
Tesla T4torchvision也是同理:
conda install https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/linux-64/torchvision-0.13.1-py38_cu102.tar.bz2
conda install torchvision
然后具体介绍一下这几个报错,这样也把我一路摸着石头过河的经历给复述一下。
你安装的torch和你的CUDA版本不匹配。
比如我的环境中就是10.2的CUDA和1.13.0(或者1.13.1,反正是1.13版本)的pytorch冲突了。
降低pytorch版本。
升级CUDA。
解决办法很多,可以参考网上其他文章。本文重点在第二个报错Torch和CUDA的编译(compile)问题,因为我自己是使用学校的机房,没权限升级CUDA,所以介绍一下我尝试过的第一个办法,降低pytorch版本:
你在看这一段时,会发现前面和我最终的解决方法是一样的,但后面不同的方法让我走了弯路。
首先确定你的CUDA版本,在Linux命令行终端中输入nvidia-smi:
nvidia-smi查看得到结果:
得到服务器的CUDA版本为10.2.
然后去torch官网中查看老版本CUDA适配的torch版本:
https://pytorch.org/get-started/previous-versions/
好了,到这一步,你可能就会按照它上面的操作,安装这几个版本的库了。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=10.2 -c pytorch不过你可能会碰到的问题有:
某个包版本不匹配当前python版本
某个包版本和其他包冲突
某个包安装的版本和CUDA版本不匹配
可能你改进了第一、二个问题,终于把整套pytorch、torchvision下下来了,但你还是要面对第三个问题,就是继而报错AssertionError: Torch not compiled with CUDA enabled,不过我一步步介绍我的经历,先看看如何面对第一和第二个问题的:
自己调试去安装,我试过,最后还是选择了使用如下命令:
conda install --override-channels -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ pytorch torchvision cudatoolkit=10.2这条命令是说,指定使用镜像源https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/,指定cudatoolkit版本适配10.2的CUDA,然后根据这个适配,下载pytorch包和torchvision包。
下载好了,尝试代码,你会得到:
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称
(输出结果:)
是否可用: False
...
AssertionError: Torch not compiled with CUDA enabled这就是第二个报错了。
而第二个报错则是因为你安装的torch是cpu版本的。比如你可以在你的conda环境下查找torch版本:
conda list | grep torch结果如下:
(base) weinz@dlp01:~$ conda list | grep torch
(正常使用命令无法看到下面注释的一行,为了直观显示,我粘贴过来了)
# Name Version Build Channel
pytorch 1.12.1 cpu_py38he8d8e81_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
torchvision 0.13.1 cpu_py38h164cc8f_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main其中包版本号Version后面的Build列,就能看到torch适配的是cpu版本。
发现问题后,改成gpu版本的就可以了。
具体方法就接上我最终的解决方案了:
首先回顾一下我们需要的torch版本:
在镜像源中找到1.12.1以及适配gpu的pytorch、torchvision
进入镜像源https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
这就是我们要找的。右键-复制链接地址,直接用这个包安装pytorch:
conda install https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/linux-64/pytorch-1.12.1-py3.8_cuda10.2_cudnn7.6.5_0.tar.bz2可以查看一下,这样下载的是否是gpu版本的。输入查找命令:
conda list | grep torch得到结果:

可以看到,显示的是cuda,这个就是gpu版本的了。
然后用以下命令,自动安装适配的依赖包:
conda install pytorch这样就安装成功了,再次调用以上python命令测试CUDA:
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称得到结果:
True
2
10.2
0
Tesla T4torchvision也是同理:
conda install https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/linux-64/torchvision-0.13.1-py38_cu102.tar.bz2
conda install torchvision看着网上的文章,还有问chatGPT,一步步解决了这个问题,还是值得的。
有的方法在选择gpu版本的时候,选择这样:
conda install -c 镜像源 后面调试版本
conda install -c 'http...' pytorch=1.12.1 torchvision=0.13.0 cudatoolkit=10.2
conda install -c 'http...' pytorch=1.9.1 torchvision=0.8.0 cudatoolkit=10.2
...一步步调版本,我在调的时候发现太搞了,而且试出来下好配套的了,可能下的也是cpu版本的。
具体可参考这篇文章:
https://blog.csdn.net/u013468614/article/details/125910538
可能更了解镜像源内部选择的方式,会有更好的解决方法。不过在此之前,这种直接下载你需要的版本然后让镜像源给你补依赖包才是最高效的方法。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我想了解Ruby方法methods()是如何工作的。我尝试使用“ruby方法”在Google上搜索,但这不是我需要的。我也看过ruby-doc.org,但我没有找到这种方法。你能详细解释一下它是如何工作的或者给我一个链接吗?更新我用methods()方法做了实验,得到了这样的结果:'labrat'代码classFirstdeffirst_instance_mymethodenddefself.first_class_mymethodendendclassSecond使用类#returnsavailablemethodslistforclassandancestorsputsSeco
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
设置:狂欢ruby1.9.2高线(1.6.13)描述:我已经相当习惯在其他一些项目中使用highline,但已经有几个月没有使用它了。现在,在Ruby1.9.2上全新安装时,它似乎不允许在同一行回答提示。所以以前我会看到类似的东西:require"highline/import"ask"Whatisyourfavoritecolor?"并得到:Whatisyourfavoritecolor?|现在我看到类似的东西:Whatisyourfavoritecolor?|竖线(|)符号是我的终端光标。知道为什么会发生这种变化吗? 最佳答案
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘